损失函数前面说过,是作为衡量模型输出与真实标签间的差异
在学习过程中,我们常常听到代价函数(cost function),目标函数(objective function)这些和损失函数区别和联系如下:
损失函数,一般用来衡量样本(或一批(batch)样本)中输出与真实标签的差异(即考虑单样本)
公式:
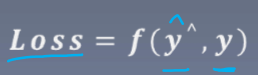
代价函数:用来求整个数据集中的损失函数的平均值(即衡量总体)
公式:
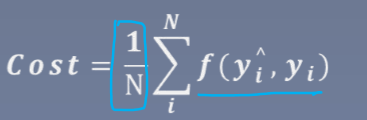
目标函数:有两部分组成,代价函数加正则项(regulation term)
扫描二维码关注公众号,回复:
11461455 查看本文章


其中减少代价函数的目的是用来控制与真实标签的差异,正则项则是用来控制过拟合
常见的损失函数
MSE(均方误差项)
作用:输出与标签之差的平方均值,常用在回归任务中
公式:
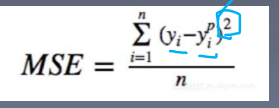
(yp即预测的标签)
交叉熵
衡量分布间的差异,常用在分类任务中
公式:
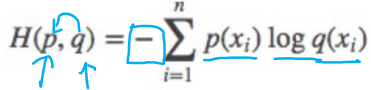
p:真实的标签 q:预测的标签
相对熵,交叉熵,信息熵
这些都是信息论中的概念,在机器学习中也经常用到
相对熵:
又被称为Kullback-Leibler散度,是两个概率分布(probability distribution)间差异的非对称性度量(即衡量分布间的差异)
公式:

交叉熵
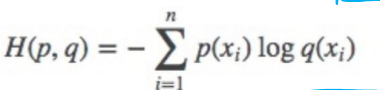
信息熵:
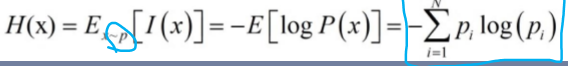

因此,优化交叉熵即等于优化相对熵
但是前面要求要讲模型输出要是概率分布的形式,那么如何确保模型的输出是这个形式呢?因此要引入softmax函数,将数据转化成概率分布的形式
概率分布有两个要求
1 概率值是非负的
2 概率之和为一
而softmax的公式:
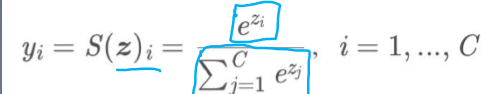
其中
1 取指数的形式来实现非负
2 除以指数之和来实现和为1