背景
语言大模型有RLHF技术点,是否图生成也需要RLHF。要回答这个问题其实首先需要回答的问题有三个:
1.RLHF到底是个什么技术
2.为什么需要用RLHF技术,在语言大模型用RLHF模型解决什么问题点
3.图在什么情况下需要用到RLHF技术点
RLHF技术是什么呢,对一件事情的认识首先古人的方法就是名副其实,也就是说需要先看他是怎么定义这件事的,然后根据定义深入挖掘它背后的真实意图。回到RLHF,先看看英文全拼是RLHF: Reinforcement Learning from Human Feedback,通过人类的反馈来做强化学习。有两个关键词:人类反馈、强化学习;先看动词强化学习,为什么要强化学习呢,并且定于事通过人类反馈。强化学习一般情况就是为了解决复杂的数学模型求解的问题,也就是说强化学习其实是一种求解的技术(当然基于这个求解技术衍生出很多应用),并且解决的问题很复杂。为什么复杂呢?往往就是一个问题有太多种的可能,给定的条件或者说求解的约束又不明确,导致这个问题很难给出一个精准的解,甚至都不一定能给出一个解的范围或者趋势。
通过强化学习为什么就能解决这个问题,或者说有可能有机会解决这个问题呢?上面大概提到了问题复杂是怎么来的:1.给的信息不够2.问题可能解空间很多3.给的信号不容易表示成有效信息(耦合,或者信号特征弱)。其实归结起来就是信息不足以支撑解空间复杂度,强化学习的做法就是:通过多次实验和试探逐步积累足够信息;等到实验和试探次数足够积累到信息足以支撑解空间复杂度,问题就可以求解了,至少是积累更多信息解会更准确。
那为什么又要人类反馈呢,原因很简单:盲目的试探代价太高,如果有个裁判或者上帝可以帮忙开开天眼指指路,减少试探的代价那么这个求解速度可以大幅提升,准确率也可以大幅提升;所以这就是为什么需要人类反馈的原因。当然引申到大语言模型还有一个原因:很多问题的解并不是客观绝对的,还是跟人的主观价值观有关系的,这样的解其实就是一种特解,既然是特解那最好办法就是让人来构建约束,但这种约束往往人类不一定能抽象成数学模型,所以最简单办法就是通过人类反馈通过反馈数据来构建随机抽样来求解。
所以大家可以再看看OpenAI是用RLHF技术来解决大语言模型什么问题,就很清楚为什么了:
1.认知偏差:歧视、种族言论
2.文案多样性
3.生成有害或事实不准的文字
图生成是否需要RLHF,图好不好看也是很主观一件事情,并且图也存在信息不足导致的幻画(坏手坏脚),以及一些审美偏差不符合主流要求情况,所以图肯定也是需要RLHF能力的。
- 图文一致性:生成的图像未能准确描述所有的数字、属性和⽂字提⽰中描述的对象关系。
- 肢体问题:生成的图像呈现了扭曲、不完整、重复或者异常的肢体部位(例如:四肢等),这一问题在人类或动物中均可能出现。
- 审美问题:生成的图像偏离⼈类对审美⻛格的平均或主流偏好。
- 有害与偏⻅内容:生成的图像具有有害、暴⼒、性相关、存在歧视、⾮法或引起⼼理不适的内容。
技术点
前面介绍了什么是RLHF,以及很多概念层面的东西。这部分主要从图的RLHF实现技术来讲解,包括了每个部分数学公式、实践。
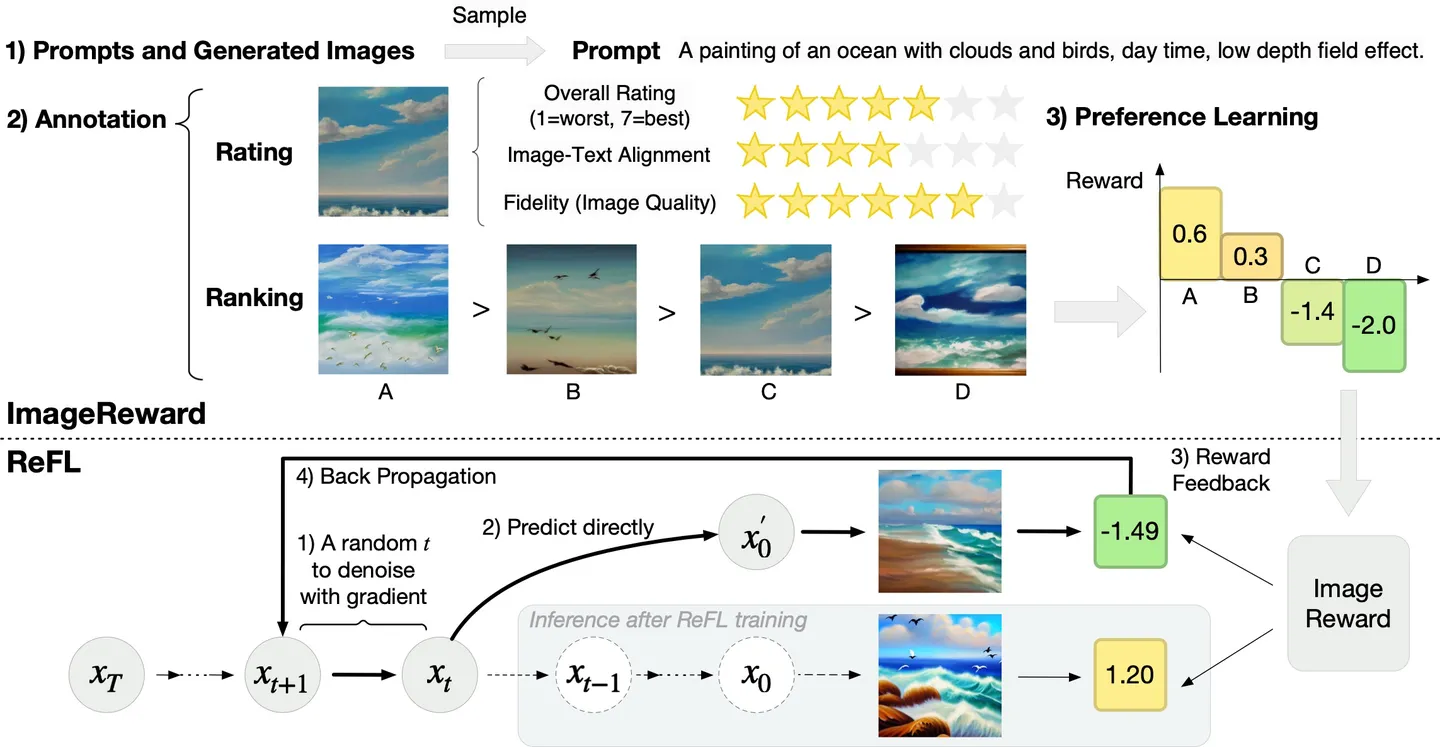
实现思路
给定prompt让模型生成多张图,人根据prompt对生成的多张图排序。模型通过学习人类的打分排序,学习人类的评判指标得到一个判别哪对哪不对的上帝模型。
利用上面学习到的判别模型,对要训练的模型做参数调整:
1.模型根据输入prompt生成图
2.判别模型把生成的图和基准图比较好坏
3.利用判别模型的排序打分作为loss调整生成模型参数
RM模型
LOSS讲解
原理
pairwise learn2rank loss,给定文本+图embbeding输入blip模型+MLP给每个图文对做相似度打分,把对单个图文对打好分的排序图list计算pairwiseloss,通过pairwiseloss来优化blip+mlp打分模型,让模型打分更准确。
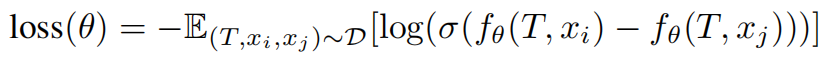
模型结构:BLIP(ViT-L作为图像编码器的,12层Transformer作为文本编码器)+ MLP(打分器)
训练方法:对于同一个prompt对应的k张图片,根据其排序结果得到pairs,每个pair中有相对更受偏好和不受偏好的两张图片。ImageReward训练所用的目标函数如下,其中T表示prompt,x表示生成的图片。
训练技巧:
- 训练时,BLIP的参数全都固定或者全都不固定都不能达到满意的准确率;事实上,我们发现固定70%的Transformer层是最有效的;
- 训练对超参数很敏感,我们通过搜索超参数发现1e-5的学习率和64的batch大小最合适。
代码讲解
def forward(self, batch_data):
# encode data
if opts.rank_pair:
batch_data = self.encode_pair(batch_data)
else:
batch_data = self.encode_data(batch_data)
