1 简介
本文根据百度2023年3月的《ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts》翻译总结的。
ERNIE-ViLG 2.0是一个大规模中文-图像扩散模型,百度论文中说该模型是中文该领域内第一个。主要有下面两个改进:
- 融合了细粒度的文本知识、图片关键元素知识;比如文本中增加了词性描述,如动词、名词、形容词,图片上增加了物体识别预处理。
- 在不同的去噪步骤(生成步骤),利用了不同的去噪专家(expert)。每个步骤采用了不同的U-Net。
在过去几年,文本-图片扩散模型,例如LDM , GLIDE , DALL-E 2 , Imagen 在生成图片的文本相关性和图片逼真度方面取得了显著的进展。但存在如下两个问题:
- 在每一个去噪(生成)步骤的学习过程,所有文本(与图片区域交互的)、所有图片区域对目标函数是相同的贡献,没有进行区分。
- 当打开整个去噪过程,不同去噪步骤的要求应该是不同的。但目前主要采用同一个U-Net于所有步骤,即在不同的去噪步骤采用了相同的训练参数。
ERNIE-ViLG 2.0的两个改进就是针对上面两个问题。
实验结果显示,ERNIE-ViLG 2.0效果好于DALL-E 2 和Stable Diffusion 。ERNIE-ViLG 2.0有24B参数(240亿),训练该模型用了320个 Tesla A100 GPUs,训练了18天,普通人玩不起啊。
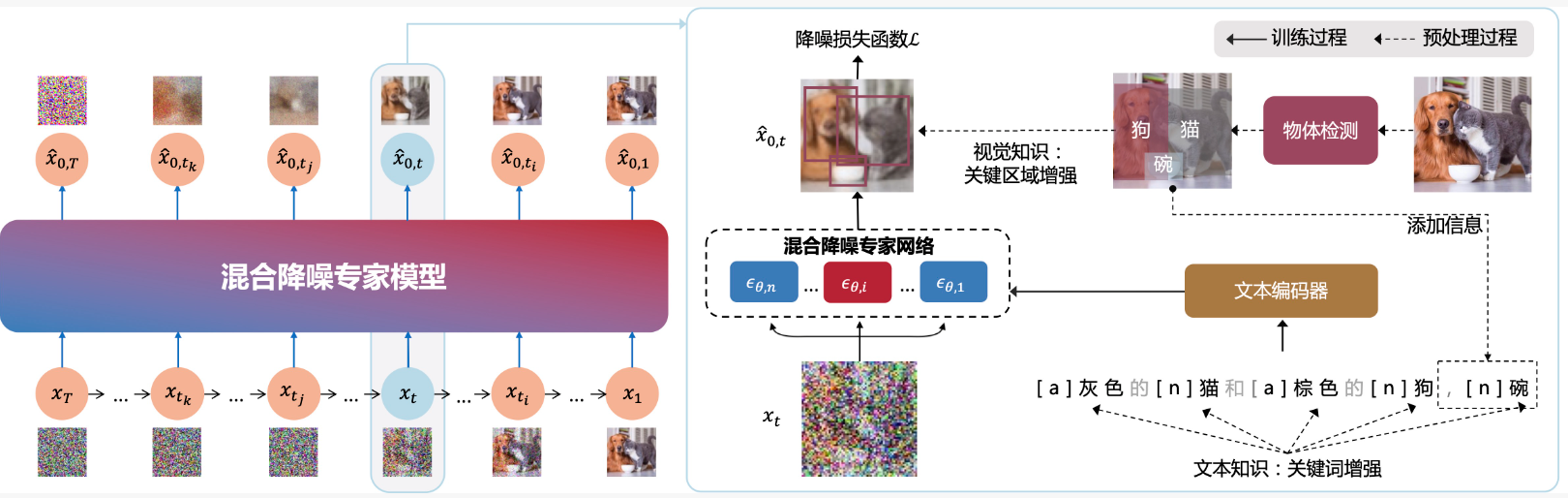
ERNIE-ViLG 2.0的两个改进主要可以看下图1.虚线(预处理过程)部分,2.混合降噪专家模型。
2 相关工作
1)前几年生成对抗模型较火;2)接着受transformer影响,文本-图片的序列到序列模型出现,如
ERNIE-ViLG , DALL-E ,Cogview , Make-A-Scene , and Parti 。3)最近,扩散模型流行,如LDM , DALL-E 2 , and Imagen。
3 基础知识

4 DDPM回顾
- 扩散过程:对初始数据图像数据x不断增加高斯噪声,在T步后转换成一个各向同性的高斯分布。公式如下:
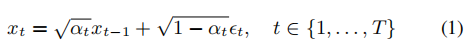

2. 去噪过程:是扩散过程的逆过程。通过迭代t=T....1步,将高斯噪声转回。公式如下:

3. 目标函数:

- 4.预测:

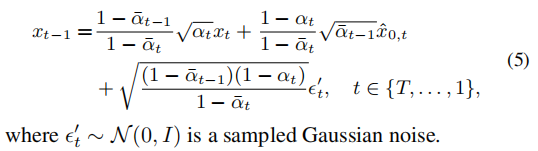
- 5.跨模关注层(cross modal attention):

5 ERNIE-ViLG知识增强--文本
- 我们采用现成的词性工具提取输入文本的词性,增加到输入序列中。如文章最开始的模型图中的a表示“灰色的”是形容词,n表示“猫”是名词。
- 在注意力层,增加这些词性的权重。从而修改上面的公式7为如下:
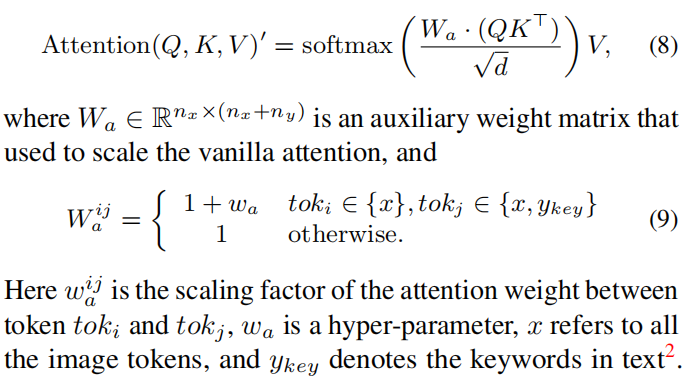
6 ERNIE-ViLG知识增强--图形
指文章最开始的模型图中的“物体检测”,如我们识别出来的“猫”、“狗”。我们对训练样本的50%增加物体检测。我们修改目标函数(公式3),使其对物体检测对应的区域增加权重,进而提高模型对这些物体的生成的聚焦。修改后目标函数如下:
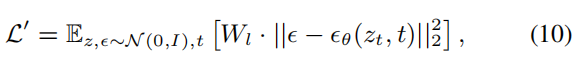

对于我们图片识别出来的“碗”,如果不在输入的文本里,我们会添加到文本里。这样会使文本表达更加准确的输入信息。
7 混合降噪专家Mixture-of-Denoising-Experts

在相同块中的步骤是采用相同的网络参数;不同块采用不同的U-Net网络参数,但其中文本编码是共用的。公式如下:
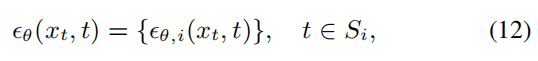
8 实验
A 实施细节

ERNIE-ViLG 2.0的参数量为24B,包括1.3B的文本编码器,和10个2.2B的混合降噪专家(U-Net)。
训练数据包括1.70亿对图片-文本数据。对于英文的文本,我们采用百度翻译api直接翻译成中文。
B实验结果
- ERNIE-ViLG 2.0模型在MS-COCO数据集上最好。

- 人为评估,也是ERNIE-ViLG 2.0效果好于DALL-E 2 和Stable Diffusion。

- 下面左图说明我们的知识增强起了作用(最后一行)。右图是逐渐增加混合降噪专家的数量,在10的时候效果最好,没有继续增加是因为算力有限的原因。

9 生成的图片
