最近ChatGPT大火,简单整理了一些文章和帖子。
ps.此时ChatGPT还没公布相应的论文,所有以下内容为官网发布内容,以及一些合理的推测。
InstructGPT
相比于GPT,2022年初推出的InstructGPT在某种程度上更像是ChatGPT的“直系前辈”。因为InstructGPT大量的使用到了人类反馈与指导,在大力出奇迹的GPT3的基础上,更加的进一步精调,使得InstructGPT的输出更加的可控,也就是跟人类习惯更加贴近了。
对于这项工作,OpenAI 表示:“我们成功训练出了在遵守用户意图方面比 GPT-3 显著更强的新语言模型,并且同时确保这些模型更加诚实,减少了有害结果的生成。具体来说,我们采用了在对齐 (alignment) 研究当中掌握的技术,使得这些训练结果成为可能”。
新的模型名为 InstructGPT(instruct 是指导的意思),意即和一般模型训练的自我监督模式不同,这次在新模型的训练当中,OpenAI 重度使用了人类作为“教师”的身份,对模型训练进行反馈和指导。从人类反馈中进行强化学习的过程,称为reinforcement learning from human feedback,简称 RLHF。这个也是使ChatGPT变得特殊的秘密武器(也许~)。
人类的监督即为,每一次GPT的反馈都会交由数据标记员评估,他们对不同 GPT模型版本生成的结果进行打分并优化参数,最后训练得到的即为InstructGPT。
RLHF
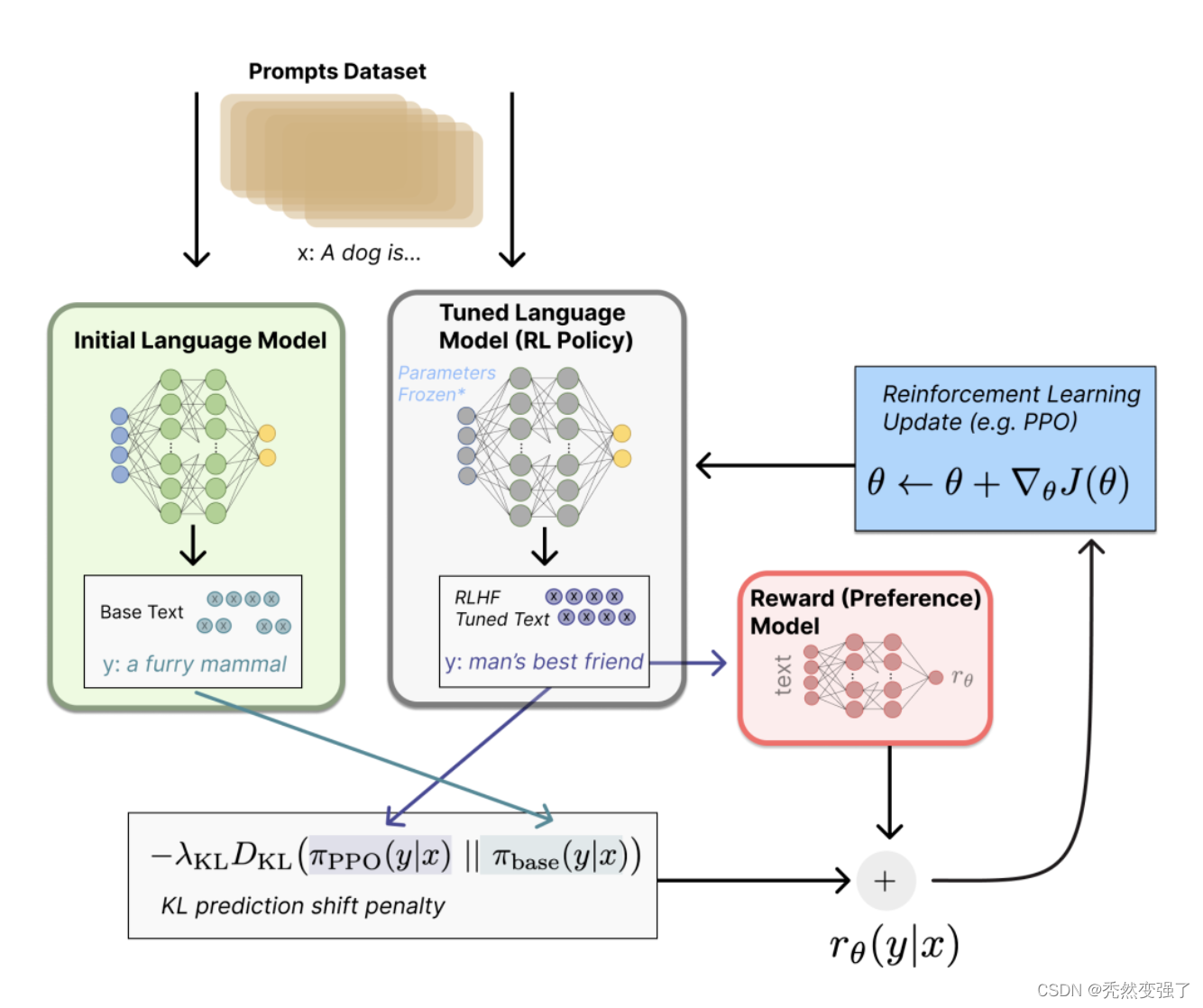
在通过语言模型实现下游任务的过程中,如生成对话任务,在使用token级别的loss以外,我们还会使用评估整体文段输出的指标,人们往往用BLEU或ROUGH等评价指标来刻画模型输出与人类偏好的相近程度,但这也仅仅是在评价的层面,模型在训练的时候是见不到这些人类真实的偏好的。因此,训练阶段,如果直接用人的偏好(或者说人的反馈)来对模型整体的输出结果计算reward或loss,显然是要比上面传统的“给定上下文,预测下一个词”的损失函数合理的多。基于这个思想,便引出了本文要讨论的对象——RLHF(Reinforcement Learning from Human Feedback):即,使用强化学习的方法,利用人类反馈信号直接优化语言模型。
