· Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition, by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géron, 978-1-492-03264-9.
· 《机器学习》周志华
· 环境:Anaconda(Python 3.8) + Pycharm
· 学习时间:2022.05.08~2022.05.09
第九章 无监督学习技术
尽管今天机器学习的大多数应用都是基于有监督学习的(因此,这是大多数投资的方向),但是绝大多数可用数据都没有标签:我们具有输入特征X,但是没有标签y。计算机科学家Yann LeCun曾有句著名的话:“如果智能是蛋糕,无监督学习将是蛋糕本体,有监督学习是蛋糕上的糖霜,强化学习是蛋糕上的樱桃。”换句话说,无监督学习具有巨大的潜力,我们才刚刚开始研究。
假设你要创建一个系统,该系统将在制造生产线上为每个产品拍摄几张图片,并检测哪些产品有缺陷。你可以相当容易地创建一个自动拍照系统,这可能每天为你提供数千张图片。然后,你可以在几周内构建一个相当大的数据集。但是,等等,没有标签!如果你想训练一个常规的二元分类器来预测某件产品是否有缺陷,则需要将每张图片标记为“有缺陷”或“正常”。这通常需要人类专家坐下来并手动浏览所有图片。这是一项漫长、昂贵且烦琐的任务,因此通常只能在可用图片的一部分上完成。因此,标记的数据集将非常小,并且分类器的性能将令人失望。而且,公司每次对其产品进行任何更改时,都需要从头开始整个过程。如果该算法只需要利用未标记的数据而无须人工标记每张图片,那不是很好吗?让我们进入无监督学习。
在第8章中,我们研究了最常见的无监督学习任务:降维。在本章中,我们将研究其他一些无监督的学习任务和算法:
-
聚类:目标是将相似的实例分组到集群中。聚类是很好的工具,用于数据分析、客户细分、推荐系统、搜索引擎、图像分割、半监督学习、降维等。
-
异常检测:目的是学习“正常”数据看起来是什么样的,然后将其用于检测异常情况,例如生产线上的缺陷产品或时间序列中的新趋势。
-
密度估算:这是估计生成数据集的随机过程的概率密度函数(PDF)的任务,密度估算通常用于异常检测:位于非常低密度区域的实例很可能是异常。它对于数据分析和可视化也很有用。
准备好蛋糕了吗?我们将从使用K-Means和DBSCAN进行聚类开始,然后讨论高斯混合模型,并了解如何将它们用于密度估计、聚类和异常检测。
文章目录
9.1 聚类
你在山中徒步旅行时,偶然发现了从未见过的植物。你环顾四周,发现还有很多。它们并不完全相同,但是它们足够相似,你可能知道它们有可能属于同一物种(或至少属于同一属)。你可能需要植物学家告诉你什么是物种,但你当然不需要专家来识别外观相似的物体组。这称为聚类:识别相似实例并将其分配给相似实例的集群或组。
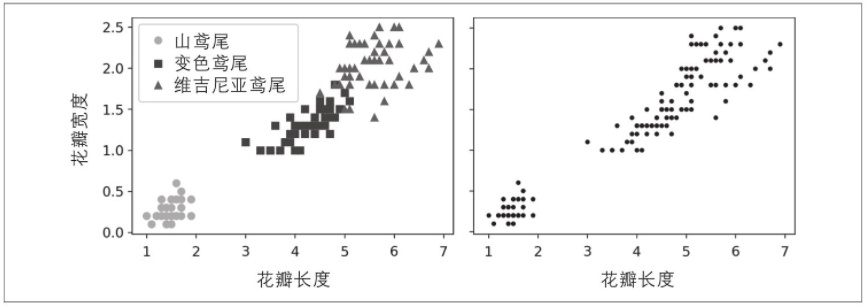
就像在分类中一样,每个实例都分配给一个组。但是与分类不同,聚类是一项无监督任务。考虑下图:左侧是鸢尾花数据集(在第4章中介绍),其中每个实例的种类(即类)用不同的标记表示。它是一个标记的数据集,非常适合使用逻辑回归、SVM或随机森林分类器等分类算法。右侧是相同的数据集,但是没有标签,因此你不能再使用分类算法。这就是聚类算法的引入之处,它们中的许多算法都可以轻松检测左下角的集群。肉眼也很容易看到,但是右上角的集群由两个不同的子集群组成,并不是很明显。也就是说,数据集具有两个附加特征(萼片长度和宽度),此处未表示,并且聚类算法可以很好地利用所有的特征,因此实际上它们可以很好地识别三个聚类(例如,使用高斯混合模型,在150个实例中,只有5个实例分配给错误的集群)。
聚类可用于各种应用程序,包括:
-
客户细分:你可以根据客户的购买记录和他们在网站上的活动对客户进行聚类。这对于了解你的客户是谁以及他们的需求很有用,因此你可以针对每个细分客户调整产品和营销活动。例如,客户细分在推荐系统中可以很有用,可以推荐同一集群中其他用户喜欢的内容。
-
数据分析:在分析新数据集时,运行聚类算法然后分别分析每个集群。
-
降维技术:数据集聚类后,通常可以测量每个实例与每个集群的相似度(相似度是衡量一个实例和一个集群的相似程度)。然后可以将每个实例的特征向量x替换为其集群的向量。如果有k个集群,则此向量为k维。此向量的维度通常比原始特征向量低得多,但它可以保留足够的信息以进行进一步处理。
-
异常检测(也称为离群值检测):对所有集群具有低相似度的任何实例都可能是异常。例如,如果你已根据用户行为对网站用户进行了聚类,则可以检测到具有异常行为的用户,例如每秒的请求数量异常。异常检测在检测制造生产线中的缺陷或欺诈检测中特别有用。
-
半监督学习:如果你只有几个标签,则可以执行聚类并将标签传播到同一集群中的所有实例。该技术可以大大增加可用于后续有监督学习算法的标签数量,从而提高其性能。
-
搜索引擎:一些搜索引擎可让你搜索与参考图像相似的图像。要构建这样的系统,首先要对数据库中的所有图像应用聚类算法,相似的图像最终会出现在同一集群中。然后,当用户提供参考图像时,你需要做的就是使用训练好的聚类模型找到该图像的集群,然后可以简单地从该集群中返回所有的图像。
-
分割图像:通过根据像素的颜色对像素进行聚类,然后用其聚类的平均颜色替换每个像素的颜色,可以显著减少图像中不同颜色的数量。图像分割用于许多物体检测和跟踪系统中,因为它可以更轻松地检测每个物体的轮廓。
关于聚类什么没有统一的定义,它实际上取决于上下文,并且不同的算法会得到不同种类的集群。一些算法会寻找围绕特定点(称为中心点)的实例。其他人则寻找密集实例的连续区域:这些集群可以呈现任何形状。一些算法是分层的,寻找集群中的集群。这样的示例不胜枚举。
在本节中,我们将研究两种流行的聚类算法——K-Means和DBSCAN,并探讨它们的一些应用,例如非线性降维、半监督学习和异常检测。
补充:性能度量
聚类性能度量亦称聚类"有效性指标"(validity index)。与监督学习中的性能度量作用相似,对聚类结果,我们需通过某种性能度量来评估其好坏;另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。
聚类是将样本集 D划分为若干互不相交的子集,即样本簇。那么,什么样的聚类结果比较好呢?直观上看,我们希望"物以类聚"、即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的"簇内相似度"fintrae-cluster similarity)高且"簇间相似度"(inter-clhuster similarity)低。
聚类性能度量大致有两类. 一类是将聚类结果与某个"参考模型"(reference model)进行比较,称为"外部指标"(external index);另一类是直接考察聚类结果而不利用任何参考模型,称为"内部指标"(internal index)。
对数据集$D = {x_1,x_2, …,x_m} , 假 定 通 过 聚 类 给 出 的 簇 划 分 为 ,假定通过聚类给出的簇划分为 ,假定通过聚类给出的簇划分为C={C_1, C_2,C_k} , 参 考 模 型 给 出 的 簇 划 分 为 ,参考模型给出的簇划分为 ,参考模型给出的簇划分为C*={C_1, C^_2, …, C^_s} 。 相 应 地 , 令 。相应地,令 。相应地,令λ 与 与 与λ 分 别 表 示 与 分别表示与 分别表示与C 和 和 和C*$对应的簇标记向量。我们将样本两两配对考虑,定义:
- a = ∣ S S ∣ , S S = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ = λ j ∗ , ( i < j ) } a = |SS|, SS = \{(x_i, x_j) | λ_i=λ_j, λ_i^* = λ^*_j, (i<j)\} a=∣SS∣,SS={ (xi,xj)∣λi=λj,λi∗=λj∗,(i<j)};
- b = ∣ S D ∣ , S D = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ ≠ λ j ∗ , ( i < j ) } b = |SD|, SD = \{(x_i, x_j) | λ_i=λ_j, λ_i^* ≠ λ^*_j, (i<j)\} b=∣SD∣,SD={ (xi,xj)∣λi=λj,λi∗=λj∗,(i<j)};
- c = ∣ D S ∣ , D S = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ = λ j ∗ , ( i < j ) } c = |DS|, DS = \{(x_i, x_j) | λ_i≠λ_j, λ_i^* = λ^*_j, (i<j)\} c=∣DS∣,DS={ (xi,xj)∣λi=λj,λi∗=λj∗,(i<j)};
- d = ∣ D D ∣ , D D = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ ≠ λ j ∗ , ( i < j ) } d = |DD|, DD = \{(x_i, x_j) | λ_i≠λ_j, λ_i^* ≠ λ^*_j, (i<j)\} d=∣DD∣,DD={ (xi,xj)∣λi=λj,λi∗=λj∗,(i<j)}。
其中集合 S S SS SS包含了在 C C C中隶属于相同簇且在 C ∗ C^* C∗中也隶属于相同簇的样本对,集合 S D SD SD包含了在C中隶属于相同簇但在 C ∗ C^* C∗中隶属于不同簇的样本对,……由于每个样本对 ( x i , x j ) ( i < j ) (x_i, x_j)\ (i<j) (xi,xj) (i<j)仅能出现在一个集合中,因此有 a + b + c + d = m ( m − 1 ) / 2 a+b+c+d= m(m-1)/2 a+b+c+d=m(m−1)/2成立。
常用的聚类性能度量外部指标有(结果均在 [ 0 , 1 ] [0, 1] [0,1]区间,值越大越好):
- Jaccard系数((Jaccard Coefficient,简称 JC)
- J C = a a + b + c JC = \frac{a}{a+b+c} JC=a+b+ca
- FM指数(Fowlkes and Mallows Index,简称FMI)
- F M I = [ a / ( a + b ) ] ⋅ [ a / ( a + c ) ] FMI = \sqrt{[a/(a+b)]·[a/(a+c)]} FMI=[a/(a+b)]⋅[a/(a+c)]
- Rand 指数(Rand Index,简称 RI)
- R I = 2 ( a + d ) m ( m + 1 ) RI = \frac{2(a+d)}{m(m+1)} RI=m(m+1)2(a+d)
考虑聚类结果的簇划分 C = { C 1 , C 2 , … . , C k } C=\{C_1,C_2,….,C_k\} C={ C1,C2,….,Ck},定义:
- a v g ( C ) = 2 ∣ C ∣ ( ∣ C ∣ − 1 ) ∑ 1 ≤ i ≤ j ≤ ∣ C ∣ d i s t ( x i , x j ) avg(C)=\frac{2}{|C|(|C|-1)}\sum_{1≤i≤j≤|C|}dist(x_i,x_j) avg(C)=∣C∣(∣C∣−1)2∑1≤i≤j≤∣C∣dist(xi,xj);
- d i a m ( C ) = m a x 1 ≤ i ≤ j ≤ ∣ C ∣ d i s t ( x i , x j ) diam(C)=max_{1≤i≤j≤|C|}dist(x_i,x_j) diam(C)=max1≤i≤j≤∣C∣dist(xi,xj);
- d m i n ( C i , C j ) = m i n x i ∈ C i , x j ∈ C j d i s t ( x i , x j ) d_{min}(C_i,C_j)=min_{x_i∈C_i,x_j∈C_j}dist(x_i,x_j) dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj);
- d c e n ( C i , C j ) = d i s t ( μ i , μ j ) d_{cen}(C_i,C_j)=dist(μ_i,μ_j) dcen(Ci,Cj)=dist(μi,μj)。
其中, d i s t ( ⋅ , ⋅ ) dist(·,·) dist(⋅,⋅)用于计算两个样本之间的距离; μ μ μ代表簇 C C C的中心点 μ = 1 ∣ C ∣ ∑ 1 ≤ i ≤ ∣ C ∣ x i μ= \frac{1}{|C|}\sum_{1≤i≤|C|}x_i μ=∣C∣1∑1≤i≤∣C∣xi。显然, a v g ( C ) avg(C) avg(C)对应于簇 C C C内样本间的平均距离, d i a m ( C ) diam(C) diam(C)对应于簇 C C C内样本间的最远距离, d m i n ( C i , C j ) d_{min}(C_i, C_j) dmin(Ci,Cj)对应于簇 C i C_i Ci与簇 C j C_j Cj最近样本间的距离, d c e n ( C i , C j ) d_{cen}(C_i, C_j) dcen(Ci,Cj)对应于簇 C i C_i Ci与簇 C j C_j Cj中心点间的距离。
常用的聚类性能度量内部指标有(DBI的值越小越好,而DI则相反,值越大越好):
- DB指数(Davie9-Bouldin Index,简称DBI)
- D B I = 1 k ∑ i = 1 k m a x j ≠ i ( a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) ) DBI = \frac{1}{k}\sum_{i=1}^kmax_{j≠i}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(μ_i,μ_j)}) DBI=k1∑i=1kmaxj=i(dcen(μi,μj)avg(Ci)+avg(Cj))
- Dunn指数(Dumn Index,简称 DI)
- D I = m i n 1 ≤ i ≤ k { m i n j ≠ i ( d m i n ( C i , C j ) m a x 1 ≤ l ≤ k d i a m ( C l ) ) } DI = min_{1≤i≤k}\{min_{j≠i}(\frac{d_{min}(C_i,C_j)}{max_{1≤l≤k}diam(C_l)})\} DI=min1≤i≤k{ minj=i(max1≤l≤kdiam(Cl)dmin(Ci,Cj))}
9.1.1 K-Means
考虑下图中所示的未标记数据集:你可以清楚地看到5组实例。K-Means算法是一种简单的算法,能够非常快速、高效地对此类数据集进行聚类,通常只需几次迭代即可。它是由贝尔实验室的Stuart Lloyd在1957年提出的,用于脉冲编码调制,但直到1982年才对外发布。1965年,Edward W.Forgy发布了相同的算法,因此K-Means有时被称为Lloyd–Forgy。
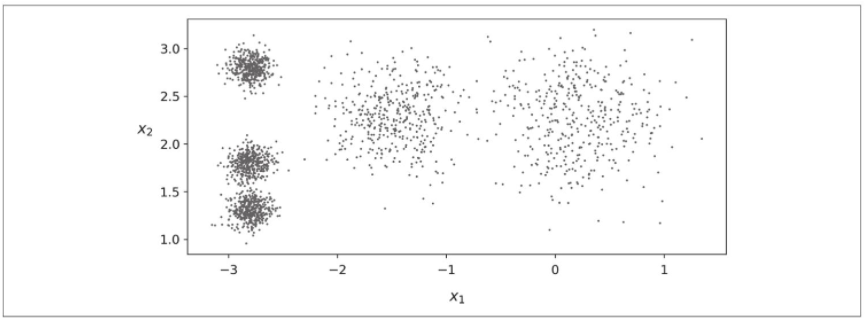
让我们在该数据集上训练一个K-Means聚类器。它将尝试找到每个集群的中心,并将每个实例分配给最近的集群:
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
blob_centers = np.array(
[[0.2, 2.3],
[-1.5, 2.3],
[-2.8, 1.8],
[-2.8, 2.8],
[-2.8, 1.3]])
blob_std = np.array([0.4, 0.3, 0.1, 0.1, 0.1])
X, y = make_blobs(n_samples=2000, centers=blob_centers, cluster_std=blob_std, random_state=7)
k = 5
kmeans = KMeans(n_clusters=k)
y_pred = kmeans.fit_predict(X)
请注意,你必须指定这个算法必须要找到的集群数k。在此例中,通过查看数据可以明显看出k应该设置为5,但总的来说并不是那么容易。我们会简短讨论这个问题。
每个实例都会分配给5个集群之一。在聚类的上下文中,实例的标签是该实例被算法分配给该集群的索引:不要与分类中的类标签相混淆(请记住,聚类是无监督学习任务)。KMeans实例保留了经过训练的实例的标签副本,可通过labels_实例变量得到该副本:
print(y_pred)
print(y_pred is kmeans.labels_)
# 输出:
# [4 0 1 ... 3 1 0]
# True
我们还可以看一下算法发现的5个中心点:
print(kmeans.cluster_centers_)
# 输出
# [[-2.80037642 1.30082566]
# [ 0.20876306 2.25551336]
# [-2.79290307 2.79641063]
# [-1.46679593 2.28585348]
# [-2.80389616 1.80117999]]
可以很容易地将新实例分配给中心点最接近的集群:
X_new = np.array([[0, 2], [3, 2], [-3, 3], [-3, 2.5]])
print(kmeans.predict(X_new))
# 输出:
# [1 1 0 0]
如果绘制集群的边界,则会得到Voronoi图(参见下图,其中每个中心点都用×表示)。
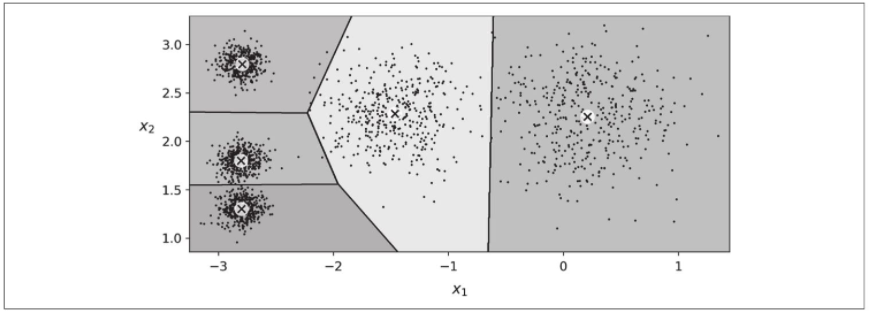
绝大多数实例已正确分配给适当的集群,但少数实例可能贴错了标签(尤其是在左上集群和中央集群之间的边界附近)。的确,当集群具有不同的直径时,K-Means算法的性能不是很好,因为将实例分配给某个集群时,它所关心的只是与中心点的距离。
与其将每个实例分配给一个单独的集群(称为硬聚类),不如为每个实例赋予每个集群一个分数(称为软聚类)会更有用。分数可以是实例与中心点之间的距离。相反,它可以是相似性分数(或远近程度),例如高斯径向基函数(在第5章中介绍)。在KMeans类中,transform()方法测量每个实例到每个中心点的距离:
print(kmeans.transform(X_new))
