InstructGPT原理讲解及ChatGPT类开源项目
Generative Pre-Trained Transformer(GPT) 是OpenAI的提出的生成式预训练语言模型,目前已经发布了GPT-1、GPT-2、GPT-3和GPT-4,未来也将发布GPT-5。
最近非常火的ChatGPT是基于InstructGPT提出的,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示性学习(Instruction Learning) 和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF) 来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。
核心要点:
- 把语言模型变大并不代表是能够按照用户的意图来做事,这些模型与用户没有align
- AI模型落地,安全性和有效性很重要
- 如何将大模型与人类意图相结合。简单的方法是使用用户反馈的监督数据进行fine-tune。
- 我们期望语言模型是helpful、honest、harmless。
相关文献:
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
构建了一个数据集,用于评测helpful和harmless:https://github.com/anthropics/hh-rlhf。
本文以GPT-3.5为起始点,关注使用fine-tuning的方法来align用户意图和大模型预训练。采用Reinforcement Learning from Human Feedback(RLHF):
Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,人类反馈的强化学习过程如下所示:
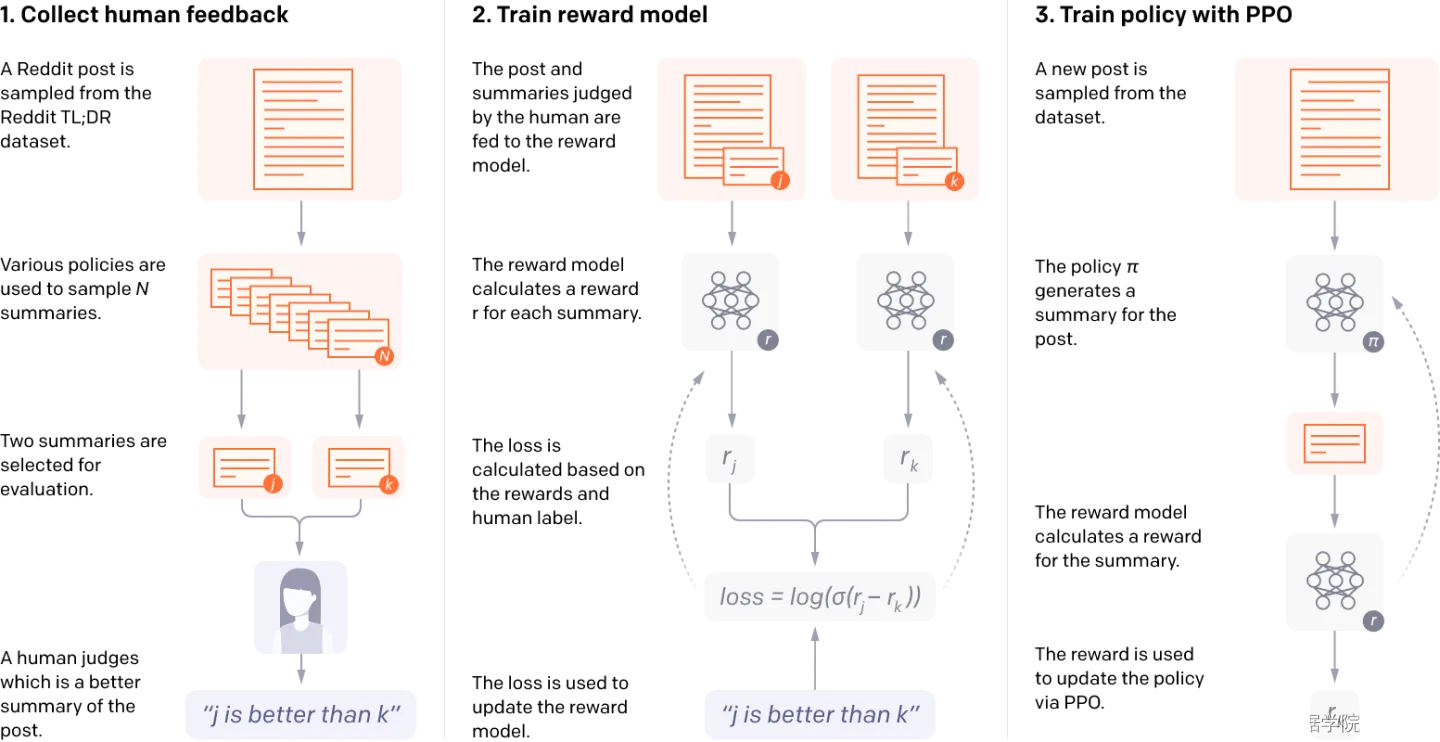
InstructionGPT的训练过程:
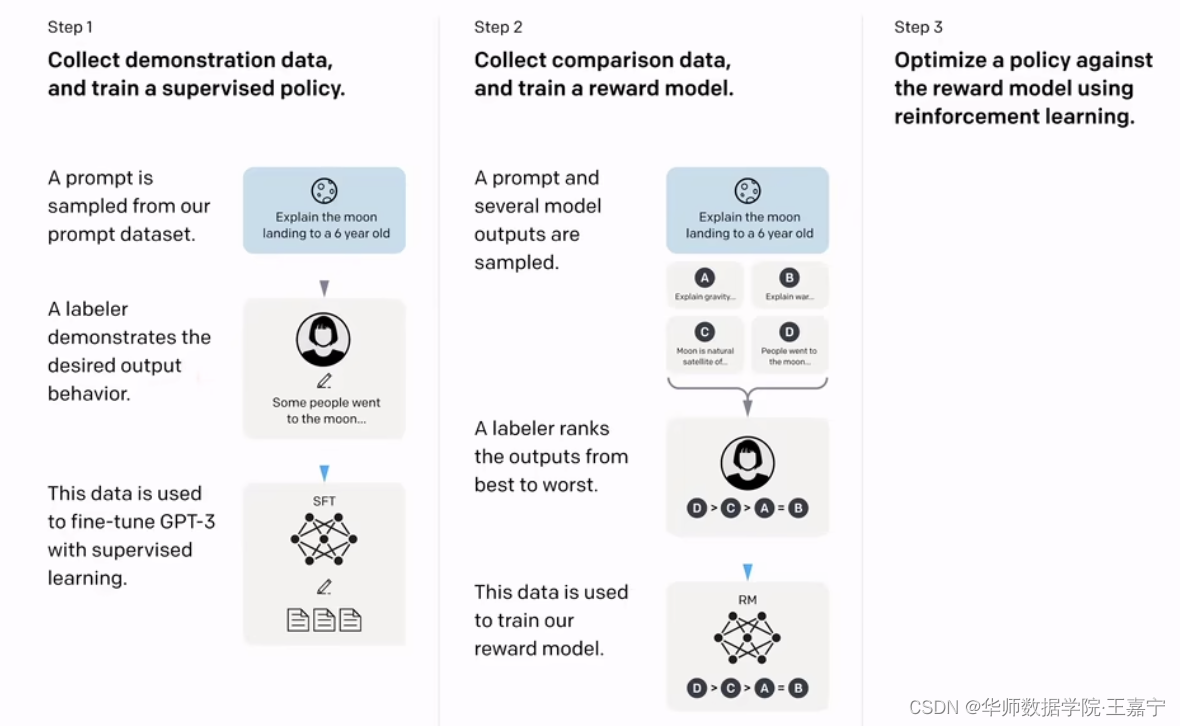
-
Step1: 先采样一些demonstration数据,其包括prompt和labeled answer。基于这些标注的数据,对 GPT-3 进行fine-tuning,得到SFT(Supervised Fine-tuning);雇佣40名标注人员完成prompt的标注(实际可能上百人参与了数据标注和处理)。此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
