NFA 转 DAF : subset construction(子集构造法)
对于一个正则表达式,虽然说NFA和DFA从input state走到final state总是能满足正则表达式的要求,但是NFA对于一个特定的例子可以有无限多中走法,而DFA对于一个特定的例子只有唯一的走法,所以DFA更利于编程转换成代码
转换的核心思想就是把NFA路线中的多个可能性的选择合并看作一个DFA state
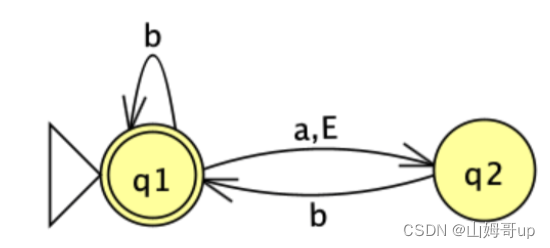
q1 → d1
q2 → d2
(q1,q2) → d3
∅ → d4
可以看出NFA的2个state可以最多有4个DFA state
如果有3个NFA state 那么可以最多有8个DFA state 即:{q1,q2,q3}
{q1} {q2} {q3} {q1,q2} {q1,q3} {q2,q3} {q1,q2,q3} {∅}
可以看出 这八个DFA state都是{q1,q2,q3}的子集 所以这也是为什么叫subset construction
总结 如果有n个NFA state 那么可以有至多
个DFA state
接下来看具体转换过程
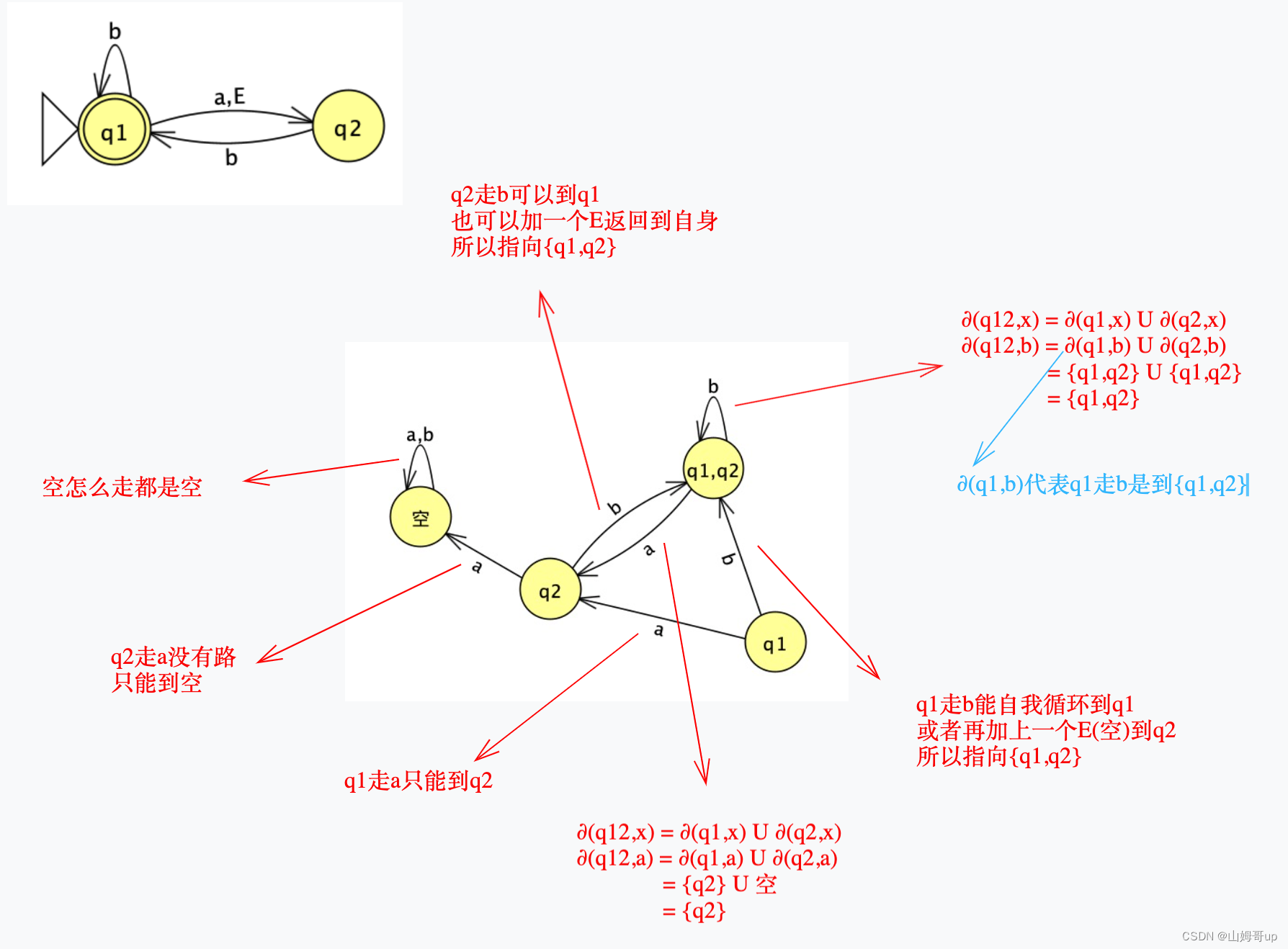
首先在NFA中q1是final state 那么在DFA中 q1和E-closure of q1都可以作为final state
接下来 可以发现上图中q1只有输出 没有输入 这种state要剔除