# 输出:
# [[2.81093633 0.32995317 1.49439034 2.9042344 2.88633901]
# [5.80730058 2.80290755 4.4759332 5.84739223 5.84236351]
# [1.21475352 3.29399768 1.69136631 0.29040966 1.71086031]
# [0.72581411 3.21806371 1.54808703 0.36159148 1.21567622]]
在此例中,X_new中的第一个实例与第一个中心点的距离为2.81,与第二个中心点的距离为0.33,与第三个中心点的距离为1.49,与第四个中心点的距离为2.90,与第五个中心点的距离为2.89。如果你有一个高维数据集并以这种方式进行转换,那么最终将得到一个k维数据集:这种转换是一种非常有效的非线性降维技术。
1. K-Means算法
那么,该算法如何工作?好吧,假设你得到了中心点。你可以通过将每个实例分配给中心点最接近的集群来标记数据集中的所有实例。相反,如果你有了所有实例的标签,则可以通过计算每个集群的实例平均值来定位所有的中心点。但是你既没有标签也没有中心点,那么如何进行呢?好吧,只要从随机放置中心点开始(例如,随机选择k个实例并将其位置用作中心点)。然后标记实例,更新中心点,标记实例,更新中心点,以此类推,直到中心点停止移动。这个算法能保证在有限数量的步骤内收敛(通常很小),不会永远振荡。
你可以在下图中看到正在使用的算法:中心点被随机初始化(左上),然后实例被标记(右上),中心点被更新(左中心),实例被重新标记(右中),以此类推。如你所看到的,仅仅三个迭代,该算法就达到了近似于最佳状态的聚类。
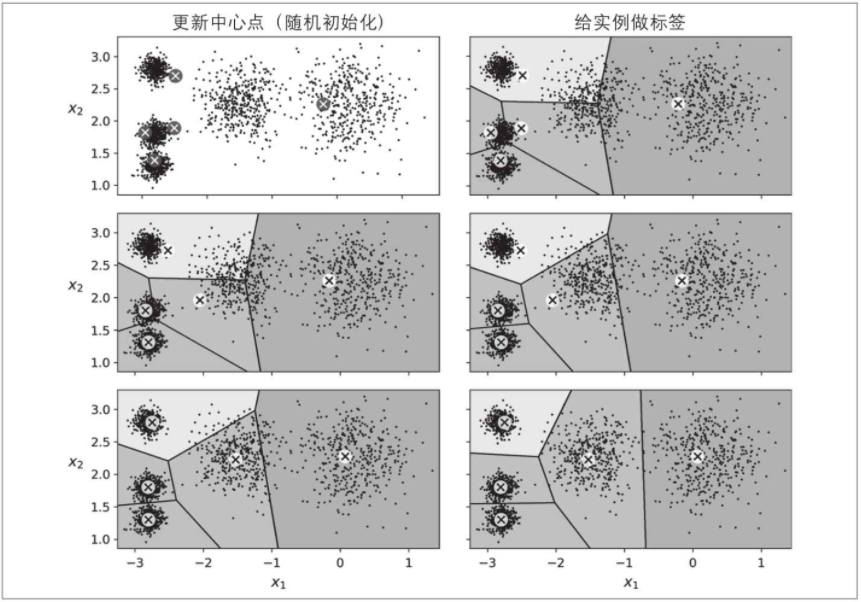
该算法的计算复杂度在实例数m,集群数k和维度n方面通常是线性的。但是,仅当数据具有聚类结构时才如此。如果不是这样,那么在最坏的情况下,复杂度会随着实例数量的增加而呈指数增加。实际上,这种情况很少发生,并且K-Means通常是最快的聚类算法之一。
尽管算法保证会收敛,但它可能不会收敛到正确解(即可能会收敛到局部最优值):这取决于中心点的初始化。图9-5显示了两个次优解,如果你不幸地使用随机初始化步骤,算法会收敛到它们。
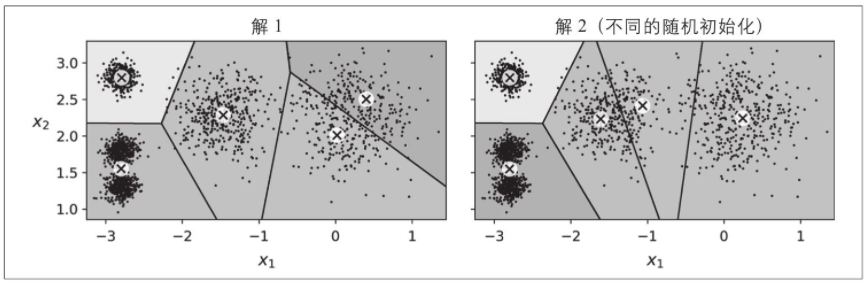
让我们看一下通过改善中心点初始化来减低这种风险的几种方法。
2. 中心点初始化方法
如果你碰巧知道了中心点应该在哪里(例如,你之前运行了另一种聚类算法),则可以将超参数init设置为包含中心点列表的NumPy数组,并将n_init设置为1:
good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]])
kmeans = KMeans(n_clusters=5, init=good_init, n_init=1)
另一种解决方案是使用不同的随机初始化多次运行算法,并保留最优解。随机初始化的数量由超参数n_init控制:默认情况下,它等于10,这意味着当你调用fit()时,前述算法运行10次,Scikit-Learn会保留最优解。但是,如何确切知道哪种解答是最优解呢?它使用性能指标!这个指标称为模型的惯性,即每个实例与其最接近的中心点之间的均方距离。对于上图左边的模型,它大约等于223.3;对于上图中右边的模型,它等于237.5;对于上上上个图中的模型,它等于211.6。KMeans类运行n_init次算法,并保留模型的最低惯性。在此例中,将选择上上上个图的模型(除非我们非常不幸地使用n_init连续随机初始化)。如果你有意,可以通过inertia_instance变量来访问模型的惯性:
kmeans.inertia_
score()方法返回负惯性。为什么是负的?因为预测器的score()方法必须始终遵循Scikit-Learn的“越大越好”的规则,即如果一个预测器比另一个更好,则其score()方法应该返回更大的数:
kmeans.score(X)
David Arthur和Sergei Vassilvitskii[3]在2006年的论文中提出了对K-Means算法的重要改进——K-Means++。他们引入了一种更智能的初始化步骤,该步骤倾向于选择彼此相距较远的中心点,这一改进使得K-Means算法收敛到次优解的可能性很小。他们表明,更智能的初始化步骤所需的额外计算量是值得的,因为它可以大大减少寻找最优解所需运行算法的次数。以下是K-Means++的初始化算法:
- 取一个中心点 c ( 1 ) c^{(1)} c(1),从数据集中随机选择一个中心点。
- 取一个新中心点 c ( i ) c^{(i)} c(i),选择一个概率为 D ( x ( i ) ) 2 / ∑ j = 1 m D ( x ( j ) ) 2 D(x^{(i)})^2/\sum^m_{j=1}D(x^{(j)})^2 D(x(i))2/∑j=1mD(x(j))2的实例 x ( i ) x^{(i)} x(i),其中 D ( x ( i ) ) D(x^{(i)}) D(x(i))是实例 x ( i ) x^{(i)} x(i)与已经选择的最远中心点的距离。这种概率分布确保距离已选择的中心点较远的实例有更大可能性被选择为中心点。
- 重复上一步,直到选择了所有k个中心点。
默认情况下,KMeans类使用这种初始化方法。如果要强制使用原始方法(即随机选择k个实例来初始化中心点),则可以将超参数init设置为"random"。你很少需要这样做。
3. 加速的K-Means和小批量K-Means
Charles Elkan在2003年的一篇论文中提出了对K-Means算法的另一个重要改进。该改进后的算法通过避免许多不必要的距离计算,大大加快了算法的速度。Elkan通过利用三角不等式(即一条直线是两点之间的最短距离)并通过跟踪实例和中心点之间的上下限距离来实现这一目的。这是KMeans类默认使用的算法(你可以通过将超参数algorithm设置为"full"来强制使用原始算法,尽管你可能永远也不需要)。
David Sculley在2010年的一篇论文中提出了K-Means算法的另一个重要变体。该算法能够在每次迭代中使用小批量K-Means稍微移动中心点,而不是在每次迭代中使用完整的数据集。这将算法的速度提高了3到4倍,并且可以对不容纳内存的大数据集进行聚类。Scikit-Learn在MiniBatchKMeans类中实现了此算法。你可以像KMeans类一样使用此类:
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5)
minibatch_kmeans.fit(X)
如果数据集无法容纳在内存中,则最简单的选择是使用memmap类,就像我们在第8章中对增量PCA所做的那样。或者你可以一次将一个小批量传给partial_fit()方法,但这需要更多的工作,因为你需要执行多次初始化并选择一个最好的初始化(有关示例请参阅notebook的小批量处理K-Means部分)。
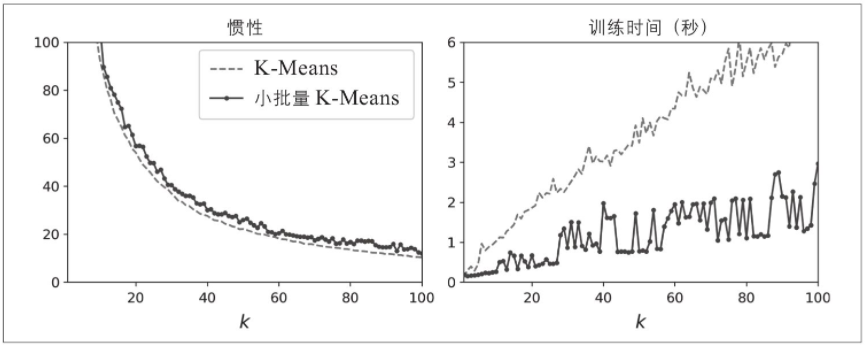
尽管小批量K-Means算法比常规K-Means算法快得多,但其惯性通常略差一些,尤其是随着集群的增加。你可以在下图中看到这一点:左侧的图比较了小批量K-Means和常规K-Means模型的惯性,这是在先前数据集上使用各种不同k训练而来的。两条曲线之间的差异保持相当恒定,但是随着k的增加,该差异变得越来越大,因为惯性变得越来越小。在右边的图中,你可以看到小批量K-Means比常规K-Means快得多,并且该差异随k的增加而增加。
4. 寻找最佳聚类数
到目前为止,我们将集群数k设置为5,因为通过查看数据可以明显看出这是正确的集群数。但是总的来说,知道如何设置k并不容易,如果将k设置为错误值,结果可能会很糟糕。如下图所示,将k设置为3或8会导致非常糟糕的模型。
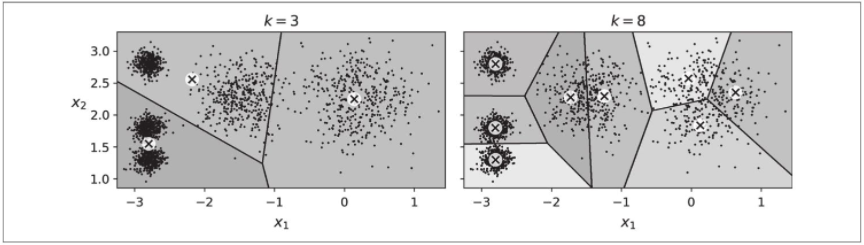
你可能会认为我们可以选择惯性最低的模型,对吗?不是那么简单!k=3的惯性是653.2,比k=5(211.6)大得多。但是在k=8的情况下,惯性仅为119.1。尝试选择k时,惯性不是一个好的性能指标,因为随着k的增加,惯性会不断降低。实际上,集群越多,每个实例将越接近其最接近的中心点,因此惯性将越低。让我们将惯性作为k的函数作图(见下图)。
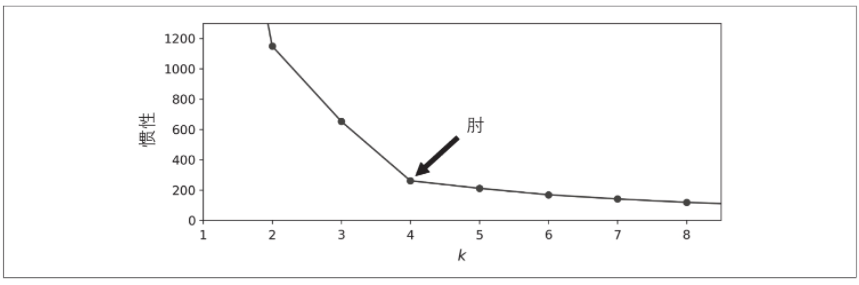
如你所见,随着k增大到4,惯性下降得很快,但随着k继续增大,惯性下降得很慢。该曲线大致像手臂形状,在k=4处有一个“肘”形。因此,如果我们不知道更好的选择,则4是一个不错的选择:较低的值变化比较大,而较高的值没有多大帮助,我们有时可以把集群再细分成两半。
为集群数选择最佳值的技术相当粗糙。一种更精确的方法(但也需要更多的计算)是使用轮廓分数,它是所有实例的平均轮廓系数。实例的轮廓系数等于 ( b − a ) / m a x ( a , b ) (b-a)/max(a,b) (b−a)/max(a,b),其中a是与同一集群中其他实例的平均距离(即集群内平均距离),b是平均最近集群距离(即到下一个最近集群实例的平均距离,定义为使b最小的那个,不包括实例自身的集群)。轮廓系数可以在-1和+1之间变化。接近+1的系数表示该实例很好地位于其自身的集群中,并且远离其他集群,而接近0的系数表示该实例接近一个集群的边界,最后一个接近-1的系数意味着该实例可能已分配给错误的集群。
