1 简介
本文根据google research 团队2023年1月的《Muse: Text-To-Image Generation via Masked Generative Transformers 》翻译总结的。Muse认为模型可能被乱用,代码没有开源。
图像生成有GAN、扩散(diffusion)、自回归模型等,而Muse采用mask图像的建模方法,非扩散、非自回归。给定从预训练大预言模型(LLM)中提取的文本embedding,Muse是被训练来预测随机mask的图像token。
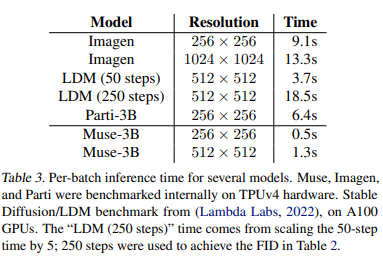
Muse的预测时间比相同参数量Imagen-3B、Parti-3B快10倍。比Stable Diffusion v1.4快3倍。
- 与像素空间的diffusion模型(如Imagen、DALL-E 2)相比,Muse因为使用了离散图像token,运行速度更快,需要较少的采样迭代。
- 与自回归模型(如Parti)相比,Muse因为使用了并行编码,运行速度更快。
- 与Stable Diffusion是因为采用了较少的采用迭代。
Muse总体来说有如下3点:
- 在文本-图像生成上,是一个state-of-the-art的模型,有很好的FID和CLIP分数。
- 因为离散图像token和并行编码,比目前其他模型快。
- Muse可以开箱即用,具有zero-shot能力,包括修补绘画(inpainting)、外补绘画(outpainting)、无掩码编辑(mask-free editing),如下图。

2 模型
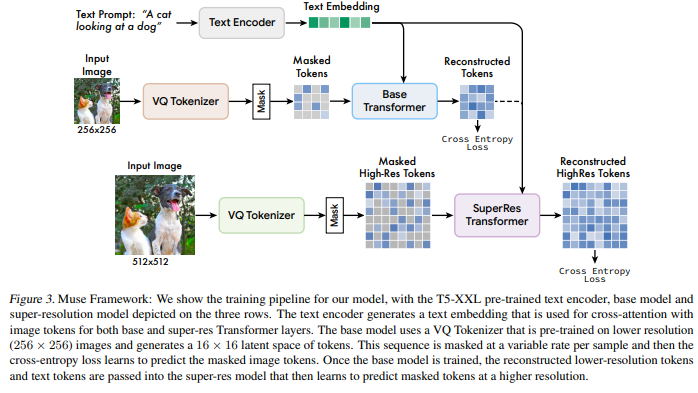
如上图,整个模型分为三部分(三行),分别为文本编码、base模型、超分辨率(super-resolutio )模型。
T5-XXL的预训练text encoder将文本转为text embedding,其会传入到base transformer和superRes transformer。base模型使用预训练的VQ tokenizer将低分辨率图像(256*256)转换为16*16的图像token,这些token接着会被部分mask掉,然后通过交叉熵损失(cross-entropy loss)来预测恢复这些被mask的图像token。一旦base模型训练完成,恢复(reconstructed)出来的token和文本token会输入到super-res模型,最终学习预测恢复高分辨率的被mask的图像token。
2.1 预训练的文本编码器
使用LLM可以提升高质量的图片生成。
我们采用T5-XXL输出4096维的embedding。
2.2 VQGAN
我们模型的一个核心组件是使用VQGAN来获得图像语义token。VQGAN包括编码器和解码器,有个量化层会将输入图像转换为token序列。我们用卷积层构建编码器和解码器,方便支持不同分辨率。编码器有很多下采样模块来降低输入的维度,而解码器有对应数量的上采样模块来还原到原始图片大小。
给定H*W的图片,编码器下采样率f,输出的token大小就是H/f *W/f。
我们训练了两个VQGAN,下采样率分别是f=16和f=8. 使用f=16的VQGAN于256*256图片,输出16*16大小token。使用f=8的VQGAN于512*512图片,输出64*64大小token。
这些离散的token方便使用交叉熵损失(cross-entropy loss)来预测恢复这些被mask的图像token。
2.3 base model
base mode是 masked transformer 。利用所有没有mask的文本embedding和随机mask一部分的图像token,替换他们用[mask]token.
2.4 Super-Resolution Model

我们采用级联的形式,训练完base model再训练super-res模型。高分辨率过程是学着将低分辨率隐变量转换为高分辨率隐变量。
2.5 编码器微调
我们通过附加更多的残差层和通道来增加VQGAN编码器的能力,而编码器保持能力不变。
2.6 可变的mask率
采用一个cosine 计划。从下面分布采用mask 率r。
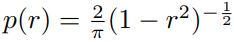
2.7 分类器自由引导(Classifier Free Guidance )
我们采用分类器自由引导(CFG:Classifier Free Guidance)来改善生成的质量和文本-图像对齐。
在训练时,我们10%随机去掉文本,这时候注意力就将为图像自注意力。