RLHF的训练过程可以分解为三个核心步骤:
- 预训练语言模型(LM):如InstructGPT使用了标准的预训练GPT3
- 收集数据并训练奖励模型:奖励模型reward model的目标是刻画模型的输出是否在人类看来表现不错。通过已有的Prompt训练奖励模型,奖励模型可以看做一个判别式的语言模型,因此我们可以用一个预训练语言模型热启,而后在 [x=[prompt,模型回答], y=人类满意度] 构成的标注语料上去微调。
- 通过强化学习微调 LM:我们将初始语言模型的微调任务建模为强化学习(RL)问题,因此需要定义策略(policy)、动作空间(action space)和奖励函数(reward function)等基本要素。显然,策略就是基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布);而动作空间就是词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选);观察空间则是可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合;而奖励函数则是基于上一章节我们训好的RM模型,配合一些策略层面的约束进行的奖励计算。
如上图所示,标注人员的任务则是对初始语言模型生成的文本进行排序。有人可能会奇怪,为啥不直接让标注人员对文本进行打分呢?这是因为研究人员发现不同的标注员,打分的偏好会有很大的差异(比如同样一段精彩的文本,有人认为可以打1.0,但有人认为只能打0.8),而这种差异就会导致出现大量的噪声样本。若改成标注排序,则发现不同的标注员的打分一致性就大大提升了。一种比较有效的做法是“pair-wise”,即给定同一个prompt,让两个语言模型同时生成文本,然后比较这两段文本哪个好。奖励模型的训练流程:
计算得到奖励reward:首先,基于前面提到的预先富集的数据,从里面采样prompt输入,同时丢给初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2。然后用奖励模型RM对y1、y2打分,判断谁更优秀。显然,打分的差值便可以作为训练策略模型参数的信号,这个信号一般通过KL散度来计算“奖励/惩罚”的大小。显然,y2文本的打分比y1高的越多,奖励就越大,反之惩罚则越大。这个reward信号就反映了文本整体的生成质量。
以上摘自:https://mp.weixin.qq.com/s/hm_bbVebSF4JudctCsiRcA
ChatGPT 更进一步
此外,ChatGPT 的强大还依赖于一项秘密武器 —— 一种名为 RLHF(人类反馈强化学习)的训练方法。
大家可以看到ChatGPT的官方示意图跟InstructGPT非常相似。在一定程度上也证明了InstructGPT与之的关系,其实就是一脉相承的,只是在一些细节上进行了修改。

所以当然训练数据的变化应该更大更有影响力。
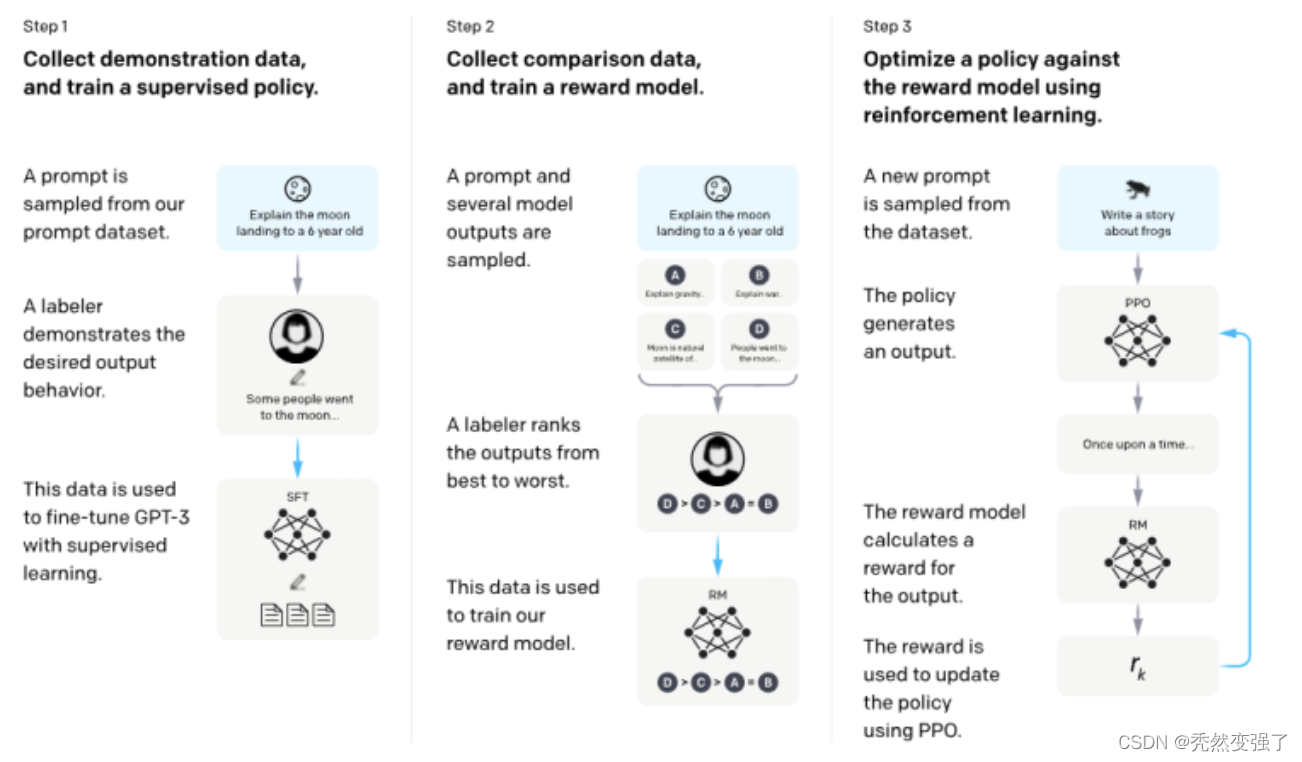
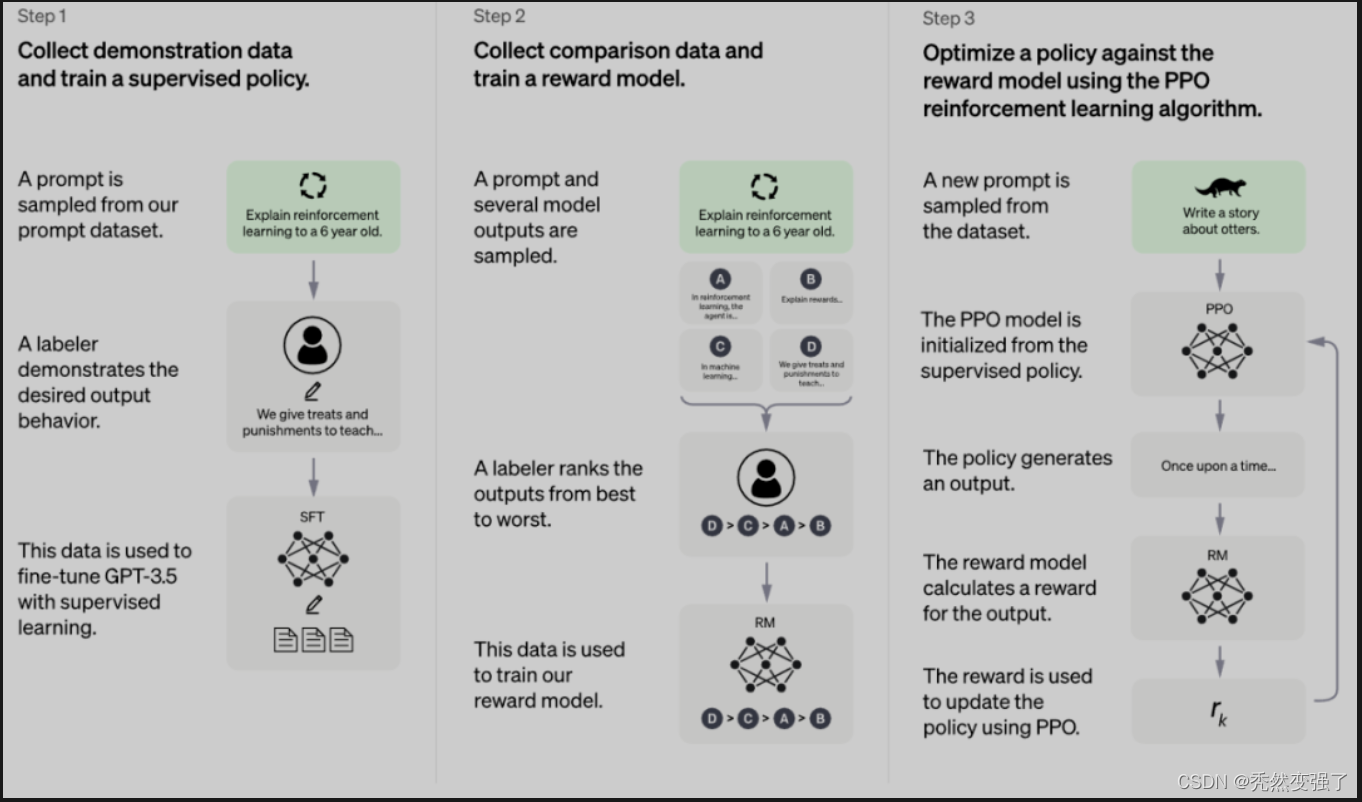 根据 OpenAI 官方公布的资料,这种训练方法主要也有三个阶段:
根据 OpenAI 官方公布的资料,这种训练方法主要也有三个阶段:
- 冷启动阶段的监督策略模型:从测试用户提交的 prompt 中随机抽取一批,靠专业的标注人员,给出指定 prompt 的高质量答案,然后用这些人工标注好的 < prompt,answer > 数据来 Fine-tune GPT 3.5 模型,从而让 GPT 3.5 初步具备理解指令中蕴含的意图的能力;
