
文章目录
论文:A Dual Weighting Label Assignment Scheme for Object Detection
代码:https://github.com/strongwolf/DW
出处:CVPR 2022
一、背景
Label Assignment 的目标是给每个 anchor 分配其 loss weight 的正或负,现有的方法一般都主要设计正样本的权重函数,负样本的权重直接从在正样本的基础上获取。这种方法缺少了一些可学习的能力。
现有的 cls loss 如下:
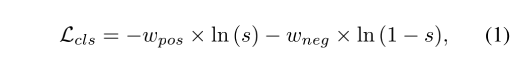
- w p o s w_{pos} wpos 和 w n e g w_{neg} wneg 分别为正样本的负样本的权重
- s s s 是预测的类别得分
根据 w p o s w_{pos} wpos 和 w n e g w_{neg} wneg 的设计模式,可以分为 hard 和 soft Label Assignment:
-
Hard Label Assignment:认为每个 anchor 非负即正,也就是 w p o s w_{pos} wpos, w n e g ∈ { 0 , 1 } w_{neg} \in \{0, 1\} wneg∈{ 0,1},且 w p o s + w n e g = 1 w_{pos} + w_{neg} = 1 wpos+wneg=1,中心思想是寻找一个分割边界来将 anchor 分为正样本和负样本,一般使用 IoU 或 anchor 距离 gt 中心点的距离来判定,但这样的规则忽略了一个问题,就是不同尺度和形状的目标的区分边界应该是不同的。
此外,也有一些动态分配的方式,如 ATSS,基于 IoU 的分布情况,将 IoU 大于 [均值+方差] 的 anchor 划分为正样本。还有 prediction-aware 的分配方法,将预测的置信得分作为判定因子,来估计 anchor 的质量。
这些方法没有考虑到 anchor 的重要程度应该是不同的,目标检测中的衡量方式应该同时考虑分类得分和定位质量,也就是说在训练的时候,分类头和回归头都是很重要的。
-
Soft Label Assignment:GFL 和 VFL 是两个典型的基于 IoU 的 soft label,TOOD 和 Mutual supervision 同时考虑回归得分和分类得分,计算得到了 anchor 的权重。
