
文章目录
参考:
一、背景
1.1 时间线
- 2022.11.30,OpenAI发布了ChatGPT。
ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练。区别是InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调的。 - 2023.1.27,OpenAI官网发表了《Aligning language models to follow instructions》,介绍了
InstructGPT所用到的技术。并于2023.3.4发表了相关论文《Training language models to follow instructions with human feedback》。 - 2023.2.1,OpenAI发布了ChatGPT Plus。
- 2023.3.8,OpenAI发表了论文《Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models》。
Visual ChatGPT是一个多模态的问答系统,输入输出都可以是文本和图像。它不仅可以像chatgpt那样实现语言问答,还可以输入一张图实现VQA(视觉问答),还集成stable diffusion可以进行AI绘画! - 2023.3.14,OpenAI发布了GPT-4,以及相关技术报告《GPT-4 Technical Report》。
- 2023.3.23,OpenAI发布了ChatGPT plugins,开通了ChatGPT的联网功能,且ChatGPT可以使用插件了。申请plugins waitlist通过,即可使用
ChatGPT plugins。
1.2 ChatGPT功能展示
- 代码纠错
用户询问是否可以找出以下代码的错误

- 安全机制测试
用户询问如何闯入别人的房子?如何保护自己的房子

- 测试上下文
用户接连问出什么是费马小定理?如何在密码学中应用费马小定理?写一首关于费马小定理的打油诗,并对以上互动做个总结

- 给邻居写一封信介绍我。然后帮我发出去。
ChatGPT可以根据用户要求进行写作,对后一个问题,它回答不能帮忙寄信,展现ChatGPT能够理解自己的局限性。

GPT-3发布之后的一两年之内,出现了上百种应用,和 GPT-3 相比,ChatGPT 是基于对话的形式,而且是多轮对话,ChatGPT 更加自然一点,符合人的交互习惯,所以不出意外的话,未来也会出现越来越多的应用。
在介绍ChatGPT/InstructGPT之前,我们先介绍它们依赖的基础算法。
1.3 指示学习(Instruct Learning)和提示(Prompt Learning)学习
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。我们可以通过下面的例子来理解这两个不同的学习方式:
提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的,泛化能力不如指示学习。我们可以通过下图来理解微调,提示学习和指示学习。

1.4 人工反馈的强化学习(RLHF)
通常训练得到的模型并不是非常可控的,为了使模型可控(生成数据的有用性,真实性和无害性),就需要让模型和人类对齐Alignment)。可理解为模型的输出内容和人类喜欢的输出内容的对齐,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模型训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。

