目录
0、摘要
当代的语义分割框架通常都会结合backbone中的低级和高级特征以增强模型性能。本文中,我们首先指出了简单的融合低级和高级特征带来的收益并不高,因为语义层级和空间层级之间有着隔阂。我们发现,通过在低级特征中引入语义信息、在高级特征中引入高分辨率细节,将会有助于后续的特征融合。基于此,提出了一个新的分割框架——ExFuse,来弥补低级和高级特征之间的隔阂,并显著提高了约4.0%的整体分割质量。此外,在具有挑战性的PASCAL VOC 2012分割基准上对我们的方法进行了评估,获得了87.9%的mIOU,这超过了之前的SOTA结果。
1、引言
以FCN为baseline,产生了一系列的研究。其基本架构都是基于Encoder-Decoder结构的:先用Encoder(通常是一个预训练好的卷积网络)一层层提取高级语义信息,然后利用Decoder(通常包括各种上采样方法)来逐步恢复空间分辨率。这样一来,得到的分割结果既有了高级语义信息,又有了高分辨率的空间信息。但是有个问题,Encoder得到的feature maps的语义信息是丰富了,但是由于其分辨率较低,从这些低分辨率的feature maps得到的分割结果也就不够精细。于是,U-Net这类的网络就通过逐步将低级高分辨率的特征融入到高级低分辨率的特征中,以期帮助Decoder恢复更为精细的分割结果。
但是,作者认为特征的融合机制还不清楚,还需要仔细研究一下。作者提出了一个直觉上的实验:极端情况下,融合最低级、最高级的两组特征。怎么融合呢?作者的想法是:
- 既然低级特征的空间分辨率信息丰富而语义信息薄弱,如果将高级的语义信息也加到里面,这不就使得其与高级特征的融合变得容易了吗?
- 同样的,对于语义信息丰富而空间信息缺乏的高级特征,给它加入一些空间信息,其与低级特征的融合也将变得容易。
该想法,如图1所示:

于是乎,作者在这种想法的基础上,提出了ExFuse框架,主要包括这两个方面:
(1)为了将更多语义信息融入低级feature maps,提出了三种方法:卷积层重排列(Layer Rearrangement,LR)、语义监督(Semantic Supervision,SS)和语义嵌入分支( Semantic Embedding Branch,SEB);
(2)为了将更多空间信息嵌入高级feature maps,提出了两种新颖的方法:显式通道分辨率嵌入( Explicit Channel Resolution Embedding,ECRE)和密集领域预测(Densely Adjacent Prediction, DAP)。
2、本文的方法
ExFuse主要是针对U-Net类型的网络进行改进,以GCN(一种U型结构的分割网络,详细信息可以参考这篇博客)为baseline所开发的,如图2所示:

首先,作者在GCN的基础上,进行不同层级的特征融合实验,将GCN的backbone(ResNet)的四个层级(layer1~4,也即图2中的res-2到res-5)从layer4开始,进行组合实验,发现layer2、layer1带来的收益很小,如表1所示:

如何更有效的进行特征融合,则正是ExFuse提出的目的。
从图2整体来看:
ExFuse框架与GCN结构相似(实线部分):以ResNet为backbone,并对其从layer1到layer4四个分支分别添加了各种模块(GCN是添加了GCN和BR,ExFuse是SEB和GCN),然后从layer4开始向上融合;
不同之处在于(虚线部分):ExFuse为了有效的进行特征融合,提出了多个模块(将语义信息引入低级特征:LR,SS,SEB;将空间信息嵌入高级特征:ECRE,DAP)加入框架中。
下面分别就将语义信息引入低级特征和将空间信息嵌入高级特征两方面分别描述各自提出的模块。
2.1、将更多语义信息引入低级特征
这部分内容的提出,主要基于以下事实:卷积神经网络中,靠近语义监督(如分类损失函数)的feature maps倾向于编码更多语义信息。这句话怎么理解呢?其实很简单,就比如在分类网络中,越是靠后(靠近输出端)的卷积层,其输出的feature map所包含的语义信息就越丰富。
为了将语义信息引入低级特征所提出的方法有三个:LR,SS,SEB。
2.1.1、LR——卷积层重排列
主要是修改了ResNet中各个阶段中 building blocks(构建块)的个数。如在ResNet101中,第2~5stage(阶段),分别有 {3,4,23,3}个构建块(也就是ResNet网络构建时,使用_make_layer函数构对每个layer造了不同数量的block),现在将这些块重新分配给各阶段: {8,8,9,8}。这样一来,总的构建块个数不变(都是33),并且分类性能不变,但是分割性能提高了0.8%。这说明低级特征的质量是可以提升的。
个人感觉,LR的作用就是将每个块中的卷积数量平均一下,使得原来的早期阶段(如stage2~3)获得更多的计算量,这样在对每个阶段尾部进行特征融合时,不至于低级特征由于计算量不足而导致跟不上高级特征的节奏。
2.1.2、SS——语义监督
另一种改善低级特征的方法是给早期阶段添加一个辅助的监督,称为语义监督,也即图2中最左边的SS模块。这样一来,早期阶段的特征就被迫多学点语义特征,这样对后续的高低级特征融合是有帮助的。其实,这种添加辅助监督,或者说是添加辅助损失函数的方法,在以前的分类网络中也有人用过,此外PSPNet中也用过(可以参考这篇博客中的解析)。
与PSPNet中添加辅助监督的目的不同:ExFuse是为了使低级特征学到更多语义信息,而PSPNet是为了简化训练(因为PSPNet没有从早期阶段提取特征)。作者对每个阶段添加了语义监督后,backbone网络的分类性能是下降了的,不过语义分割性能有所提升,如表2所示:
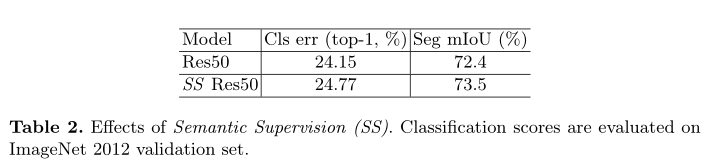
这个怎么理解呢?个人认为是这样:既然添加语义监督的目的是为了让低层级获取更多语义信息,那么相应的其分类性能就难免会受到影响,毕竟模型的目的不一样了。但既然对分割有效,那就可以使用。
至于SS模块的结构,就是将每个stage得到的feature maps送入两组3*3卷积,再接上全局池化、全连接层,然后进行预训练。SS组件如图3:

此外,如果从辅助模块的第二层卷积提取feature maps(也即图3中的第二个3*3Conv模块的输出)来用作后续的微调,性能还能进一步提升1.5%。这一点也验证了作者的猜想:越是接近监督(也就是模型的输出部分,或者说是用于计算损失函数的部分;对于图3的辅助模块,就是最下层的输出)的feature maps其编码的语义信息就越多。
2.1.3、SEB——语义嵌入分支
对于普通的特征融合,其方式是对高级-低分辨率的特征上采样然后与低级-高分辨率的特征相加,如:
(1)
式(1)中的残差项是低级-高分辨率的特征。然而,如果残差项
包含的语义信息较少,其恢复的语义就会不够,于是作者提出了下面这种方式进行特征融合:
(2)
也即:先将当前stage的feature maps和其后各个stage的feature maps融合(公式2的后半部分),然后将下一stage的feature maps上采样(公式2的前半部分),最后add相加(整个公式2);其意义就是:将多个高级-低分辨率的语义信息包含进来,以指导特征的融合。
各个stage的特征融合(公式2的后半部分)方式如图4所示:

2.2、将更多空间分辨率信息嵌入到高级特征中
对于大多backbone特征提取网络来说,其高级特征往往会具有较低的分辨率(HRNet是个例外,后面专门写篇文章来讲一下),比如ResNet或者ResNext从大小为224*224的输入得到7*7的feature maps(下采样32倍)。一种解决方案是dilated strategy(膨胀策略,也即利用空洞卷积获取高分辨率的输出),这种方式的优点是不需要重新训练backbone,缺点是计算量太大。ExFuse没有采用这种“物理方法”,而是使用了将更多的分辨率信息编码进通道中的方法,也即是其提出的ECRE和DAP模块。
2.2.1、ECRE——显式通道分辨率嵌入
在ExFuse的整个框架中,分割损失仅与Decoder输出相关,这在一定程度上对高级特征中的空间信息影响较小。一种解决方案就是上文提到的SS模块——通过对高级feature maps添加辅助监督分支,强迫其学习到精细的分割结果。于是乎,按照这种思路就提出了ECRE模块,就是图2中的浅蓝色的模块。
ECRE模块对第一个上采样模块(图2中最下面)添加一个辅助损失,使该部分能够包含更多空间分辨率信息。作者尝试了两种方案:第一种是使用反卷积+辅助损失,第二种是使用亚像素上采样(Sub-pixel Upsample)+辅助损失。实验发现,直接使用第一种方案并不work,而第二种方案work。此外,为了验证使该方法work的因素不是由Sub-pixel Upsample造成的,作者单单只用了Sub-pixel Upsample而没有加辅助损失,发现效果变得特别差,这也就说了要和辅助损失一起用才work。
ECRE模块示意图如图5所示:

2.2.2、DAP——密集邻域预测
通常在解码器中,一个点负责预测一个同位置的语义信息。作者提出DAP模块来使得一个点可以预测其邻域通道的语义信息,然后再求平均,从而得到更鲁棒的预测结果。DAP示意图如图6所示:

使用了DAP,可提高约0.6%的mIOU。
3、实验结果
在PASCAL VOC 2012上与各主流模型进行的对比如表8所示,可以看出,ExFuse是优于其他各模型的。

分割结果可视化如图7所示:

4、结论
总得来说,ExFuse是基于GCN进行了特征融合的增强,提出了多种模块来进行不同方向的融合,包括将语义信息融合低级特征(LR、SS、SEB)和将空间信息嵌入高级特征(ECRE、DAP),分别弥补了低级特征中语义信息不足、高级特征中空间信息不足的缺点。在这些方法的加持下,ExFuse达到了当时的SOTA。