机器学习实战:基于Scikit-Learn和TensorFlow—第三章笔记
一、学习目标
第三章将从分类的角度来进行学习,并且引入很多对于检验分类效果的性能指标。
二、数据集
本章将使用MNIST数据集,这是一组由美国高中生和人口调查局员工手写的70000个数字的图片。每张图像都用其代表的数字标记。
这边我是先把数据下载到本地来进行加载使用了。
from sklearn.datasets import fetch_mldata
# 类型为 <class 'sklearn.utils.Bunch'>
mnist = fetch_mldata('MNIST Original',data_home='./')
整个数据集共有7万张图片,每张图片有784个特征。因为图片是28×28像素,每个特征代表了一个像素点的强度,从0(白色)到255(黑色)。
三、性能指标
3.1、训练一个二元分类器(只针对数字5,也就是区分这个数字是不是5)
y_train_5 = (y_train == 5) # True for all 5s, False for all other digits.
y_test_5 = (y_test == 5)
# 随机梯度下降(SGD)分类器进行训练
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
使用交叉验证来检验:
print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy"))
发现所有折叠交叉验证的准确率(正确预测的比率)超过95%,好像很不错,但是看看下面。
假设这里有一个笨的分类器,它将每张图都分类成“非5”:
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
来看看这个模型的准确度:
print(cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy"))
准确率超过90%!这是因为只有大约10%的图像是数字5,所以如果你猜一张图不是5,90%的时间你都是正确。这说明准确率通常无法成为分类器的首要性能指标,特别是当你处理偏斜数据集(skewed dataset)的时候(即某些类比其他类更为频繁)。所以接下来要引入评估分类器性能的更好方法。
3.2、混淆矩阵
评估分类器性能的更好方法是混淆矩阵。总体思路就是统计A类别实例被分成为B类别的次数。
继续使用上面的分类器,来看看它的混淆矩阵。
y_train_5 = (y_train == 5) # True for all 5s, False for all other digits.
y_test_5 = (y_test == 5)
# 随机梯度下降(SGD)分类器进行训练
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
# 与cross_val_score()函数一样,cross_val_predict()函数同样执行K-fold交叉验证,但返回的不是评估分数,而是每个折叠的预测。
# 这意味着对于每个实例都可以得到一个干净的预测(“干净”的意思是模型预测时使用的数据,在其训练期间从未见过)。
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
print(confusion_matrix(y_train_5, y_train_pred))
最终输出:
[[53272, 1307]
[ 1077, 4344]]
混淆矩阵中的行表示实际类别,列表示预测类别。本例中第一行表示所有“非5”(负类)的图片中:53272张被正确地分为“非5”类别(真负类),1307张被错误地分类成了“5”(假正类);第二行表示
所有“5”(正类)的图片中:1077张被错误地分为“非5”类别(假负类),4344张被正确地分在了“5”这一类别(真正类)。一个完美的分类器只有真正类和真负类,所以它的混淆矩阵只会在其对角线(左上到右下)上有非零值,如:
[54579, 0]
[ 0, 5421]]
这里注明一下,可能大家在网上查资料的时候看到的例子是说列表示实际类别,行表示预测类别,这是因为在sklearn中生成的混淆矩阵中,行表示实际类别,列表示预测类别,此处需要注意。
3.3、精度
正类预测的准确率是一个有意思的指标
公式1:精度
TP / TP + FP
TP是真正类的数量,FP是假正类的数量。
3.4、召回率
