目录
一.什么是堆
1.基本介绍
堆是一种数据结构,通常被描述为一棵完全二叉树,其中每个节点都满足堆属性。堆有两种类型:最大堆(大顶堆)和最小堆(小顶堆)。在最大堆中,父节点的值大于或等于其子节点的值,而在最小堆中,父节点的值小于或等于其子节点的值。堆常常用于优先队列中,其中最大(或最小)元素总是位于堆的根节点。堆也可以被用作排序算法的一部分,如堆排序
2.堆的实现方式
堆有两种常见的实现方式:二叉堆和斐波那契堆。
二叉堆是最常见的堆实现方式,其特点是满足以下两点性质:
- 堆是一种完全二叉树;
- 堆中每个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
由于完全二叉树的性质,我们可以使用数组来表示二叉堆,(根结点为0时)其节点的左孩子在数组中的位置为 2i+1,右孩子的位置为 2i+2,其父节点的位置为 (i-1)/2。
斐波那契堆是另一种常见的堆实现方式,其相较于二叉堆更加高效,但是实现起来也更加复杂。斐波那契堆采用了一种基于树形结构的优化方法,可以支持更加高效的插入、删除和查找操作。但是,斐波那契堆的常数项较大,且实现也更加复杂,因此在实际应用中并不常见。
二.最大堆的实现
1.最大堆
最大堆,父节点的值大于或等于其子节点的值,我们通常用数组来表示堆结构,因此(都存在的情况下)结点i的左孩子结点下标为2*i+1,右孩子结点2*i+2,父亲节点为(i-1)/2,每一次添加和删除操作,我们都要保持最大堆的结构性质.
2.思路分析
首先我们用List<Integer>集合来保存堆中的元素,当然我们也可以用数组,但需要考虑扩容,因此为了方便起见,我们直接使用API提供的,底层也是用数组实现的.
0.基础操作
1.交换两个元素
private void swap(int i, int j) {
int temp = data.get(i);
data.set(i, data.get(j));
data.set(j, temp);
}
2.返回当前结点左孩子下标
//返回左子树结点的索引
public int leftChild(int index) {
return index * 2 + 1;
}
3.返回当前结点右孩子下标
//返回右子树结点的索引
public int rightChild(int index) {
return index * 2 + 2;
}4.返回当前结点的父节点下标
//返回父节点的索引
public int parent(int index) {
return (index - 1) / 2;
}1.添加+上浮操作
首先考虑添加元素的处理:我们首先把元素添加到最后一个位置,也就是索引为size的位置,size++;此时这个元素位置只是临时的,因为我们要保持大顶堆的结构性质:父节点的值大于或等于其子结点的值,这个时候我们需要进行上浮操作(siftup),上浮的位置应该满足当前元素的值大于或等于其子结点的值.例如:{7,4,5,2,3}中添加8元素

此时8大于它的父节点5,将8和5进行交换

8大于它的父节点7,将将8和7进行交换
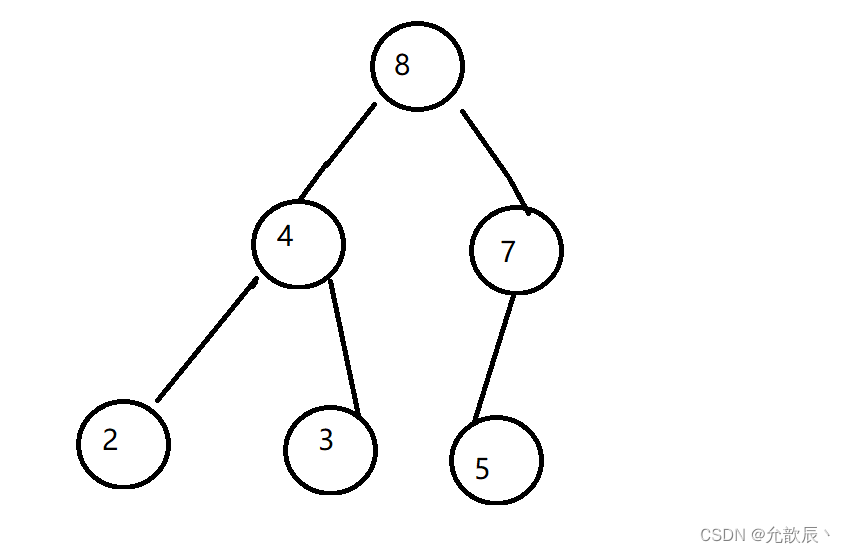
此时8位于根结点,不存在父节点了,因此循环结束
因此我们可以总结出循环结束的两个条件,一个就是当前结点小于根结点,或者当前结点不存在父节点,也就是结点的索引不是0,循环继续的条件则为index>0&&data.get(parent(index)) < data.get(index),因此我们便可以很容易的写出来上浮siftup操作.
