主要内容
1.摘要
在本篇中,我将为大家分析股票市场的交易策略,如何通过机器学习分析股票市场数据,制定交易策略。我将从技术层面结合业内常识对数据进行数据挖掘。我将使用pandas_datareader来导入我们的数据,这将使我们能够访问几个股票数据的来源,包括雅虎,谷歌。
接下来,开启我们的数据挖掘过程吧。从整个过程探索股票市场的交易策略。
2.案例探索
2.1.首先,导入需要的包和股票数据
import pandas as pd
import numpy as np
from pandas_datareader import data, wb
import pandas_datareader as pdr
import matplotlib.pyplot as plt
%matplotlib inline
start_date = pd.to_datetime('2005-01-01')
end_date = pd.to_datetime('2018-12-30')
data = pdr.data.get_data_stooq("SPY",start_date,end_date)
data = data.sort_index()
data.head()
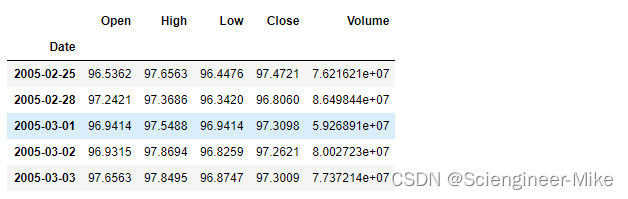
上述的数据分别为开盘价,最高价,最低价,收盘价以及交易量。接下来,我们绘制下2005-2018年收盘价的变化趋势。这里我们看到SPY从 2005 年初到 2018 年 12 月 1 日的价格走势。在此期间,市场无疑出现了许多波动,因为市场经历了高度积极和高度消极的局面。

2.2.数据分析流程
接下来,我们用第一天的开盘价减去最后一天的收盘价,即就是我们整个过程中的收益值。
data_firstopen = data["Open"][0]
data_lastclose = data["Close"][-1]
data_lastclose - data_firstopen

我们再用每天的收盘价减去开盘价,然后求和,看看白天持有的收益值。
data_mp = data["Close"] - data["Open"]
data_mp.sum()

所以,正如你所看到的,我们已经从超过 137 点的收益变成了刚刚超过 2.3 点的收益。所以说,整个市场收益的大部分来自这一时期的隔夜持有。
data_nightchange = data["Open"] -data["Close"].shift(1)
np.std(data_mp.values),np.std(data_nightchange)

因此,与日内交易相比,我们的隔夜交易不仅收益更高,而且波动性也更低。但并非所有的波动都是平等的。
data_mp[data_mp<0].mean(),data_nightchange[data_nightchange<0].mean()
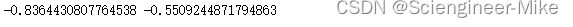
通过上面求均值,我们可以得到隔夜交易策略的平均下行波动远小于我们的盘中交易策略。接下来,我们来看看每日回报。这将有助于把我们的得失放到一个更现实的背景中。包括每日回报(接近收盘变化)、日内回报和隔夜回报。
# 每日回报
daily_rtn = (data["Close"] - data["Close"].shift(1))/data["Close"].shift(1)*100
# 日内回报
id_rtn = (data["Close"] - data["Open"])/data["Open"]*100
# 隔夜汇报
on_rtn = (data["Open"] - data["Close"].shift(1))/data["Close"].shift(1)*100
