3.2.基于FPGA的原型设计流程概述
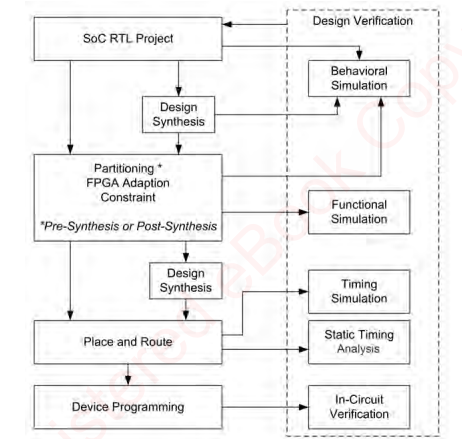
图26显示了我们在基于FPGA的原型化过程中所遵循的基本流程:让我们依次快速查看这些步骤。
-
综合: 可以在分割之前或分割之后进行。将RTL转换为FPGA网列表的过程。综合过程为所选设备生成一个FPGA网列表,以及FPGA后端工具将使用的实现约束。此外,一些综合工具提供了对预期性能的早期估计,这允许用户在可能漫长的后端过程中花费任何时间之前对设计或约束进行更改。
-
针对FPGA的设计适应:在这一步中,SoC RTL的设计被修改,以更好地适合FPGA技术和特定的原型平台。对SoC RTL的典型修改包括删除没有原型的块,用时钟生成和其他IP等FPGA结构替换一些SoC特定的结构,以及调整内存等块的大小以更好地适合FPGA。
-
分区:**分区:将SoC RTL设计的FPGA-ready版本被划分为映射到单个fpga的块的过程。**这一步对于不适合于单个FPGA的设计是必需的。分区可以手动或使用分区工具来完成。第3章探讨了一些划分的方法。
-
约束生成:**这是流中的一个方便的点,可以进入各种实现约束,如时间和针脚位置。**虽然在综合后可能会产生约束并应用于后端工具,但在综合步骤之前这样做可以使综合产生一个FPGA网表,更优化,以满足位置和路线后的面积/速度约束。
-
布局布线:将FPGA网络列表和用户约束转换为FPGA位流的过程,该位流将被加载到FPGA中,以为其提供设计功能。这通常被简单地称为地点和路线,但实际上涉及到许多步骤,如地图,地点和路线和时间分析。
我们将仔细看看所有的实现步骤,但我们不打算在这本书中涵盖验证阶段,除了建议尽可能多的现有SoC验证框架维护原型项目中使用。
在流程的所有方面,有方法来验证我们的工作是很重要的。重新使用原始的RTL测试工作台和设置,可能需要进行一些调整,以匹配分区设计。例如,在分区之后,需要一个顶级网络列表来将分区的FPGA网络列表链接到整个SoC设计中;通常这个顶级可以由分区工具自己生成。
即使不是针对整个设计,而是针对子功能,当我们需要检查工作台上设计中看到的功能问题时,维护一个验证框架会给我们回报。
3.3.在原型化过程中需要的实现工具
我们现在已经详细地探索了FPGA设备的能力,但如果它们不能轻易地用于我们的原型项目,那么它们就没有什么兴趣了。
在上面的原型实用工具框中,我们已经提到了一些资源是自动使用的,而其他资源则需要一些特别的考虑。FPGA的EDA工具充分利用设备资源的能力与资源本身同样重要。
现在,我们将概述今天FPGA流中的主要EDA工具,即综合工具、分区工具、放置和路由工具和调试工具。
我们的目标是保持解释尽可能通用,在每种情况下只给出我们自己公司的工具的小例子。关于同步系统®和Xilinx®提供的工具的更多具体细节可以通过参考文献获得。在其他章节中也有更多关于工具使用的细节,特别是在第7、8和11章中。
3.3.1.综合工具
就像几乎每一个EDA工具流一样,我们在核心找到了综合。对于基于FPGA的原型,我们发现综合将SoC RTL转换为许多FPGA网列表,供后端工具使用,然后最终放置和路由FPGA。
然而,与此同时,综合过程也被期望从RTL中推断出规则的结构,优化它们,并有效地将它们映射到FPGA中,从而满足空间和性能目标。
作为这个过程的简要说明,图27显示了一个同步系统的FPGA综合工具的屏幕截图,以及相同的小型ALU设计的三个视图。在左下角是一个文本编辑器,显示了RTL,并且在上面显示了从综合的第一阶段中提取的行为。我们可以看到一个mux根据依赖于操作码的输出来选择三种不同操作的结果。在屏幕截图的右边,我们看到了由综合创建的最终逻辑的一部分,特别注意多路复用使用lut,寄存器使用FFs和默认用于实现乘法器的DSP48块。

在上面的示例中,我们可以决定我们不想浪费像DSP48块这样强大的资源来实现一个简单的乘数,所以我们可以在RTL或并行约束文件中添加一个称为属性的额外命令,以覆盖默认映射。这正是综合用户对解释和实现RTL的方式的控制。
让我们更仔细地看看综合是将RTL映射到FPGA资源的方式。
3.3.2.将SoC设计元素映射到FPGA中
本节描述了该工具支持将SoC设计映射到FPGA中的特性,它使用了来自Xilinx®Virtex-6家族的示例FPGA设备。FPGA的许多资源对用户是透明支持的,因为综合工具自动推断FPGA结构,以用户的干预实现用户的RTL。
3.3.2.1.逻辑映射
由于逻辑是逻辑原型的主要资源,将RTL映射到clb是一个基本函数。例如,对于Xilinx®Virtex-6体系结构,综合应该能够执行以下操作:
- 推断LUT6,其中最多需要6个输入函数。当需要或多或少的输入时,lut将被级联或拆分。例如,当两个共享最多5个公共输入的函数可以占据相同的CLB时,将自动推断出双LUT5s。SLICEM类型切片中的
- 内存使用情况将被推断为实现分布式RAM和快速移位寄存器。
- 时钟启用将被推断出来,并能够重新连接低扇出时钟启用到LUTS,以最大限度地提高切片利用率。
- 设置/重置、同步或异步将被推断出来,包括防止/仲裁同时设置/重置断言,避免在硅中出现不可预测的行为。例如,Synplify Pro检测到这种可能性,发出警告,然后生成逻辑上等价的单异步重位逻辑。
3.3.2.2.内存块映射
SoC设计包括许多不同的内存元素,我们需要有效地映射这些元素,以避免浪费我们的FPGA资源。综合应该能够执行以下操作:
- 自动将单个和双端口的内存结构推断到块ram中。
- 自动将管道阶段的相邻输入和输出寄存器打包到块ram中。
- 使用BlockRAM的操作模式,包括读先、写先和无更改:保留RAM的输入或输出端口的初始值——以匹配SoC的行为。
- 自动将超出块容量的较大内存分割为多个块,并根据需要添加必要的逻辑来拆分和合并地址和数据。分裂的拓扑结构(即,根据速度或面积进行了优化)也应该是可控的。
3.3.2.3.DSP块映射
许多SoC设计包括广泛使用算术和算法函数的块。如果这些工具可以在默认情况下将它们映射到FPGA中的DSP块中,那么很大一部分的FPGA资源就可以被释放出来用于其他目的。
- 加法器/减法器: FPGA逻辑元素具有简单的门结构或配置模式,更有效地映射携带功能,使良好地实现基本算术。综合系统将自动使用这些结构。
- 乘法器:同步自动推断RTL中的功能和操作符(参见上面第3.3.1节)。
- 预加法器:在Xilinx®Virtex-6设备中,综合应该在DSP48的乘法器之前推断出一个可选的25位加法器。
- DSP级联:对于RTL中更广泛的算术,综合应该在DSP块之间使用专用的级联互连自动推断多个DSP块,例如Xilinx®Virtex-6设备中的DSP48E块之间的端口。
- 管道支持:如果管道寄存器存在于算术数据路径中,那么如果合适的话,这些数据路径将自动打包到DSP块中。
正如我们在上面看到的,FPGA综合工具对FPGA架构有深入的了解,因此作为原型,我们可以依赖大多数SoC RTL被自动有效地映射,而不必雕刻出一些RTL,并用FPGA等价的代码替换它。
3.3.3.综合与原型设计的三个“定律”
到目前为止,我们已经看到综合工具的任务是将SoC设计映射到可用的FPGA资源中。这可以自动化得越多,构建基于FPGA的原型的过程就越容易、越快。

实际上,综合的任务是面对所谓的“原型三定律”,如下表4所示。这些“定律”的明显的后果是:
- a)设计可能需要分区,
- b)设计可能不能在全SoC速度运行,和
- c)设计可能需要一些修改为了使FPGA-ready。