//添加值为val的值到堆中
public void add(int val) {
data.add(val);
size++;
siftUp(size - 1);
}
private void siftUp(int index) {
//当前结点不是根结点且当前结点大于其父节点
while (index > 0 && data.get(parent(index)) < data.get(index)) {
swap(parent(index), index);
index = parent(index);
}
}2.删除+下沉操作
我们实现的堆每一次删除堆中的最大值,也就是索引为0位置上的元素,我们可以使用这种方式来删除元素,将索引为0的元素和最后一个元素(size-1)进行交换,然后将最后一个元素删除,这样可以保持完全二叉树的结构,也可以实现删除操作.
然后我们调整这个二叉树使其成为堆,因为将最后一个结点交换到第一个结点一定不是堆结构,每一次我们寻找到其孩子结点的最大值,然后将此结点和最大值进行对比,如果大于最大值或者当前结点的左孩子的索引大于size就停止交换,此时就是最大堆了,如果比最大值小,就交换这两个结点
public int extractMax() {
if (data.isEmpty()) {
throw new NoSuchElementException("heap is empty!cannot extract!");
}
swap(0, size - 1);
Integer remove = data.remove(size - 1);
size--;
siftDown(0);
return remove;
}
private void siftDown(int index) {
//确保有左子树
while (leftChild(index) < size) {
int j = leftChild(index);
if (j + 1 < size && data.get(j) < data.get(j + 1)) {
j = j + 1;
}
if (data.get(index) < data.get(j)) {
swap(index, j);
index = j;
} else {
break;
}
}
}3.将数组堆化操作
将传入的数组转化为大顶堆,我们可以将数组中的元素一个个调用添加操作,当然可以转化为大顶堆,但我们还是定义一个方法(构造器),来对传入的数组进行堆化操作(在堆排序中使用到).