现在让我们来看看这三种策略的统计数据。我们将创建一个函数,他可以返回我们想要返回的自定义需求。我们将获得我们的每一次赢、输和盈亏平衡交易的统计数据,以及一种叫做夏普比率的东西。我之前说过,回报是在风险调整的基础上判断的;这正是夏普比率提供给我们的;这是一种通过计算回报的波动性来比较回报的方法。这里,我们使用夏普比率,并对比率进行年度调整。
# 自定义函数进行包装数据
def get_stats(s,n=252):
s = s.dropna()
wins = len(s[s>0])
losses = len(s[s<0])
evens = len(s[s==0])
mean_w = round(s[s>0].mean(),3)
mean_l = round(s[s<0].mean(),3)
win_r = round(wins/losses,3)
mean_trd = round(s.mean(),3)
sd = round(np.std(s),3)
max_l = round(s.min(),3)
max_w = round(s.max(),3)
sharpe_r = round((s.mean()/np.std(s))*np.sqrt(n),4)
cnt = len(s)
print('Trades:', cnt,'\nWins:', wins,'\nLosses:', losses,'\nBreakeven:', evens,'\nWin/Loss Ratio', win_r,
'\nMean Win:', mean_w,'\nMean Loss:', mean_l,'\nMean', mean_trd,'\nStd Dev:', sd,'\nMax Loss:',\
max_l,'\nMax Win:', max_w,'\nSharpe Ratio:',sharpe_r)
查看每日回报的统计数据
get_stats(daily_rtn)

查看当天回报的统计数据
get_stats(id_rtn)

查看隔夜回报的统计数据
get_stats(on_rtn)
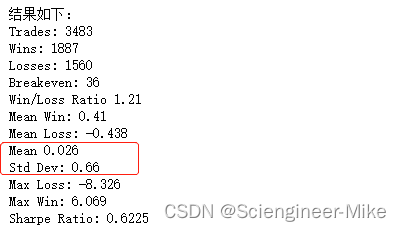
通过以上得到的结论:每日回报平均回报率最高,标准差也最高。它也有最大的每日提款(损失)。你还会注意到,即使隔夜策略的平均回报率高于日内策略,它的波动性也要小得多。这反过来又使其夏普比率高于日内策略。
3.建立回归模型
首先,建立一个包含每天价格的数据,我们将在模型中包含过去的20次收盘。
for i in range(1,21,1):
data1.loc[:,"Close Minus " + str(i)] = data1["Close"].shift(i)
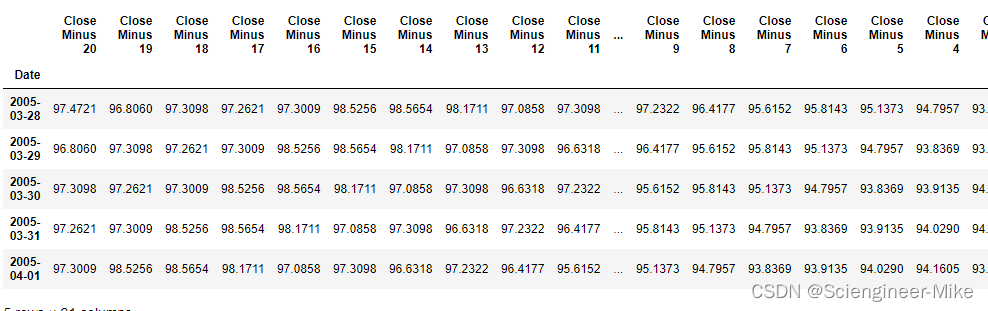
data1_20 = data1[[x for x in data1.columns if "Close Minus" in x or x == "Close"]].iloc[20:,]
data1_20 = data1_20.iloc[:,::-1]
data1_20.head()
3.1.搭建随机森林回归进行数据预测。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 划分数据
y = data1_20["Close"].shift(-1)[1:-1]
X = data1_20.drop(["Close"],axis=1)[1:-1]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
# 建模分析
clf = RandomForestRegressor()
model = clf.fit(X_train,y_train)
pred = model.predict(X_test)
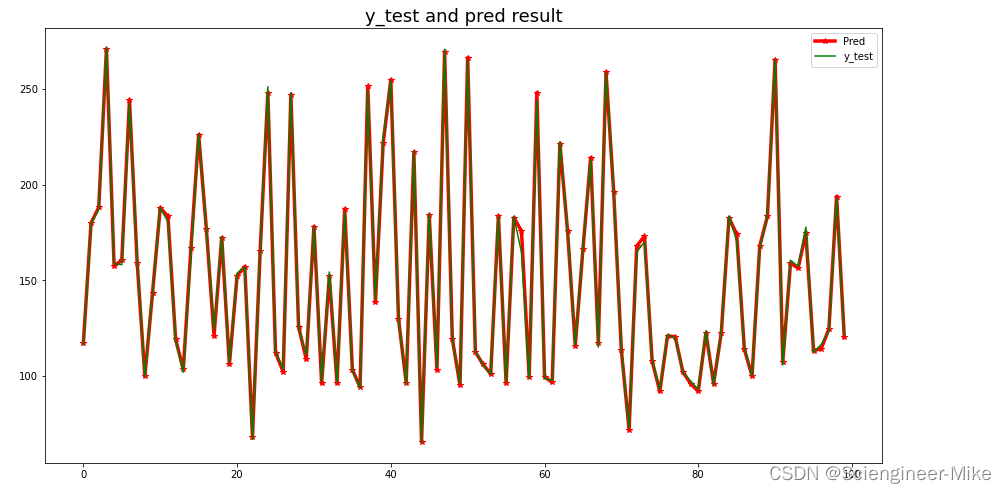
结果绘制