# forward
emb_better, emb_worse = batch_data['emb_better'], batch_data['emb_worse']
#对better位置的图文计算打分
reward_better = self.mlp(emb_better)
#对worse位置的图文计算打分
reward_worse = self.mlp(emb_worse)
#把better位置、worse位置的图文对打分拼接输出,方便后面做pairwiseloss计算
reward = torch.concat((reward_better, reward_worse), dim=1)
return reward
#把输入的图文对encode
def encode_pair(self, batch_data):
text_ids, text_mask, img_better, img_worse = batch_data['text_ids'], batch_data['text_mask'], batch_data['img_better'], batch_data['img_worse']
text_ids = text_ids.view(text_ids.shape[0], -1).to(self.device) # [batch_size, seq_len]
text_mask = text_mask.view(text_mask.shape[0], -1).to(self.device) # [batch_size, seq_len]
img_better = img_better.to(self.device) # [batch_size, C, H, W]
img_worse = img_worse.to(self.device) # [batch_size, C, H, W]
# encode better emb
image_embeds_better = self.blip.visual_encoder(img_better)
image_atts_better = torch.ones(image_embeds_better.size()[:-1], dtype=torch.long).to(self.device)
emb_better = self.blip.text_encoder(text_ids,
attention_mask = text_mask,
encoder_hidden_states = image_embeds_better,
encoder_attention_mask = image_atts_better,
return_dict = True,
).last_hidden_state # [batch_size, seq_len, feature_dim]
emb_better = emb_better[:, -1, :].float()
# encode worse emb
image_embeds_worse = self.blip.visual_encoder(img_worse)
image_atts_worse = torch.ones(image_embeds_worse.size()[:-1], dtype=torch.long).to(self.device)
emb_worse = self.blip.text_encoder(text_ids,
attention_mask = text_mask,
encoder_hidden_states = image_embeds_worse,
encoder_attention_mask = image_atts_worse,
return_dict = True,
).last_hidden_state
emb_worse = emb_worse[:, -1, :].float()
# get batch data
batch_data = {
'emb_better': emb_better,
'emb_worse': emb_worse,
}
return batch_data#pairwise loss
def loss_func(reward):
"""
计算损失函数
Args:
reward (torch.Tensor): 一个形状为 (batch_size, 2) 的张量,其中第一列为正样本,第二列为负样本
Returns:
loss (torch.Tensor): 损失函数的值
loss_list (torch.Tensor): 损失函数的梯度
acc (torch.Tensor): 正样本的准确率
"""
# 创建一个形状为 (batch_size,) 的全零张量,并将其移动到指定设备上
target = torch.zeros(reward.shape[0], dtype=torch.long).to(reward.device)
# 计算交叉熵损失函数
loss_list = F.cross_entropy(reward, target, reduction='none')
# 计算平均损失函数
loss = torch.mean(loss_list)
# 计算正样本的准确率
reward_diff = reward[:, 0] - reward[:, 1]
acc = torch.mean((reward_diff > 0).clone().detach().float())
return loss, loss_list, acc
数据构建

训练代码
# 首先要从 dataset 下载数据
from datasets import load_dataset
# 加载 8K 集合数据集
dataset = load_dataset("THUDM/ImageRewardDB", "8k")
# 将数据集转换成指定格式
dict_item = {}
dict_item['clip_text'] = clip.tokenize(item["prompt"], truncate=True)
dict_item['text_ids'] = text_input.input_ids
dict_item['text_mask'] = text_input.attention_mask
if labels[id_l] < labels[id_r]:
dict_item['img_better'] = img_set[id_l]
dict_item['img_worse'] = img_set[id_r]
elif labels[id_l] > labels[id_r]:
dict_item['img_better'] = img_set[id_r]
dict_item['img_worse'] = img_set[id_l]
# 运行脚本以训练模型
bash scripts/train_one_node.sh
结果验证
import os
import torch
import ImageReward as RM
if __name__ == "__main__":
prompt = "a painting of an ocean with clouds and birds, day time, low depth field effect"
img_prefix = "assets/images"
generations = [f"{pic_id}.webp" for pic_id in range(1, 5)]
img_list = [os.path.join(img_prefix, img) for img in generations]
model = RM.load("ImageReward-v1.0") #把这个模型换成你自己训练出来的模型地址
with torch.no_grad():
ranking, rewards = model.inference_rank(prompt, img_list)
# Print the result
print("\nPreference predictions:\n")
print(f"ranking = {ranking}")
print(f"rewards = {rewards}")
for index in range(len(img_list)):
score = model.score(prompt, img_list[index])
print(f"{generations[index]:>16s}: {score:.2f}")
# 或者用下面的这个验证也行,<prompt>输入的生成文本,<img1_obj_or_path>需要打分的图路径
import ImageReward as RM
model = RM.load("ImageReward-v1.0")
rewards = model.score("<prompt>", ["<img1_obj_or_path>", "<img2_obj_or_path>", ...])RLHF模型
LOSS讲解

通过观察去噪步骤中的ImageReward分数,我们得出了一个有趣的发现(参见上图左)。对于一个降噪过程,例如降噪步数为40步时,在降噪过程中途直接预测中间降噪结果对应的原图:
- 当t ≤ 15:ImageReward得分和最终结果的一致性很低;
- 当15 ≤ t ≤ 30:高质量生成结果的ImageReward得分开始脱颖而出,但总体上我们仍然无法根据目前的ImageReward分数清楚地判断所有生成结果的最终质量;
- 当t ≥ 30:不同生成结果对应的ImageReward分数的已经可以区分。
根据观察,我们得出结论,经过30步去噪(总步数为40步),而不需要到最后一步降噪,ImageReward分数可以作为改进LDM的可靠反馈。因此,我们提出了一种直接微调LDM的算法。算法流程可见上图右。将RM的分数视为人类的偏好损失,将梯度反向传播到去噪过程中随机挑选的后一步t(在我们的例子中t取值范围为30~40)。随机选择t而不是使用最后一步的原因是,如果只保留最后一个去噪步骤的梯度,训练被证明是非常不稳定的,结果是不好的。在实践中,为了避免快速过拟合和稳定微调,我们对ReFL Loss进行重新加权,并用Pre-training Loss进行正则化。
原理
loss包括两个阶段:
1.第一阶段在
2.第二阶段是在每张图的30-40步
代码讲解
for epoch in range(first_epoch, args.num_train_epochs):
self.unet.train()
train_loss = 0.0
for step, batch in enumerate(self.train_dataloader):
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
with self.accelerator.accumulate(self.unet):
encoder_hidden_states = self.text_encoder(batch["input_ids"])[0]
latents = torch.randn((args.train_batch_size, 4, 64, 64), device=self.accelerator.device)
self.noise_scheduler.set_timesteps(40, device=self.accelerator.device)
timesteps = self.noise_scheduler.timesteps
#在30-40步之间随机选择一步出来作为模型优化
mid_timestep = random.randint(30, 39)
#在mid_timestep之前的不计算loss
for i, t in enumerate(timesteps[:mid_timestep]):
with torch.no_grad():
latent_model_input = latents
latent_model_input = self.noise_scheduler.scale_model_input(latent_model_input, t)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=encoder_hidden_states,
).sample
latents = self.noise_scheduler.step(noise_pred, t, latents).prev_sample
#mid_timestep把生成的图和参照图排序大分,计算loss优化sd模型
#这样做的好处有点类似LLM模型里面预测和实际数据KL约束生成图不要离原始模型太大,但是又需要微细调整参数
latent_model_input = latents
latent_model_input = self.noise_scheduler.scale_model_input(latent_model_input, mid_timestep)
noise_pred = self.unet(
latent_model_input,
mid_timestep,
encoder_hidden_states=encoder_hidden_states,
).sample
pred_original_sample = self.noise_scheduler.step(noise_pred, t, latents).pred_original_sample.to(self.weight_dtype)
pred_original_sample = 1 / self.vae.config.scaling_factor * pred_original_sample
image = self.vae.decode(pred_original_sample.to(self.weight_dtype)).sample
image = (image / 2 + 0.5).clamp(0, 1)
# image encode
def _transform():
return Compose([
Resize(224, interpolation=BICUBIC),
CenterCrop(224),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
rm_preprocess = _transform()
image = rm_preprocess(image).to(self.accelerator.device)
rewards = self.reward_model.score_gard(batch["rm_input_ids"], batch["rm_attention_mask"], image)
loss = F.relu(-rewards+2)
loss = loss.mean() * args.grad_scale
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = self.accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
self.accelerator.backward(loss)
if self.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.unet.parameters(), args.max_grad_norm)