如果start state在NFA中是q1 那么转换到DFA中则成了E-closure of q1
⚠️:E-closure of q1的意思是除了q1本身外 q1通过E(空)还能走到哪里,可以看到也可以走到q2 所以closure of q1是{q1,q2}

最终形成了以下的DFA

改一下state的名字 就成了: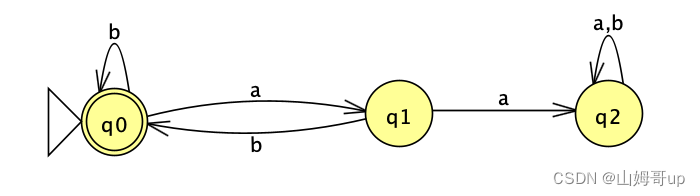
可以看出 这个NFA只有两个state 但是在第一步的时候按照标准的subset construction的做法也是要画出个state 我们说至多
因为可以看到在过程中有些state可能会被消除
如果NFA是10个state 那么意味着至多2的十次方即1024个DFA state
但是通常来说是不需要这么多 运气好的话或许很少的state就可以完成DFA的转换
这个的复杂程度可以看出是指数倍的 但是没有关系 因为这个并不是在编译过程中完成的 这个是在做编译器的时候完成的 可以说是一劳永逸的工作 不会重复的去做
再看一个例子
a (b U c)*
NFA: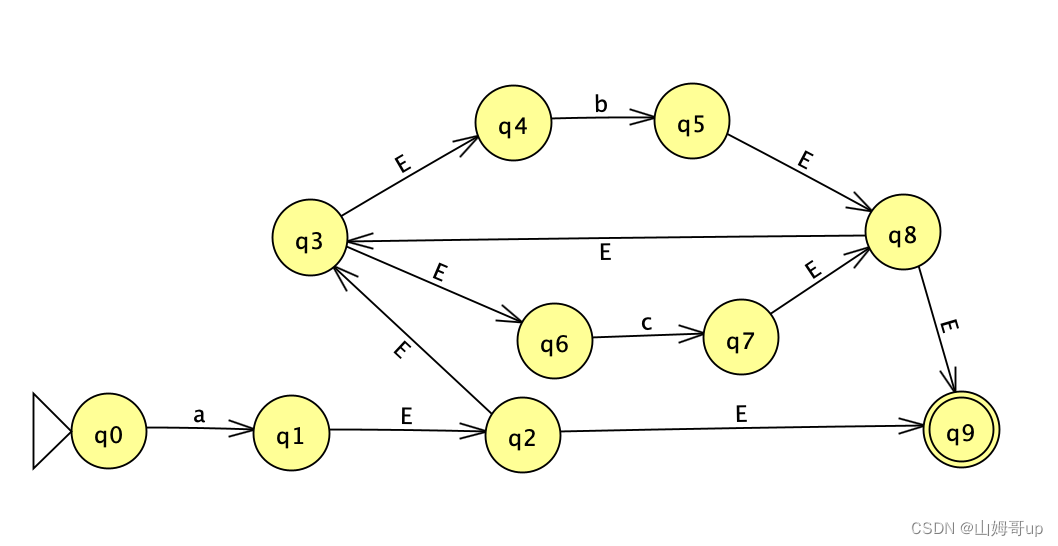
图表:
| DFA state | NFA state | x=a | x=b | x=c |
| d0 | q0 | d1 | d∅ | d∅ |
| d1 | {q1,q2,q3,q4,q6,q9} | d∅ | d2 | d3 |
| d∅ | {} | d∅ | d∅ | d∅ |
| d2 | {q3,q4,q5,q6,q8,q9} | d∅ | d2 | d3 |
