ChatGPT
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
从ChatGPT”方法“原文可以看出,其使用的网络模型来自GPT-3.5,其原始模型在2022年已经训练完成,之后使用InstructGPT中的方法进行微调。 鉴于ChatGPT的论文还没有发表,故了解InstructGPT的实现对理解ChatGPT大有帮助。
Training language models to follow instructions with human feedback(InstructGPT)
1. “有害”信息
因为GPT的训练数据集非常大,故其中一定会包含很多的”有害“信息。例如:种族歧视、性别歧视以及违法暴力等。对于一个NLP模型来说,其本身不知道这些信息在人类社会是有害的。因此,对于训练好的GPT模型需要进行人为的引导来告诉它什么是对的,什么是错的。InstructGPT中通过人类反馈在原有GPT模型上做微调实现了人类的意图与NLP之间的契合。
2. RLHF—reinforcement learning from human feedback
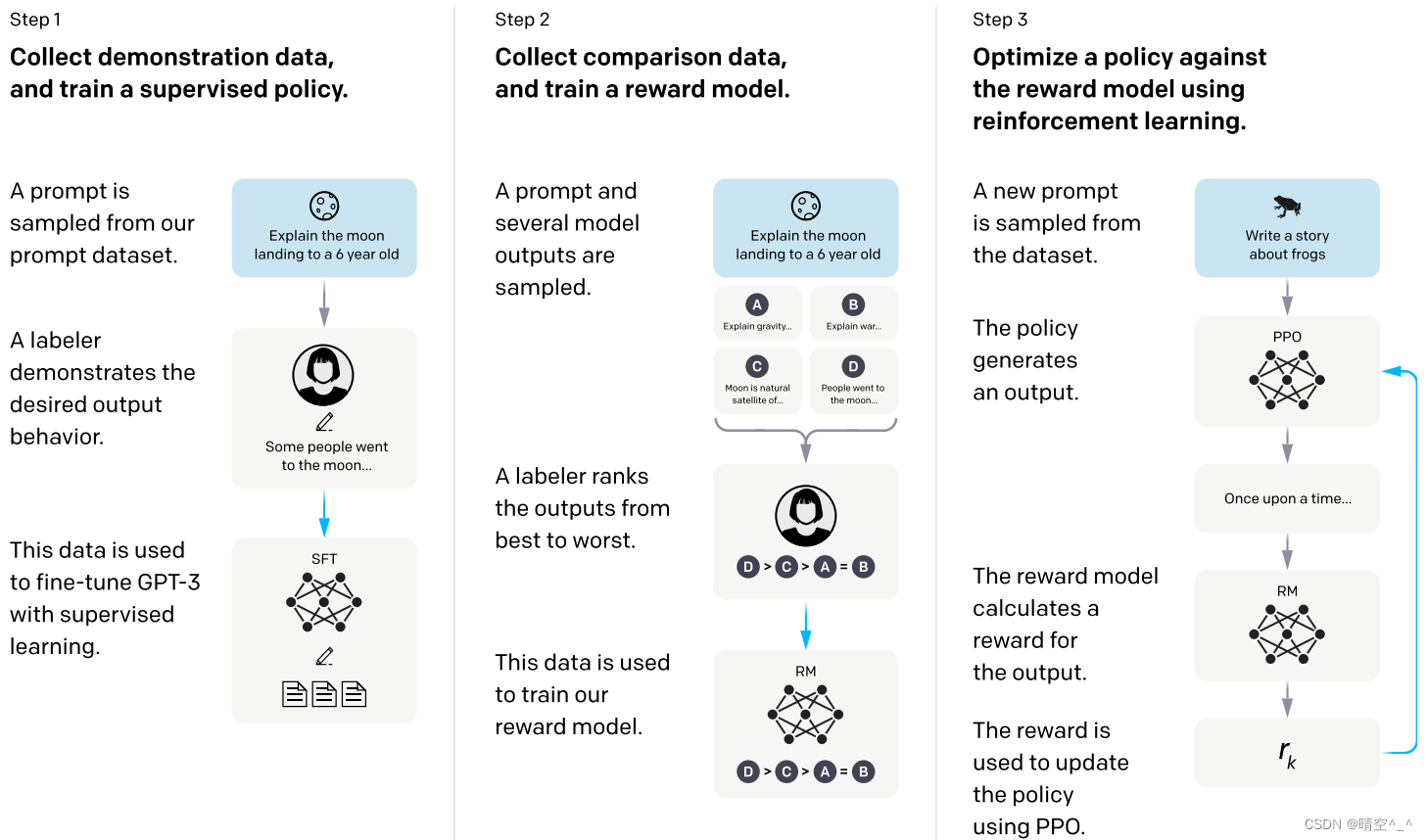
如图,InstructGPT的微调分为三个阶段:
第一阶段:手动选择问题并给出答案,对SFT做有监督学习
- 首先标注员提出问题(prompt)
- 标注员对提出的问题作出合理的解释(output)
- 使用监督学习的方法利用1、2收集到的“prompt-output”数据对SFT做微调。
第二阶段:让训练好的SFT模型回答一些问题,人工对这些问题排序。之后利用这些数据训练一个RM模型对回答的结果进行打分。
- 首先由标注员向模型输入一个问题(prompt)
- 之后模型会输出不止一个答案(如图为A、B、C和D,类似于beam search方法)
- 标注员对这些答案做排序(如图为D>C>A=B)
- 由1、3得到的数据集训练一个RM模型,其作用是对输出的答案排序。
第三阶段:如图,根据RM模型的打分结果代替人工来继续优化SFT模型
由微调过程可以看到需要大量的标注员。
3. 三个模型
-
SFT—Supervised fine-tuning
利用监督学习方法对GPT模型做微调。
-
RM—Reward modeling
对SFT模型做更改,将最后的softmax层改为一个线性层,将所有词的输出投影到一个值上面作为output的分数。可以理解成为GPT加了一个下游任务。
之后,训练一个RM模型,大小比SFT要小很多,主要任务是对SFT输出的值打分(输出标量奖励)。
损失函数Pairwise Ranking Loss:
l o s s ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ l o g ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ] loss(\theta ) = - \frac{1}{\binom{K}{2} } E_{(x, y_w, y_l) \sim D} [log(\sigma (r_\theta (x, y_w)-r_\theta(x, y_l) )] loss(θ)=−(2K)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl))]