我们可以从当前完全二叉树的最后一个非叶子结点(parent(size-1))开始向下调整,使得每个子树为转化为堆
//将arr调整为最大堆
public MaxHeap(int[] arr) {
this.data = new ArrayList<>(arr.length);
for (int i : arr) {
data.add(i);
size++;
}
//从当前完全二叉树的最后一个非叶子结点向下调整,使每个子树为堆
for (int i = parent(size - 1); i >= 0; --i) {
siftDown(i);
}
} private static void siftDown(int[] arr, int index, int size) {
//确保有左子树
while (index * 2 + 1 < size) {
//左孩子
int j = index * 2 + 1;
//左右孩子两者的最大值
if (j + 1 < size && arr[j] < arr[j + 1]) {
j = j + 1;
}
if (arr[index] < arr[j]) {
swap(arr, index, j);
index = j;
} else {
break;
}
}
}2.代码实现
public class MaxHeap {
private List<Integer> data;
private int size;
//将arr调整为最大堆
public MaxHeap(int[] arr) {
this.data = new ArrayList<>(arr.length);
for (int i : arr) {
data.add(i);
size++;
}
//从当前完全二叉树的最后一个非叶子结点向下调整,使每个子树为堆
for (int i = parent(size - 1); i >= 0; --i) {
siftDown(i);
}
}
public MaxHeap() {
this(10);
}
public MaxHeap(int size) {
this.data = new ArrayList<>(size);
this.size = 0;
}
public int size() {
return this.size;
}
@Override
public String toString() {
return data.toString();
}
//添加值为val的值到堆中
public void add(int val) {
data.add(val);
size++;
siftUp(size - 1);
}
//返回左子树结点的索引
public int leftChild(int index) {
return index * 2 + 1;
}
//返回右子树结点的索引
public int rightChild(int index) {
return index * 2 + 2;
}
//返回父节点的索引
public int parent(int index) {
return (index - 1) / 2;
}
private void siftUp(int index) {
//当前结点不是根结点且当前结点大于其父节点
while (index > 0 && data.get(parent(index)) < data.get(index)) {
swap(parent(index), index);
index = parent(index);
}
}
public int extractMax() {
if (data.isEmpty()) {
throw new NoSuchElementException("heap is empty!cannot extract!");
}
swap(0, size - 1);
Integer remove = data.remove(size - 1);
size--;
siftDown(0);
return remove;
}
private void siftDown(int index) {
//确保有左子树
while (leftChild(index) < size) {
int j = leftChild(index);
if (j + 1 < size && data.get(j) < data.get(j + 1)) {
j = j + 1;
}
if (data.get(index) < data.get(j)) {
swap(index, j);
index = j;
} else {
break;
}
}
}
private void swap(int i, int j) {
int temp = data.get(i);
data.set(i, data.get(j));
data.set(j, temp);
}
}
希望大家可以自己实现小顶堆的实现,实现思路基本和大顶堆的实现一样.
三.堆排序
1.什么是堆排序
堆排序是一种基于堆数据结构的排序算法,它的时间复杂度为O(n log n)。堆排序的核心思想是将待排序序列构造成一个堆,然后依次将堆顶元素与堆底元素交换,再对剩余的元素重新构造成堆,直到所有元素都有序。由于堆排序是基于完全二叉树的,因此可以使用数组来表示堆,从而节省了树的指针空间的开销。堆排序有两种形式:大根堆和小根堆。在大根堆中,父节点的值大于等于任何一个子节点的值,在小根堆中则相反,父节点的值小于等于任何一个子节点的值。因此,大根堆可以用来进行升序排序,而小根堆则可以用来进行降序排序。堆排序的主要优点是稳定性好,适用于大规模数据的排序。
2.思路分析
其实大部分的操作我们在堆中已经将讲解过了,首先我们对数组堆化操作,转化为一个大顶堆,然后我们每次将堆顶元素和最后一个元素进行交换,因为堆顶元素都是剩下元素的最大元素,因此每次我们都能找到剩下元素中的最大值,每一次交换之后堆的长度就减一,因为之后的元素已经有序了
3.代码实现
//原地堆排序
public static void heapSort(int[] arr) {
//将arr堆化
//从当前完全二叉树的最后一个非叶子结点向下调整,使每个子树为堆
for (int i = (arr.length - 2) / 2; i >= 0; --i) {
siftDown(arr, i, arr.length);
}
//将堆顶的元素和最后一个交换
for (int i = arr.length - 1; i >= 0; --i) {
swap(arr, 0, i);
siftDown(arr, 0, i);
}
}
private static void siftDown(int[] arr, int index, int size) {
//确保有左子树
while (index * 2 + 1 < size) {
//左孩子
int j = index * 2 + 1;
//左右孩子两者的最大值
if (j + 1 < size && arr[j] < arr[j + 1]) {
j = j + 1;
}
if (arr[index] < arr[j]) {
swap(arr, index, j);
index = j;
} else {
break;
}
}
}
public static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}