要计算轮廓分数,可以使用Scikit-Learn的silhouette_score()函数,为它输入数据集中的所有实例以及为其分配的标签:
from sklearn.metrics import silhouette_score
print(silhouette_score(X, kmeans.labels_))
让我们比较不同集群数量的轮廓分数(见下图)。

如你所见,这个可视化效果比上一个更加丰富:尽管它确认k=4是一个很好的选择,但它也说明一个事实,即k=5也非常好,并且比k=6或者k=7要好得多。这个在比较惯性时看不到。
当你绘制每个实例的轮廓系数时,可以获得更加丰富的可视化效果,这些轮廓系数按它们分配的集群和系数值进行排序,这称为轮廓图(见下图)。每个图包含一个刀形的聚类。形状的高度表示集群包含的实例数,宽度表示集群中实例的排序轮廓系数(越宽越好)。虚线表示平均轮廓系数。
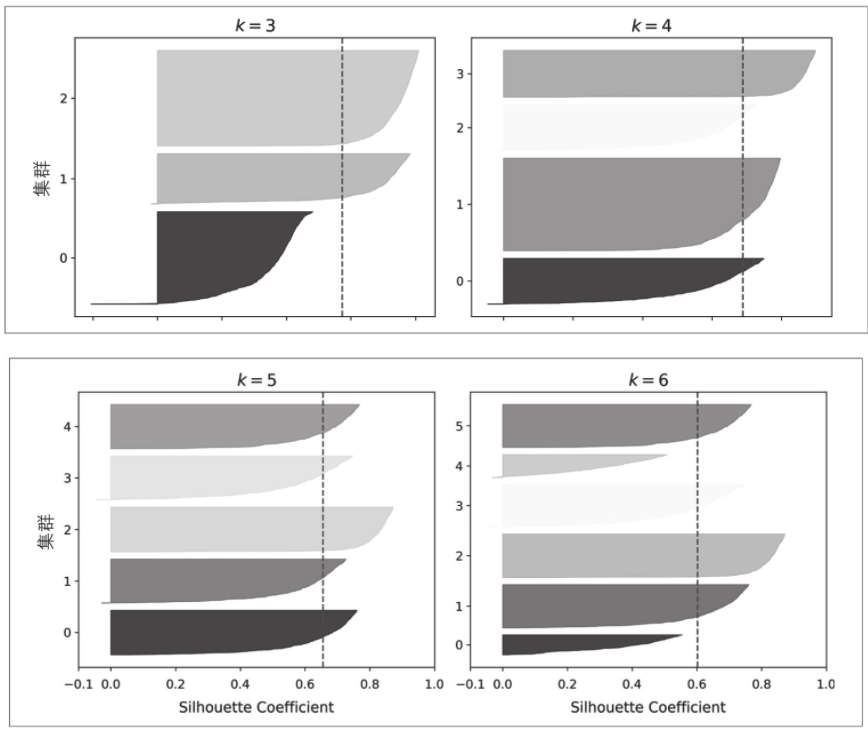
垂直虚线表示每个集群的轮廓分数。当集群中的大多数实例的系数均低于此分数时(如果许多实例在虚线附近停止,在其左侧结束),则该集群比较糟糕,因为这意味着其实例太接近其他集群了。可以看到,当k=3或者k=6时,我们得到了不好的集群。但是当k=4或k=5时,集群看起来很好:大多数实例都超出虚线,向右延伸并接近1.0。当k=4时,索引为1(从顶部开始的第三个)的集群很大。当k=5时,所有集群的大小都相似。因此,即使k=4的整体轮廓得分略大于k=5的轮廓得分,使用k=5来获得相似大小的集群似乎也是一个好主意。
9.1.2 K-Means的局限
尽管K-Means有许多优点,尤其是快速且可扩展,但它并不完美。如我们所见,必须多次运行该算法才能避免次优解,此外,你还需要指定集群数,这很麻烦。此外,当集群具有不同的大小、不同的密度或非球形时,K-Means的表现也不佳。例如,下图显示了K-Means如何对包含三个不同尺寸、密度和方向的椭圆形集群的数据集进行聚类。
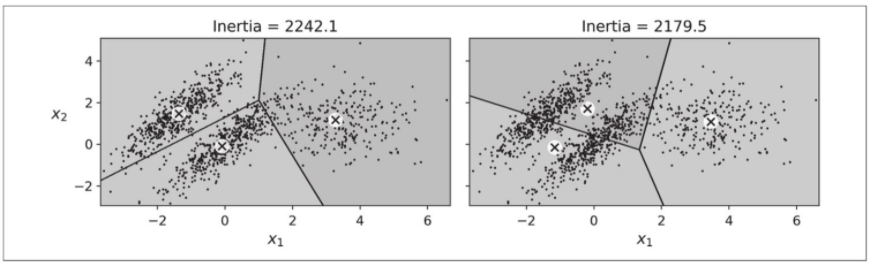
如你所见,这些聚类的结果都不好。左边的结果好一点,但是它仍然砍掉了中间集群的25%,并将其分配给右边的集群。即使其惯性较低,右侧的结果也很糟糕。因此,根据数据,不同的聚类算法可能会表现好一点。在这种类型的椭圆簇上,高斯混合模型非常有效。
在运行K-Means之前,请先缩放输入特征,否则集群可能会变形,这样K-Means的性能会很差。缩放特征并不能保证所有的集群都很好,但是通常可以改善结果。
现在让我们看一些可以从聚类中受益的方法。我们将使用K-Means,但可以随时试验其他的聚类算法。
9.1.3 使用聚类进行图像分割
图像分割是将图像分成多个分割的任务。在语义分割中,属于同一对象类型的所有像素均被分配给同一分割。例如,在无人驾驶汽车的视觉系统中,可能会将行人图像中的所有像素都分配给“行人”(会有一个包含所有行人的分割)。在实例分割中,属于同一单个对象的所有像素都分配给同一分割。在这种情况下,每个行人会有不同的分割。如今,使用最新技术的基于卷积神经网络的复杂结构可以实现语义分割或实例分割(见第14章)。在这里,我们做一些简单的事情:颜色分割。如果像素具有相似的颜色,我们将简单地将它们分配给同一分割。在某些应用中,这可能就足够了。例如,如果要分析卫星图像以测量某个区域中有多少森林总面积,则颜色分割就很好了。
首先,使用Matplotlib的imread()函数加载图像(见下图的左上方图像):
import os
from matplotlib.image import imread # or `from imageio import imread`
image = imread(os.path.join("images", "unsupervised_learning", "ladybug.png"))
print(image.shape)
# 输出:(533, 800, 3)

图像表示为3D数组。第一维的大小是高度,第二个是宽度,第三个是颜色通道的数量,在这种情况下为红色、绿色和蓝色(RGB)。换句话说,对于每个像素都有一个3D向量,包含红色、绿色和蓝色的强度,强度在0.0和1.0之间(如果使用imageio.imread(),则在0和255之间)。某些图像可能具有较少的通道,例如灰度图像(一个通道)。某些图像可能具有更多的通道,例如具有透明度的alpha通道的图像或卫星图像,这些图像通常包含许多光频率(例如红外)的通道。
以下代码对数组进行重构以得到RGB颜色的长列表,然后使用K-Means将这些颜色聚类:
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
例如,它可以识别所有绿色阴影的颜色聚类。接下来,对于每种颜色(例如深绿色),它会寻找像素颜色集群的平均颜色。例如,所有绿色阴影都可以用相同的浅绿色代替(假设绿色集群的平均颜色是浅绿色)。最后,它会重新调整颜色的长列表,使其形状与原始图像相同。我们完成了!
这样就输出了上图右上方所示的图像。你可以尝试各种数量的集群,如上图所示。当你使用少于8个集群时,请注意,瓢虫的闪亮红色不能聚成单独的一类,它将与环境中的颜色合并。这是因为K-Means更喜欢相似大小的集群。瓢虫很小,比图像的其余部分要小得多,所以即使它的颜色是鲜明的,K-Means也不能为它指定一个集群。
不是很难,不是吗?现在让我们看一下聚类的另一个应用:预处理。
9.1.4 使用聚类进行预处理
聚类是一种有效的降维方法,特别是作为有监督学习算法之前的预处理步骤。作为使用聚类进行降维的示例,让我们处理数字数据集,它是一个类似于MNIST的简单数据集,其中包含了表示从0到9数字的1797个灰度8×8图像。首先,加载数据集,将其分为训练集和测试集:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
X_digits, y_digits = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X_digits, y_digits)
拟合一个逻辑回归模型,在测试集上评估其精度:
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
print(log_reg.score(X_test, y_test))
# 输出:0.9688888888888889
这就是我们的基准:准确率为96.9%。让我们看看通过使用K-Means作为预处理是否可以做得更好。我们创建一个流水线,该流水线首先将训练集聚类为50个集群,并将图像替换为其与这50个集群的距离,然后应用逻辑回归模型:
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
("kmeans", KMeans(n_clusters=50)),
("log_reg", LogisticRegression()),
])
pipeline.fit(X_train, y_train)
# 评估这个分类流水线:
print(pipeline.score(X_test, y_test))
# 输出:0.9777777777777777
由于有10个不同的数字,因此很容易将集群数量设置为10。但是,每个数字可以用几种不同的方式写入,因此最好使用更大的集群数量,例如50。
怎么样?我们把错误率降低了近30%(从大约3.1%降低到大约2.2%)!
但是我们是任意选择集群k,我们当然可以做得更好。由于K-Means只是分类流水线中的预处理步骤,因此为k找到一个好的值要比以前简单得多。无须执行轮廓分析或最小化惯性。k的最优解是在交叉验证过程中的最佳分类性能的值。我们可以使用GridSearchCV来找到集群的最优解:
from sklearn.model_selection import GridSearchCV
param_grid = dict(kmeans__n_clusters=range(2, 100))
grid_clf = GridSearchCV(pipeline, param_grid, cv=3, verbose=2)
grid_clf.fit(X_train, y_train)
让我们看一下k的最优解和流水线的性能:
print(grid_clf.best_params)
print(grid_clf.score(X_test, y_test))
# 输出:
# {'kmeans__n_clusters': 99}
# 0.9822222222222222
在k=99个聚类的情况下,我们获得了显著的精度提升,在测试集上达到了98.22%的精度。你可以继续探索更高值的k,因为99是我们探索范围内的最大值。
9.1.5 使用聚类进行半监督学习
聚类的另一个应用是在半监督学习中,我们有很多未标记的实例,而很少带标签的实例。让我们在digits数据集的50个带标签实例的样本上训练逻辑回归模型:
n_labeled = 50
log_reg = LogisticRegression()
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])
