CV Master基于神经网络的3D重建(NeRF, SDF 等)_哔哩哔哩_bilibiliCV Master基于神经网络的3D重建(NeRF, SDF 等)共计4条视频,包括:L1 NeRF及Plenoxel理论入门、L2 基于NeRF和SDF的三维重建与实践、L3 NeRF在实际场景中的应用等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1Jt4y1x7PJ/?vd_source=4aed82e35f26bb600bc5b46e65e25c22https://gitee.com/leeguandong/introduction-neural-3d-reconstruction
https://www.bilibili.com/video/BV1Jt4y1x7PJ/?vd_source=4aed82e35f26bb600bc5b46e65e25c22https://gitee.com/leeguandong/introduction-neural-3d-reconstruction![]() https://gitee.com/leeguandong/introduction-neural-3d-reconstruction
https://gitee.com/leeguandong/introduction-neural-3d-reconstruction
左边是计算机视觉,输入图片,通过神经网络来认识图片,右侧是计算机图形学,恰好相反,图形学是已知场景,来获取该场景的图片。下图就是有一些图片,希望重建这些图片的位姿,一张图片的位姿其实就是拍这张图片时相机的位姿。
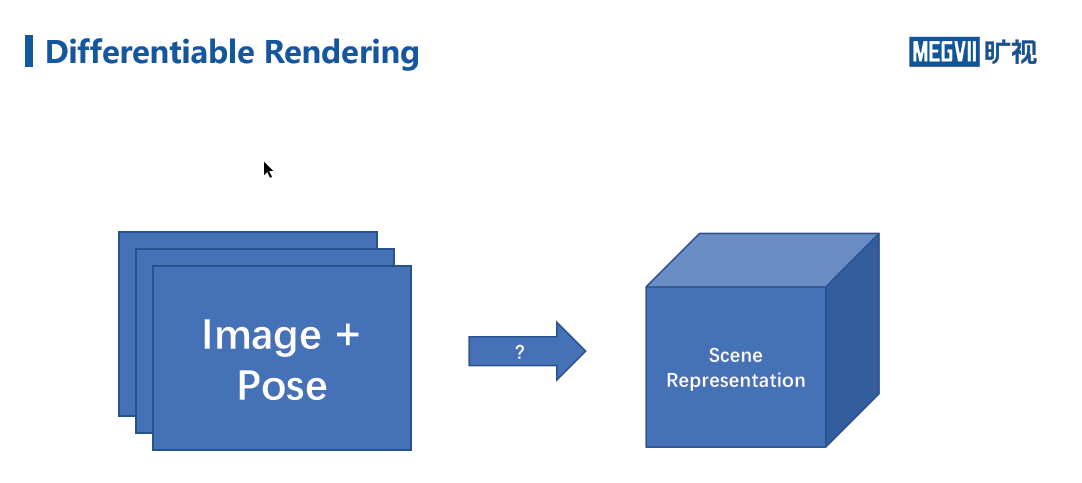
相机在空中有三个旋转自由度加上位置信息, 想重建下面架子鼓的场景,有很多照片,每个照片相机的位置如下分布,基本是个半球形的盖子。
 对于一个计算机图形学的问题,如果已知架子鼓的场景表示,那么根据这些位姿就可以渲染出很多架子鼓的照片
对于一个计算机图形学的问题,如果已知架子鼓的场景表示,那么根据这些位姿就可以渲染出很多架子鼓的照片

如果图形学的这个过程是可微的,那么我们如果有一堆图片,那么可以将图片作为GT,对每张图的位姿都做一个渲染能够获得一个渲染图,将渲染图和GT算一次loss,由于渲染过程可微,用loss直接更新场景的表示,通过反复更新,实现计算机视觉的需求,即从图片把场景还原出来。
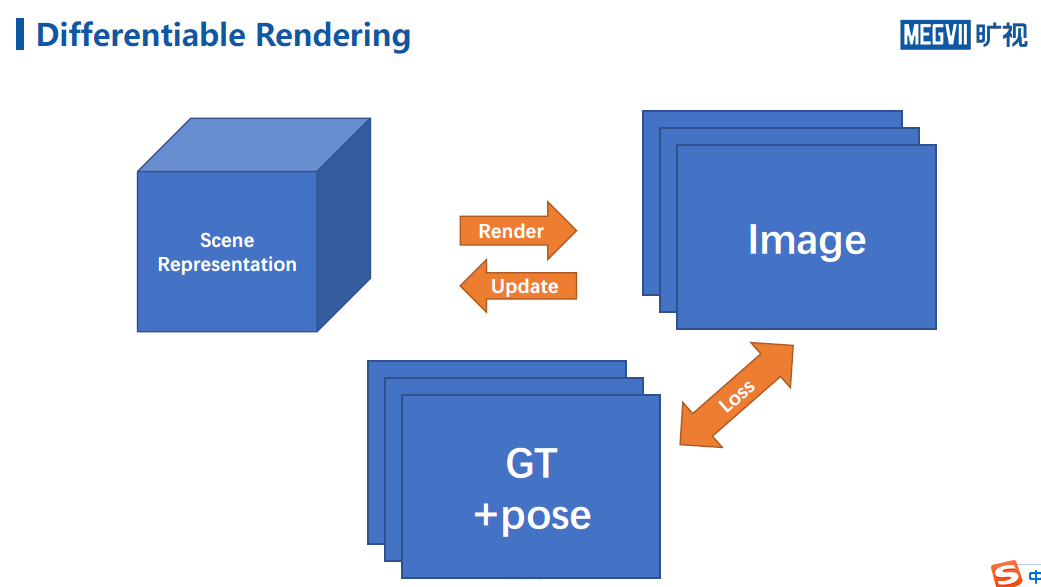
如果有场景,那么可以渲染不同角度的图片,重建出场景以后,就可以排除连续的图片。

