使用爬虫对视频弹幕进行爬取并保存为csv文件,导入数据库中,进而实现前后端交互功能。
数据集中包含的数据分别为爬取的热门视频的标题、播放量、弹幕量、收藏量、综合得分以及视频的类别等信息,便于后续我们进行数据分析。
我们使用数据库中的数据评出综合得分排名前50的热门视频以及播放量的排名前10的视频,我们还可以通过弹幕去绘制词云图和播放量与点赞量关系的散点图,最后将这些数据进行可视化展示。
系统首页面
运行flask项目中的app.py进入系统首页面,首页面为B站系统分析的欢迎页面,左边是菜单栏,我们可以进行热门视频数据搜索,查看数据的可视化分析等,其中欢迎页面的公告栏里点击综合热门以及每周必看等字体可以跳转进入B站网站中的综合热门视频、每周必看视频页面进行详细查看,页面的右上角可以通过查询功能进入百度或者B站进行查询。

数据搜索
选择菜单栏中的数据搜索页面我们可以看到热门视频的标题、播放量、弹幕量、收藏量、综合得分以及视频分类等基本情况。我们可以通过search查询我们想要了解的某一视频的数据情况,我们还可以选择每个页面的数据数量,比如五条,十条,二十条或者30条,当然,总页面数量也会随着每页数据数量的变化而变化。

可视化展示
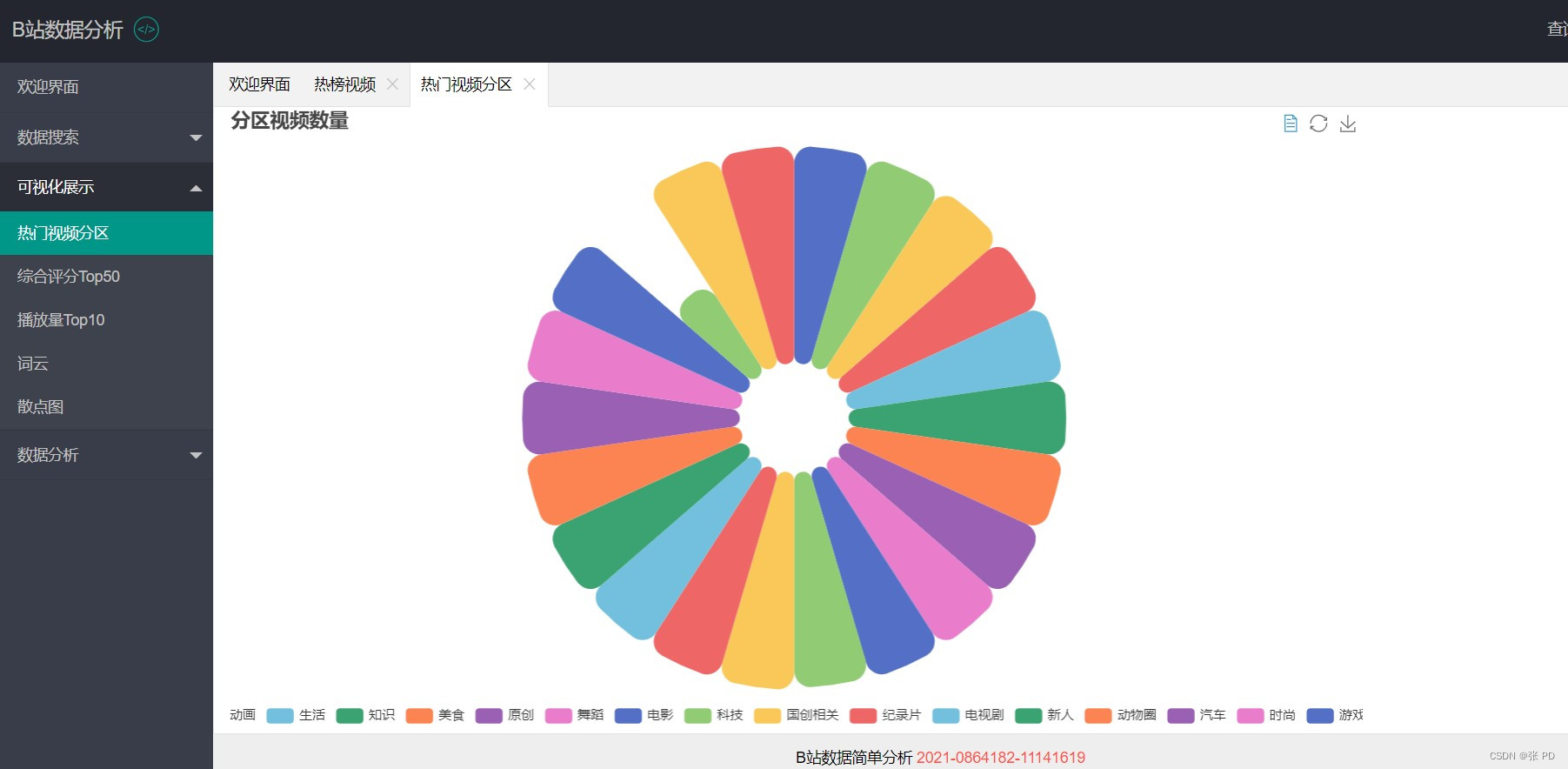
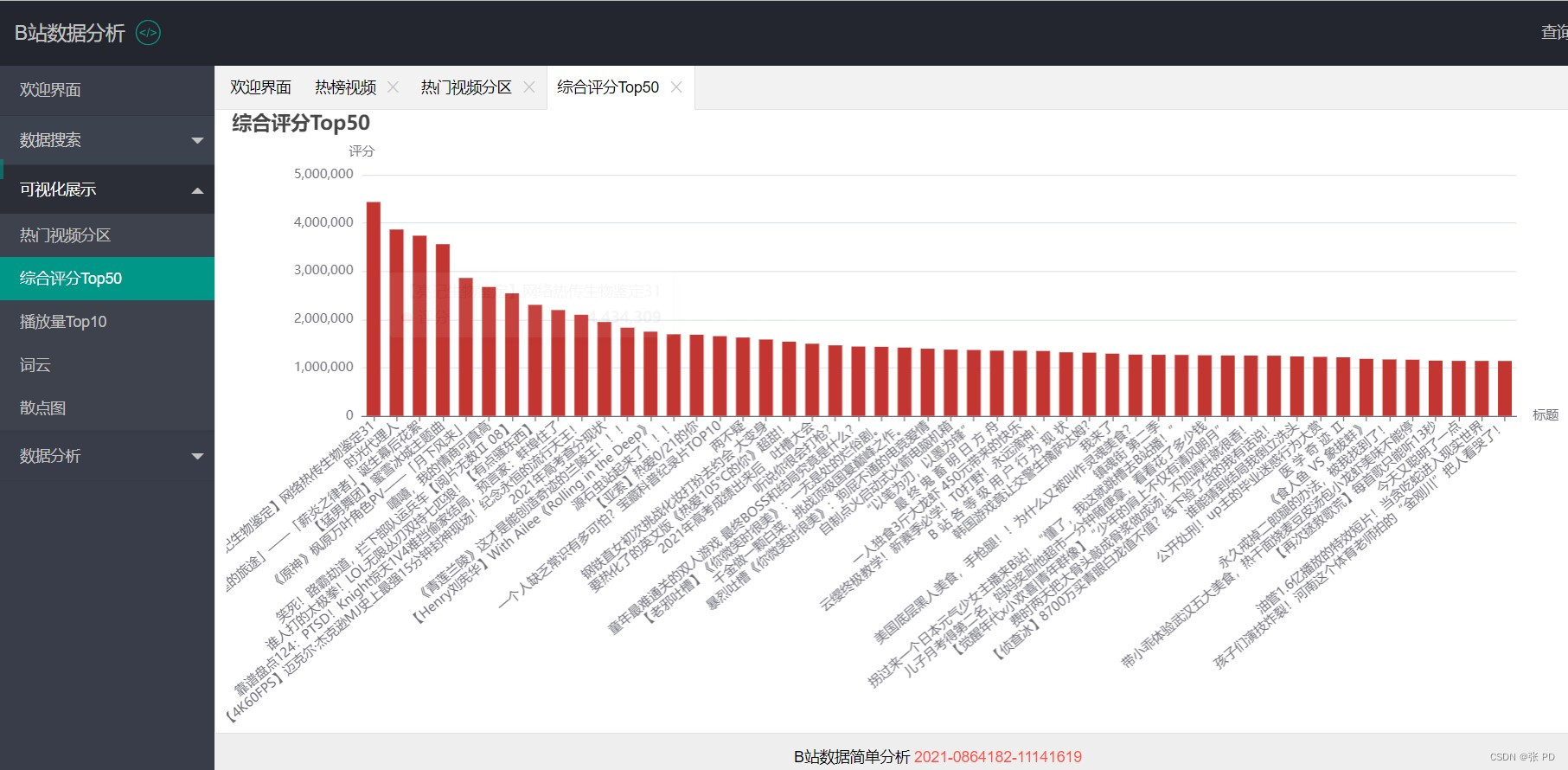
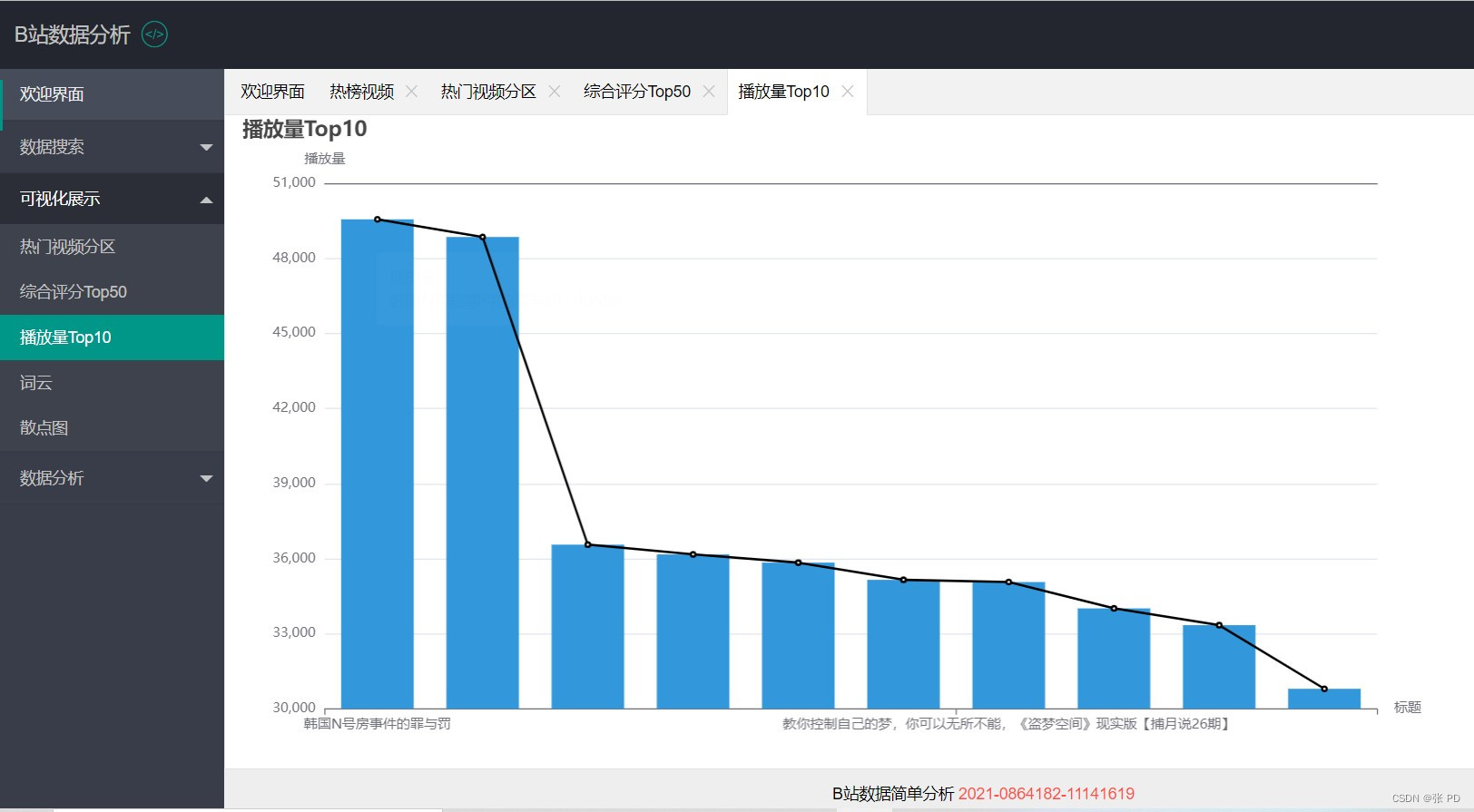
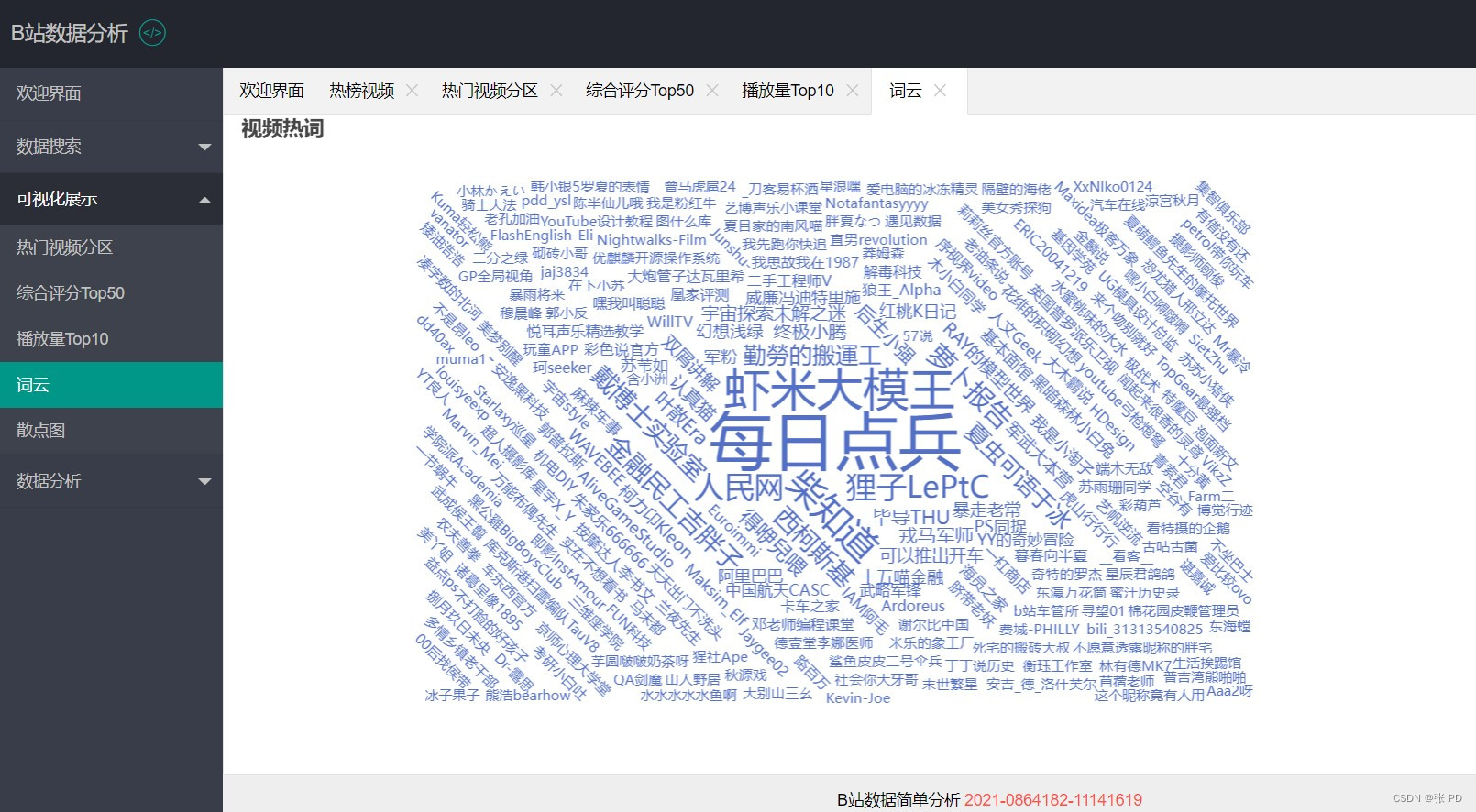
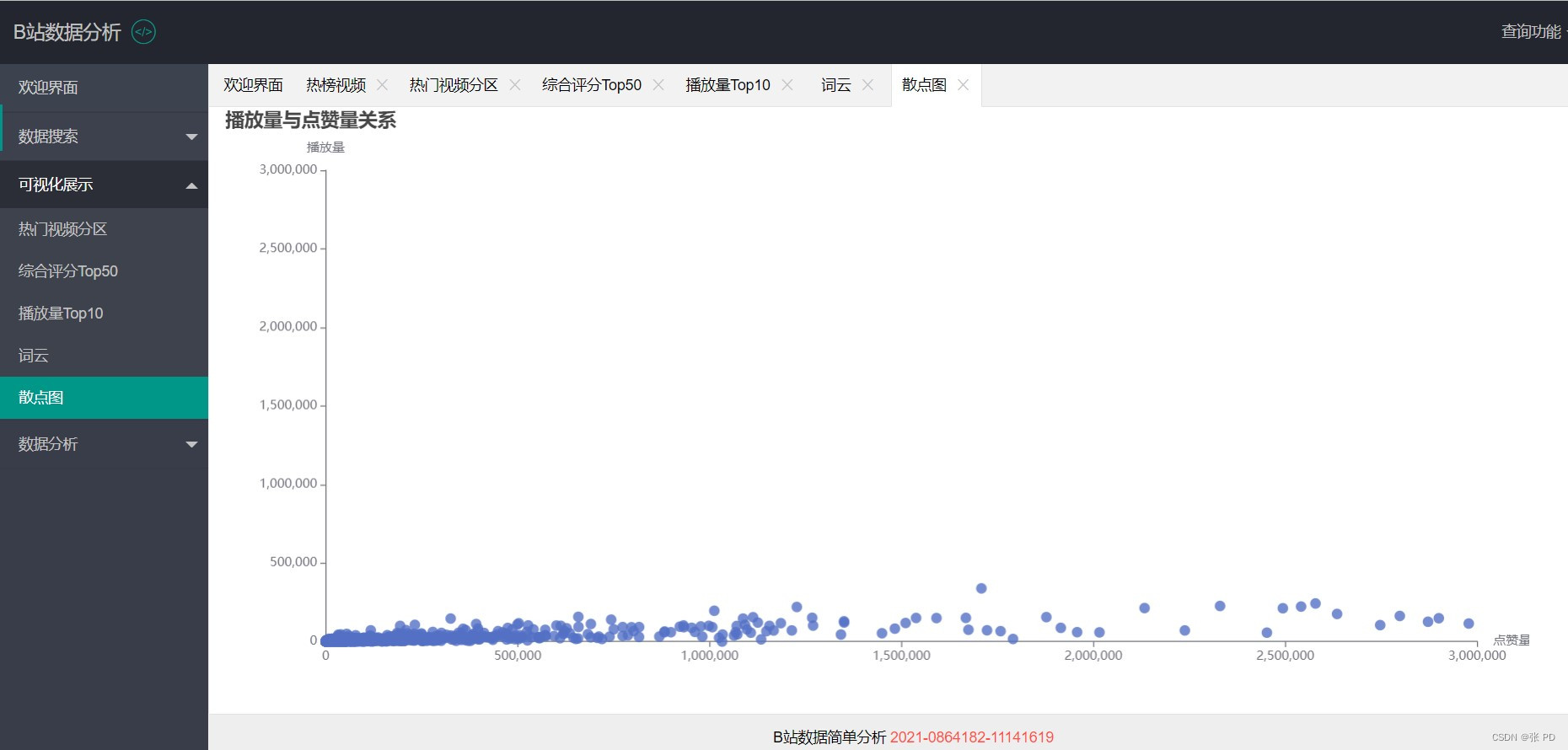