- 训练回报模型(Reward Model,RM):随机抽样一批用户提交的 prompt,然后使用第一阶段 Fine-tune 好的冷启动模型为每个 prompt 生成 K 个不同的回答,再让标注人员对 K 个结果进行排序,以此作为训练数据,通过 pair-wise learning to rank 模式来训练回报模型;
- 采用强化学习来增强预训练模型的能力:利用上一阶段学好的 RM 模型,靠 RM 打分结果来更新预训练模型参数。可以观察到使用RLHF仍然是被声明为关键环节。
关于RLHF在整个训练过程中到底起了多大作用,我个人比较喜欢张俊林老师的这段话“尽管如此,我觉得第三阶段采用强化学习策略,未必是ChatGPT模型效果特别好的主要原因。假设第三阶段不采用强化学习,换成如下方法:类似第二阶段的做法,对于一个新的prompt,冷启动模型可以产生k个回答,由RM模型分别打分,我们选择得分最高的回答,构成新的训练数据<prompt,answer>,去fine-tune LLM模型。假设换成这种模式,我相信起到的作用可能跟强化学习比,虽然没那么精巧,但是效果也未必一定就差很多。第三阶段无论采取哪种技术模式,本质上很可能都是利用第二阶段学会的RM,起到了扩充LLM模型高质量训练数据的作用。”
实际上我的理解是,无论收敛是否用的是强化学习,其目的是为了引入忍得评价作为一种loss来干预模型的精调,那么无论是一般的token级的比对,还是对每一个输出进行排序打分,亦或是使用RLHF,都不过是一种实现方法,希望后续能有陆续的研究对该内容进行消融实验看看效果。别是消融试验一做,发现如transform一般,很多设置都是帮助不大的,改成MLP is all you need 也可以 \笑。
我的感悟:
- 不用恐慌:刚开始我自己没进行测评的时候,看帖子大家说 ChatGPT的短板的时候会说,ChatGPT不能看得懂脑筋急转弯,我当时还在想,那这不是说明ChatGPT已经很厉害很智能了嘛。但是当我自己进行测试,也阅读了很多测试帖子之后,还是明显能感觉到ChatGPT并没有大家说的那么夸张,无懈可击。相反,对于应用ChatGPT到现实生活中,实际上还是很有距离的。