 从一堆图片中获取场景表示,体积渲染,对于空间中的每一点,都有一个密度,下图中猪蹄认为是密度很高的点,空气是没有密度的点。
从一堆图片中获取场景表示,体积渲染,对于空间中的每一点,都有一个密度,下图中猪蹄认为是密度很高的点,空气是没有密度的点。
对于这样一个物体,拍摄一个照片,一条光线从右边达到左边来,光线被不透明度所吸收,最终到达相机。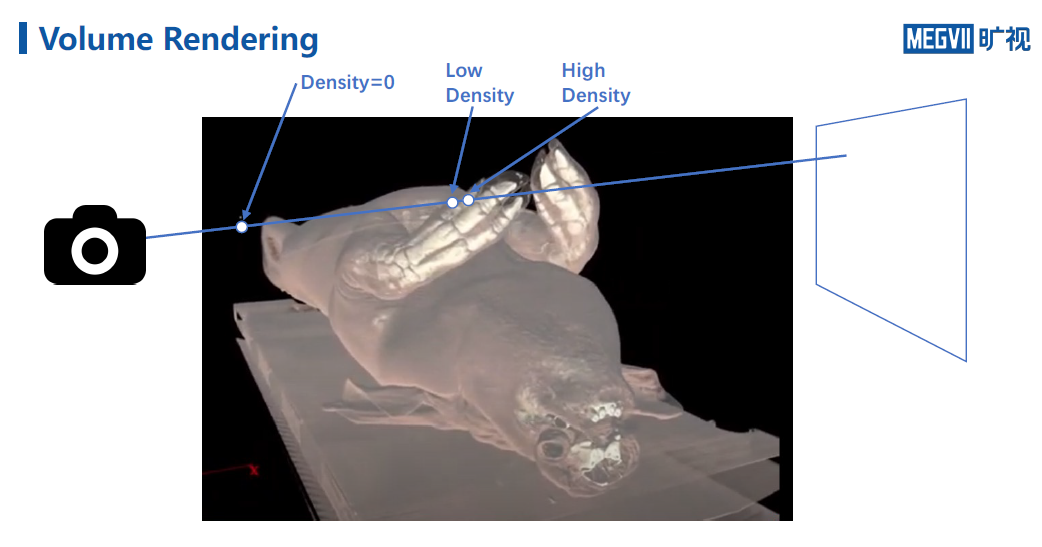
下图有一个滤镜,不透明度是0.6,也就是1的光线只能通过0.6的光线,不透明度和密度的关系如右侧公式所示,dh是滤镜的厚度,不透明度和厚度相除得到密度,想象一下如何物体都是dh的组合,那么可以得到关于密度的积分,T就是光线所剩的透光率。
下图想象一下光从相机出发,光路可逆,经过猪蹄时,密度变大,则被吸收的光变多,透过率变小。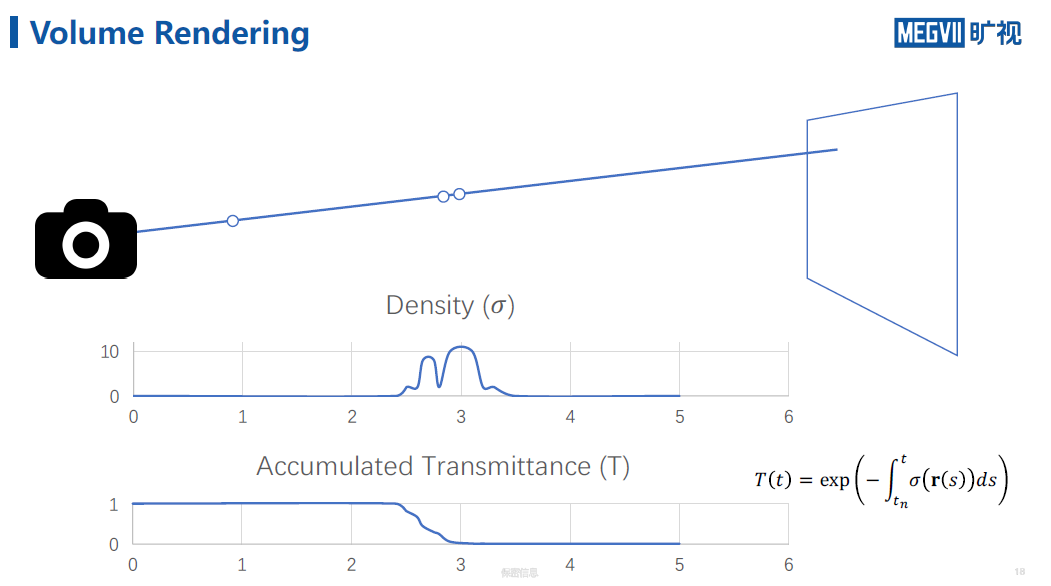
假设空间中每个点不仅有一个密度还有一个颜色,则光路积分如下,光线所剩的透光率,当前位置的密度和当前位置的颜色的积。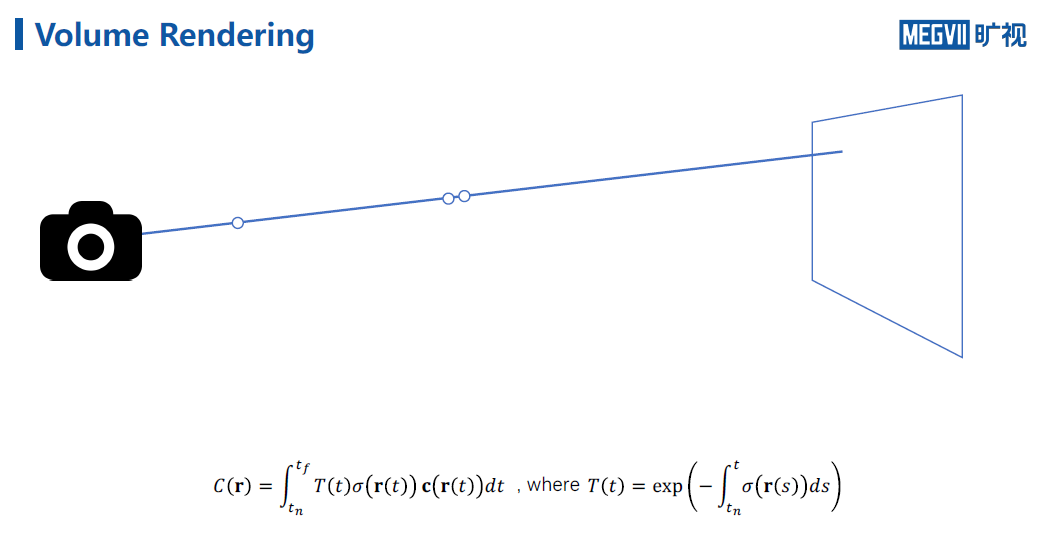