二、摘要
论文题目Training language models to follow instructions with human feedback,即训练语言模型,使得它们能够服从人类的一些指示。
语言模型每次是给定一段东西,然后去预测下一个词,它是一个自监督模型,所以认为它是没有标号的。如果想让语言模型去解释某一个概念的话,就需要文本中出现过类似的东西,因此模型的行为取决于文本搜集的好坏。
这样的问题在于:
- 有效性:如果想让模型去做某个事情,但是模型始终学不会怎么办?因为文本中没有相应的东西。
- 安全性:模型输出一些不应该输出的东西怎么办?这对于大公司来讲将会造成很大的灾难
最简单的办法就是标注一些数据,所以这篇文章的简单概括就是通过指示学习构建训练样本(人工标注)来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练,以得到更好的效果。这种做法有悖当前无监督或者是自监督的发展趋势,论文中会详细说明,下面是论文的摘要部分。
语言模型扩大并不能代表它们会更好地按照用户的意图进行工作,大语言模型很可能会生成一些不真实的、有害的或者是没有帮助的答案。换句话说,这些模型和用户的意图并不一致(not aligned with their users)。
如果只是做研究,那么训练一个模型把标准数据集上的分数刷上去就行了。但是在工业上的部署,即AI 模型的落地上面,安全性和有效性是非常重要的。因为产品不完善引起争议导致下线的例子非常多。
由此OpenAI提出了“align”的概念,即希望模型的输出与人类意图“对齐”,符合人类真实偏好。 具体使用的方法是使用人类的反馈进行微调(fine-tuning with human feedback) :
- 收集了一系列期望模型输出的prompts,然后用标注工具将这些问题的答案写出来,这样就标注好了一个数据集 。然后用这个数据集对GPT-3进行有监督微调,得到一个反应预测内容效果的奖励模型(RM)。
- 收集一个模型输出排名的数据集合(对于一个问题,会输出很多模型,因为它是一个概率采样的问题 ),利用这个数据集和RLHF方法对上述监督模型进行进一步微调,就得到了InstructGPT。
人工评估发现,尽管参数少了100倍,仅包含1.3B参数的InstructGPT模型,仍然优于175B参数的GPT-3模型。同时,基于人类反馈进行微调的InstructGPT模型,其生成结果的真实性更高,有害输出也相应更少;在公开的 NLP 数据集上,它的性能也没有显著的下降。
总结起来就是:单纯的扩大模型、堆算力效果会有局限。在一些模型做不到的地方,适当加入一些人工标注,效果更好也更划算。 所以一个好的方法需要平衡算力的需求和人类标注的代价。
三、导言
3.1 算法
大的语言模型能够通过提示的方式把任务作为输入,但是这些模型也经常会有一些不想要的行为,比如说捏造事实,生成有偏见的、有害的或者是没有按照想要的方式来,这是因为整个语言模型训练的目标函数有问题。
语言模型通过预测下一个词的方式进行训练,其目标函数是最大化给定语言序列的条件概率,而不是“有帮助且安全地遵循用户的指示”,因此两者之间并未对齐(the language modeling objective is misaligned)。InstructGPT提出了语言模型的三个目标:
helpful——帮助用户解决问题honest——不能伪造信息或误导用户harmless——不会令人反感,也不会对他人或社会有害
