Python:numpy




Pandas:
Series:

两种创建Series的方式 

变了说明 numpy创建的arr是引用对象
它改变了值以后 Series里面的值也会随之改变
Series的访问:







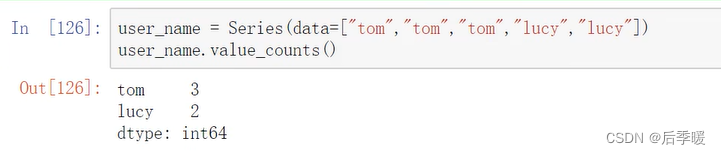

上面NaN加上数字还是NaN 想要保留原来a的值 那么就要用到add这种 然后fill_value变成0 所以下面那句准确的说是保留value


Dataframe


Series转为dataframe:





两列以上要两个中括号




iloc是隐式索引 loc就是行索引和列索引


所以怎么列切片呢?

用隐式索引切片:

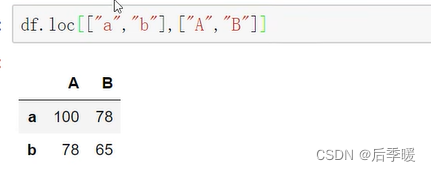
练习:多种方式拿到A列和C列:

读取AB两列 ab两行

求arr每一行的和或者是平均这些就是axis=1 列就是axis=0

用每一行的填充空值



构建层级索引 product类似于笛卡尔积 上半年分别乘与下面三个 再分别乘与第二组的三个


新增一列:wencha列 第一种方法:


这个就是count









然后能直接调用string的slice来截取嘛 答案是不行 还要str一次
![]()
merge关联表:

下面是各种连接 如果连接字段重名 则可以省略这个参数
left和right都是df名 也就是表名

切记 这里的A、B、C...不是行索引 因为这里是在创建dataframe 所以其实是列索引



















![]()

多层索引:下面是根据公司和日期分组 所以公司和日期这两列不是真的列 是索引



reset就是把索引变成普通的列