-
Step2: Fine-tuning完之后,再给一个prompt让SFT模型生成出若干结果(生成约4~7个结果,可以通过beam search等方法),例如上图中生成ABCD四种结果,通过人工标注为其排序,例如D>C>A=B,可以得到标注的排序pair;
基于标注的排序结果,训练一个Reward Model:
对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高:
l o s s ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] loss(\theta) = -\frac{1}{K\choose 2}E_{(x, y_w, y_l)\sim D[\log(\sigma(r_{\theta}(x, y_w) - r_{\theta}(x, y_l)))]} loss(θ)=−(2K)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]r θ r_{\theta} rθ表示一个reward function
论文中K表示生成的数量4~9之间。
解决过拟合的问题:
即在训练时,InstructGPT/ChatGPT将每个prompt的 C K 2 C_{K}^{2} CK2 个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。

- Step3: 继续用生成出来的结果训练SFT,并通过强化学习的PPO方法,最大化SFT生成出排序靠前的answer。
o b j e c t i v e ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ∼ D p r e t r a i n [ log ( π ϕ R L ( x ) ) ] objective(\phi) = E_{(x, y)\sim D_{\pi_{\phi}^{RL}}}[r_{\theta}(x, y) - \beta\log(\pi_{\phi}^{RL}(y|x)/\pi^{SFT}(y|x))] + \gamma E_{x\sim D_{pretrain}}[\log(\pi_{\phi}^{RL}(x))] objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]