plt.figure(figsize=(15,8))
plt.plot(pred[:100],color="red",marker="*",linewidth=3.5,label="Pred")
plt.plot(y_test.values[:100],color="green",label="y_test")
plt.title("y_test and pred result",fontsize=18)
plt.legend()
plt.show()
3.2.搭建LSTM进行数据预测。
# 导入相应的包
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM,Dense,Dropout
from keras import optimizers
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
y = data1_20["Close"].shift(-1)[1:-1]
X = data1_20.drop(["Close"],axis=1)[1:-1]
# 归一化数据
MMS = MinMaxScaler()
X = MMS.fit_transform(X)
y = MMS.fit_transform(np.array(y).reshape(-1,1))
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
# 增加数据维度方便导入模型
X_train = np.expand_dims(X_train,axis=2)
X_test = np.expand_dims(X_test,axis=2)
# 使用keras建立model,并训练
def build_model():
model = Sequential()
model.add(LSTM(50,return_sequences=True,input_shape=(20,1)))
model.add(LSTM(30))
model.add(Dropout(0.2))
model.add(Dense(1,activation='relu'))
model.compile(loss = 'mse',optimizer = "adam")
return model
model_lstm = build_model()
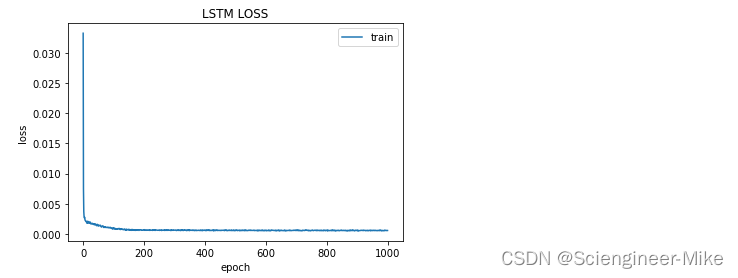
history = model_lstm.fit(X_train,y_train,verbose=0,epochs=1000,batch_size=128)
plt.plot(history.history['loss'], label='train')
plt.title('LSTM LOSS', fontsize='12')
plt.ylabel('loss', fontsize='10')
plt.xlabel('epoch', fontsize='10')
plt.legend()
plt.show()
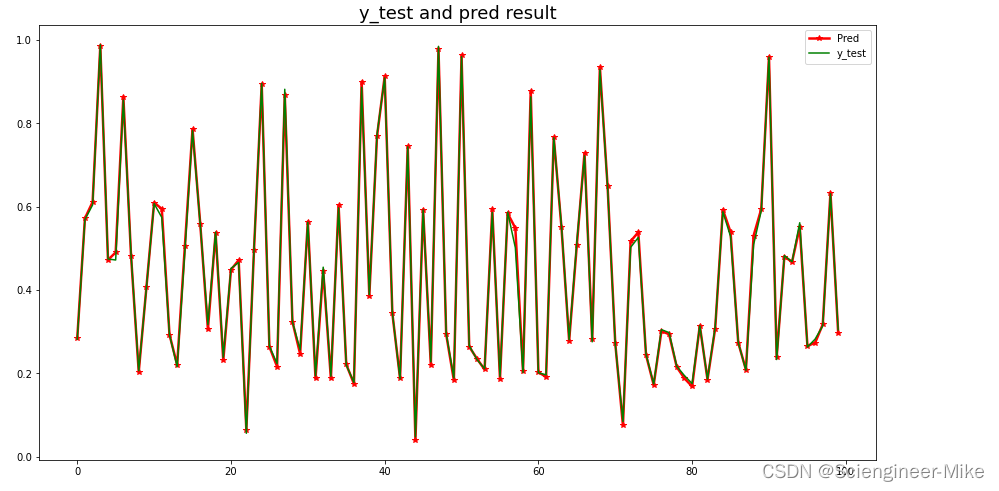
plt.figure(figsize=(15,8))
plt.plot(model_lstm.predict(X_test)[:100],color="red",marker="*",linewidth=2.5,label="Pred")
plt.plot(y_test[:100,:],color="green",label="y_test")
plt.title("y_test and pred result",fontsize=18)
plt.legend()
plt.show()
对归一化后的数据进行预测,预测值与真实值基本完全吻合。
4.平滑+LSTM搭建模型
4.1.什么是平滑?