最好能把ChatGPT理解成一种工具,他不会直接反馈给你绝对正确的答案,但是能在一定程度上帮助你节约时间,减少工作量,就犹如最近大火的Diffusion model在绘画上面能给画师提供草稿一样,是需要具备一定专业知识的从业人员能利用好的工具,而不是随便来个人加上ChatGPT就可以抢工程师饭碗了。但是在这个基础上,我们可以说ChatGPT的确是能改变某些行业的生态的。
- ChatGPT也有短板:在基于 RLHF 范式训练模型时,人工标注的成本是非常高昂的,而 RLHF 性能最终仅能达到标注人员的知识水平。
- 合理的认识ChatGPT带来的技术优化:实际上并没有啥突破性的技术进展,但是得到了比较不错的效果。
- 数据:数据应该是ChatGPT成功很大程度依赖一个关键因素,首先是人工标注的有监督学习的数据,根据内容编写prompt来得到的。回报函数模型的训练也同样依赖标注者的人工排序。这些不仅需要大量的人力,同时对人工标注的成熟度,准确度也有很大要求,并不容易复现。
- 对于非常拿手的写代码,Stack overflow表示:关于 Stack Overflow 为何禁用 ChatGPT,官方表示:「我们正在试图阻止 ChatGPT 随机编造,现阶段让其与当前技术保持平衡是很棘手的主要问题在于,虽然 ChatGPT 产生的答案错误率很高,但我们很难看出来它哪里错了。」这会造成问题回答鱼目混珠的情况,\摊手手
参考文章,部分内容截取自:
【1】OpenAI 拾回初心?总爱乱讲话的GPT-3终于懂事了
【2】台大資訊 深度學習之應用 | ADL 17.2: OpenAI InstructGPT 從人類回饋中學習 ChatGPT 的前身
【3】抱抱脸:ChatGPT背后的算法——RLHF | 附12篇RLHF必刷论文
【4】张俊林:由ChatGPT反思大语言模型(LLM)的技术精要
【5】ChatGPT的前世今生
【6】张俊林:ChatGPT会成为下一代搜索引擎吗
【7】前沿重器[31] | 理性聊聊ChatGPT