NeRF 源码分析解读(三)
光线的生成
上一章节我们对 NeRF 模型的初始化代码进行了分析,即 create_nerf() 部分,本章节我们继续对 NeRF 代码进行分析注释。
我们回顾一下前两节的内容:
def train():
# 1、加载数据
if args.dataset_type == 'llff':
elif ...
...
# 2、初始化网络模型
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf(args)
...
if args.render_only: ...
初始化网络模型之后我们继续向下分析代码,会发现一个渲染操作的判断 if args.render_only 。在网络模型训练好以后我们保存整个网络,在测试渲染时只需要将 render_only 参数置 True,不再对网络进行训练,直接得到渲染结果。核心代码在于渲染函数,我们先不对这一块儿代码进行分析,按照训练的流程,在初始化光线以后需要渲染得到像素值,因此我们对渲染函数的分析留在光线生成之后。我们继续向下分析代码。
下面的代码会涉及到光线的生成部分,比较重要
def train():
...
# 开始读取光线以及光线对应的像素值
N_rand = args.N_rand
# 是否以批处理的形式生成光线
use_batching = not args.no_batching
if use_batching:
...
use_batching 参数决定了是否从多个角度进行光线投射。源代码中对 lego 小车重建时参数为 False,这里我们为了读者能够更好的理解,同样对这部分代码进行解析。
def train():
...
if use_batching:
print('get rays')
rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:,:3,:4]], 0) # [N, ro+rd, H, W, 3]
print('done, concats')
rays_rgb = np.concatenate([rays, images[:, None]], 1) # [N, ro+rd+rgb, H, W, 3] 这里把光线的原点、方向、以及这条光线对应的像素颜色结合到一起,便于后面的 shuffle 操作
rays_rgb = np.transpose(rays_rgb, [0,2,3,1,4]) # [N, H, W, ro+rd+rgb, 3]
rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # train images only
rays_rgb = np.reshape(rays_rgb, [-1,3,3]) # [(N-1)*H*W, ro+rd+rgb, 3]
rays_rgb = rays_rgb.astype(np.float32)
print('shuffle rays')
np.random.shuffle(rays_rgb)
print('done')
i_batch = 0
我们可以看到,这段代码的核心在于 get_rays_np() 函数,其他的操作都是一些数据的变换,因此我们对 get_rays_np() 函数进行代码分析。
def get_rays_np(H, W, K, c2w):
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy')
dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d))
return rays_o, rays_d
np.meshgrid(a, b,indexing = "xy") 函数会返回 b.shape() 行 ,a.shape() 列的二维数组。因此 i, j 都是 [H, W] 的二维数组。i 的每一行代表 x 轴坐标,j 的每一行代表 y 轴坐标。如此一来我们的到了一个图片的每个像素点的笛卡尔坐标。
我们回到第二节提到的相机内参 K
K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
我们利用相机内参 K 计算每个像素坐标相对于光心的单位方向:
dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
我们对计算公式进行分析。如下图所示,在相机坐标系下根据小孔成像原理求解像素平面上一点到相机光心的方向:
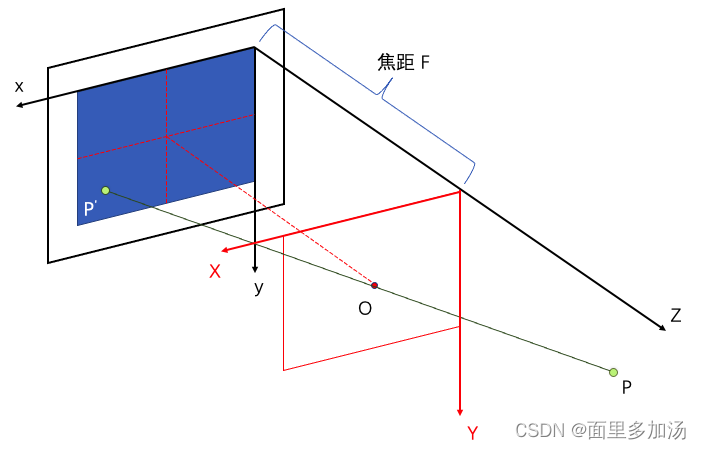
如图,空间中一点 P 经过光心 O (小孔)在成像平面上呈一点 P’ ,并且呈一个倒立的像。我们以光心所在的面建立相机坐标系,那么光心所在的位置可以表示为 ( W 2 , H 2 , 0 ) (\frac{W}{2} ,\frac{H}{2}, 0 ) (2W,2H,0) ,成像点 P’ 的位置可以表示为 ( i , j , − f ) (i ,j,-f) (i,j,−f) 。
由此两点位置,我们可以确定一个方向向量 O P ′ → = ( i − W 2 , j − H 2 , − f ) \overrightarrow{OP'} = (i - \frac{W}{2}, j - \frac{H}{2}, -f) OP′=(i−2W,j−2H,−f) 。由于小孔成像呈一个倒立的像,因此我们对 O P ′ → \overrightarrow{OP'} OP′ 的 Y 轴坐标取反,并对 O P ′ → \overrightarrow{OP'} OP′ 的 Z 轴归一化。我们得到一个新的方向向量: ( ( i − W 2 ) / f , − ( j − H 2 ) / f , − 1 ) ((i - \frac{W}{2})/f, -(j - \frac{H}{2})/f, -1) ((i−2W)/f,−(j−2H)/f,−1) 。
由此公式我们得到每个像素点关于光心 O 的方向 dirs 。随后我们利用相机外参转置矩阵将相机坐标转换为世界坐标。
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1)
事实上 get_rays() 函数与 get_rays_np() 函数基本是一致的,只不过是 torch.meshgrid(a, b) 返回的是 a.shape() 行 ,b.shape() 列的二维数组。因此需要一个转置操作 i.t() ,其余步骤相同。
至此我们生成了每个方向下的像素点到光心的单位方向(Z 轴为 1)。我们有了这个单位方向就可以通过调整 Z 轴坐标生成空间中每一个点坐标,借此模拟一条光线。
光线生成步骤基本结束,后续我们开始分析训练步骤中关于批处理光线以及空间中位置生成的部分 NeRF 源码分析解读(四)。