# 该模型在测试集上的性能如何呢?
print(log_reg.score(X_test, y_test))
# 输出:0.8333333333333334
精度仅为83.3%。毫不奇怪,这比我们在完整的训练集上训练模型时要低得多。让我们看看如何能做得更好。首先,我们将训练集聚类为50个集群。然后,对于每个集群,找到最接近中心点的图像。我们将这些图像称为代表性图像:
k = 50
kmeans = KMeans(n_clusters=k)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = np.argmin(X_digits_dist, axis=0)
X_representative_digits = X_train[representative_digit_idx]
下图显示了这50张代表性图像:

让我们看一下每个图像并手动标记它:
y_representative_digits = np.array([
4, 8, 0, 6, 8, 3, 7, 7, 9, 2,
5, 5, 8, 5, 2, 1, 2, 9, 6, 1,
1, 6, 9, 0, 8, 3, 0, 7, 4, 1,
6, 5, 2, 4, 1, 8, 6, 3, 9, 2,
4, 2, 9, 4, 7, 6, 2, 3, 1, 1])
现在,我们有一个只有50个带标签实例的数据集,但是它们不是随机实例,每个实例都是其集群的代表图像。让我们看看性能是否更好:
log_reg = LogisticRegression()
log_reg.fit(X_representative_digits, y_representative_digits)
print(log_reg.score(X_test, y_test))
# 输出:0.9222222222222223
哇!尽管我们仍然仅在50个实例上训练模型,但准确性从83.3%跃升至92.2%。由于标记实例通常很昂贵且很痛苦,尤其是当必须由专家手动完成时,标记代表性实例(而不是随机实例)是一个好主意。
但是也许我们可以更进一步:如果将标签传播到同一集群中的所有其他实例,会怎么样?这称为标签传播:
y_train_propagated = np.empty(len(X_train), dtype=np.int32)
for i in range(k):
y_train_propagated[kmeans.labels_ == i] = y_representative_digits[i]
# 再次训练模型并查看其性能:
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train_propagated)
print(log_reg.score(X_test, y_test))
# 输出:0.9333333333333333
我们获得了合理的精度提升,这不让人惊奇。问题在于,我们把每个代表性实例的标签传播到同一集群中的所有实例,包括位于集群边界附近的实例,这些实例更容易被错误标记。让我们看看如果仅将标签传播到最接近中心点的20%的实例,会发生什么情况:
percentile_closest = 20
X_cluster_dist = X_digits_dist[np.arange(len(X_train)), kmeans.labels_]
for i in range(k):
in_cluster = (kmeans.labels_ == i)
cluster_dist = X_cluster_dist[in_cluster]
cutoff_distance = np.percentile(cluster_dist, percentile_closest)
above_cutoff = (X_cluster_dist > cutoff_distance)
X_cluster_dist[in_cluster & above_cutoff] = -1
partially_propagated = (X_cluster_dist != -1)
X_train_partially_propagated = X_train[partially_propagated]
y_train_partially_propagated = y_train_propagated[partially_propagated]
# 在这个部分传播的数据集上再次训练模型:
log_reg = LogisticRegression()
log_reg.fit(X_train_partially_propagated, y_train_partially_propagated)
print(log_reg.score(X_test, y_test))
# 输出:0.94
很好!仅使用50个带标签的实例(平均每个类只有5个实例!),我们获得了94.0%的准确率,与整个带标签的数字数据集上逻辑回归的性能非常接近(96.9%)。之所以如此出色,是因为传播的标签实际上非常好,它们的准确率非常接近99%,如以下代码所示:
print(np.mean(y_train_partially_propagated == y_train[partially_propagated]))
# 输出:0.9896907216494846
主动学习
为了继续改进模型和训练集,下一步可能是进行几轮主动学习,即当人类专家与学习算法进行交互时,在算法要求时为特定实例提供标签。主动学习有许多不同的策略,但最常见的策略之一称为不确定性采样。下面是它的工作原理:
-
该模型是在目前为止收集到的带标签的实例上进行训练,并且该模型用于对所有未标记实例进行预测。
-
把模型预测最不确定的实例(当估计的概率最低时)提供给专家来做标记。
-
重复此过程,直到性能改进到不值得做标记为止。
其他策略包括标记那些会导致模型最大变化的实例或模型验证错误下降最大的实例,或不同模型不一致的实例(例如SVM或随机森林)。
在进入高斯混合模型之前,让我们看一下DBSCAN,这是另一种流行的聚类算法,它说明了一种基于局部密度估计的不同的方法。这种方法允许算法识别任意形状的聚类。
9.1.6 DBSCAN
该算法将集群定义为高密度的连续区域。下面是它的工作原理:
-
对于每个实例,该算法都会计算在距它一小段距离ε内有多少个实例。该区域称为实例的ε-邻域。
-
如果一个实例在其ε邻域中至少包含min sam_ples个实例(包括自身),则该实例被视为核心实例。换句话说,核心实例是位于密集区域中的实例。
-
核心实例附近的所有实例都属于同一集群。这个邻域可能包括其他核心实例。因此,一长串相邻的核心实例形成一个集群。
-
任何不是核心实例且邻居中没有实例的实例都被视为异常。
如果所有集群足够密集并且被低密度区域很好地分隔开,则该算法效果很好。Scikit-Learn中的DBSCAN类就像你期望的那样易于使用。让我们在第5章介绍的moons数据集上进行测试:
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
# 在labels_实例变量中可以得到所有实例的标签:
print(dbscan.labels_)
# 输出:array([ 0, 2, -1, -1, 1, 0, 0, 0, ..., 3, 2, 3, 3, 4, 2, 6, 3])
请注意,某些实例的集群索引等于-1,这意味着该算法将它们视为异常。core_sample_indices_变量可以得到核心实例的索引,components_变量可以得到核心实例本身:
print(len(dbscan.core_sample_indices_))
print(dbscan.core_sample_indices_)
print(dbscan.components_)
# 输出:
# 808
# array([ 0, 4, 5, 6, 7, 8, 10, 11, ..., 992, 993, 995, 997, 998, 999])
# array([[-0.02137124, 0.40618608],
# [-0.84192557, 0.53058695],
# ...
# [-0.94355873, 0.3278936 ],
# [ 0.79419406, 0.60777171]])
这种聚类在下图的左侧图中表示。如你所见,它识别出很多异常以及7个不同的集群。很令人失望!幸运的是,如果通过将eps增大到0.2来扩大每个实例的邻域,则可以得到右边的聚类,看起来很完美。让我们继续这个模型。
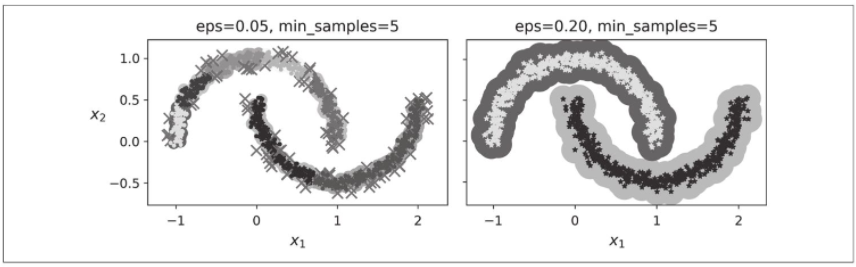
出乎意料的是,尽管DBSCAN类具有fit_predict()方法,但它没有predict()方法。换句话说,它无法预测新实例属于哪个集群。之所以做出这个决定是因为不同的分类算法可以更好地完成不同的任务,因此作者决定让用户选择使用哪种算法。而且实现起来并不难。例如,让我们训练一个KNeighborsClassifier:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])
现在,给出一些新实例,我们可以预测它们最有可能属于哪个集群,甚至可以估计每个集群的概率:
X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]])
print(knn.predict(X_new))
# 输出:array([1, 0, 1, 0])
print(knn.predict_proba(X_new))
# 输出:array([[0.18, 0.82], [1. , 0. ], [0.12, 0.88], [1. , 0. ]])
请注意,我们仅在核心实例上训练了分类器,但是我们也可以选择在所有实例或除异常之外的所有实例上训练分类器,这取决于你的任务。
决策边界如下图所示(十字表示X_new中的四个实例)。注意,由于训练集中没有异常,分类器总是选择一个集群,即使该集群很远也是如此。直接引入最大距离的概念,在这种情况下,距离两个集群均较远的两个实例被归类为异常。为此,请使用KNeighborsClassifier的kneighbors()方法。给定一组实例,它返回训练集中k个最近邻居的距离和索引(两个矩阵,每个有k列):
y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
y_pred[y_dist > 0.2] = -1
y_pred.ravel()
# 输出:array([-1, 0, 1, -1])
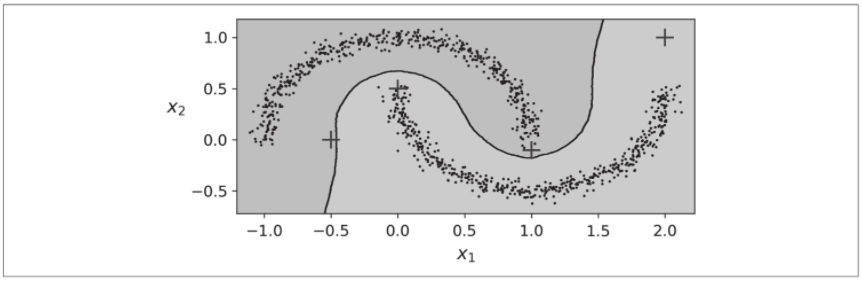
简而言之,DBSCAN是一种非常简单但功能强大的算法,能够识别任何数量的任何形状的集群。它对异常值具有鲁棒性,并且只有两个超参数(eps和min_samples)。但是,如果密度在整个集群中变化很大,则可能无法正确识别所有的集群。它的计算复杂度大约为 O ( m l o g m ) O(mlog^m) O(mlogm),使其在实例数量上非常接近线性,但是如果eps大,Scikit-Learn的实现可能需要多达 O ( m 2 ) O(m^2) O(m2)的内存。
你可能也需要尝试在scikit-learn-contrib项目中实现的Hierarchical DBSCAN(HDBSCAN)。