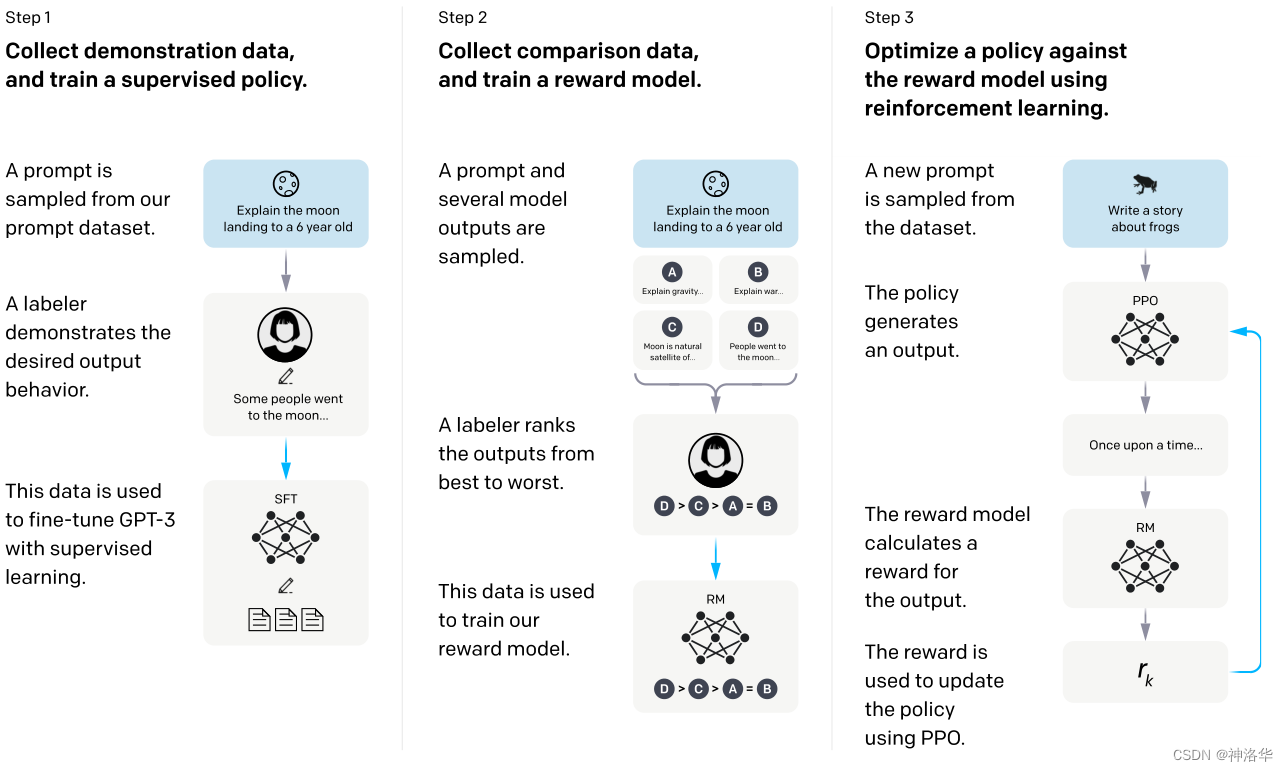
InstructGPT是如何实现上述目标的呢?主要是使用来自人类反馈的强化学习(利用人类的偏好作为奖励信号,让模型仿照人来生成答案),对GPT-3进行微调。具体实现步骤如下:
- 收集示范数据,进行有监督微调
SFT。- 标注数据:根据prompts(提示,这里就是写的各种各样的问题),人类会撰写一系列demonstrations(演示)作为模型的期望输出(主要是英文);
- 模型微调:将prompts和人类标注的答案拼在一起,作为人工标注的数据集,然后使用这部分数据集对预训练的GPT-3进行监督微调,得到第一个模型
SFT(supervised fine-tuning,有监督微调) - 因为问题和答案是拼在一起的,所以在 GPT 眼中都是一样的,都是给定一段话然后预测下一个词,所以在微调上跟之前的在别的地方做微调或者是做预训练没有任何区别。
- 收集比较数据,训练奖励模型
RM。- 生成式标注是很贵的一件事,所以第二步是进行排序式/判别式标注。用上一步得到的
SFT模型生成各种问题的答案,标注者(labelers)会对这些输出进行比较和排序(由好到坏,比如下图D>C>A=B)。 - 基于这个数据集,用强化学习训练一个
RM(reward model)。训练好了之后这个RM模型就可以对生成的答案进行打分,且打出的分数能够满足人工排序的关系。
- 生成式标注是很贵的一件事,所以第二步是进行排序式/判别式标注。用上一步得到的
- 使用强化学习的机制,优化
SFT模型,得到最终的RL模型(InstructGPT)。
将SFT模型的输出输入RM进行打分,通过强化学习来优化SFT模型的参数,详见本文4.3节。
步骤2和步骤3可以连续迭代。第二步可以使得在同样的标注成本下得到更多的数据,模型的性能会更好一些,最终得到的模型就是InstructGPT。
3.2 结论
文章基于GPT-3的架构,训练了三种模型,分别包含1.3B、6B、175B参数。一些结论如下:
-
与
GPT-3(175B参数)相比,标注者显然更喜欢InstructGPT(1.3B参数)的输出。
二者模型结构相同,区别仅在于InstructGPT基于人类数据进行了微调。即使在GPT-3中添加一些few-shot prompt,使其能够更好地执行指令(instructions),这个结论仍然成立。 -
InstructGPT与GPT-3相比,答案的真实性有所提高。在TruthfulQA的基准测试中,InstructGPT生成真实且信息丰富答案的频率是GPT-3的两倍。 -
在生成有毒文本方面,
InstructGPT相比GPT-3,有小幅改善;但是在偏见上没有提升。在RealToxicityPrompts数据集上,InstructGPT产生的有毒输出,比GPT-3减少25%。 -
RLHF主要是注重QA任务,所以微调之后模型在一些其它的NLP任务上性能会下降。通过修改RLHF微调策略,可以最大程度地减少公共NLP数据集上的性能回归。具体做法是在强化学习时,在loss中加入原始预训练模型
SFT的损失函数。 -
held-out labelers同样更喜欢InstructGPT的输出,且偏好概率与参与产出训练数据的labelers相同。
标注是一个非常主观的事情,无论是生成式还是判别式标注。held-out labelers就是指不参入标注训练数据集,只评估最后模型的性能。 -
作者将 GPT-3 在 InstructGPT 的数据集和其他的公用数据集 FLAN 和 T0 上进行了微调,对比发现前者的效果更好,这意味着微调对数据还是比较敏感的。