假设空间每个点的颜色是一个固定的值,是不对的,每个点离光源距离不同,颜色是有区别,空间中同一个点从不同角度看,颜色是不一样的,在c中增加观察角度d,即颜色不仅是当前位置的函数,还是观察角度的函数。
积分很难计算,要做离散化,即在空间中进行采样一些点,将密度函数换成一个分段函数,下面的公式是离散化的结果,并且可微。
nerf有很多图片的输入,经过渲染方程,即上面公式,可以得到场景表示。
输入位置坐标和像素,训练一个mlp,上图是gt,下图是恢复的,由三角形可能是因为用了relu,相当于模型把每个位置的rgb都记下来了。

坐标进行位置编码后,送入模型,相当于模型能把编码记下来进行还原。
输入是5位,是入射光线角度,从球心到球表面的一个点,需求经度和纬度两处来表示,输出空间中每个位置和入射角度都能知道

空间上的点从不同角度看,颜色可以不一样,但是透明度不一定是不一样的,从物理属性上不应该不一样,通过模型来限制。
入射角度不影响透明度,入射角度只影响颜色。

在空间上进行采样,但是这样均匀采样是比较浪费的,实际只有那么一小块是有透明度的,有物体的,和anchor一样,因此如何采样?先训练一个网络来找采样区域,先采样一个粗采样,再用一个fine采样。
plenoxels加速训练
体素,三维数据,对于整数点是有颜色,对于非整数点插值。
球表面的函数可以表示成这些正交基的线性组合