在可视化展示页面我们绘制了热门视频种类的饼图,对综合评分排名前50的热门视频进行柱状图展示,对播放量排名前10进行柱状图与和折线图展示,对视频热词进行词云展示,关于播放量与点赞量的关联性效果进行散点图展示。

数据分析
使用k均值聚类算法(k-means clustering algorithm),计算第一个特征值(总弹幕数+总评论数)/总播放量/统计范围内视频数量,计算第二个特征值(点赞数 * 1+投币数 * 2+收藏数 * 3+分享数 * 4)/播放量 * 发布视频数,使用kmeans算法进行聚类,选择簇类k=2,向算法中传入特征值集合,产生聚类集合。
K均值聚类
定义:k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
首先确定特征值features,特征值包含两个数据;
data01:反映的是平均每个视频的互动率,互动率越高,表明其视频更能产生用户的共鸣,使其有话题感。
data01=(总弹幕数+总评论数)/总播放量/统计范围内视频数量
data02:表示的是统计时间内发布视频的平均点赞率,越大表示视频质量越稳定,用户对up主的认可度也就越高。
data02=(点赞数 * 1+投币数 * 2+收藏数 * 3+分享数 * 4)/播放量 * 发布视频数
然后数据预处理,代码如下:
#创建SparkSession对象
sc = SparkContext('local', 'spark_project')
sc.setLogLevel('WARN')
spark = SparkSession.builder.getOrCreate()
#创建DataFrame对象
df = spark.read.csv('D:/Bdatas/techno.csv',header=True)
#去重
df = df.distinct()
#删除指定字段
df = df.drop('types', 'url', 'title')
#去除所有有空值的行
df = df.dropna(how="all")
#将字符串数据转换为float浮点型
df = df.withColumn("mid", df.coins.cast('float'))
df = df.withColumn("coins", df.coins.cast('float'))
df = df.withColumn("danmu", df.danmu.cast('float'))
df = df.withColumn("favorite", df.favorite.cast('float'))
df = df.withColumn("likes", df.likes.cast('float'))
df = df.withColumn("replay", df.replay.cast('float'))
df = df.withColumn("share", df.share.cast('float'))
df = df.withColumn("view", df.view.cast('float'))
# describe可以获取字段的各种基本统计信息例如最大、最小值
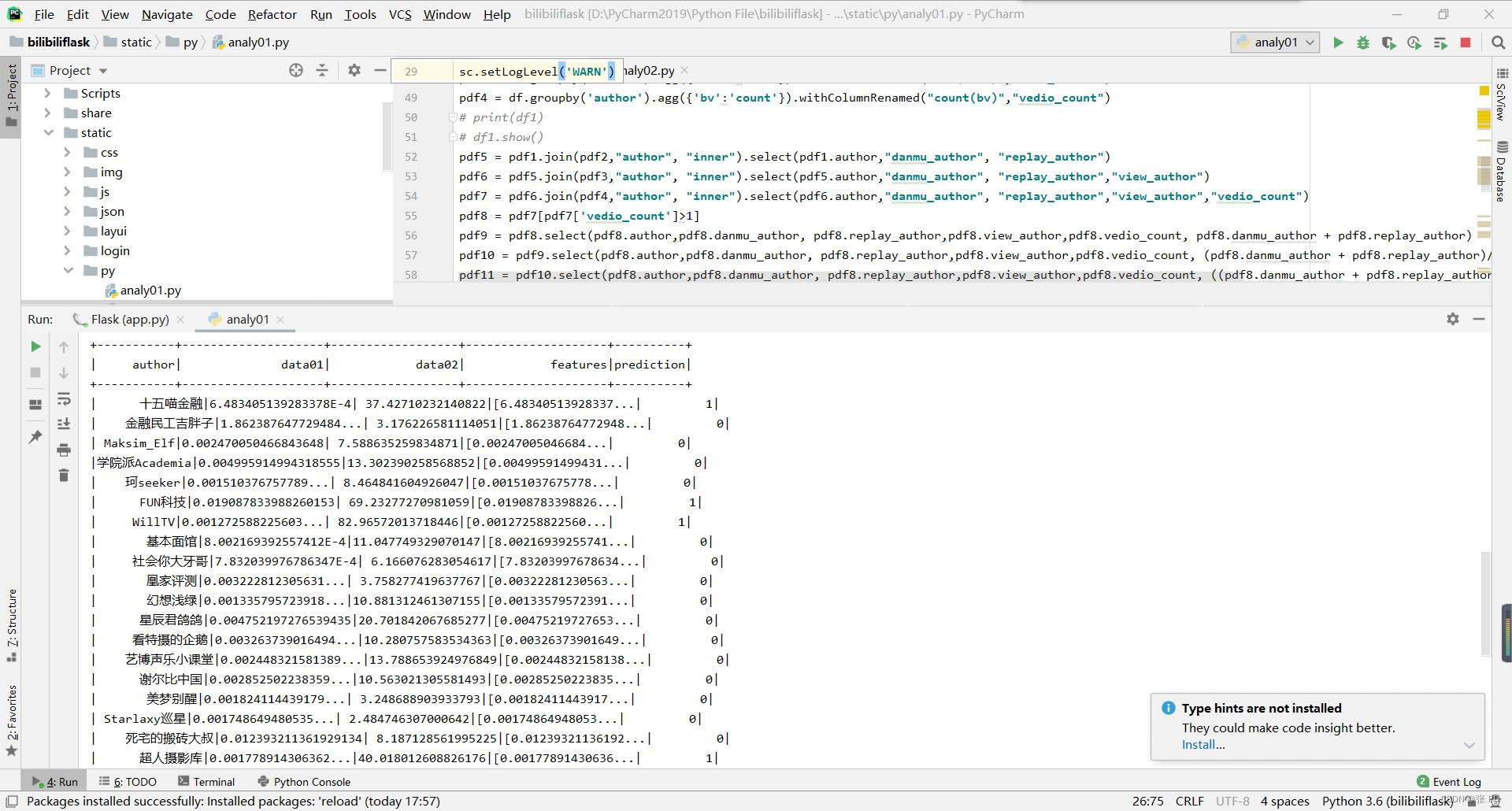
df.describe("coins","danmu","favorite","likes","replay","share","view").show()计算第一个特征值(总弹幕数+总评论数)/总播放量/统计范围内视频数量,通过up主分组,分别单独计算每个up主发布视频的总弹幕数、总评论数、总播放量、以及发布视频数量,分别用字段danmu_author、view_author、replay_author、vedio_count表示,总弹幕数和总播放量实例代码如下:
pdf1 = df.groupby('author').agg({'danmu':'sum'}
).withColumnRenamed("sum(danmu)","danmu_author")
pdf2 = df.groupby('author').agg({'replay':'sum'}
).withColumnRenamed("sum(replay)","replay_author")之后通过join将多个DataFrame通过相同的列“author”连接合并,示例连接代码如下:
pdf5 = pdf1.join(pdf2,"author", "inner"
).select(pdf1.author,"danmu_author", "replay_author")将up主发布的视频数量少于1的过滤掉,避免个别因素影响算法效果,代码如下:
pdf8 = pdf7[pdf7['vedio_count']>1]获取并输出特征值1,代码如下:
# 选择多个列到DataFrame
pdf11 = pdf10.select(pdf8.author,pdf8.danmu_author,
pdf8.replay_author,pdf8.view_author,pdf8.vedio_count,
((pdf8.danmu_author + pdf8.replay_author)
/pdf8.view_author)/pdf8.vedio_count)
#删除不需要的列
pdf12 = pdf11.drop('danmu_author', 'replay_author',
'view_author','vedio_count')
#将特征值1字段名改为data01
pdf13 = pdf12.withColumnRenamed("(((danmu_author + replay_author) / view_author) / vedio_count)","data01")计算第二个特征值(点赞数 * 1+投币数 * 2+收藏数 * 3+分享数 * 4)/播放量 * 发布视频数,通过“author”字段去重,选择需要的列生成DataFrame并输出查看,代码如下:
#通过单列去重
xdf0 = df.select("author")
# 单列为标准
xdf01 = df.dropDuplicates(subset=[c for c in df.columns if c in ["author"]])
#选择多个列生成DataFrame
xdf1 = xdf01.select(df.author,df.likes,df.coins,
df.favorite,df.share,df.view,
(df.likes + df.coins*2 + df.favorite*3 + df.share*4) / df.view * 100)
#删除不需要的列
xdf2 = xdf1.drop('likes', 'coins', 'favorite','share','view')
#特征值2字段名改为data02
xdf3 = xdf2.withColumnRenamed("(((((likes + (coins * 2)) + (favorite * 3)) + (share * 4)) / view) * 100)","data02")
xdf3.show()将两个特征值连接,代码如下:
ydf2 = pdf13.join(xdf3,"author", "inner"
).select(pdf13.author,pdf13.data01, xdf3.data02)两组特征值都是数字,因此我们需要使用向量汇编器(Vector Assembler)将它们转换为特征。向量汇编器是一种转换器,它将一组特征转换为单个向量列,通常称为特征数组,这里的特征是列。首先使用.columns提取所需的列,将其作为输入传递给Vector Assembler,然后使用transform将输入列转换为一个称为features的向量列。使用kmeans算法进行聚类,选择簇类k=2,向算法中传入特征值集合,产生聚类集合,代码如下:
assembler = VectorAssembler(
inputCols=["data01", "data02"],
outputCol="features")
output = assembler.transform(ydf2)
print("Assembled columns 'data01', 'data02' to vector column
'features'")
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(output.select('features'))
transformed = model.transform(output)
transformed.show()


KNN分类算法
定义:KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
读取数据集,将数据集中的中文使用0、1、2、3等代替进行分类,代码如下:
data = pd.read_csv("D:/Bdatas/technolo005.csv",header=0)
data["types"] = data["types"].map({"科学科普":0,"社科人文":1,"野生技术协会":2,"机械":3,"汽车":4,"星海":5})
data.drop_duplicates(inplace=True)
data["types"].value_counts()处理数据集数据 清洗,采用留出法hold-out拆分数据集:训练集、测试集,代码如下:
t0 = data[data["types"] == 0]
t1 = data[data["types"] == 1]
t0 = t0.sample(len(t0),random_state=0)
t1 = t1.sample(len(t1),random_state=0)
train_X = pd.concat([t0.iloc[:300, :-1],t1.iloc[:300, :-1],t2.iloc[:300, :-1],t3.iloc[:300, :-1],t4.iloc[:300, :-1],t5.iloc[:300, :-1]],axis=0)
train_y = pd.concat([t0.iloc[:300, -1],t1.iloc[:300, -1],t2.iloc[:300, -1],t3.iloc[:300, -1],t4.iloc[:300, -1],t5.iloc[:300, -1]],axis=0)
test_X = pd.concat([t0.iloc[300:, :-1],t1.iloc[300:, :-1],t2.iloc[300:, :-1],t3.iloc[300:, :-1],t4.iloc[300:, :-1],t5.iloc[300:, :-1]],axis=0)
test_y = pd.concat([t0.iloc[300:, -1],t1.iloc[300:, -1],t2.iloc[300:, -1],t3.iloc[300:, -1],t4.iloc[300:, -1],t5.iloc[300:, -1]],axis=0)class KNN:
def __init__(self,k):
self.k = k
def fit(self,X,y):
self.X = np.asarray(X) #将x转换成ndarray数组
self.y = np.asarray(y)
def predict(self,X):
X = np.asarray(X)
result = []
#对数组进行遍历,每次取数组中的一行
for x in X:
dis = np.sqrt(np.sum((x-self.X)**2,axis=1))
index = dis.argsort()
index = index[:self.k]
count = np.bincount(self.y[index],weights=1/dis[index])
result.append(count.argmax())
return np.asarray(result)
#定义k=6
knn = KNN(k=6) #创建KNN对象
knn.fit(train_X,train_y) #进行训练
result = knn.predict(test_X) #进行测试
display(np.sum(result == test_y),axis=0)
display(np.sum(result == test_y)/len(result))