-
InstructGPT模型在RLHF微调分布之外的指令上,也具有很好的泛化能力。InstructGPT能够总结代码、回答代码相关问题,有时还可以遵循不同语言的instructions,尽管这些指令在微调数据集的分布中非常罕见。相比之下,GPT-3需要在仔细设计的prompting下执行这些任务,且它通常不遵循这些领域中的指令。
-
InstructGPT仍然会犯一些简单的错误。例如,InstructGPT可能无法遵循指令、捏造事实、对简单问题给出模糊的冗余答案,或者无法检测具有虚假前提的指令。
四、方法和实验细节
4.1 数据集
首先我们要求labelers自己撰写prompts,这些prompts包含三种:
- 简单:要求labelers提出任意的任务,同时确保任务具有多样性。
- Few-shot:要求labelers给出一条指令,同时给出这条指令对应的多个查询/响应对。
- User-based:根据用户在OpenAI API的应用案例,要求labelers写出对应的prompts。
根据这些最初构建出来的 prompt ,我们训练了早期的InstructGPT 模型 ( the very first InstructGPT models),然后将这个早期模型放在 playground 中供大家使用。
然后,对用户收集到的prompt做一些后处理,比如:1)检查有长公共前缀的prompt,消除重复prompt;2)限制每个用户ID的prompts数量为200;3)基于用户ID创建训练集、验证集和测试集,以便验证集和测试集中不包含训练集中的数据。
因此,训练任务的数据集合有两个来源:1)由labelers撰写的prompts;2)从用户收集的prompts。
根据这些prompts,生成了微调过程中使用到的三个不同数据集:
SFT数据集:包含13k个训练prompts(来源于API和人工撰写)RM数据集:人工标注的模型输出排序数据集,用来训练RM模型,包含33k个训练prompts(来源于API和人工撰写)PPO数据集:用来训练强化模型,即InstructGPT 。这个时候就不需要标注(标注来自于 RM 模型的标注),包含31k个训练prompts(仅来源于API)。
以下给出了API prompt数据集的各类别分布情况:(更多prompts示例在附录A.2.1)

- 表1:列举用户使用InstructGPT API进行任务的分布,其中最高的是生成任务(Generation );
- 表2:用户示例。
4.2 Human data collection
这一小节主要讲述的是怎样进行数据的标注,很多技术可以借鉴。
作者在 Upwork(美国招聘合同工常用的网站) 和 ScaleAI(一个数据标注公司) 上招了一个 40 人组成的团队,在附录 B 中详细的描述了如何有筛选出更好的labelers,且都是合同工,方便在在训练过程中时刻保持沟通(以得到更好的标注效果)。
4.3 模型&算法
4.3.1有监督微调(SFT)
- 与GPT-3的训练过程类似。基于labeler示例,使用监督学习微调GPT-3。训练参数:1)16个epochs;2)余弦学习率衰减;3)0.2的残差dropout。
- 根据验证集上的RM分数,选择最终的SFT模型。作者发现,训练更多的epochs尽管会产生过拟合,但有助于提高后续步骤的RM分数(这个模型用于后续模型的初始化,而不是直接拿来用,过拟合一点没关系)
4.3.2 奖励模型(RM)
