自 2021 年初以来,AI 领域推出大量基于文本到图像的模型(例如 DALL-E-2、Stable Diffusion 和 Midjourney 等)。近日,谷歌也公开了一款名为“Muse”的基于文本生成图像的模型,声称可以实现最先进的图像生成性能。
下图均为 Muse 的基于文本生成的图像
- 一群鱼在海里拼成“MUSE”字样
- 嘴里叼着“MUSE”牌子的威尔士柯基
- 带有“Muse”的拿铁咖啡
- 壁炉中的火焰呈现“MUSE”字样




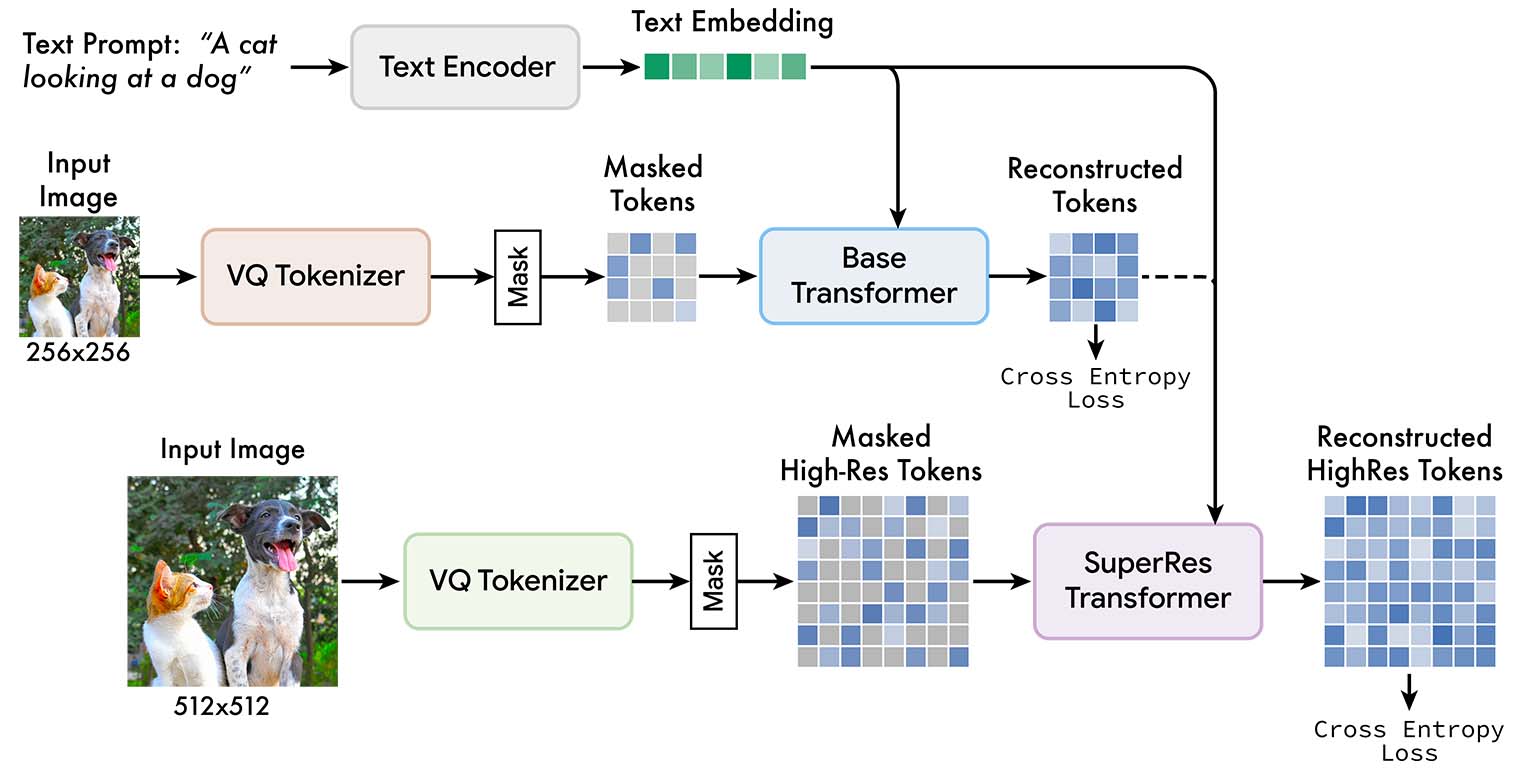
Muse 在离散标记空间中接受掩蔽建模任务的训练:给定从预训练的大型语言模型 (LLM) 中提取的文本嵌入,训练 Muse 以预测随机掩蔽的图像标记。使用预训练的 LLM 可以实现细粒度的语言理解,转化为高保真图像生成以及对视觉概念(例如对象)的理解,比如空间关系、姿势、基数等。
总体来说,MUSE 的优势在于其 FID 和 CLIP 分数更高、生成效率比其他同类模型快得多,且支持开箱即用的蒙版编辑功能(即支持通过蒙版继续编辑已生成的图片)。
分数更高:MUSE 模型获得了出色的 FID 和 CLIP 分数,可定量衡量图像生成质量、多样性和与文本的对齐情况。数据方面,MUSE 的 900M 参数模型在 CC3M 上实现了新的 SOTA,FID 得分为 6.06。Muse 3B 参数模型在零样本 COCO 评估中实现了 7.88 的 FID,以及 0.32 的 CLIP 分数。
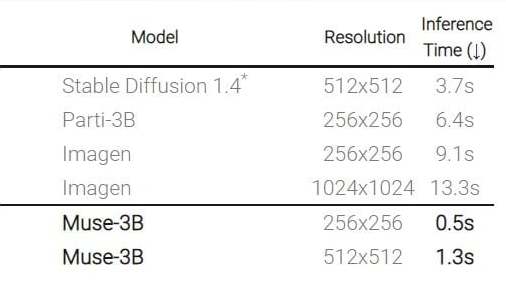
生成效率:由于使用压缩的、离散的潜在空间和并行解码,MUSE 模型比其他同类模型快得多。与 Imagen 和 DALL-E 2 等像素空间扩散模型相比,Muse 使用离散标记,且需要的采样迭代更少,因此生成效率显著提高;与谷歌自己的 Parti 等自回归模型相比,Muse 使用了并行解码,生成效率也更高。
编辑功能: MUSE 支持基于蒙版的编辑功能,比如下图,通过在左图创建蒙版并输入“热气球”,便可生成右边的新图片。


另外,Muse 团队指出,当今语言和图像人工智能系统的用例存在一些“潜在的危害”,例如社会偏见或传播错误信息。出于这个原因,该团队并未发布 MUSE 的源代码和任何公开的 Demo 演示。
在 MUSE 主页可以看到更多基于 MUSE 的图像作品,下图为部分 MUSE 作品预览:

