论文一、多域构建为一个整体graph

论文标题:HeroGRAPH: A Heterogeneous Graph Framework for Multi-Target Cross-Domain Recommendation;
发布刊物:ResSys 2020;
论文下载链接:http://ceur-ws.org/Vol-2715/paper6.pdf
思路:现有跨域推荐系统多为 single-traget 或者 dual-traget cross-domain recommendation,前者主要致力于从源域提取信息辅助目标域的学习,后者同时利用源域和目标域的信息来提升两个域的推荐性能。但是实际生活中,更常见的是大于等于3个域的多域multi-traget系统。
如果直接将dual-traget的模型应用于multi-target任务,度量n个域两两之间的关系,会产生个对应关系,提高了复杂性。所以需要直接的multi-target的模型。
模型结构:本文通过将多域的user和item构建为一个整体的Heterogeneous graph,实现对不同域的学习。模型结构如下图1所示。对每一个域,首先用提取各自user和item的within-domain信息。
然后如下图最下面一行所示,将所有域的user和item构建为一个异构图(有一个疑问,相同user在异构图中为同一个node,那么对于不完全相同但是近似的item,如何处理呢?是分别作为node,还是相似的item合并为一个node?如何合并?)。借助于GraphSAGE和attention机制(简写为下图Embedding Layer的函数),提取cross-domain的user和item特征,学习该异构图中每一个节点的embedding。

最后,得到所有user和item的表征为:
![]()
通过对每个域中positive的user-item关系和negative的user-item关系做处理,得到每个域的loss(公式6,7),然后对所有loss求和得到本文模型的总loss,如下面的公式所示。

实验及分析:通过对不同任务下数据稀疏性的分析(稀疏性高低对应graph中存在多少user-item边),发现越是稀疏的数据上本文的模型效果越好。
总结及展望:本文最后提出了多个针对本文模型可以进行改进的点:
- 采用其他统一的整体shared结构将所有域信息联系到一起,如knowledge graph;
- 在所构建的graph中增加user proflie,item attribute等额外信息来辅助node embedding;
- 在每一个域中,可以给不同user-item赋予不同的权重;
- (在graph中,可以为同一个user的不同边赋予不同权重);
- 在整合每个域的loss时,可以给每一项loss赋予不同的权重;
- 同调不确定性Homoscedastic uncertainty可能是研究权重的一个好策略,它可以在训练中自动更新。
论文二、分别学习双域特征,合并其中重叠部分