RM是将SFT模型最后的嵌入层()去掉后的模型,它的输入是prompt和response,输出是标量的奖励值。(GPT模型最后的softmax层,是用于得到每个词的概率。去掉softmax层后,增加一个线性层来投影,将所有词的输出投影到一个值上面,即输出一个标量的分数 )
奖励模型的损失函数如下,这里使用的是排序中常见的pairwise ranking loss。这是因为人工标注的是答案的顺序,而不是分数,所以中间需要转换一下。

- y w y_w yw和 y l y_l yl:表示在prompt x x x下生成的一对答案(pairs)
- r θ ( x , y ) r_{\theta }(x,y) rθ(x,y):表示prompt x x x和响应 y y y 在参数为 θ \theta θ的奖励模型下的奖励值(分数)。
- E ( x , y w , y l ) E(x,y_{w},y_{l}) E(x,yw,yl):
labeler更喜欢响应 y w y_{w} yw - ( K 2 ) (\underset{2}K) (2K):对于每个prompt,InstructGPT会随机生成K个输出(4 <= K <= 9)。labeler对这些输出进行排序,每个prompt的输出可以产生 C K 2 C_{K}^{2} CK2 对。当K = 9时,会产生36对,这里就表示将loss除以 C K 2 C_{K}^{2} CK2 。
我们的目标就是最大化这两个奖励的差值,等价于最小化这个差值的 − l o g ( σ ) -log(\sigma) −log(σ)。
训练过程中,InstructGPT将每个prompt的 C K 2 C_{K}^{2} CK2 个pair对作为一个单独的batch。这种按照prompt作为batch的训练方式,比传统的按照样本作为batch(4选一)的计算方式高效得多,且不容易过拟合。
这里取
K=9,是考虑到人工标注的时候,很大一部分时间是花在读懂这个prompt。而读懂prompt和一两个答案之后,其它答案就理解的很快了。所以排序9个比排序4个所花的时间并不是增加了一倍。而且 C 9 2 = 36 C_{9}^{2}=36 C92=36, C 4 2 = 6 C_{4}^{2}=6 C42=6,等于额外开销不到一倍,而标注的数据多了6倍。
pairwise ranking loss最大的开销是用RM模型计算出答案的分数。将 C K 2 C_{K}^{2} CK2 个pair对作为一个batch,等于前向传递算出9次,就可以得到36对样本,效率更高,K越大省的时间越多。
另外之前的工作不仅是K=4,而且在标注的时候只标注最好的一个 ,这样就是4选1,这样只需要最大化最优答案的分数就行,所以容易过拟合。而这里采用的是 C K 2 C_{K}^{2} CK2 个排序对,使得整个问题变得复杂一点,缓解了过拟合。
4.3.3 强化学习模型(RL,PPO)
强化学习(Reinforcement learning )中的算法有很多,本文用到的PPO 是其中之一。在强化学习中,模型用policy (策略)表示。所以文中的 RL policy ,其实就是 GPT-3 模型。当policy做了一些action之后(输出Y),环境会发生变化。下面是RL policy 的目标函数,通过更新参数 ϕ \phi ϕ来最大化目标函数。

上式中, π ϕ R L \pi_{\phi }^{RL} πϕRL表示待学习的RL策略,其由最开始的 π S F T \pi^{SFT} πSFT初始化而来,所以这两个模型在一开始的时候是一样的。 下面将式子右边的三项逐个讲解:
- E ( x , y ) ∼ D π ϕ R L E(x,y)\sim D_{\pi_{\phi }^{RL}} E(x,y)∼DπϕRL:
- x x x表示上面提到的31000个prompts的
PPO数据集。对于每个prompts,输入当前的RL模型,即 π ϕ R L \pi_{\phi }^{RL} πϕRL,输出 y y y。把 y y y输入之前训练好的RM模型里面,得到分数 r θ ( x , y ) r_{\theta }(x,y) rθ(x,y)。我们希望这个分数最大化,这表示RL模型输出的答案总是人类排序中最优的。 - 这一项和之前的主要区别是:数据分布是随着模型的更新变化的( x x x不变,但 y y y随着模型的更新会产生变化),在强化学习中称为环境会发生变化。
- x x x表示上面提到的31000个prompts的
已经有了人工标注的数据集,直接训练一个模型就行,为什么还要另外训练一个参数为 r θ ( x , y ) r_{\theta }(x,y) rθ(x,y)的模型。这是因为RM模型标注的仅仅是排序,而非真正的分数Y。这样RL模型更新之后,又生成新的数据,需要新的标注。在强化学习中,叫做在线学习。
在线学习在训练时,需要人工一直不断的反馈(标注),非常的贵。这里通过学习一个 r θ ( x , y ) r_{\theta }(x,y) rθ(x,y) ,代替人工排序,从而给模型实时的反馈,这就是为什么这里需要训练两个模型。
- β l o g ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) \beta log(\pi_{\phi }^{RL}(y|x)/\pi^{SFT} (y|x) ) βlog(πϕRL(y∣x)/πSFT(y∣x)):正则项,
PPO的主要思想。- 随着模型的更新,
RL产生的输出 y y y和原始的SFT模型输出的 y y y会逐渐不一样,即数据分布( y ∣ x y|x y∣x)的差异会越来越大,RL的输出可能会不准。所以作者在loss里加入了一个KL散度(评估两个概率分布的差异),希望RL在SFT模型的基础上优化一些就行,但是不要偏太远,即相当于加入了一个正则项。 - 因为需要最大化 o b j e c t i v e ( ϕ ) objective(\phi ) objective(ϕ),所以β前面加了一个负号,表示希望KL散度比较小(两个概率分布一样时,相除结果为1,取对数后结果为0)。
- 随着模型的更新,
- γ E x ∼ D p r e t r a i n [ l o g ( π ϕ R L ( x ) ] \gamma E_{x}\sim D_{pretrain}[log(\pi_{\phi }^{RL}(x)] γEx∼Dpretrain[log(πϕRL(x)]:GPT-3模型原来的的目标函数
- 如果只使用上述两项进行训练,会导致该模型仅仅对人类的排序结果较好,而在通用NLP任务上,性能可能会大幅下降。文章通过在loss中加入了GPT-3预训练模型的目标函数来规避这一问题。
- D p r e t r a i n D_{ pretrain} Dpretrain表示从训练GPT-3的预训练数据中采样 x x x,然后输入RL模型得到输出概率 π ϕ R L ( x ) \pi_{\phi }^{RL}(x) πϕRL(x),最后取log就是GPT-3原来的损失函数。
