从正规式到NFA
正规式是对模式的形式化描述,DFA负责高效、优雅地识别这种模式。从正规式到最优DFA要走三步:构建NFA、NFA确定化、DFA最小化。
本节关注从正规式构造NFA的算法:Thompson。
在学习之前我们有必要把正规式和NFA两者的本质和关系理清。
正规式的作用:描述一个字符串模式。
NFA的作用:识别一个字符串模式。
两者关系:正规式负责生产,NFA负责验收。
1.正规式如何生产?
重点不是正规式如何生产,而是模式如何生产(正规式就是对模式的形式化描述嘛)。回想起形形色色的字符串,我们会发现这些字符串模式都有如下几个基本特征:基本成分为字符、下一个字符可以有多个选择、字符之间有连接。从这三个共有的基本特征我们可以提炼出:模式生产就是这三个基本特征的实体任意组合的过程。
那么换到正规式之后,我们也可以这样说:正规式生产就是基本正规式任意组合的过程(这是从非形式化到形式化的映射)。与基本特征对应的基本正规式包括:基本字符a(a代指任意字符)、字符或’|‘(做选择)、字符与’.’(连接)。
2.NFA如何验收?
验收是根据生产过程而来的,这可不是先有鸡还是先有蛋的问题,逻辑很清晰。既然这样,我们自然而然想到,可以先求出基本正规式的NFA——基本NFA,然后剩下的所有工作就是对基本NFA的组合了。基本NFA将在算法讲解部分介绍,注意我们还会介绍两个特殊的NFA:空字符E基本NFA(作状态的连接)、闭包’*'复合NFA(识别模式的一种特殊结构)。
3.算法讲解(Thompson算法)
功能:从正规式构造一个可以识别它的NFA。
输入:字母表上的正规式r。
输出:接收L(r)的NFA N。
原理:将基本NFA按照r中正规式的组合顺序组装起来,得到一个冗余的NFA。注意空状态转移E的灵活使用。
以下状态中,s0是初态,f是终态。
基本NFA:
- 基本NFA1——识别空字符E:输入一个空字符e就到终态,识别完成。
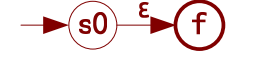
这个NFA其实没有做任何事:状态s0和状态f是同一个状态。它唯一的作用就是使模式的状态转换图结构更加清晰,这是在考虑我们人类的感受。
- 基本NFA2——识别单字符a:输入一个字符a就到终态,识别完成。
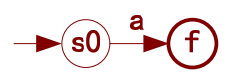
这是最基础的NFA,负责识别字母表中的每一个字符。没有它,一切只是摇摇欲坠之高楼广厦。
- 基本NFA3——识别符号或’|‘:只要输入中有任意一个预期字符(串),就到终态,完成识别。
名词解释:N(P)和N(Q)都是一个NFA。它们可以很简单,只是上文提及的的基本NFA1、基本NFA2(识别一个字符);也能很复杂,是许多个NFA的任意组合(识别一个字符串)。但不管怎样,是NFA就对了。你懂我意思吗?下文同义。
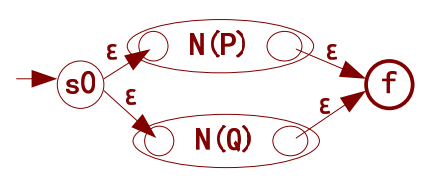
这个NFA负责”或“操作,可以识别出不同的”字符(串)“。
- 基本NFA4——识别符号与’.‘:输入连续的两个预期字符(串),到达终端,完成识别。
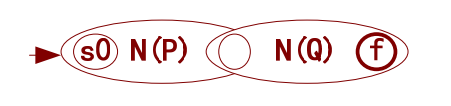
这个NFA负责字符(串)的拼接,它能完成对广泛延申的字符模式的识别。
- 复合NFA5——识别闭包*:输入0或无穷多个预期字符(串),可以到达终态,此时完成识别。
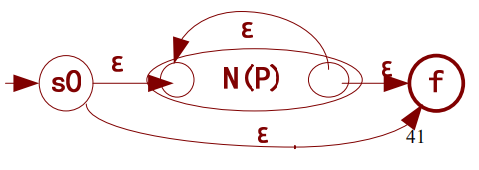
比如对于a*,这个闭包NFA识别:空字符E、a、aa、aaa、aaaaaaaaaa……。
这以后,所有的构造工作都是对以上几个NFA进行递归组装了。