这些方法主要考虑正样本权重函数的设计,缺失了负样本的设计,这种耦合的加权方式不能很细致的区分训练样本。
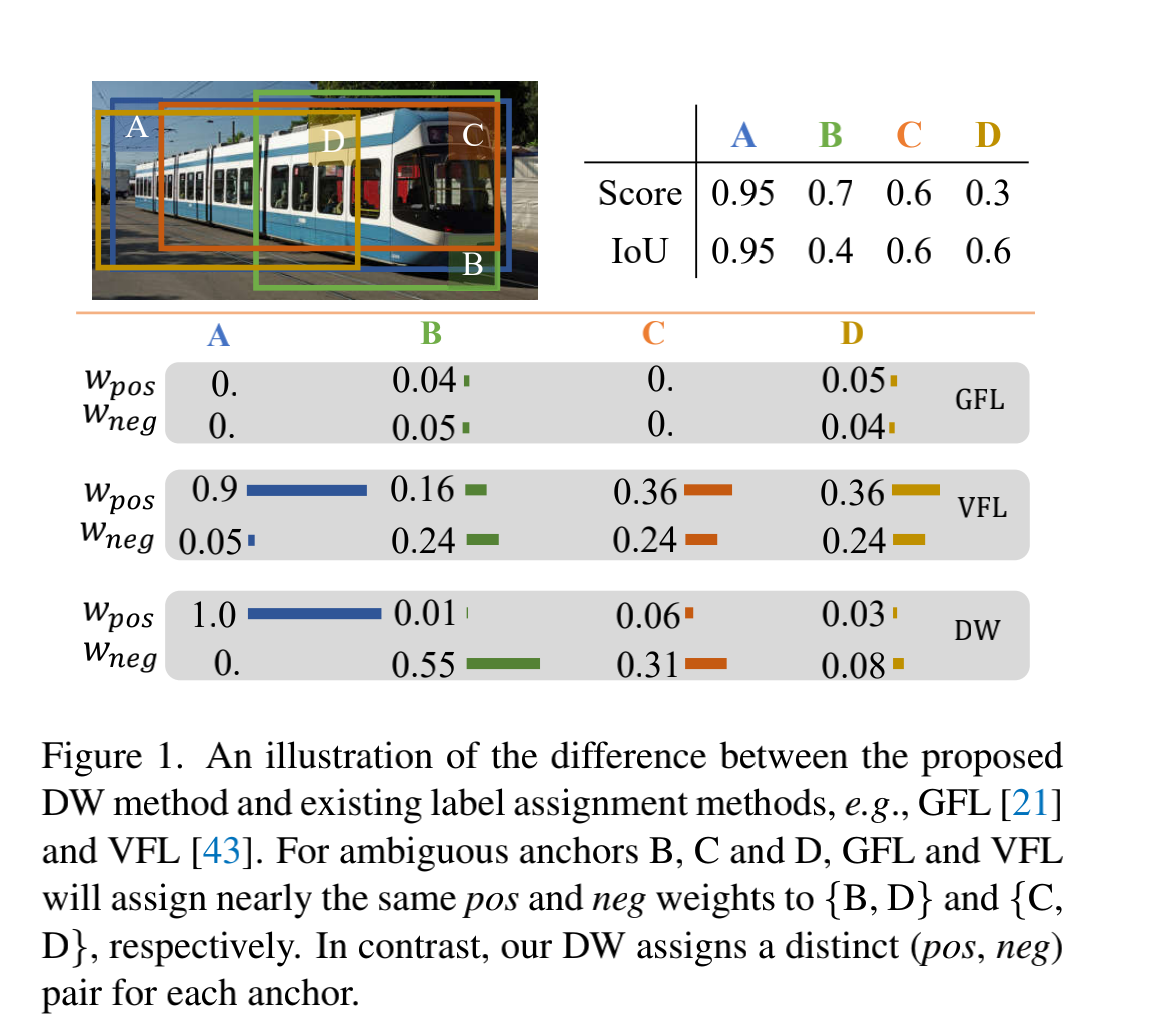
图 1 展示了 4 种不同的预测结果,GFL 和 VFL 给 (B, D) 和 (C, D) 分配了很近似的 (pos, neg) 权重对儿。GFL 给 A 和 C 的 pos 和 neg 都分配了 0 权重,因为有相同的 cls score 和 IoU。
因为现有的方法中,neg 权重函数是和 pos 权重函数强相关的,不同属性的 anchor 可能被分配近似的权重,会损坏检测器效果。
为了获得更具有区分性的信号,本文方法设计了一种新的权重策略,dual weighting(DW),来分别为正样本和负样本来分配权重,让它们互补。
-
pos weights:由分类得分和定位得分联合动态获取
pos weights 反映了 cls head 和 reg head 的一致性程度,同时能够驱动那些一致性更高的 anchor 排到前面,在 infer 的时候,这些分类和定位得分都较好的 anchor 经过 NMS 后就能保留下来
如图 1 所示,DW 能够通过给这 4 个不同的 anchor 分配不同的 (pos, neg) 权重对儿,来提供更细粒度的监督信号
此外,为了得到更准确的 reg 得分,作者提出了一个 box refinement 操作
-
neg weight:解耦为两部分:① the probability that it is a neg sample;② its importance conditioned on being a neg sample
二、方法
2.1 Hard Label Assignment 和 Soft Label Assignment
Hard Label Assignment:
- 如 FCOS 和 Foveabox 都是使用中心采样的方式,当 anchor 距离 GT 的中心点近,就判定为正样本,是一个静态的方式,并非最优的方式。
- ATSS 是更进阶一些的方式,将 IoU > mean+std 的 top-k 个 anchor 作为正样本,PAA 将 cls 和 reg loss 联合写成极大似然的形式,使用分布来区分正负样本,OTA 将 label assignment 建模成了最优传输问题。
- Hard Label Assignment 方法将所有 sample 同等对待,和目标检测的测评方式不是很兼容