初始化时 π ϕ R L = π S F T \pi_{\phi}^{RL}=\pi^{SFT} πϕRL=πSFT
PPO算法在训练过程中环境会发生变换。
首先,根据自动标注的数据(下面的来源3),喂入 π ϕ R L \pi_{\phi}^{RL} πϕRL中,得到输出结果 y y y,其会根据 r θ r_{\theta} rθ得到一个得分,期望在训练 π ϕ R L \pi_{\phi}^{RL} πϕRL时能够最大化reward的得分;
第二项loss表示KL散度,在迭代训练过程中,避免RL模型 π ϕ R L \pi_{\phi}^{RL} πϕRL与原始的监督训练的SFT模型差的太远;
第三项则是一个预训练目标,可以理解为避免灾难遗忘。当 γ = 0 \gamma=0 γ=0时则为标准的PPO模型,否则为PPO-ptx模型;
1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,尽管参数少了 100 多倍。
Prompt数据来源
标注人员先标注一些prompt,主要包括三种类型的数据集:
- 来源1:标注人员直接标注prompt对应的答案,然后训练SFT模型;
- 来源2:标注人员标注排序数据(即对SFT生成的多个答案进行排序),用于训练RM模型;
- 来源3:PPO数据集,此时不需要任何标注,其来自于RM模型对生成的若干结果进行排序后的内容
训练一个V1版本的模型;
发布内测,收集公众的提问数据,进行筛选后再次训练模型,迭代训练。
考虑到ChatGPT仅仅被用在对话领域,这里我猜测ChatGPT在数据采集上有两个不同:
- 提高了对话类任务的占比;
- 将提示的方式转换Q&A的方式。当然这里也仅仅是猜测,更准确的描述要等到ChatGPT的论文、源码等更详细的资料公布我们才能知道。
ChatGPT训练语料大约40T大小。大规模预训练语言模型预训练语料:
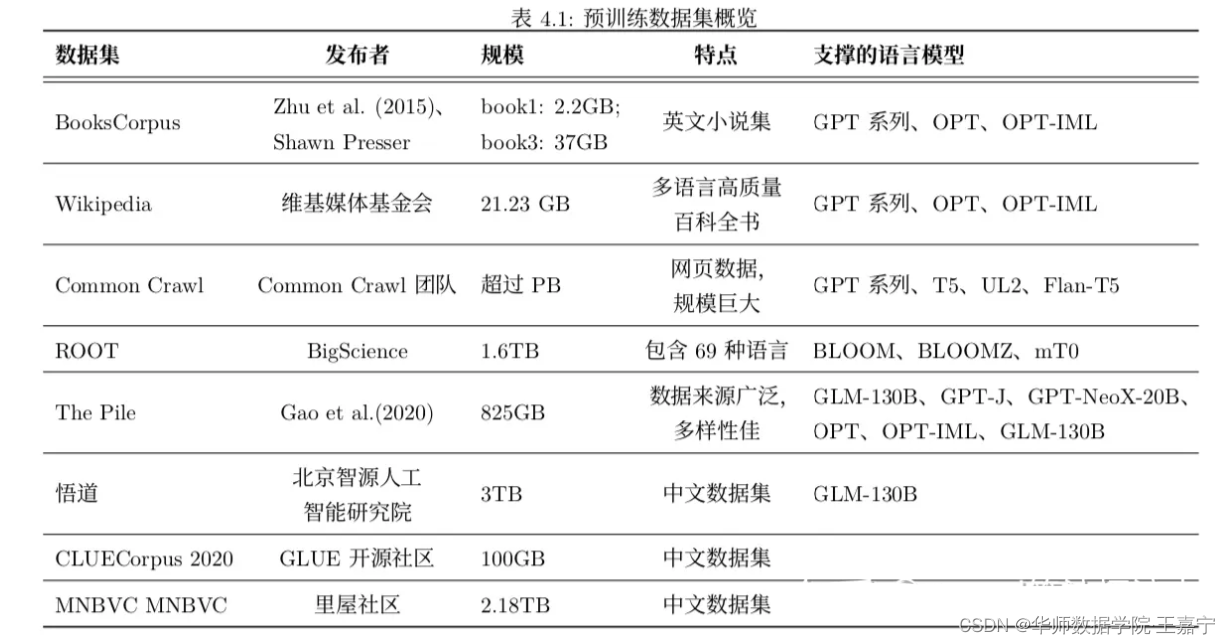
(1)BookCorpus:
- 2.2GB:https://hyper.ai/datasets/13642
- 37GB:https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
(2)中文Wudao: https://data.baai.ac.cn/details/WuDaoCorporaText
(3)CLUECorpus: 100GB 的高质量中文预训练语料:https://github.com/CLUEbenchmark/CLUECorpus2020
(4)MNBVC: 2376.12GB超大规模中文语料:https://github.com/esbatmop/MNBVC
MNBVC数据集不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。数据均来源于互联网收集。
其他数据集:
| 名称 | 项目地址 | 基础模型 | 训练方法/数据集 |
|---|---|---|---|
| Alpaca | https://github.com/tatsu-lab/stanford_alpaca | LLaMA | Alpaca |
| ChatGLM | https://github.com/THUDM/ChatGLM-6B | GLM | 自定义数据集(1T) |
| Dolly | https://github.com/databrickslabs/dolly | GPT-J 6B | Alpaca |
| BELLE | https://github.com/LianjiaTech/BELLE | BLOOM | Alpaca转中文+自定义数据集(0.5 ~ 2M) |
| OpenChatKit | https://github.com/togethercomputer/OpenChatKit | GPT-NEOX/Pythia | OIG-43M |
| FastChat/Vicuna | https://github.com/lm-sys/FastChat | LLaMA shareGPT(70k) | |
| gpt4all | https://github.com/nomic-ai/gpt4all | LLaMA | 自定义数据集(800k) |
| lit-llama | https://github.com/Lightning-AI/lit-llama Lit-LLaMA | Alpaca | |
| HugNLP | https://github.com/wjn1996/HugNLP | GPT / OPT / LLaMA | 中文3M,英文1.5M |
参考资料:
【1】InstructGPT原理
【2】理解Actor-Critic的关键是什么?(附代码及代码分析)
【3】Prompt-Tuning——深度解读一种新的微调范式