self.optimizer.step()
self.lr_scheduler.step()
self.optimizer.zero_grad()数据构建

图文对,训练时候也是输入文本,利用参照sd模型生成图,然后把生成图和参照图做rm排序求loss,通过loss调整模型的参数,调整的其实也是unet模型预测噪声的能力。
训练代码
from ImageReward import ReFL
if __name__ == "__main__":
args = ReFL.parse_args()
trainer = ReFL.Trainer("CompVis/stable-diffusion-v1-4", "data/refl_data.json", args=args)
trainer.train(args=args)
accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 refl.py \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=2 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=3000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="checkpoint/refl" \
--grad_scale 0.001 \
--checkpointing_steps 100
#2块A40 10000条数据5个epoch 大概10个小时训练可以完成结果验证
#加载训练好的模型参数
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
vae = AutoencoderKL.from_pretrained("/root/autodl-tmp/ImageReward/checkpoint/refl", subfolder="vae", revision=False)
unet = UNet2DConditionModel.from_pretrained(
"/root/autodl-tmp/ImageReward/checkpoint/refl/checkpoint-3000", subfolder="unet_ema", revision=True
)
text_encoder = CLIPTextModel.from_pretrained(
"/root/autodl-tmp/ImageReward/checkpoint/refl", subfolder="text_encoder", revision=False
)
pipeline = StableDiffusionPipeline.from_pretrained(
"/root/autodl-tmp/ImageReward/checkpoint/refl",
text_encoder=text_encoder,
vae=vae,
unet=unet,
revision=True,
)
pipe = pipeline.to(device)
prompt = "a painting of a girl walking in a hallway and suddenly finds a giant sunflower on the floor blocking her way."
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse3.png")
#下面验证方式是直接把训练好的unet把老的模型unet参数换掉
import torch
from diffusers import StableDiffusionPipeline
device = "cuda"
model_id = "/root/autodl-tmp/ImageReward/checkpoint/refl"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
prompt = "a painting of a girl walking in a hallway and suddenly finds a giant sunflower on the floor blocking her way."
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse1.png")
左边是没有rlhf模型生成图,生成图对细粒度文本理解不够;右边是经过1万张图rlhf模型效果,图对细粒度意图理解较好。
小结
1.用作者的观点和视角解释了为什么需要rlhf,以及rlhf能解决什么大语言模型问题
2.结合image的rlhf模型来讲解了一种图片的rlhf做法
3.对图片rlhf中两个比较重要的环节loss和代码实现做了较详细介绍
4.用10000张人排序图多了训练,对比了经过rlhf和未经过rlhf模型的效果