Soft Label Assignment:
- Focal loss 在 cross entropy 的基础上,降低了简单样本和负样本的权重,让检测器更关注难样本
- GFL 给每个 anchor 分配一个 cls-localization 联合的 soft weight
- Varifocal loss 使用 IoU-aware cls label 来训练 cls head
- 上面的这几种方法都是先给正样本一个权重 w p o s w_{pos} wpos,然后将负样本的权重简单的设置为 1 − w p o s 1-w_{pos} 1−wpos,本文方法给每个 anchor 分别计算其正/负的权重
- 很多 soft 方法都在 loss 上加权,还有一些方法直接在得分上加权, L c l s = − l n ( w p o s × s ) − l n ( 1 − w n e g × s ) L_{cls}=-ln(w_{pos} \times s)-ln(1-w_{neg} \times s) Lcls=−ln(wpos×s)−ln(1−wneg×s),如 FreeAnchor 和 Autoassign,且 Autoassign 的 w p o s w_{pos} wpos 和 w n e g w_{neg} wneg 都是接收梯度回传的。
- 本文方法中,这两个权重的梯度是被截断的,和在 loss 上加权有相同的特点
2.2 框架结构
目标检测推理阶段一般都会使用 NMS 来处理预测框,所以,一个好的检测器的结果,应该同时具备高分类得分和高定位质量,但是,分类头和定位头是两个独立的头,会有高分类得分低定位质量,或高定位质量低分类得分的情况。
soft label assignment 方法中,使用 weighting loss 的方法,来加强两者的一致性,一般的 loss 如下:
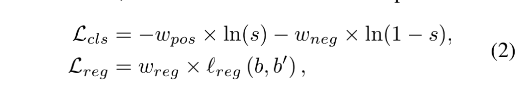
- s 是 cls score
- b 是预测 box, b’ 是 GT box
- reg loss 是 Smooth L1、IoU、GIoU 等 loss
- 如果给那些具有较高一致性的 anchor 分配更大的 w p o s w_{pos} wpos 和 w n e g w_{neg} wneg ,则就能避免一些问题
