#pic_center =400x
系列文章:
情形1全文替换
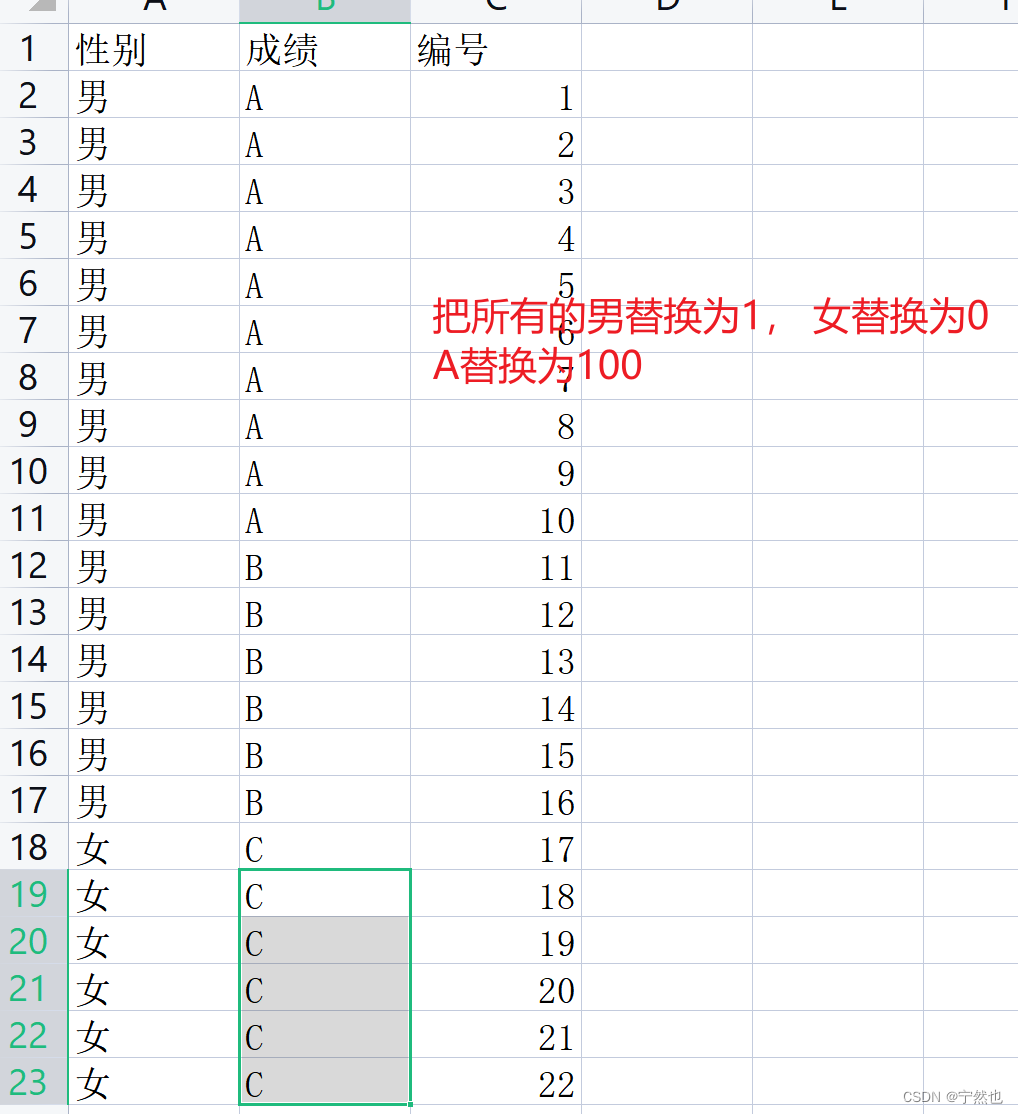
需要进行数据分析,里面包含中文等,需要将它转换为纯数字形式(其他形式也可以的)
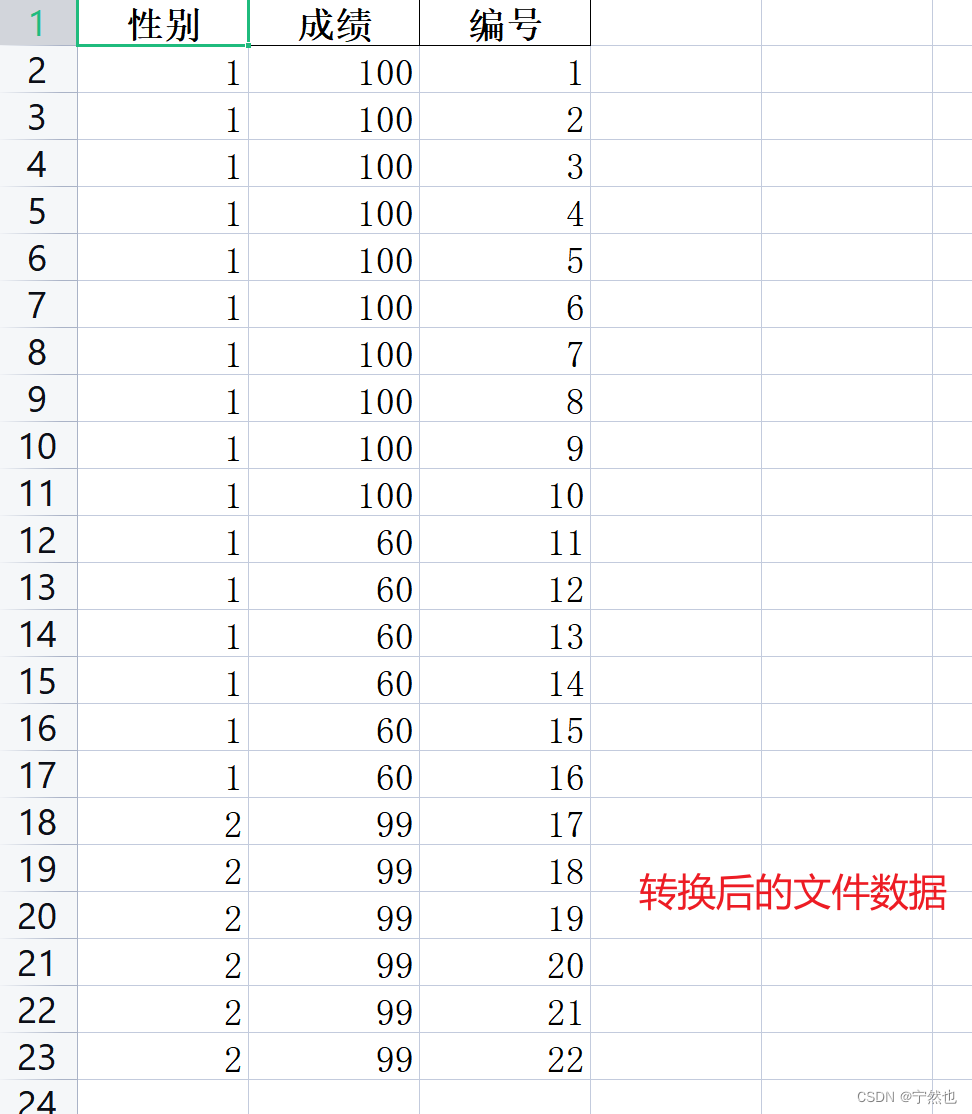
结果如图,这个比如成绩中有男也会替换。如果指定列替换看情形2
代码
import pandas as pd
import xlsxwriter
# 源文件
sourceFile = "C:\\Users\\ytm\\Desktop\\result\\dataSets\\源数据.xlsx"
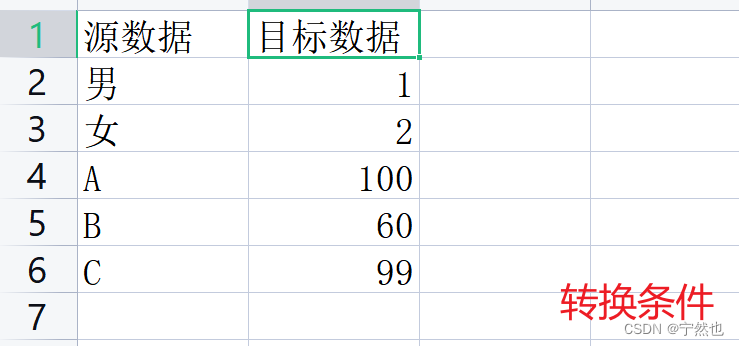
# 转换条件
conditionTransFile = "C:\\Users\\ytm\\Desktop\\result\\dataSets\\转换条件.xlsx"
#用来存储转换条件的字典 k-v形式
dic = {
}
# 读取转换条件
conditionTrans = pd.read_excel(conditionTransFile)
print(conditionTrans)
# 获取panda的DataFrame格式数据的值
value = conditionTrans.values
# 获取行列数,这里的行是转换条件的个数, 列就是2(源数据和目标数据)
row ,col = value.shape
for i in range(0, row):
print(value[i][0], value[i][1])
# 转换条件数据装入字典,也可用其他数据形式如列表
dic[value[i][0]] = value[i][1]
# 读取源文件数据,是DataFrame格式
sourceData = pd.read_excel(sourceFile)
for i in dic:
v = dic[i]
print(i, v)
# 替换数据
sourceData.replace(i, v, inplace=True)
print(sourceData)
# 替换后数据保存为文件, index为False是不将行号写入excel
sourceData.to_excel("C:\\Users\\ytm\\Desktop\\result\\dataSets\\转换后文件.xlsx", index=False)