论文标题: A Graphical and Attentional Framework for Dual-Target Cross-Domain Recommendation;
发表刊物:IJCAI 2020;
论文下载地址:A Graphical and Attentional Framework for Dual-Target Cross-Domain Recommendation | IJCAI
代码下载地址:https://github.com/FengZhu-Joey/GA-DTCDR
思路:现有的跨域推荐可以分为两种:
- single-traget Cross-Domain Recommendation问题致力于从richer domain中提取信息辅助sparser domian中的推荐准确率。
- dual-traget CDR问题致力于联合从richer domain和sparser domain中提取信息,同时提升这两个域中的推荐准确率。
一种直接的dual-traget CDR方法是将single-traget CDR的方法反过来做一遍,分别从richer -> sparser和sparser -> richer中提取信息,来辅助两个域的推荐。但是这种方法会带来negative transfer,因为sparser domain中学到的信息可能是不准确的,就会对richer domain中的推荐产生负面影响,甚至降低其推荐准确率。因此需要专门设计dual-target的方法。
针对dual-traget CDR问题,关键点在于:
- 如何从每一个域中学习和提取user和item的embedding?
- 如何优化每个域中所学emb使得两个域的推荐性能都有提升?
本文针对上述两个关键点构建dual-target CDR模型。
模型结构:
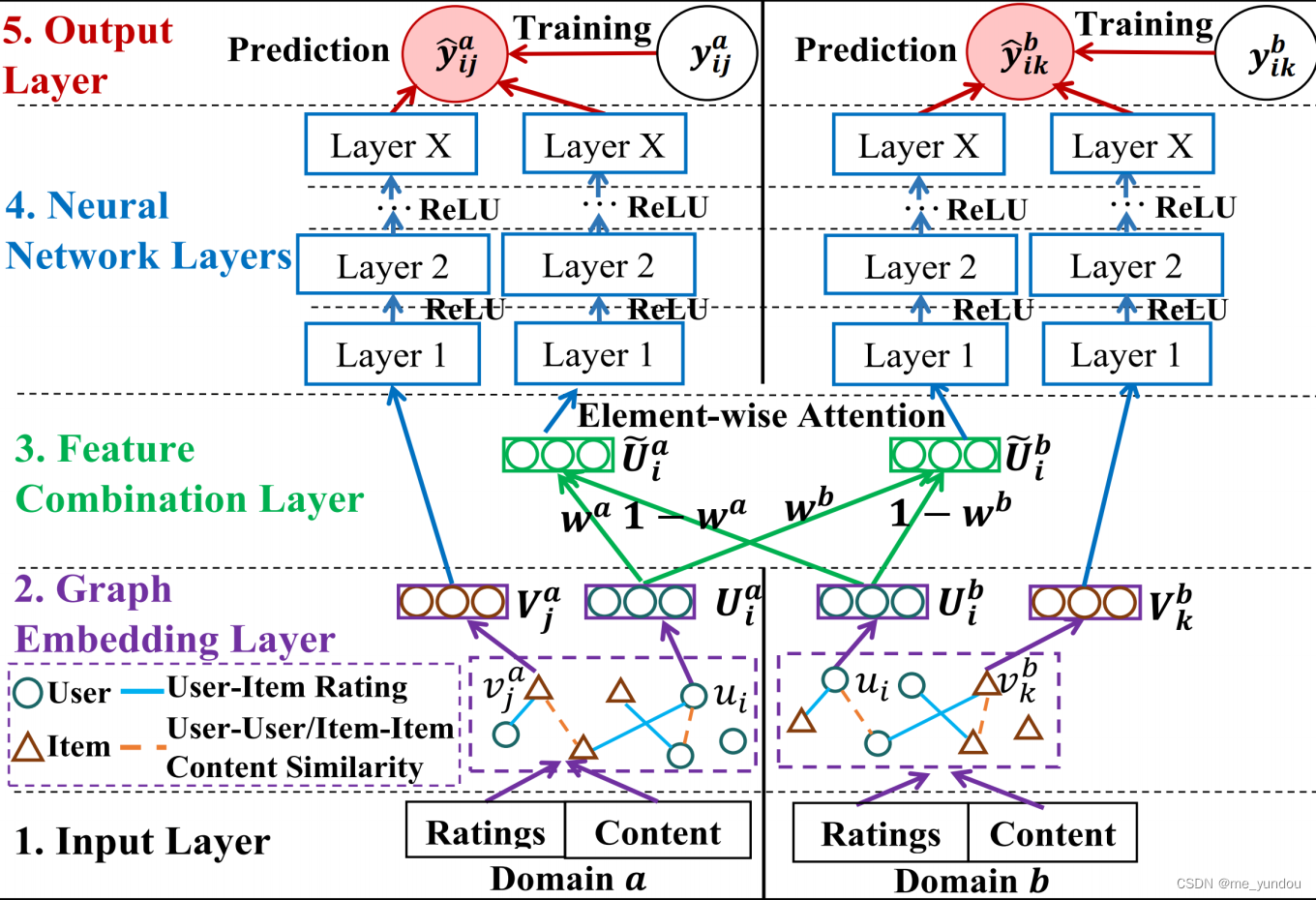
如上图所示,本文模型一共有5个部分:
- 输入层:针对每一个域,都考虑explicit信息(ratings,comments)和side信息(user profiles,item details),分别被称之为rating info和content info。
- 图编码层:针对每一个域,利用其中rating和content info构建一个异构图,其中有user-item交互边,user-user相似性边,item-item相似性边。然后采用图编码模型,比如Node2vec学习异构图中的user和item节点的embeddings,分别记为U和V。
- 特征合并层:本文提出一个element-wise的注意力机制来合并两个域中common user的emb,利用上一层两个异构图学到的user node emb。
- 神经网络层:采用全连接层来学习每个域中user和item的非线性关系。
- 输出层:对user-item交互行为进行预测。
具体而言,本文的第2层图编码层,包含以下几个步骤:
- 针对每一个user或者item,将其所有信息都整合成一个document,包括reviews, tags, user profiles, item details等,然后使用doc2vec模型得到document emb。这样就得到了每一个user和item的document emb:UC和VC。
- 针对每一个域中的异构图的构建,user-item边来自数据集中的交互信息。而user-user和item-item边都是通过相似性计算的。如下公式1,利用上一步学到的document emb,计算每两个user或者两个item之间的normalized余弦相似度,再乘上一个超参数,得到这两个user或者两个item之间存在边的概率:
![]()
总结及展望:
本文虽然是针对不同域的推荐,但是模型同样可以适用于cross-system recommendation,只需要将本文的不同domain变为不同的system,不同域中重叠的user变为不同system中重叠的item。
未来本文方法还可以扩展到multi-traget recommendation,或者其他新的推荐系统数据集,来研究数据稀疏性和common user数目对推荐性能的影响。
更多论文阅读,有待更新。。。。。。