表 1 展示了不同方法对于一个 pos anchor 的 w p o s w_{pos} wpos 和 w n e g w_{neg} wneg ,一般会使用 t 来表示两个 head 的一致性程度,然后将不一致性定义为 1-t,然后通过使用尺度因子 ( ( s − t ) 2 , s 2 or t ) ((s-t)^2, s^2 \ \text{or} \ t) ((s−t)2,s2 or t)将其变为 pos、neg loss weights。

不同于表 1 中的具有高相关性的 w p o s w_{pos} wpos 和 w n e g w_{neg} wneg ,本文作者提出的 pos 和 neg weights 是分开进行的。
- pos weighting:将 cls score 和 IoU(预测的 box 和 gt 的 IoU)作为输入,通过估计 cls head 和 reg head 输出的一致性,来作为 pos weighting
- neg weighting:将 cls score 和 IoU(预测的 box 和 gt 的 IoU)作为输入,然后将该 anchor 是 neg 的概率和该 anchor 是 neg 的重要程度相乘
- 这样一来,那些具有相似 pos weights 的模棱两可的 anchor,就可以得到更细粒度的监督信号(有区分力的 neg weights),和现有方法不同
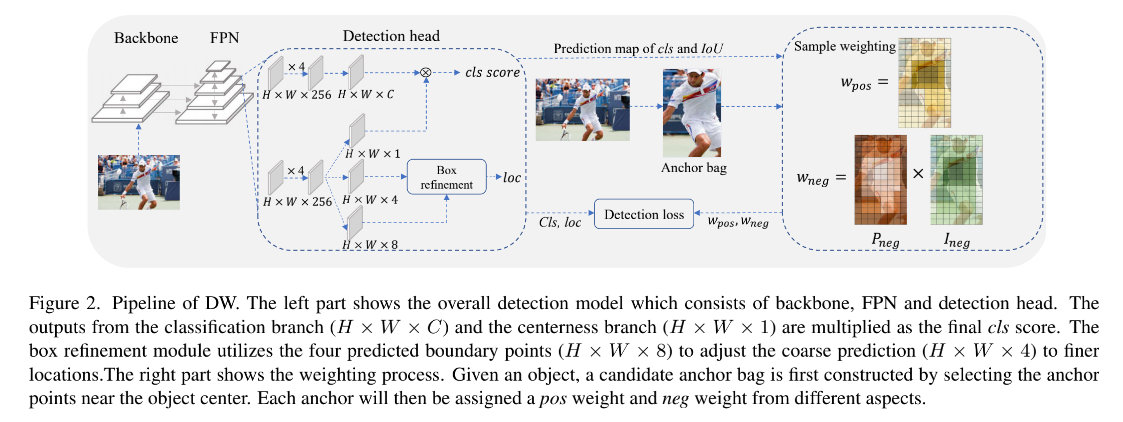
DW 的结构如图 2 所示:
- 首先,给每个 GT 分配对应的 anchor(根据 center prior 选定参与训练的 anchor),然后给这些候选 anchor 分配 3 个 权重: w p o s w_{pos} wpos 、 w n e g w_{neg} wneg 和 w r e g w_{reg} wreg
- 在候选 anchor 之外的 anchor 被分为负样本,不会参与后面的过程,因为这些 anchor 的统计信息在训练早期很杂乱,如 IoU、cls score 等
2.2.1 Positive Weighting Function
在 COCO 测评中,同一类别中的所有预测框会被排序后来决定去留。有些方法使用 cls score 作为排序标准,有些方法将 cls score 和预测 IoU 进行联合作为排序标准。
只有当一个 anchor 的 IoU>阈值且前面没有其他框排在前面的时候,这个预测结果会被认为是正确的
也就是说,对于一个 GT,只有排在第一个位置且 IoU>阈值的 box 会被认为是 pos,其他 box 都会被认为是该 GT 的假正例。