做一个单独的正类预测,并确保它是正确的,就可以得到完美精度(精度=1/1=100%)。但这没什么意义,因为分类器会忽略这个正类实例之外的所有内容。因此,精度通常与另一个指标一起使用,这个指标就是召回率(recall),也称为灵敏度(sensitivity)或者真正类率(TPR):它是分类器正确检测到的正类实例的比率
公式2:召回率
TP / TP + FN
FN是假负类的数量
Scikit-Learn提供了计算多种分类器指标的函数,精度和召回率也是其一:
print(precision_score(y_train_5, y_train_pred))
print(recall_score(y_train_5, y_train_pred))
输出0.76871350203503808和0.79136690647482011
现在再看,这个5-检测器看起来似乎并不像它的准确率那么光鲜亮眼了。当它说一张图片是5时,只有77%的时间是准确的,并且也只有79%的数字5被它检测出来了。
3.5、F1分数
将精度和召回率组合成一个单一的指标,称为F1分数。当你需要一个简单的方法来比较两种分类器时,这是个非常不错的指标。F1分数是精度和召回率的谐波平均值。正常的平均值平等对待所有的值,而谐波平均值会给予较低的值更高的权重。因此,只有当召回率和精度都很高时,分类器才能得到较高的F1分数。
公式3:F1分数
TP / (TP + (FN + FP) / 2)
要计算F 1 分数,只需要调用f1_score()即可
print(f1_score(y_train_5, y_train_pred))
3.6、精度/召回率权衡
要理解这个权衡过程,我们来看看SGDClassifier如何进行分类决策。对于每个实例,它会基于决策函数计算出一个分值,如果该值大于阈值,则将该实例判为正类,否则便将其判为负类。下图显示了
从左边最低分到右边最高分的几个数字。假设决策阈值位于中间箭头位置(两个5之间):在阈值的右侧可以找到4个真正类(真的5),一个假正类(实际上是6)。因此,在该阈值下,精度为80%(4/5)。但是在6个真正的5中,分类器仅检测到了4个,所以召回率为67%(4/6)。现在,如果提高阈值(将其挪动到右边箭头的位置),假正类(数字6)变成了真负类,因此精度得到提升(本例中提升到100%),但是一个真正类变成一个假负类,召回率降低至50%。反之,降低阈值则会在增加召回率的同时降低精度。
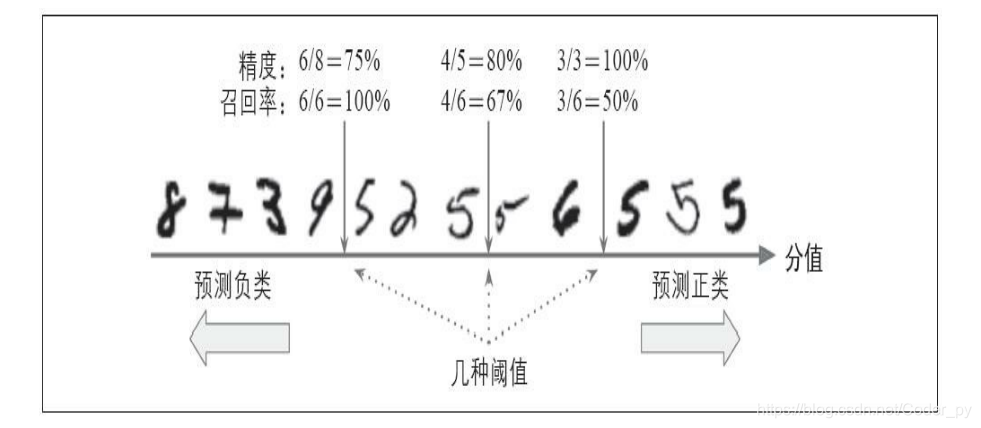
那么要如何决定使用什么阈值呢?
使用cross_val_predict()函数获取训练集中所有实例的分数,但是这次需要它返回的是决策分数而不是预测结果:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function")
有了这些分数,可以使用precision_recall_curve()函数来计算所有可能的阈值的精度和召回率:
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
使用Matplotlib绘制精度和召回率相对于阈值的函数图:
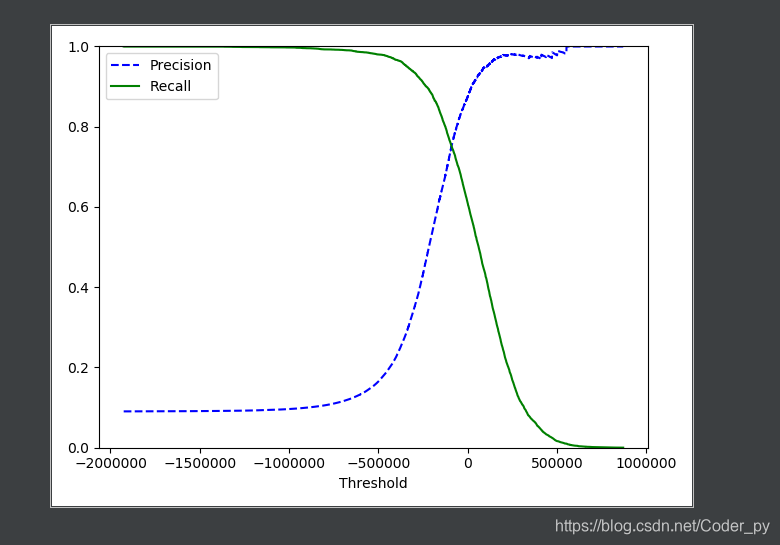
3.7、ROC曲线
还有一种经常与二元分类器一起使用的工具,叫作受试者工作特征曲线(简称ROC)。它与精度/召回率曲线非常相似,但绘制的不是精度和召回率,而是真正类率(召回率的另一名称)和假正类率(FPR)。FPR是被错误分为正类的负类实例比率。它等于1减去真负类率(TNR),后者是被正确分类为负类的负类实例比率,也称为特异度。因此,ROC曲线绘制的是灵敏度和(1-特异度)的关系。
要绘制ROC曲线,首先需要使用roc_curve()函数计算多种阈值的TPR和FPR:
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
使用Matplotlib绘制FPR对TPR的曲线:

同样这里再次面临一个折中权衡:召回率(TPR)越高,分类器产生的假正类(FPR)就越多。虚线表示纯随机分类器的ROC曲线;一个优秀的分类器应该离这条线越远越好(向左上角)。
有一种比较分类器的方法是测量曲线下面积(AUC)。完美的分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。Scikit-Learn提供计算ROC AUC的函数:
roc_auc_score(y_train_5, y_scores)
这章笔记就到这里了,后面还有些剩余内容,但笔记主要想记录下分类的性能指标。
- 参考资料 <<机器学习实战:基于Scikit-Learn和TensorFlow>>