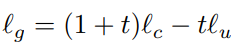
CFG用多样性换取准确性。通过增加t,减少对多样性的打击。
2.8 预测时迭代并行编码
在单独前向过程,使用并行编码预测多个输出。并行编码的主要假设是马尔可夫属性,许多token是条件独立于其他token。编码基于cosine 计划,步骤里先选择高可行度的mask token的一定片段。这些token然后在剩下的步骤里设为unmask,这样mask token的集合就减少了。使用这个过程,我们有能力在base模型中只使用24个编码步骤进行256个token的预测。在超分辨率模型中使用8个编码步骤进行4096个token预测。而自回归模型分别需要256步或者4096步,扩散模型也需要上百步。
3 结果
我们在Imagen数据集上训练的,含4.60亿文本-图片对。训练了一百万步,批大小512,在512核的TPU-v4,训练了1周时间。
3.1定性分析
如下图,可以在基数(cardinality)、组合(composition)、风格、文本书写、整个提示的使用等情况,生成的图片质量都很好。但在长的文本书写、高基数下效果一般(右下角图)。
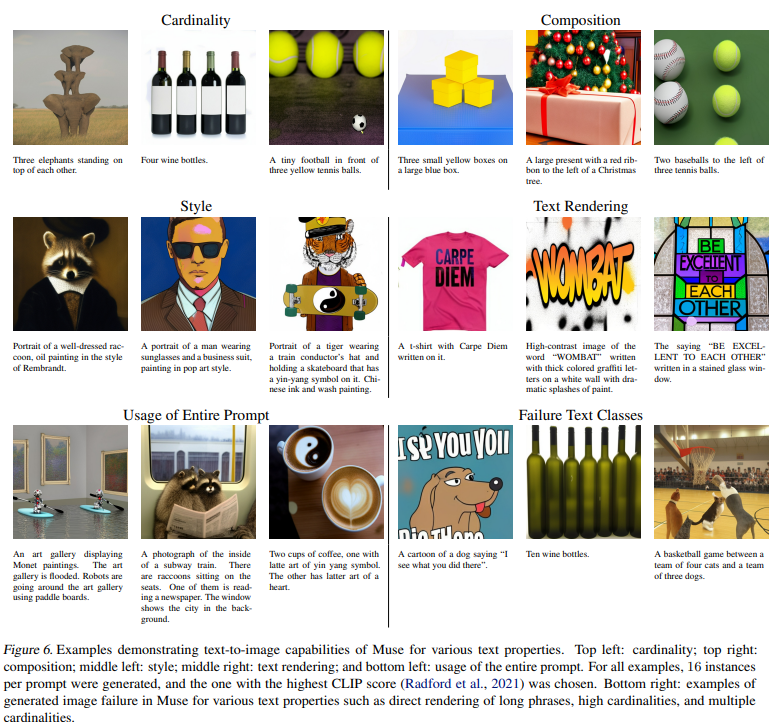
和其他模型比较,Muse效果好些,尤其比DALL-E 2好些。

3.2 定量分析
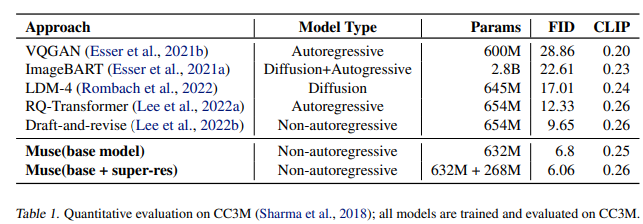
Muse在CC3M数据集上效果最好。
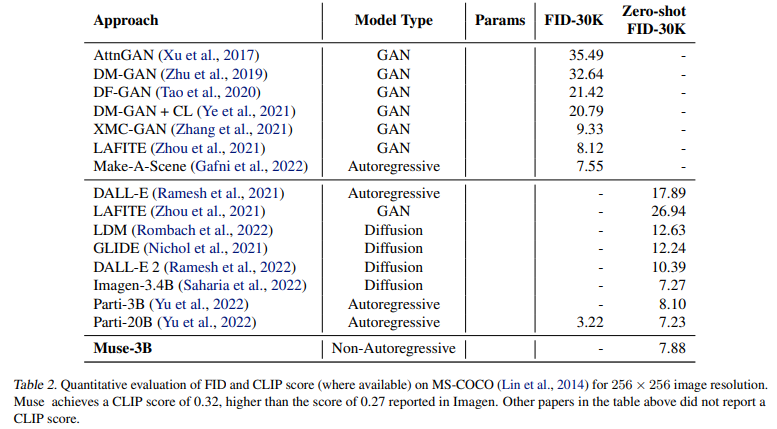
Muse在MS-COCO数据集上效果也好。
CLIP和FID之间会存在权衡,即在没有伤害CLIP下改善FID。如下图:

3.2.1人类评估
比较生成的图片和哪个描述匹配。我们发下Muse生成的在70.6%情况下,评委人员认为比stable diffusion好。
3.2.2 预测速度