一、项目简介
本项目是基于Python + Echarts + Flask + Layui + MySQL的新冠疫情实时监测系统。涉及到的关键技术有pandas一键导入、使用MySQL做相关数据存储功能、使用Python与MySQL数据库进行交互、使用Flask构建web项目、基于Echarts制作数据可视化展示地图、使用Layui作为后台数据管理可视化框架、 以pycharm作为开发平台。
二、项目功能
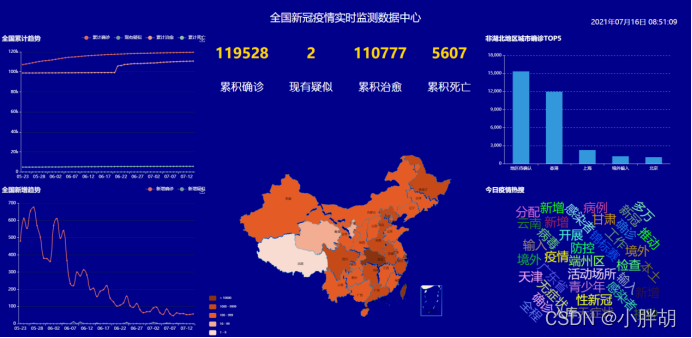
①全国新冠肺炎疫情总体状况统计并展示;
②用Echarts制作全国新冠肺炎疫情地图并展示各省确诊人数;
③采用Layui框架制作后台数据管理系统并制作管理员登入功能;
④全国新冠肺炎疫情累计人数趋势通过曲线图展示;
⑤全国新冠肺炎疫情新增人数趋势通过曲线图展示;
⑥非湖北地区城市确诊人数TOP5柱状图排行展示;
⑦管理员用户对数据一键导入;
⑧管理员用户对后台疫情相关数据进行修改和删除操作。
三、项目功能

四、更新说明
由于国家疫情政策放开,目前所有网站的疫情数据已经停止维护,大部分疫情数据通道关闭。所以通过爬虫获取数据这条路已经走不通了,但该项目仍然保留之前的爬虫代码,仅供学习和参考使用。
同时配套报告也与版本存在差异,报告仅供参考。
更新内容:
- 加入数据新增以及部分数据一键导入功能,可以快速导入项目
- 修复疫情数据接口停止带来的页面报错提醒
- 优化整个代码目录结构
五、项目演示
系统前台数据展示页面
系统后台登录界面
系统后台首页(包含启动爬虫、跳转数据看板)
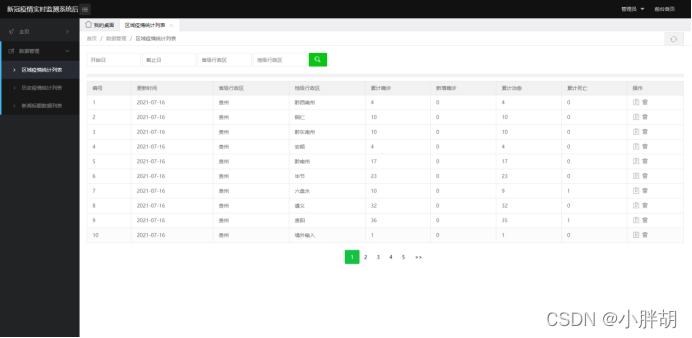
区域疫情统计列表(包含删除、修改、查询、分页功能)
区域疫情统计修改页面
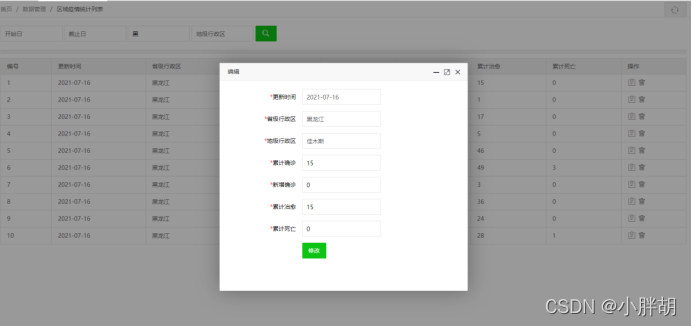
历史疫情统计列表(包含删除、修改、查询、分页功能)
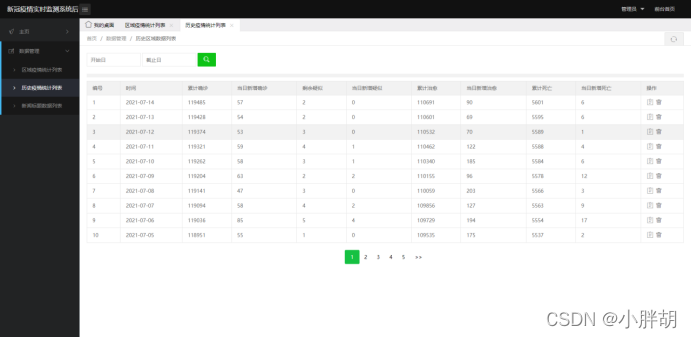
历史疫情统导入

导入模板

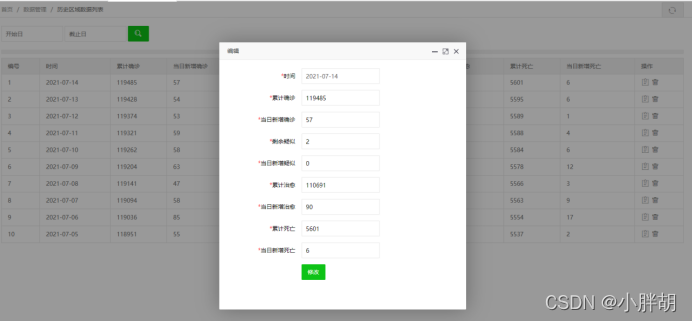
历史疫情统计修改页面
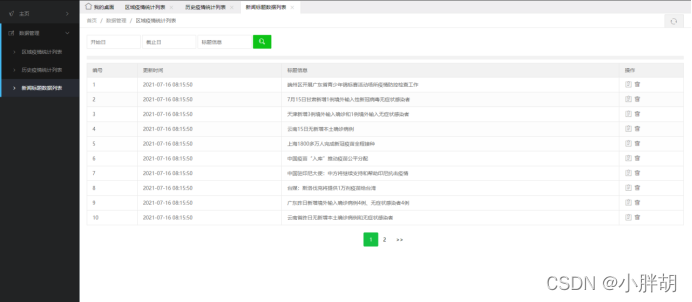
新闻标题统计列表(包含删除、修改、查询、分页功能)
新闻标题修改页面
六、项目源码
爬虫源码
import time
import datetime
from selenium.webdriver.common.by import By
import pymysql
import json
import traceback
import requests
from selenium.webdriver import Firefox, FirefoxOptions
from bs4 import BeautifulSoup
import re
def get_conn():
# 建立数据库连接
conn = pymysql.connect(host="127.0.0.1", user="root", password="123456", db="cov", charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
##################爬虫独立模块######################
# 功能说明:
# ①爬取并插入各个地区历史疫情数据
# ②爬取并插入全国历史疫情统计数据
# ③爬取并插入百度新闻标题最新数据
# 文件说明:
# ①可独立运行呈现结果
# ②调用online方法运行
####################################################
def get_tx_history_data():
url2 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_other"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r2 = requests.get(url2, headers)
res2 = json.loads(r2.text)
try:
data_all2 = json.loads(res2["data"])
except:
return [], []
history = {
}
for i in data_all2["chinaDayList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {
"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all2["chinaDayAddList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
if ds in history:
history[ds].update({
"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
return history
def get_tx_detail_data():
url1 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r1 = requests.get(url1, headers)