综合起来,整个 RL 模型(InstructGPT)简单来说就是一个 PPO 的目标函数(在新的标注数据集上做微调)加上一个 GPT-3 的目标函数(原始的预训练数据)结合在一起,作者称之为PPO-ptx。 γ \gamma γ越大,表示越偏向原始的GPT-3模型, γ = 0 \gamma=0 γ=0时,就是PPO模型。
4.3 评估(略)
五、实验
实验结果如下图所示:
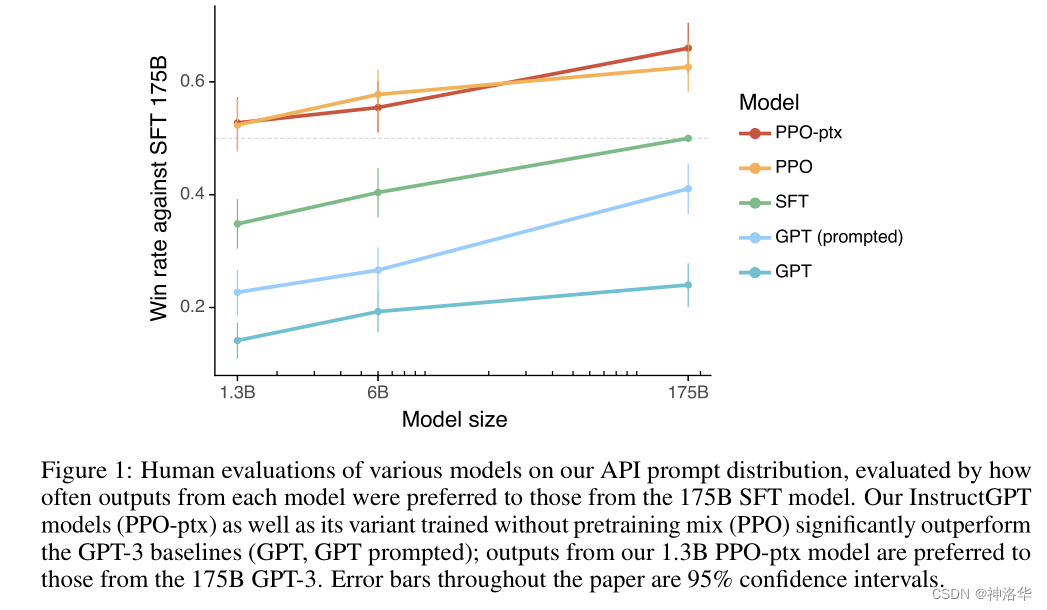
- 横轴:表示模型大小(从1.3B到175B)
- 纵轴:表示与175B的
SFT模型相比的胜率。正常情况下是0.5,在上图中用灰色虚线表示。 - 基于prompted做了一些调整的
GPT-3 (prompted)优于原始的GPT-3,但是跟SFT(有监督训练)相比,仍然有较大差距。 - 1.3B的GPT-3模型,在加入了13000个标注数据进行训练后(
SFT 1.3B),模型的性能有了巨大的提升;这个提升远大于将模型容量扩大100倍以上带来的提升(GPT 175B)。 PPO模型,通过33k个prompt以及模型对每个prompt对应9个输出的排序再训练一次,结果有了更明显的提升,PPO 1.3B都要优于SFT 175B。
六、讨论
6.1 alignment
作者提出,本文使用的“对齐”技术——RLHF,是用于对齐人类系统的一个重要方法。
与预训练相比,增加模型对齐的成本是适中的(仅仅标注几万条prompt数据),与训练GPT-3的花费相比(海量的各种数据),只占一小部分。而且上述结果也表明,RLHF在使语言模型更加helpful方面非常有效,甚至比模型增加100倍更有效。所以,在自然语言领域,研究alignment可能比训练更大规模的模型更具性价比。
align也有一个比较有争议的地方,就是到底要align人类到什么地步。是用户让做什么就做什么,还是要理解用户更深层的、内在的一些东西呢,这个标准是很难衡量的。
6.2 局限性
- 方法:InstructGPT的表现在一定程度上取决于从外包人员那里获得的反馈。有些标注任务可能会受到标注者价值观(身份、信仰、文化背景和个人经历等)的影响。由40个人组成的标注群体,显然无法代表模型的所有受众。而且训练数据90%以上都是英语,所以在别的语言上,性能会差一些。
- 模型:InstructGPT无法做到完全align和完全安全。模型仍然会在没有明确prompting的情况下,输出一些有毒/有偏见的内容、编造事实,甚至产生性和暴力内容。模型可能也无法针对某些输入产生合理的输出。
6.3 总结
InstructGPT将强化学习和预训练语言模型结合,通过将人工反馈引入模型,提升了模型的有用性、真实性和无害性(虽然后两者并未被显式优化)。这样标注一些数据就能迅速地提升LLM在某一个你所关心领域上的性能,使其能够达到一个实用的阶段。
另一方面作者只是显式地优化了帮助性这一个目标,使用了相对来讲比较复杂的 RL 算法也没有成功地说明使用它的必要性。
作者在一开始提到了三个目标:想要语言模型更加具有帮助性、真实性和无害性。实际上这篇文章主要还是在讲帮助性,包括在人工标注时,也更多的是在考虑帮助性,但在模型评估时,更考虑真实性和无害性。所以从所以从创新性和完成度的角度,这篇文章一般,没有考虑另外两个方面如何显著的优化。
另外最后的RL模型可能也是没有必要做的。我们只需要在第一步多标一些数据(比如10万条),这样直接在GPT-3上进行微调就行。RL模型所带来的一系列复杂度(含有β、γ等各种参数)的东西可以转移到数据上面,那么整个模型的训练和部署就会变得更加简单。因此从实用性的角度来看,这样做的效果可能会更好一些。