诚然,这些确实比法律更具挑战性,而且它们有时会被破坏,例如,一些SoC设计确实只需要一个FPGA来制作原型,从而违反了第一定律。然而,这三个定律很好地提醒了我们,在使用基于FPGA的原型设计时需要克服的主要问题,以及如何为FPGA做好设计准备所需的步骤。
下面的部分描述了综合工具中可用的主要特性,并参考了同步系统工具,但有关这些工具的进一步信息,请参阅参考文献。
执行原型设计的最重要的原因之一是,与仿真等其他验证方法相比,要获得最高的性能;然而,综合不良(或综合使用不当)可能会危及这一目标。使用快速传递的低努力综合,或减少综合的目标,以实现更快的运行时间,确实,一些综合工具允许正是为了这种权衡。然而,在一些设计块中,为了满足原型的总体性能目标,最好的综合结果是必要的。
综合的最重要的要求是克服原型设计的第三定律的含义,即在SoC设计中去除或中和FPGA-敌对的元素。只有这样,我们才能将设计有效地映射到目标FPGA的资源中,我们将在第7章中充分解释这些内容。
综合工具的许多特性通常对原型开发人员有益。这些包括:
- 快速综合:一种综合工具忽略一些机会进行完成优化的操作模式。通过这种方式,运行时可以以牺牲FPGA性能为代价,比速度快2倍-比正常速度快3倍。如果综合运行时以小时为单位,那么这种快速模式将在原型项目期间节省许多天或数周的等待时间。快速综合运行时在初始分区和实现试验中也很有用,其中只需要估计的设计大小和粗略的性能。
- 增量综合:工具与位置和路径工具的增量实现协作的特性(如下所述)。在这种操作模式中,设计被认为是每个FPGA内的块或子树。综合工具将维护每个子树的历史版本,并可以注意到新的RTL更改是否会影响每个子树。如果增量综合认识到子树没有改变,那么它将避免重新综合,而是使用该子树的历史版本,从而节省大量时间。增量综合引擎的决策被向前注释到后端位置和路由工具,作为放置约束,以便维护以前的逻辑映射和放置。考虑的增量综合使用可以显著减少FPGA板上从小的设计更改到最终实现的设计的周转时间。关于增量流的进一步细节见第11章。
- 物理综合:一种特性,其中综合为物理实现进行优化,其中工具考虑实际路由延迟,并产生位置和路由工具使用的逻辑放置约束。这一特性通常会为设计提供更快和更准确的定时闭合。这似乎与我们对上面快速综合的考虑相矛盾,但通常情况下,一个特定的FPGA在原型中努力达到全速,因此选择性地使用物理综合是一种FPGA可以更快地定时关闭的方法。
综合工具可以从第三方EDA供应商和FPGA供应商那里获得。我们将重点关注本章中必要的综合工具,但没有任何伟大的细节。有关综合系统FPGA综合的具体信息,请注意这本书后面的参考资料。
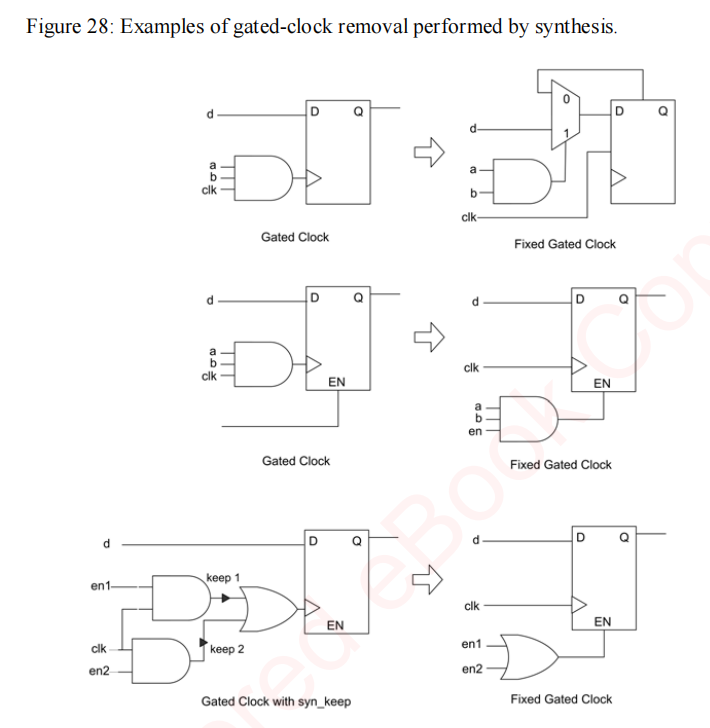
3.3.4.门控时钟映射
除了映射到FPGA资源之外,综合的一个功能是能够自动操作设计,以避免RTL的更改。这方面最重要的例子是在SoC设计中去除时钟门控,以简化对FPGA的映射。
时钟门控在SoC设计中很常见,但对于FPGA技术来说并不是一个好的选择,因为专用的低倾斜时钟分配网将无门控时钟提供到模具上的所有寄存器。与在RTL中发现的门控时钟不同,同步系统同步化®工具从时钟网中删除了组合门控,并将门控逻辑应用于FPGA中大多数顺序元素上可用的时钟启用引脚。
图28显示了一些时钟门控转换的例子,但在第7章中将会有更多关于门控时钟操作的描述。综合需要指导在哪个时钟保存,顺序元素,包括ram,如何处理时钟启用,甚至如何操纵黑盒项目。这一切都可以在不改变RTL的情况下实现。
去除时钟门后的结果实现在逻辑上等同于输入逻辑,但更具有资源效率,并且实际上消除了由于低倾斜时钟分布而造成的设置和保持时间违规。
最后,综合只是流程的一部分,一个重要的考虑是综合如何与流程的其他部分协作,特别是位置和路线后端,以确保所有工具都朝着共同的目标工作。现在让我们来看看执行设计分区的工具的重要主题。