res1 = json.loads(r1.text)
print(res1["data"])
data_all1 = {
}
try:
data_all1 = json.loads(res1["data"])
except:
return []
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"]
data_province = data_country[0]["children"]
for pro_infos in data_province:
province = pro_infos["name"]
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return details
def get_dx_detail_data():
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 省级正则表达式
provinceName_re = re.compile(r'"provinceName":"(.*?)",')
provinceShortName_re = re.compile(r'"provinceShortName":"(.*?)",')
currentConfirmedCount_re = re.compile(r'"currentConfirmedCount":(.*?),')
confirmedCount_re = re.compile(r'"confirmedCount":(.*?),')
suspectedCount_re = re.compile(r'"suspectedCount":(.*?),')
curedCount_re = re.compile(r'"curedCount":(.*?),')
deadCount_re = re.compile(r'"deadCount":(.*?),')
cities_re = re.compile(r'"cities":\[\{(.*?)\}\]')
# 爬虫爬取数据
datas = requests.get(url, headers=headers)
datas.encoding = 'utf-8'
soup = BeautifulSoup(datas.text, 'lxml')
data = soup.find_all('script', {
'id': 'getAreaStat'}) # 网页检查定位
data = str(data)
data_str = data[54:-23]
# print(data_str)
# 替换字符串内容,避免重复查找
citiess = re.sub(cities_re, '8888', data_str)
# 查找省级数据
provinceShortNames = re.findall(provinceShortName_re, citiess)
currentConfirmedCounts = re.findall(currentConfirmedCount_re, citiess)
confirmedCounts = re.findall(confirmedCount_re, citiess)
suspectedCounts = re.findall(suspectedCount_re, citiess)
curedCounts = re.findall(curedCount_re, citiess)
deadCounts = re.findall(deadCount_re, citiess)
details = []
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
for index, name in enumerate(provinceShortNames):
# 备用历史区域获取接口,只获取省份的累计确诊、现有确诊、累计治愈、累计死亡
details.append([current_date, name, name, confirmedCounts[index], currentConfirmedCounts[index], curedCounts[index], deadCounts[index]])
return details
# 插入地区疫情历史数据
# 插入全国疫情历史数据
def update_history():
conn, cursor = get_conn()
try:
# li = get_tx_detail_data() # 1代表最新数据
li = get_dx_detail_data() # 1代表最新数据
if len(li) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析地区历史疫数据异常...")
else:
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = 'select %s=(select update_time from details order by id desc limit 1)'
# 对比当前最大时间戳
cursor.execute(sql_query, li[0][0])
if not cursor.fetchone()[0]:
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已启动,正在获取数据....")
for item in li:
print(f"[INFO] {
time.asctime()} 已获取地区历史疫情数据:", item)
cursor.execute(sql, item)
conn.commit()
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已完成,更新到最新数据成功...")
else:
print(f"[WARN] {
time.asctime()}地区历史疫情爬虫已启动,已是最新数据...")
except:
traceback.print_exc()
try:
dic = get_tx_history_data() # 1代表最新数据
if len(dic) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析全国历史疫情数据异常...")
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已启动,正在获取数据....")
conn, cursor = get_conn()
sql = "insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k, v in dic.items():
if not cursor.execute(sql_query, k):
print(f"[INFO] {
time.asctime()} 已获取全国历史疫情:",
[k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit()
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
# 爬取腾讯健康热搜数据
def get_tenxun_hot():
option = FirefoxOptions()
option.add_argument("--headless") # 隐藏游览器
option.add_argument("--no--sandbox")
browser = Firefox(options=option)
url = "https://feiyan.wecity.qq.com/wuhan/dist/index.html#/?tab=shishitongbao"
browser.get(url)
time.sleep(3)
c = browser.find_elements(By.XPATH,"//*[@id='app']/div/div[1]/div[3]/div[3]/div[2]/div/div[2]/div[1]/div/div[2]")
context = [i.text for i in c]
browser.close()
return context
def is_number(s):
try: # 如果能运行float(s)语句,返回True(字符串s是浮点数)
float(s)
return True
except ValueError: # ValueError为Python的一种标准异常,表示"传入无效的参数"
pass # 如果引发了ValueError这种异常,不做任何事情(pass:不做任何事情,一般用做占位语句)
try:
import unicodedata # 处理ASCii码的包
unicodedata.numeric(s) # 把一个表示数字的字符串转换为浮点数返回的函数
return True
except (TypeError, ValueError):
pass
return False
# 插入百度热搜实时数据
def update_hotsearch():
cursor = None
conn = None
try:
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已启动,正在获取数据...")
context = get_tenxun_hot()
conn, cursor = get_conn()
sql = "insert into hotsearch(dt,content) values(%s,%s)"
ts = time.strftime("%Y-%m-%d %X")
for i in context:
print(f"[INFO] {
time.asctime()} 已获取历史疫情:", [ts, i])
cursor.execute(sql, (ts, i))
conn.commit()
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
def online():
update_history()
update_hotsearch()
return 200
if __name__ == "__main__":
update_history()
update_hotsearch()
七、源码获取
本项目有于疫情结束,数据采取旧数据!无法通过爬虫获取数据了!
源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目!