pos weight w p o s w_{pos} wpos 和 IoU 、s 是正相关的,故作者首先定义一个一致性度量参数 t 来衡量这个两个条件的一致性:
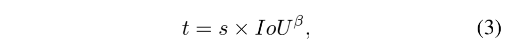
- β \beta β 是用来平衡这两个条件的
为了让 pos weights 在不同 anchor 上有大的方差,作者添加了一个修正因子:
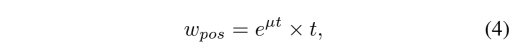
- μ \mu μ 是超参数,来控制不同 pos weights 的相对 gaps
最后,每个 anchor 的 pos weights 会使用加和进行归一化
2.2.2 Negative Weighting Function
如图 1 ,anchor D 有更细致的定位,但 cls score 更低,anchor B 定位粗糙,但 cls score 更高,这样的话,这两个 anchor 的一致性程度 t 就可能是很接近的,就没法反映出两个 anchor 的区别了。所以,作者使用下面两个数相乘的方式来获得更能区分开的 neg weights。
1、Probability of being a Negative Sample
根据 COCO 的测评标准,小于阈值的 IoU 的框被判定为错误,这说明就算一个预测框的 cls score 很高,如果 IoU 小于阈值,则会认为是错误的。也就是 IoU 是决定 neg sample 的 probability 唯一的因子,定义为 P n e g P_{neg} Pneg。
此外,COCO 使用 0.5~0.95,的 IoU 跨度来估计 AP,故 P n e g P_{neg} Pneg 要满足下面的条件:

- 任何单调递增的函数都满足 P n e g P_{neg} Pneg
为了简化, P n e g P_{neg} Pneg 公式如下:
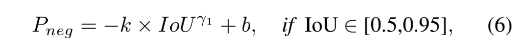
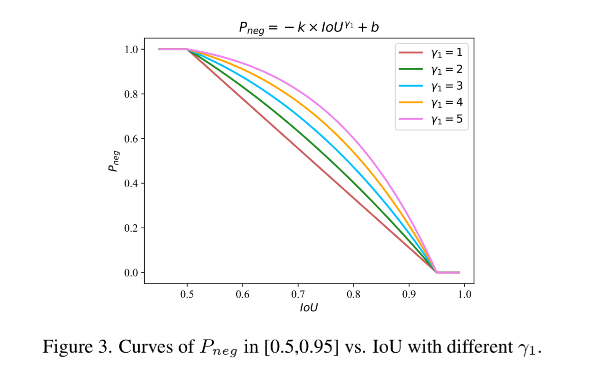
- 一旦 γ 1 \gamma_1 γ1 确定,k 和 b 也就可以获得,图 3 绘制了 P n e g P_{neg} Pneg-IoU 的曲线
2、Importance Conditioned on being a Negative Sample