对于输入 x x x,取出一对 y w y_w yw和 y l y_l yl答案。假设 y w y_w yw的排序比 y l y_l yl要高,将两个答案分别放入 r θ r_\theta rθ奖励模型中算出奖励分数。因为 y w y_w yw的排序比 y l y_l yl的高,故前者的奖励分数比后者要高,在此使用逻辑回归的方法使两者的差越大越好。其中 σ \sigma σ代表sigmod函数。对于每个prompt有9个output,故一共有 ( 9 2 ) = 36 \binom{9}{2}=36 (29)=36种选择方法。
-
RL—Reinforcement learning
使用PPO方法。
在 RL 训练中最大化以下组合目标函数:
o b j e c t i v e ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r ϕ ( x , y ) − β l o g ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ] + γ E x ∼ D p r e t r a i n [ l o g ( π θ R L ( x ) ) ] objective(\phi ) = E_{(x, y) \sim D_{\pi^{RL}_ \phi}}[r_\phi(x, y) - \beta log(\pi_\phi^{RL}(y | x)/\pi^{SFT}(y|x)] + \\ \gamma E_{x \sim D_{pretrain}}[log(\pi^{RL}_ \theta (x))] objective(ϕ)=E(x,y)∼DπϕRL[rϕ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x)]+γEx∼Dpretrain[log(πθRL(x))]
其中: π ϕ P L \pi_{\phi}^{PL} πϕPL是学习到的奖励策略, π S F T \pi^{SFT} πSFT是第一步得到的SFT模型, D p r e t r a i n D_{pretrain} Dpretrain是预训练的分布。 KL 奖励系数 β \beta β和预训练损失系数 γ \gamma γ 分别控制 KL 惩罚和预训练梯度的强度
该模型还尝试将预训练梯度混合到 PPO 梯度中,以修复公共 NLP 数据集上的性能回归。 称这 些模型为“PPO-ptx”。对于“PPO”模型, γ \gamma γ设置为0,InstructGPT中 γ \gamma γ不为0。
4. 总结:四个阶段—GPT的“社会化”过程
-
学习文字接龙:
GPT-3通过无监督学习进行序列到序列的生成。
-
人类引导文字接龙的方向:
使用人工标注的prompt-output数据集对GPT-3进行微调生成SFT。
-
模仿人类的喜好:
训练一个RM模型使其学习人类的喜好并输出一个分数。
-
用增强学习向模拟老师学习:
利用增强学习的技术使用RM模型对SFT进行微调。
GPT从第1阶段开始在大量的数据集中学习知识,此时GPT像一个孩子一样想到什么就说什么。在2、3和4阶段中,人类一步一步引导GPT说出适合人类社会的答案以及规避“有毒”的答案使其逐渐融入人类社会,并最终实现了令人惊艳的效果。