大家好,我是微学AI,今天给大家带来深度学习技巧应用5-神经网络中的模型剪枝技巧,模型剪枝是深度学习中的一个重要的技巧应用,用好了可以简化模型已经提高模型推理深度。
一、模型剪枝技巧介绍
模型剪枝是一种常用的深度学习模型优化技巧,其目的是通过去除模型中一些不必要的参数或节点,从而提高模型的运行效率和准确性。在模型剪枝技巧中,最常见的方法是结构化剪枝和非结构化剪枝。其中,结构化剪枝对模型的结构进行优化,例如对整个卷积层或全连接层进行剪枝;非结构化剪枝则对模型的参数进行优化,通常是通过数值的大小来判断参数的重要性,然后将数值较小的参数删除掉。
模型剪枝就像是整理植物的枝干一样,将模型中不必要的枝干切除,让模型更加紧凑。就像一个苹果树上的枝干一样,如果有太多的枝干,会浪费苹果树能量的同时也会影响果实的质量和产量。同样的,模型中的参数如果过多,会降低模型的训练速度和推理速度,同时也可能会过拟合数据。因此我们需要通过剪枝来减少模型中的不必要的权重和神经元。
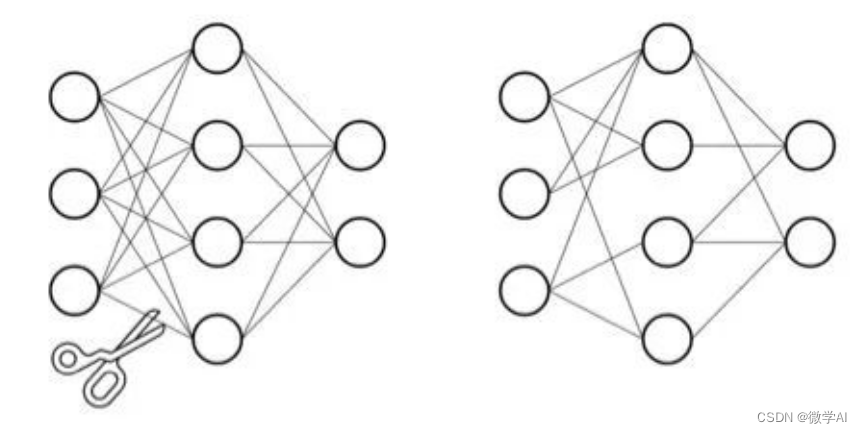
在模型剪枝中,我们对模型中的一些参数做出修改,使得它们的影响减少,从而降低整个模型的冗余度。这些修改包括减少层数,减小卷积核的大小,以及删除某些层中不需要的节点等。通过这些修改,在不影响模型精度的前提下,我们可以减少模型的大小和训练时间。

二、模型剪枝代码案例
在PyTorch框架中,可以通过torch.nn.utils.prune库中的函数来实现模型剪枝。我将使用ResNet18模型,在训练MNIST数据集时进行结构化剪枝,从而削减卷积层的参数量。
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128,
shuffle=False, num_workers=2)
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64))
self.layer2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(128))
self.layer3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256))
self.layer4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(512))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, 10)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
#模型剪枝
def model_pruning(model):
layer1 = model.conv1
prune.random_unstructured(layer1, name="weight", amount=0.3)
prune.remove(layer1, 'weight')
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.5)
prune.remove(module, 'weight')
elif isinstance(module, torch.nn.Linear):
prune.l1_unstructured(module, name='weight', amount=0.5)
prune.remove(module, 'weight')
return 0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = ResNet18()
model_pruning(net)
net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)在模型中对ResNet18的所有Conv2d,Linear层进行剪枝,使用L1正则化的方法,将50%的权重参数裁剪掉。代码使用`self.named_modules()`遍历了模型中的所有层,当遇到一个`nn.Conv2d`层时,就使用`prune.l1_unstructured`函数对其进行剪枝。`prune.l1_unstructured`剪枝方法会移除模块中最小的abs(weight)* amount个参数,并将它们设置为0。其中,`amount`表示要裁剪掉的权重比例,这里设置为0.5即50%。
模型剪枝后主要的变化主要有:
1.部分权重参数被裁剪掉了,模型的稀疏性增加。
2.网络的计算复杂度会减小,从而在一定程度上提高了推理速度。
3.可能会对模型的精度产生一定的影响,因为裁剪掉的参数中可能包含了一些对模型来说很重要的信息。
模型训练:
if __name__=="__main__":
for epoch in range(1): # 训练5个轮次
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2 == 0: # 每100个批次输出一下当前的训练状态
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2))
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))获取更多资料,请持续关注!