图像的多尺度信息对于图像的处理十分重要。一般,获取图像的多尺度信息有三种方法。第一,就是图像金字塔,通过输入不同分辨率的图片进行处理得到图像的多尺度信息。第二就是编码器结构。编码器对图像进行下采样捕获更多的上下文信息,然后解码器来上采样,并使用跳跃连接来组合多尺度上下文信息。第三就是DeepLab中的空间金字塔池化(ASPP)模块,其中并行应用不同膨胀了的扩张卷积来捕获多尺度信息。
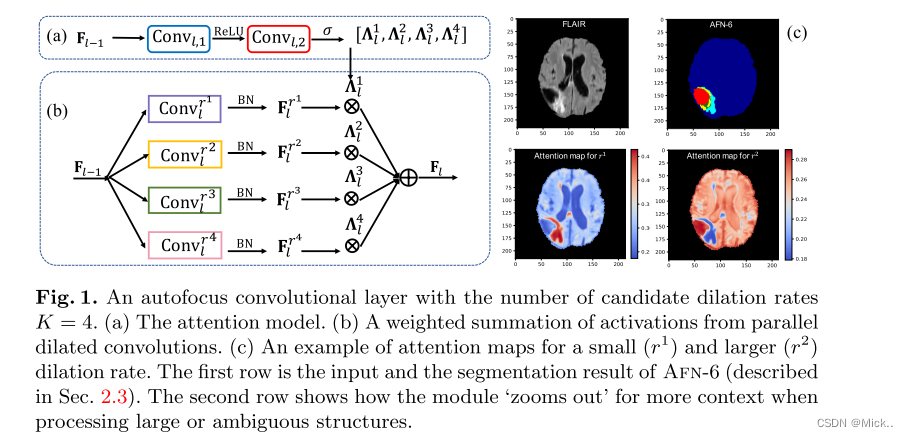
这篇文章与DeepLab相同的是都是使用并行不同膨胀率的扩张卷积进行多尺度特征提取,不同的是DeepLab只是简单的将不同尺度的信息进行融合。本文采用的自适应的融合方式。具体请看图a.具体来将就是用两个卷积层。

参考文献
[1805.08403] Autofocus Layer for Semantic Segmentation (arxiv.org)
Autofocus-Layer/models.py at master · yaq007/Autofocus-Layer (github.com)