infer 的时候,neg prediction 在排序列表中不会影响 recall,但会影响 precision,所以,排序的时候 neg prediction 拍的越后越好。
所以,如果一个 neg prediction 有大的排序得分的话,网络更应该关注并降低其得分,也可以看做是网络优化中的难例。
作者使用 I n e g I_{neg} Ineg 来定义一个 neg prediction 的重要程度,排序得分越大,越是难例,越重要:
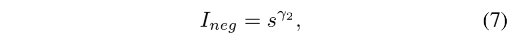
- γ 2 \gamma_2 γ2 是调控因子,控制着网络需要给这个预测结果多大的关注
最后,neg weight w n e g = P n e g × I n e g w_{neg} = P_{neg} \times I_{neg} wneg=Pneg×Ineg:
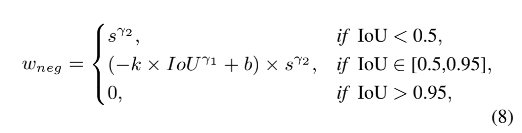
- w n e g w_{neg} wneg 和 IoU 是呈反比的,和 s 是呈正比的
- 假设两个 anchors 有相同的 pos weight,则 IoU 更小的 anchor 会有更大的 pos weight
- w n e g w_{neg} wneg 在推理的过程很重要,而且能够区分开那些有着近似 pos weight 的模棱两可的 anchor
2.2.3 Box Refinement
由于 pos 和 neg weight function 都将 IoU 作为输入,故更加准确的 IoU 就能得到更好的权重,所以作者预测了一个 offset map O ∈ R H × W × 4 O \in R^{H \times W \times 4} O∈RH×W×4,分别学习对左上右下的偏移修正,如图 4 所示。
由于距离目标边界更近的点预测的位置更准确,所示作者设计了可学习的预测模块,基于 coarse bounding box 来对每个边生成 boundary point,根据图 4,四个 boundary points 的坐标如下:


2.2.4 Loss Function
本文提出的 DW 方法可以用于现有的狠毒哦检测器,作者在 FCOS 中嵌入了 DW,如图 2 所示,且作者仍然使用 centerness x classification 作为排序 cls score,loss 函数为:
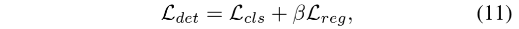
- β \beta β 是平衡因子,和公式 3 中的相同