9.1.7 其他聚类算法
Scikit-Learn还实现了另外几种你应该了解的聚类算法。我们无法在此处详细介绍所有内容,以下是一个简要概述:
-
聚类
- 集群的层次结构是自下而上构建的。想想许多微小的气泡漂浮在水上并逐渐相互附着在一起,直到有一大群气泡。同样,在每次迭代中,聚集聚类连接最近的一对集群(从单个实例开始)。如果为每对合并的集群绘制一个带有分支的树,将得到一个二叉树集群,其中叶子是各个实例。这种方法可以很好地扩展到大量实例或集群。它可以识别各种形状的集群,生成灵活且信息丰富的集群树,而不强迫你选择特定的集群规模,并且可以与任何成对的距离一起使用。如果你有一个连通矩阵,它可以很好地扩展到大量实例,该矩阵是一个稀疏m×m矩阵,它表明哪些实例对是相邻的(例如,由
sklearn.neighbors.kneighbors_graph()返回)。没有连通矩阵,该算法就无法很好地扩展到大型数据集。
- 集群的层次结构是自下而上构建的。想想许多微小的气泡漂浮在水上并逐渐相互附着在一起,直到有一大群气泡。同样,在每次迭代中,聚集聚类连接最近的一对集群(从单个实例开始)。如果为每对合并的集群绘制一个带有分支的树,将得到一个二叉树集群,其中叶子是各个实例。这种方法可以很好地扩展到大量实例或集群。它可以识别各种形状的集群,生成灵活且信息丰富的集群树,而不强迫你选择特定的集群规模,并且可以与任何成对的距离一起使用。如果你有一个连通矩阵,它可以很好地扩展到大量实例,该矩阵是一个稀疏m×m矩阵,它表明哪些实例对是相邻的(例如,由
-
BIRCH
- BIRCH(使用层次结构的平衡迭代约简和聚类)算法是专门为非常大的数据集设计的,并且只要特征数量不太大(<20),它可以比批量处理的K-Means更快,结果相似。在训练期间,它构建了一个树结构,该树结构仅包含足以将每个新实例快速分配给集群的信息,而不必将所有实例存储在树中,这种方法使它在处理大型数据集时使用有限的内存。
-
均值漂移
- 此算法从开始在每个实例上居中放置一个圆圈。然后,对于每个圆,它会计算位于其中的所有实例的均值,然后移动圆,使其以均值为中心。接下来,迭代此均值移动步骤,直到所有圆都停止移动(直到每个圆都以其包含的实例的均值为中心)为止。均值漂移将圆向较高密度的方向移动,直到每个圆都找到了局部最大密度。最后,所有圆已经落在同一位置(或足够近)的实例都分配给同一集群。均值漂移具有与DBSCAN相同的特性,例如如何找到具有任何形状的任意数量的集群,它的超参数很少(仅一个圆的半径,称为带宽),并且依赖于局部密度估计。但是,与DBSCAN不同,均值漂移在有内部密度变化时,集群会分裂成小块。不幸的是,其计算复杂度为O(m2),因此不适用于大型数据集。
-
相似性传播
- 此算法使用投票机制,实例对相似的实例进行投票将其作为代表,一旦该算法收敛,每个代表及其投票者将组成一个集群。相似性传播可以检测任意数量的不同大小的集群。不幸的是,该算法的计算复杂度为O(m2),因此也不适用于大型数据集。
-
谱聚类
- 该算法采用实例之间的相似度矩阵,并由其创建低维嵌入(即降维),然后在该低维空间中使用另一种聚类算法(Scikit-Learn使用K-Means实现)。谱聚类可以识别复杂的集群结构,也可以用于分割图(例如,识别社交网络上的朋友集群)。它不能很好地扩展到大量实例,并且当集群的大小不同时,它的效果也不好。
聚类算法分类:
- 原型聚类
- 原型聚类亦称"基于原型的聚类"(prototype-based clustering)。此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。通常情形下、算法先对原型进行初始化、然后对原型进行迭代更新求解。采用不同的原型表示、不同的求解方式,将产生不同的算法。
- "原型"是指样本空间中具有代表性的点。
- 著名的原型聚类算法有:K均值算法、学习向量量化(Learning Vector Quantization,LVQ)、高斯混合聚类
- 密度聚类
- 密度聚类亦称"基于密度的聚类"(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
- 著名的密度聚类算法有:DBSCAN。
- 层次聚类
- 层次聚类(hierarchical custering)试图在不同层次对数据集进行划分、从而形成树形的聚类结构。数据集的划分可采用"自底向上"的聚合策略,也可采用"自顶向下"的分拆策略。
- 著名的层次聚类算法有:AGNES。
现在让我们深入研究高斯混合模型,该模型可用于密度估计、聚类和异常检测。
9.2 高斯混合模型
高斯混合模型(GMM)是一种概率模型,它假定实例是由多个参数未知的高斯分布的混合生成的。从单个高斯分布生成的所有实例都形成一个集群,通常看起来像一个椭圆。每个集群可以具有不同的椭圆形状、大小、密度和方向,如9.1.2图所示。当你观察到一个实例时,知道它是从一个高斯分布中生成的,但是不知道是哪个高斯分布,并且你也不知道这些分布的参数是什么。
有几种GMM变体。在GaussianMixture类中实现的最简单变体中,你必须事先知道高斯分布的数量k。假定数据集X是通过以下概率过程生成的:
-
对于每个实例,从k个集群中随机选择一个集群。选择第j个集群的概率由集群的权重 φ ( j ) φ^{(j)} φ(j)定义。第i个实例选择的集群的索引记为 z ( i ) z^{(i)} z(i)。
-
如果 z ( i ) = j z^{(i)}=j z(i)=j,表示第i个实例已分配给第j个集群,则从高斯分布中随机采样该实例的位置 x ( i ) x^{(i)} x(i),其中均值 μ ( j ) μ^{(j)} μ(j)和协方差矩阵 Σ ( j ) Σ^{(j)} Σ(j)。这记为 x ( i ) − N ( μ ( j ) , ∑ ( j ) ) x^{(i)-N(μ^{(j)},\sum^{(j))}} x(i)−N(μ(j),∑(j))。
该生成过程可以表示为图模型。下图表示随机变量之间的条件依存关系的结构。
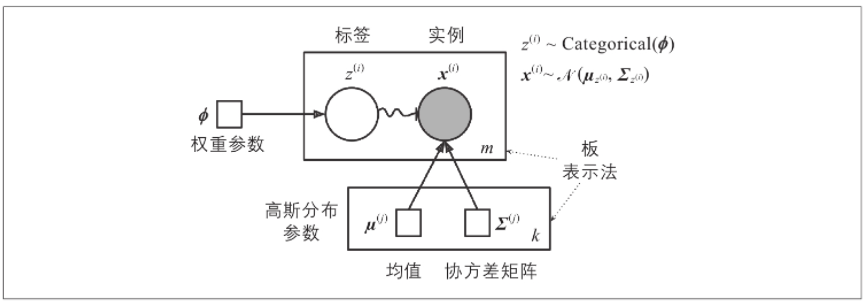
这是该图的解释:
- 圆圈代表随机变量。
- 正方形代表固定值(即模型的参数)。
- 大矩形称为平板。它们表示其内容重复了几次。
- 每个平板右下角的数字表示其内容重复了多少次。因此,有m个随机变量 z ( i ) z^{(i)} z(i)(从 z ( 1 ) z^{(1)} z(1)到 z ( m ) z^{(m)} z(m))和m个随机变量 x ( i ) x^{(i)} x(i),还有k个均值 μ ( j ) μ^{(j)} μ(j)和k个协方差矩阵 Σ ( j ) Σ^{(j)} Σ(j)。最后,只有一个权重向量φ(包含所有权重 φ ( 1 ) φ^{(1)} φ(1)到 φ ( k ) φ^{(k)} φ(k))。
- 每个变量 z ( i ) z^{(i)} z(i)从具有权重φ的分类分布中得出。每个变量 x ( i ) x^{(i)} x(i)从正态分布中得出,均值和协方差矩阵由其集群 z ( i ) z^{(i)} z(i)定义。
- 实线箭头表示条件依赖性。例如,每个随机变量 z ( i ) z^{(i)} z(i)的概率分布取决于权重向量φ。请注意,当箭头越过平板边界时,这意味着它适用于该平板的所有重复。例如,权重向量φ确定所有随机变量 x ( 1 ) x^{(1)} x(1)到 x ( m ) x^{(m)} x(m)的概率分布。
- 从 z ( i ) z^{(i)} z(i)到 x ( i ) x^{(i)} x(i)的弯曲箭头表示一个切换:根据 z ( i ) z^{(i)} z(i)的值,将从不同的高斯分布中采样实例 x ( i ) x^{(i)} x(i)。例如,如果 z ( i ) = j z^{(i)}=j z(i)=j,则 x ( i ) x^{(i)} x(i)~( μ ( j ) μ^{(j)} μ(j), Σ ( j ) Σ^{(j)} Σ(j))。
- 阴影节点表示该值是已知的。因此,在这种情况下,只有随机变量 x ( i ) x^{(i)} x(i)具有已知值,它们被称为已观察变量。未知的随机变量 z ( i ) z^{(i)} z(i)称为潜在变量。
那么,你可以用这种模型做什么?好吧,给定数据集X,你通常希望首先估计权重φ以及所有分布参数 μ ( 1 ) μ^{(1)} μ(1)至 μ ( k ) μ^{(k)} μ(k)和 Σ ( 1 ) Σ^{(1)} Σ(1)至 Σ ( k ) Σ^{(k)} Σ(k)。Scikit-Learn的GaussianMixture类使这个超级简单:
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=3, n_init=10)
gm.fit(X)
# 算法估计的参数:
print(gm.weights_)
# 输出:array([0.20965228, 0.4000662 , 0.39028152])
print(gm.means_)
# 输出:array([[ 3.39909717, 1.05933727], [-1.40763984, 1.42710194], [ 0.05135313, 0.07524095]])
print(gm.covariances_)
# 输出:
# array([[[ 1.14807234, -0.03270354],
# [-0.03270354, 0.95496237]],
# [[ 0.63478101, 0.72969804],
# [ 0.72969804, 1.1609872 ]],
# [[ 0.68809572, 0.79608475],
# [ 0.79608475, 1.21234145]]])
效果很好!实际上,用于生成数据的权重分别为0.2、0.4和0.4。同样,均值和协方差矩阵与该算法发现的非常接近。但这是怎么做到的?这个类依赖于期望最大化(Expectation-Maximization,EM)算法,该算法与K-Means算法有很多相似之处:
它随机初始化集群参数,然后重复两个步骤直到收敛,首先将实例分配给集群(这称为期望步骤),然后更新集群(这称为最大化步骤)。听起来很熟悉,对吧?在聚类的上下文中,你可以将EM看作是K-Means的推广,它不仅可以找到集群中心( μ ( 1 ) μ^{(1)} μ(1)到 μ ( k ) μ^{(k)} μ(k)),而且可以找到它们的大小、形状和方向( Σ ( 1 ) Σ^{(1)} Σ(1)到 Σ ( k ) Σ^{(k)} Σ(k))以及它们的相对权重( φ ( 1 ) φ^{(1)} φ(1)到 φ ( k ) φ^{(k)} φ(k))。
但是与K-Means不同,EM使用软集群分配而不是硬分配。对于每个实例,在期望步骤中,该算法(基于当前的集群参数)估计它属于每个集群的概率。然后,在最大化步骤中,使用数据集中的所有实例来更新每个聚类,并通过每个实例属于该集群的估计概率对其进行加权。这些概率称为实例集群的职责。在最大化步骤中,每个集群的更新主要受到其最负责的实例的影响。
不幸的是,就像K-Means一样,EM最终可能会收敛到较差的解,因此它需要运行几次,仅仅保留最优解。这就是我们将n_init设置为10的原因。请注意,默认情况下,n_init设置为1。
检查算法是否收敛以及迭代次数:
print(gm.converged_)
print(gm.n_iter_)
# 输出:
# True
# 3
现在,你已经估算了每个集群的位置、大小、形状、方向和相对权重,该模型可以容易地将每个实例分配给最可能的集群(硬聚类)或估算它属于特定集群的概率(软聚类)。只需对硬聚类使用predict()方法,对软聚类使用predict_proba()方法:
print(gm.predict(X))
# 输出:array([2, 2, 1, ..., 0, 0, 0])
print(gm.predict_proba(X))
# 输出:array([[2.32389467e-02, 6.77397850e-07, 9.76760376e-01],
# [1.64685609e-02, 6.75361303e-04, 9.82856078e-01],
# [2.01535333e-06, 9.99923053e-01, 7.49319577e-05],
# ...,
# [9.99999571e-01, 2.13946075e-26, 4.28788333e-07],
# [1.00000000e+00, 1.46454409e-41, 5.12459171e-16],
# [1.00000000e+00, 8.02006365e-41, 2.27626238e-15]])
高斯混合模型是一个生成模型,这意味着你可以从中采样新实例(请注意,它们按集群索引排序):
X_new, y_new = gm.sample(6)
print(X_new)
print(y_new)
# 输出:
# array([[ 2.95400315, 2.63680992],
# [-1.16654575, 1.62792705],
# [-1.39477712, -1.48511338],
# [ 0.27221525, 0.690366 ],
# [ 0.54095936, 0.48591934],
# [ 0.38064009, -0.56240465]])
# array([0, 1, 2, 2, 2, 2])
也可以在任何给定位置估计模型的密度。这可以使用score_samples()方法实现的:对于每个给定的实例,该方法估算该位置的概率密度函数(PDF)的对数。分数越高,密度越高:
print(gm.score_samples(X))
# 输出:array([-2.60782346, -3.57106041, -3.33003479, ..., -3.51352783, -4.39802535, -3.80743859])
如果你计算这些分数的指数,可以在给定实例的位置得到PDF的值。这些不是概率,而是概率密度,它们可以取任何正值(不只是0到1之间的值)。要估计实例落入特定区域的概率,你必须在该区域上积分PDF(如果你在可能的实例位置的整个空间中执行此操作,结果将为1)。
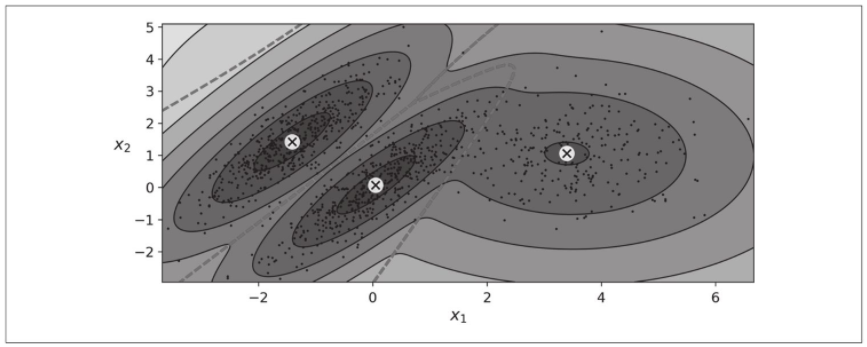
下图显示了该模型的集群均值、决策边界(虚线)和密度等值线。
很好!该算法显然找到了一个很好的解答。当然,我们通过使用一组二维高斯分布生成数据来简化其任务(不幸的是,现实生活中的数据并不总是那么高斯和低维的)。我们还为算法提供了正确数量的集群。当存在多个维度、多个集群或很少实例时,EM可能难以收敛到最佳解决方案。你可能需要通过限制算法必须学习的参数数量来降低任务的难度。一种方法是限制集群可能具有的形状和方向的范围,这可以通过对协方差矩阵施加约束来实现。为此,将covariance_type超参数设置为以下值之一:
- “spherical”:所有集群都必须是球形的,但它们可以具有不同的直径(即不同的方差)。
- “diag”:集群可以采用任何大小的任意椭圆形,但是椭圆形的轴必须平行于坐标轴(即协方差矩阵必须是对角线)。
- “tied”:所有集群必须具有相同的椭圆形状、大小和方向(即所有集群共享相同的协方差矩阵)。
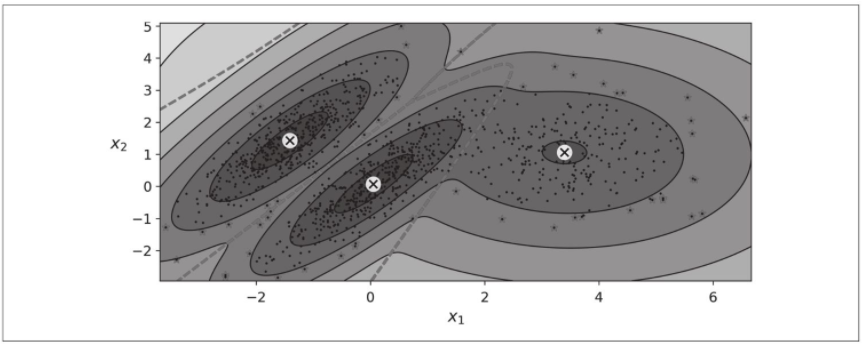
默认情况下,covariance_type等于"full",意味着每个集群可以采用任何形状、大小和方向(它具有自己无约束的协方差矩阵)。下图绘制了当covariance_type设置为"tied"或"spherical"时,通过EM算法找到的解。
训练高斯混合模型的计算复杂度取决于实例数m、维度n、集群数k和协方差矩阵的约束。如果covariance_type为"spherical"或"diag",假定数据具有聚类结构,则为O(kmn);如果cova riance_type为"tied"或"full",则为O(kmn2+kn3),因此不会扩展到具有大量特征。
高斯混合模型也可以用于异常检测。让我们看看它是如何做的。

9.2.1 使用高斯混合进行异常检测
异常检测(也称为离群值检测)是检测严重偏离标准的实例的任务。这些实例称为异常或离群值,而正常实例称为内值。异常检测在各种应用中很有用,例如欺诈检测,在制造业中检测有缺陷的产品,或在训练一个模型之前从数据集中删除异常值(这可以显著提高所得模型的性能)。
使用高斯混合模型进行异常检测非常简单:位于低密度区域的任何实例都可以被视为异常。你必须定义要使用的密度阈值。例如,在试图检测缺陷产品的制造业公司中,缺陷产品的比例通常是已知的,假设它等于4%。将密度阈值设置为导致4%的实例位于该阈值密度以下的区域中的值。如果你发现误报过多(即标记为有缺陷的好产品),则可以降低阈值。相反,如果假负过多(即系统未将其标记为次品的次品),则可以提高阈值。这是通常的精度/召回的权衡(见第3章)。以下是使用最低4%的密度作为阈值来识别异常值的方法(即大约4%的实例被标记为异常):
densities = gm.score_samples(X)
density_threshold = np.percentile(densities, 4)
anomalies = X[densities < density_threshold]
一个与之密切相关的任务是新颖性检测,它与异常检测不同之处在于,该算法被假定为在“干净”的数据集上训练的,不受异常值的污染,而异常检测并没有这个假设。实际上,离群值检测通常用于清理数据集。
高斯混合模型会尝试拟合所有数据,包括异常数据,因此,如果你有太多异常值,这将使模型的“正常性”产生偏差,某些离群值可能被错误地视为正常数据。如果发生这种情况,你可以尝试拟合模型一次,使用它来检测并去除最极端的离群值,然后再次将模型拟合到清理后的数据集上。另一种方法是使用鲁棒的协方差估计方法(请参阅EllipticEnvelope类)。
就像K-Means一样,GaussianMixture算法要求你指定集群数目。那么,我们如何找到它呢?
9.2.2 选择聚类数
使用K-Means,你可以使用惯性或轮廓分数来选择适当的集群数。但是对于高斯混合,则无法使用这些度量标准,因为当集群不是球形或具有不同大小时,它们不可靠。相反,你可以尝试找到最小化理论信息量准则的模型,例如下面公式中定义的贝叶斯信息准则(BIC)或赤池信息准则(AIC)。

BIC和AIC都对具有更多要学习的参数(例如,更多的集群)的模型进行惩罚,并奖励非常拟合数据的模型。它们常常最终会选择相同的模型。当它们不同时,BIC选择的模型往往比AIC选择的模型更简单(参数更少),但往往不太拟合数据(对于较大的数据集尤其如此)。
似然函数
术语“概率”和“似然”在英语中经常互换使用,但是它们在统计学中的含义却大不相同。给定具有一些参数θ的统计模型,用“概率”一词描述未来的结果x的合理性(知道参数值θ),而用“似然”一词表示描述在知道结果x之后,一组特定的参数值θ的合理性。
考虑两个以-4和+1为中心的高斯分布一维混合模型。为简单起见,此玩具模型具有一个控制两个分布的标准差的单个参数θ。下图的左上方轮廓图显示了以x和θ为函数的模型f(x;θ)。要估计未来结果x的概率分布,需要设置模型参数θ。例如,如果将θ设置为1.3(水平线),则会获得左下图中所示的概率密度函数f(x;θ=1.3)。假设你要估算x落在-2和+2之间的概率,则必须在此范围内(即阴影区域的表面)计算PDF的积分。但是,如果你不知道θ,而是观察到单个实例x=2.5(左上图中的垂直线),该怎么办?在这种情况下,你得到似然函数…(θ|x=2.5)=f(x=2.5;θ),如右上图所示。

简而言之,PDF是x的函数(固定了θ),而似然函数是θ的函数(固定了x)。重要的是要理解似然函数不是概率分布:如果你对x的所有可能值积分其概率分布,则总为1;但是,如果对所有可能的θ值积分其似然函数,则结果可以是任何正值。
给定数据集X,一项常见的任务是尝试估计模型参数最有可能的值。为此,你必须找到给定X的最大化似然函数的值。在此示例中,如果观察到单个实例x=2.5,则最大似然估计(MLE)为 θ ′ = 1.5 θ' = 1.5 θ′=1.5 。如果存在关于θ的先验概率分布g,则可以通过最大化L(θ|x)g(θ)来考虑,而不仅仅是最大化L(θ|x)。这称为最大后验(MAP)估计。由于MAP会约束参数值,因此你可以将其视为MLE的正则化版本。
注意,最大化似然函数等效于最大化其对数(在图9-20的右下方图中表示)。实际上,对数是严格增加的函数,因此,如果θ使对数可能性最大化,那么对数也就使似然最大化。事实证明,通常使对数可能性最大化更容易。例如,如果观察到几个独立的实例x(1)到x(m),则你需要找到使单个似然函数的乘积最大化的θ值。但是,由于对数可以将乘积转换为和,所以最大化对数似然函数的和(而不是乘积)是等效的,而且要简单得多:log(ab)=log(a)+log(b)。
一旦你估算出 ,即似然函数最大化的θ值,便可以计算 L ′ = L ( θ ′ , x ) L' = L(θ',x) L′=L(θ′,x),这是用于计算AIC和BIC的值,你可以将其视为模型拟合数据的程度的度量。
要计算BIC和AIC,请调用bic()和aic()方法:
print(gm.bic(X))
# 输出:8189.74345832983
print(gm.aic(X))
# 输出:8102.518178214792
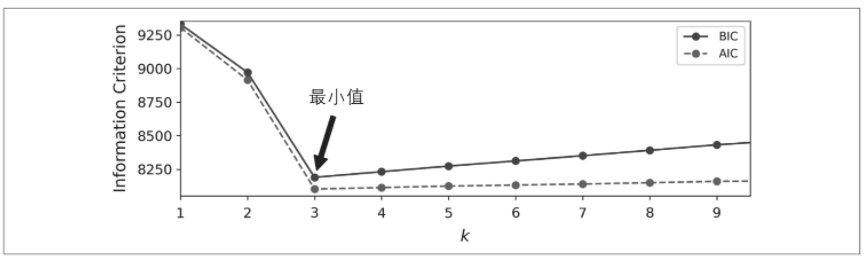
下图显示了不同数目的集群k的BIC。如你所见,当k=3时,BIC和AIC都最低,因此它很可能是最佳选择。请注意,我们也可以为超参数covariance_type搜索最佳值。例如,如果它是"spherical"而不是"full",则该模型要学习的参数要少得多,但它不是很拟合数据。
9.2.3 贝叶斯高斯混合模型
你可以使用BayesianGaussianMixture类,而不是手动搜索集群的最佳数目,该类能够为不必要的集群赋予等于(或接近于)零的权重。将集群数目n_components设置为一个你有充分理由相信的值,该值大于最佳集群的数量(这假定你对当前问题有一些了解),算法会自动消除不必要的集群。例如,让我们将集群数设置为10,然后看看会发生什么:
from sklearn.mixture import BayesianGaussianMixture
bgm = BayesianGaussianMixture(n_components=10, n_init=10)
bgm.fit(X)
np.round(bgm.weights_, 2)