| d3 | {q3,q4,q6,q7,q8,q9} | d∅ | d2 | d3 |
起始位置为E-closure of q0 即q0自己 标记为d0 q0走a到了E-closure of q1 是个集合 需要设为d1 走b和c都走不通 即为d空
因为出现了d1和 d空 就需要继续列表表示其走向
d1是E-closure of q1 即为集合{q1,q2,q3,q4,q6,q9} 这个集合中没有任何一个state走的通a 所以为d空 走b的话集合中q4可以走到E-closure of q5 是个集合需要设为d2 同理走c的话q6可以走到E-closure of q7 是个集合 需要设为d3
d空走什么都是d空
d2是E-closure of q5 走a走不通 设为d空 走b的话q4可以走到E-closure of q5 即自己d2本身 走c的话q6可以走到E-closure of q7 即为d3
d3是E-closure of q7 走a走不通 设为d空 走b的话q4可以走到E-closure of q5 就是d2 走c的话q6可以走到E-closure of q7 即为自己d3本身
这时候发现没有出现新的d集合需要继续列表了 证明DFA可以用当前表格完成
DFA:
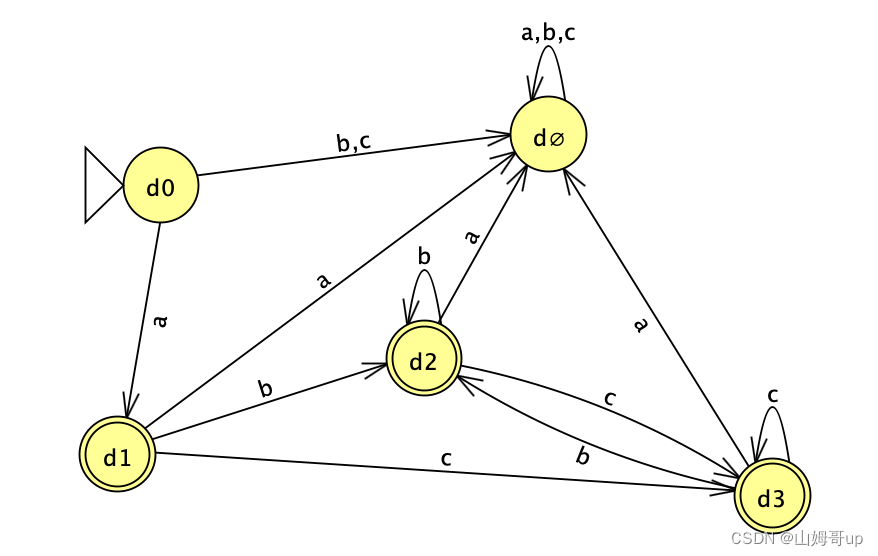
这里的start state就是E-closure of q0 就是q0本身 即d0
final state是E-closure of q9 即d集合包含q9的都算 即是d1 d2 d3