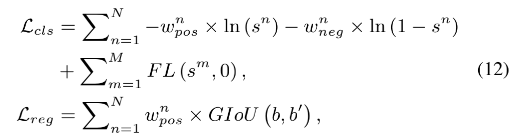
- N 是在候选 bag 中的 anchor 个数
- M 是不在候选 bag 中的 anchor 个数
- FL 是 Focal Loss
- s 是预测的 cls score
- b 和 b’ 分别是预测和 gt 的框
三、效果
backbone:ResNet50 在 ImageNet 上预训练后,加上 FPN 作为 backbone
消融实验:
1、Hyper-parameters of Positive Weighting: β = 5 \beta=5 β=5, μ = 5 \mu=5 μ=5
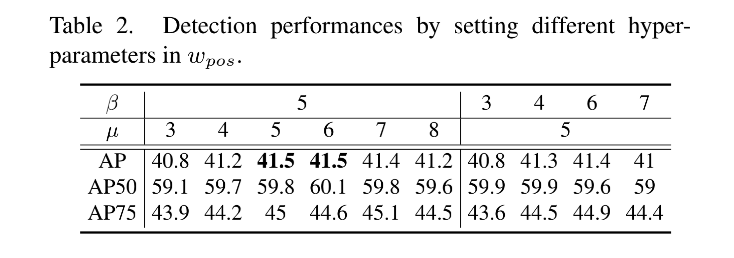
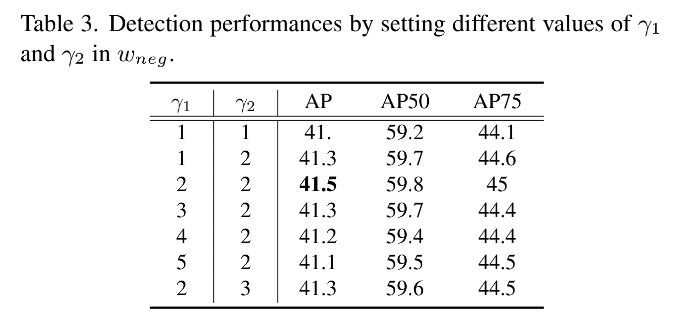
2、Hyper-parameters of Negative Weighting:
3、Construction of Candidate Bag:

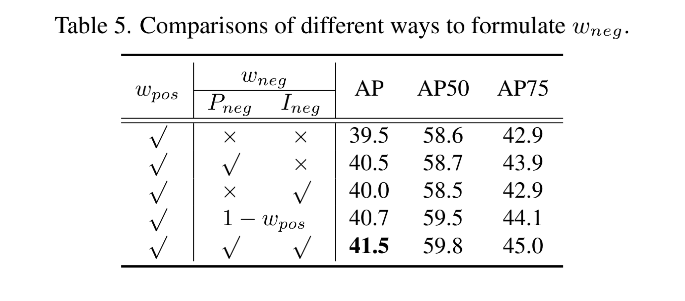
4、Design of Negative Weighting Function:
5、Box Refinement
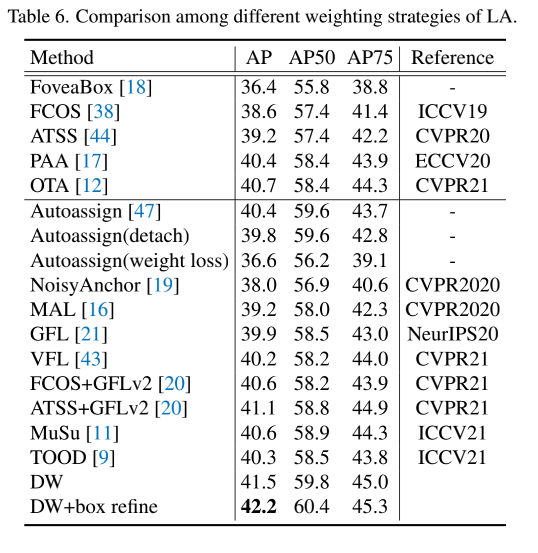
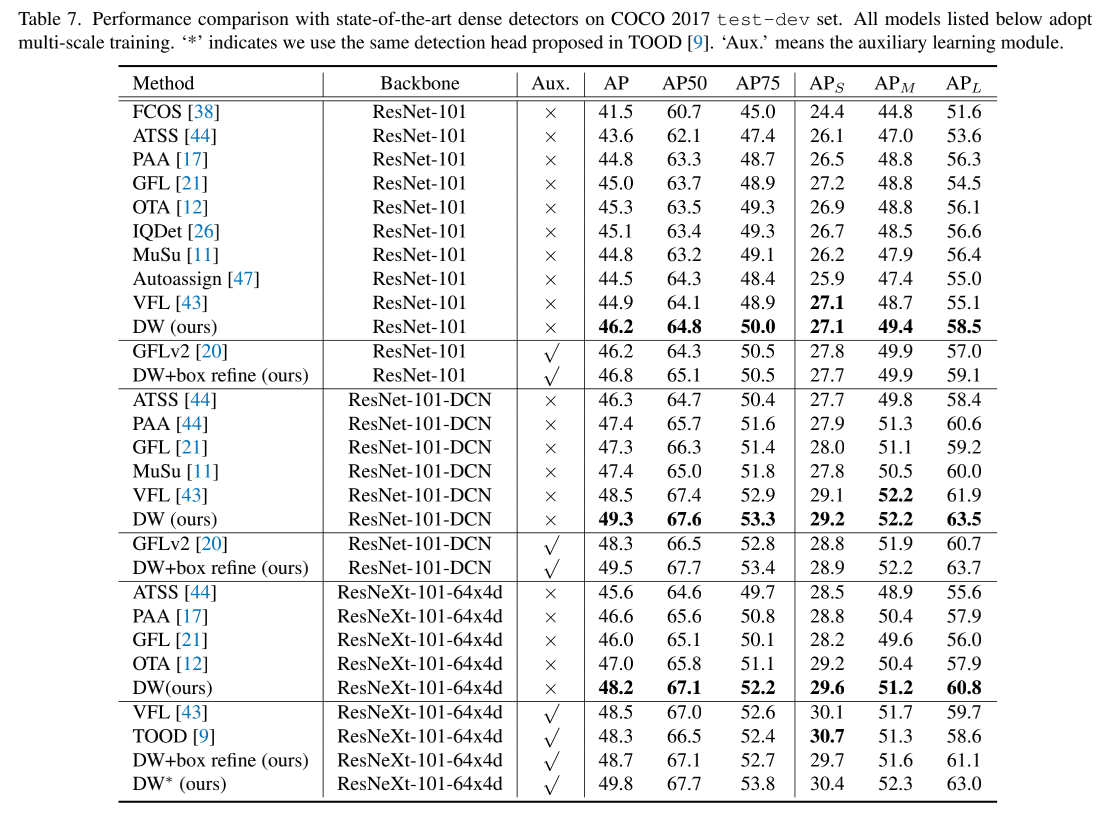
和 SOTA 的对比:
DW 可视化:
如图 5 所示,可以看出 pos 和 neg weights 主要集中在 GT 的中间区域,GFL 和 VFL 分配权重区域会更宽一些,这种不同说明,DW 会更关注重要的样本,降低简单样本的贡献,如边界附近的,所以 DW 对 candidate bag 的选择方式更鲁棒一些。
此外,DW 集中区域的 anchor 的权重也有不同,GFL 和 VFL 的 neg weights 和 pos weights 相关度更高一些,尤其是橘色高亮区域,GFL 和 VFL pos weight 和 neg weight 很接近,DW 可以明显的区分开来。
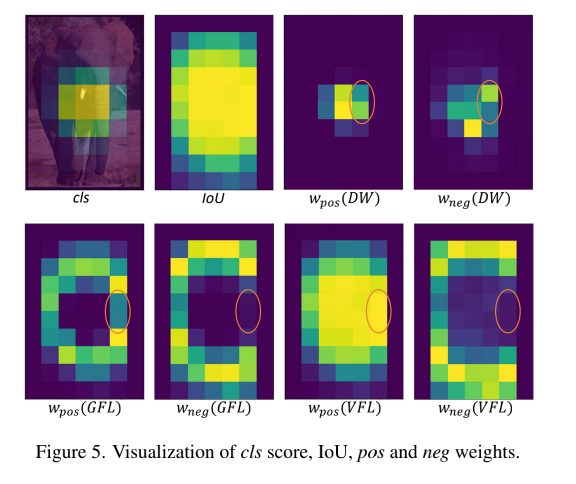
DW 的局限:
尽管 DW 能够较好的区分 anchor 的重要性,但会同时降低训练样本的数量,如图 5,可能会对小目标造成影响,如表 7 所示,DW 对小目标的提升没有其他目标多,作者说,后面会根据目标的大小来进一步优化。