原始数据的预处理取决于数据和用例需求。然而,每种类型的数据都有特定的标准预处理技术。与我们目前所见的数据集不同,我们认为每个观察值都独立于其他(过去或未来)观察值,时间序列与历史观察值有着内在的相关性。时间序列数据的一个固有属性是,除了它的其他成分之外,它还具有随机变化。为了更好地理解、建模和利用预测相关任务的时间序列,我们通常执行一个预处理步骤,更好地称为平滑。平滑有助于减少随机变化的影响,并有助于清楚地揭示序列的季节性、趋势和残差成分。有多种方法可以平滑时间序列。以下主要介绍移动平均数和指数平滑法两种平滑预处理方法。
(1)移动平均法:我们通过移动窗口的方法,将连续的n个值的平均值作为当前值,以消除随机变化对于值的影响,公式如下:
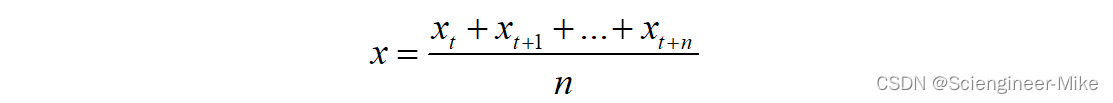
代码实现:
test = data["Close"].rolling(window=3,center=False).mean()
fig = plt.figure(figsize=(15,6))
plt.plot(data["Close"][:400],"-",color="black",alpha=3)
plt.plot(test[:400],color="red")
plt.legend()
plt.show()
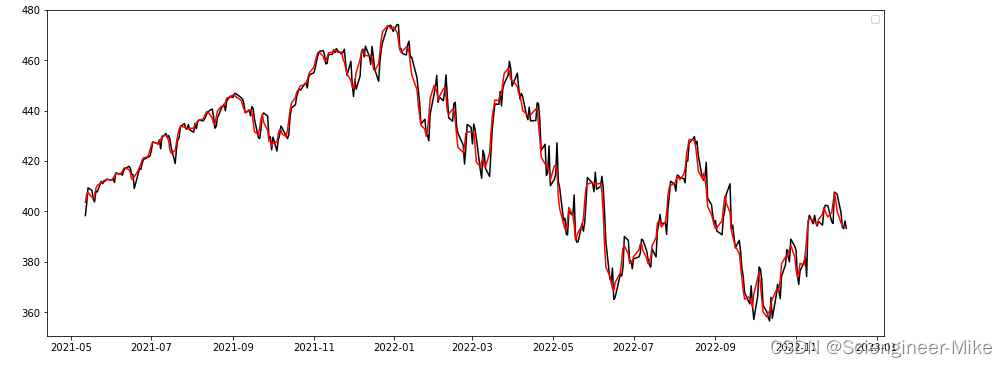
曲线显示了平滑后的访问时间序列。平滑后的系列始终保持原始系列的整体结构,同时减少其中的随机变化。
(2)指数平滑法:指数平滑技术将指数递减的权重应用于旧的观测值,公式如下:
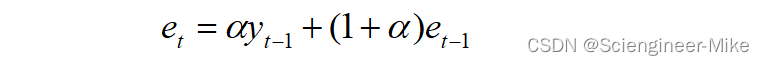
et为第t次平滑后的观测值,y为t-1时刻的实际观测值,α为0-1之间的平滑系数。
代码实现:
test2 = data["Close"].ewm(halflife=2,ignore_na=False,min_periods=0,adjust=True).mean()
fig = plt.figure(figsize=(15,6))
plt.plot(data["Close"][:400],"-",color="black",alpha=3)
plt.plot(test[:400],color="red")
plt.legend()
plt.show()
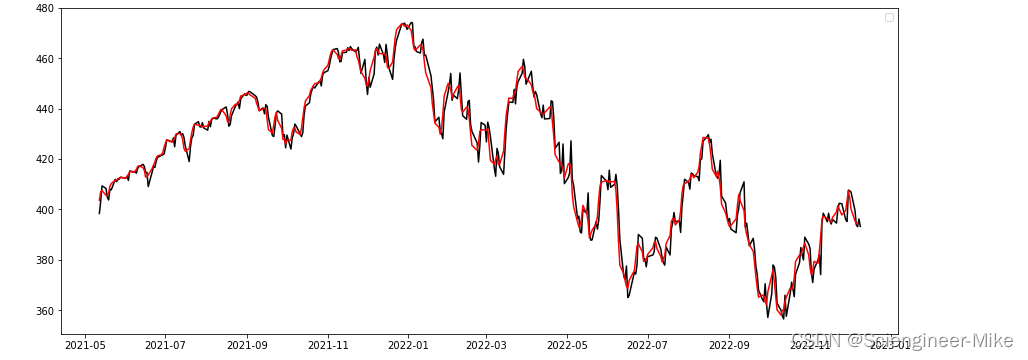
接下来,将平滑后的数据带入模型。
4.2.预处理数据搭建模型
LSTMs 接受 3D 张量作为输入,我们以(N,W,F)格式变换每个窗口(或序列)。这里,N 是原始时间序列的样本数或窗口数,W 是每个窗口的大小或历史时间步长数,F 是每个时间步长的特征数。在我们的例子中,由于我们只使用收盘价,F 等于 1,N 和 W 是可配置的。以下函数使用pandas和numpy执行窗口和 3D 张量变换。
def get_reg_train_test(timeseries,sequence_length=51,train_size=0.1,roll_mean_window=5,normalize=True,scale=False):
# 平滑操作
if roll_mean_window:
timeseries = timeseries.rolling(roll_mean_window).mean().dropna()
# 创建数据窗口
result = []
for index in range(len(timeseries) - sequence_length):
result.append(timeseries[index:index+sequence_length])
# 归一化
if normalize:
normalize_data = []
for window in result:
normalized_window = [((float(p)/float(window[0]))-1) for p in window]
normalize_data.append(normalized_window)
result = normalize_data
#划分训练集和测试集
result = np.array(result)
print(result.shape)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
if scale:
MMS = MinMaxScaler()
result = MMS.fit_transform(result)
result_x = result[:,:-1]
result_x = np.expand_dims(result_x,axis=2)
result_y = result[:,-1]
Xtrain,Xtest,Ytrain,Ytest = train_test_split(result_x,result_y,test_size=train_size,random_state=0)
return Xtrain,Xtest,Ytrain,Ytest
Xtrain,Xtest,Ytrain,Ytest = get_reg_train_test(data["Close"],sequence_length=7,roll_mean_window=5,normalize=True,scale=False)
model1 = Sequential()
model1.add(LSTM(50,return_sequences=False,input_shape=(6,1)))
model1.add(Dropout(0.2))
model1.add(Dense(1))
model1.compile(loss="mse",optimizer="adam",metrics=["acc"])
history = model1.fit(Xtrain,Ytrain,epochs=500,verbose=0,batch_size=64)
# 绘制结果
fig = plt.figure(figsize=(15,8))
plt.plot(model1.predict(Xtest)[:150],"-",color="red",linewidth=2,label="Pred_value")
plt.plot(Ytest[:150],"--",color="green",linewidth=2,label="True_value")
plt.legend()
plt.show()
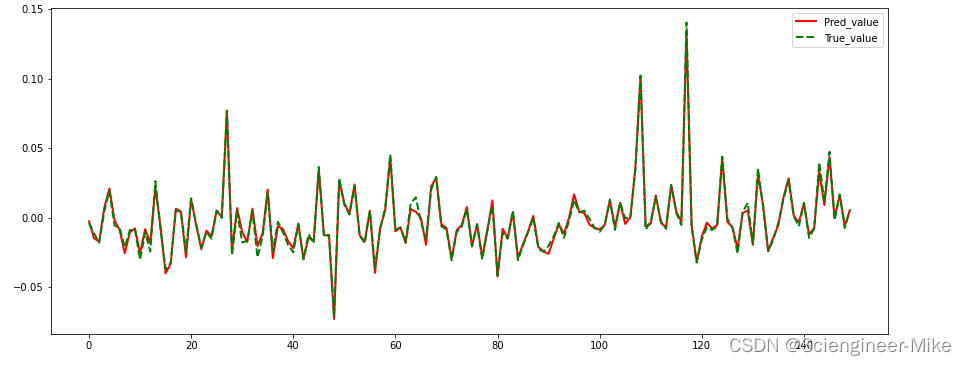
5.总结
至此,我们分别采用LSTM和RandomForest的方法对股票市场数据的分析预测,并在第四小节,添加了属于数据平滑预处理技术,避免异常值的影响,重新使用LSTM进行建模,预测效果也是十分优秀的。希望对大家有所启示。