# 输出:array([0.4, 0.21, 0.4, 0., 0., 0., 0., 0., 0., 0.])
完美:算法自动检测到只需要三个集群,并且所得集群几乎与上面的相同。
在此模型中,集群参数(包括权重、均值和协方差矩阵)不再被视为固定的模型参数,而是被视为潜在的随机变量,像集群分配(请参见下图)。因此,z现在同时包括集群参数和集群分配。
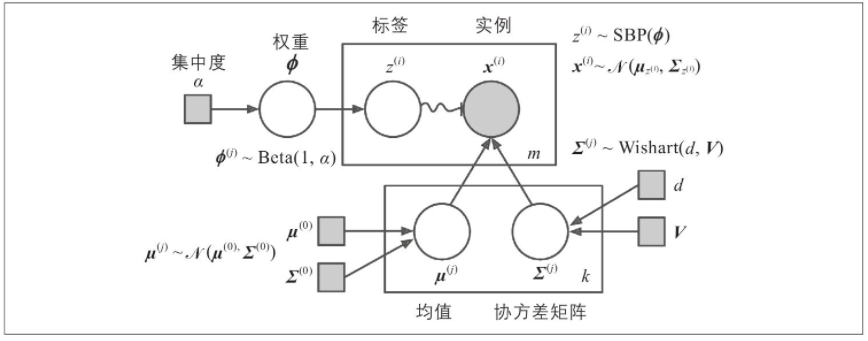
Beta分布通常用于对值在固定范围内的随机变量进行建模。在这种情况下,范围是0到1。最好通过一个示例来说明“突破性过程”(SBP):假设Φ=[0.3,0.6,0.5,…],那么分配30%的实例到集群0,剩余实例的60%分配给集群1,然后将剩余实例的50%分配给集群2,以此类推。在这种数据集中,新实例相比小集群更可能加入大集群(例如人们更可能迁移到较大的城市)。如果α集中度高,则Φ值很可能接近0,并且SBP会生成许多集群。相反,如果集中度低,则Φ值很可能接近1,并且集群很少。最后,使用Wishart分布对协方差矩阵进行采样:参数d和V控制集群形状的分布。
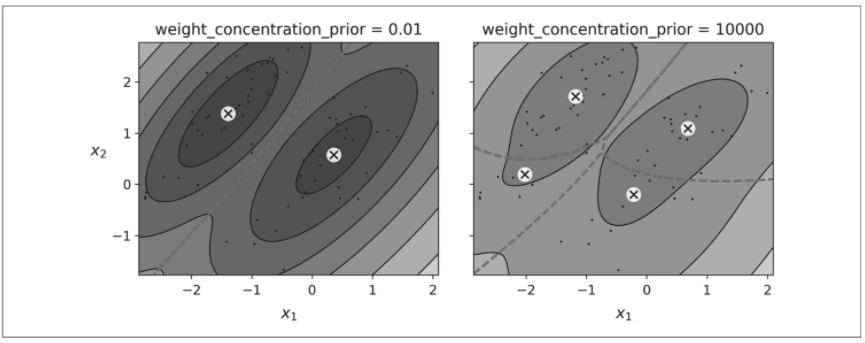
可以在概率分布p(z)中编码有关潜在变量z的先验知识称为先验。例如,我们可能先验地认为聚类可能很少(低集中度),或者相反,它们可能很多(高集中度)。可以使用超参数weight_concentration_prior来调整有关集群数的先验知识。将其设置为0.01或10 000可得到非常不同的聚类(见下图)。但是,我们拥有的数据越多,先验就越不重要。实际上,要绘制具有如此大差异的图表,你必须使用非常强的先验知识和少量数据。
贝叶斯定理(见下面公式)告诉我们在观察到一些数据X之后如何更新潜在变量的概率分布。它计算后验分布p(z|X),这是给定X的z的条件概率。

不幸的是,在高斯混合模型(以及许多其他问题)中,分母p(X)很难处理,因为它需要对z的所有可能值进行积分(见下面公式),这需要考虑所有可能的集群参数和集群分配的组合。
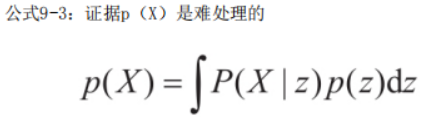
这种难处理性是贝叶斯统计中的核心问题之一,有几种解决方法。其中之一是变分推理,它选择具有变分参数λ的分布族q(z;λ),然后优化这些参数以使q(z)成为p(z|X)的良好近似值。这是通过找到最小化从q(z)到p(z|X)的KL散度的λ值来实现的,记为DKL(q||p)。KL散度方程如公式9-4所示,可以将其重写为证据的对数(log p(X))减去证据的下界(ELBO)。由于证据的对数不依赖于q,它是一个常数项,因此,使KL散度最小化只需要使ELBO最大化。

在实践中,存在多种使ELBO最大化的不同技术。在均值场变分推理中,有必要非常仔细地选择分布族q(z;λ)和先验p(z),确保ELBO的方程能简化为可计算的形式。不幸的是,没有一般的方法可以做到这一点。选择正确的分布族和正确的先验取决于任务并需要一些数学技能。例如,文档中介绍了Scikit-Learn的BayesianGaussianMixture类中使用的分布和下界等式。从这些方程式中可以得出集群参数和赋值变量的更新方程式。然后,这些方程式的使用非常类似于ExpectationMaximization算法。实际上,BayesianGaussianMixture类的计算复杂度类似于GaussianMixture类的计算复杂度(但通常要慢得多)。一种最大化ELBO的更简单方法称为黑盒随机变分推理(BBSVI):在每次迭代中,从q中抽取一些样本,然后使用它们来估计ELBO关于变分参数λ的梯度,然后将其用于梯度上升步骤。这种方法使得可以将贝叶斯推理用于任何类型的模型(假设它是可微分的),甚至是深度神经网络。将贝叶斯推理与深度神经网络结合使用称为贝叶斯深度学习。
如果你想更深入地了解贝叶斯统计,请查阅Andrew Gelman等人的Bayesian Data Analysis一书。
高斯混合模型在具有椭圆形状的集群上效果很好,但是如果你尝试拟合具有不同形状的数据集,可能会感到意外。例如,让我们看看如果使用贝叶斯高斯混合模型对moons数据集进行聚类会发生什么情况(见下图)。
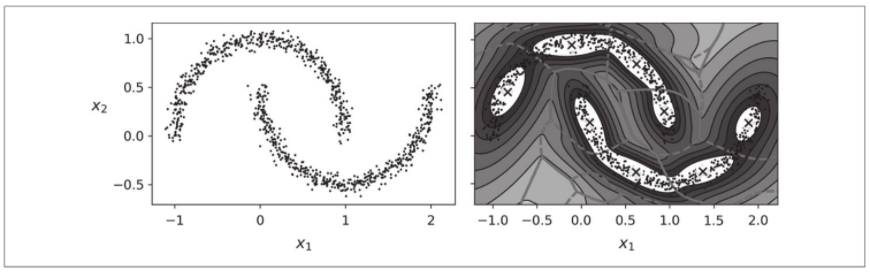
很糟糕!该算法拼命搜索椭圆形,因此找到了8个不同的集群(而不是两个)。密度估计还算不错,因此该模型可能可以用于异常检测,但未能识别出两个卫星。现在让我们看一些能够处理任意形状集群的聚类算法。
9.2.4 其他用于异常检测和新颖性检测的算法
Scikit-Learn实现了专用于异常检测或新颖性检测的其他算法:
- PCA(以及其他使用inverse_transform()方法的降维技术):
- 如果你将正常实例的重建误差与异常的重建误差进行比较,则后者通常会大得多。这是一种简单且通常非常有效的异常检测方法(有关此方法的应用,请参阅本章的练习)。
- Fast-MCD(最小协方差决定):
- 由EllipticEnvelope类实现,该算法对于异常值检测(特别是清理数据集)很有用。假定正常实例(内部值)是根据一个单个高斯分布(而不是混合)生成的。它还假定数据集被不是由该高斯分布生成的异常值所污染。当算法估算高斯分布的参数(即围绕椭圆的椭圆形包络线的形状)时,请小心忽略最可能是异常值的实例。
- 该技术可以更好地估计椭圆形包络,从而使算法在识别异常值方面更好。
- 隔离森林:
- 这是一种用于异常值检测的有效算法,尤其是在高维数据集中。该算法构建一个随机森林,其中每个决策树都是随机生长的:在每个节点上,它随机选择一个特征,然后选择一个随机阈值(介于最小值和最大值之间)来将数据集分成两部分。数据集以这种方式逐渐切成分支,直到所有实例最终都与其他实例隔离开来。异常通常与其他实例相距甚远,因此平均而言(在所有决策树中),与正常实例相比,它们倾向于用更少的步骤被隔离。
- 局部离群因子(Local Outlier Factor,LOF):
- 此算法也可用于离群值检测。它将给定实例周围的实例密度与其相邻实例周围的密度进行比较。异常值通常比k个最近的邻居更孤立。
- 单类SVM:
- 此算法更适合新颖性检测。回想一下,一个内核化的SVM分类器通过首先(隐式地)将所有的实例映射到一个高维空间,然后在这个高维空间中使用线性SVM分类器来分离这两个类(见第5章)。由于我们只有单类实例,因此单类SVM算法会尝试将高维空间中的实例与原点分开。在原始空间中,这将对应于找到一个包含所有实例的小区域。如果新实例不在该区域内,则为异常。有一些超参数需要调整:用于内核化SVM的超参数,还有一个余量超参数,它对应于一个新实例实际上是正常的而被误认为是新颖实例的可能性。它非常有用,特别是对于高维数据集,但是像所有SVM一样,它不能扩展到大型数据集。
9.3 练习题
问题
-
如何定义聚类?你能列举几种聚类算法吗?
-
聚类算法的主要应用有哪些?
-
描述两种使用K-Means时选择正确数目的集群的技术。
-
什么是标签传播?为什么要实施它,如何实现?
-
你能否说出两种可以扩展到大型数据集的聚类算法?两个寻找高密度区域的算法?6.你能想到一个主动学习有用的示例吗?你将如何实施它?
-
异常检测和新颖性检测有什么区别?
-
什么是高斯混合模型?你可以将其用于哪些任务?
-
使用高斯混合模型时,你能否列举两种技术来找到正确数量的集群?
-
经典的Olivetti人脸数据集包含400张灰度的64×64像素的人脸图像。每个图像被展平为大小为4096的一维向量。40个不同的人被拍照(每个10次),通常的任务是训练一个模型来预测每个图片中代表哪个人。使用sklearn.datasets.fetch_olivetti_faces()函数来加载数据集,然后将其拆分为训练集、验证集和测试集(请注意,数据集已缩放到0到1之间)。由于数据集非常小,你可能希望使用分层抽样来确保每组中每个人的图像数量相同。接下来,使用K-Means对图像进行聚类,确保你拥有正确的集群数(使用本章中讨论的一种技术)。可视化集群:你在每个集群中看到了相似面孔吗?
-
继续使用Olivetti人脸数据集,训练分类器来预测每张图片代表哪个人,并在验证集上对其进行评估。接下来,将K-Means用作降维工具,然后在简化集上训练分类器。搜索使分类器获得最佳性能的集群数量:可以达到什么性能?如果将简化集中的特征附加到原始特征上(再次搜索最佳数目的集群)怎么办?
-
在Olivetti人脸数据集上训练高斯混合模型。为了加快算法的速度,你可能应该降低数据集的维度(例如,使用PCA,保留99%的方差)。使用该模型来生成一些新面孔(使用sample()方法),并对其进行可视化(如果使用PCA,需要使用其inverse_transform()方法)。尝试修改一些图像(例如,旋转、翻转、变暗),然后查看模型是否可以检测到异常(即比较score_samples()方法对正常图像和异常图像的输出)。
-
一些降维技术也可以用于异常检测。例如,使用Olivetti人脸数据集并使用PCA对其进行降维,保留99%的方差。然后计算每个图像的重建误差。接下来,使用一些你在练习12中构建的一些修改后的图像,查看其重建误差:注意重建误差的大小。如果画出重建图像,你会看到原因:它尝试重建一张正常的脸。
答案
-
在机器学习中,聚类是将相似的实例组合在一起的无监督任务。相似性的概念取决于你手头的任务:例如,在某些情况下,两个附近的实例将被认为是相似的,而在另一些情况下,只要它们属于同一密度组,则相似的实例可能相距甚远。流行的聚类算法包括K-Means、DBSCAN、聚集聚类、BIRCH、均值平移、亲和度传播和光谱聚类。
-
聚类算法的主要应用包括数据分析、客户分组、推荐系统、搜索引擎、图像分割、半监督学习、降维、异常检测和新颖性检测。
-
肘部法则是一种在使用K-Means时选择集群数的简单技术:将惯量(从每个实例到其最近的中心点的均方距离)作为集群数量的函数绘制出来,并找到曲线中惯量停止快速下降的点(“肘”)。另一种方法是将轮廓分数作为集群数量的函数绘制出来。通常最佳集群数是在一个高峰的附近。轮廓分数是所有实例上的平均轮廓系数。对于位于集群内且与其他集群相距甚远的实例,该系数为+1;对于与另一集群非常接近的实例,该系数为-1。你也可以绘制轮廓图并进行更细致的分析。
-
标记数据集既昂贵又费时。因此,通常有很多未标记的实例,很少有标记的实例。标签传播是一种技术,该技术包括将部分(或全部)标签从已标记的实例复制到相似的未标记实例。这可以大大增加标记实例的数量,从而使监督算法达到更好的性能(这是半监督学习的一种形式)。一种方法是在所有实例上使用诸如K-Means之类的聚类算法,然后为每个集群找到最常见的标签或最具代表性的实例(即最接近中心点的实例)的标签并将其传播到同一集群中未标记的实例。
-
K均值和BIRCH可以很好地扩展到大数据集。DBSCAN和Mean-Shift寻找高密度区域。
-
当你有大量未标记的实例而做标记非常昂贵时,主动学习就非常有用。在这种情况下(非常常见),与其随机选择实例来做标记,不如进行主动学习,这通常是更可取的一种方法,人类专家可以与算法进行交互,并在算法有需要时为特定实例提供标签。常见的方法是不确定性采样(见9.1.5节的“主动学习”)。
-
许多人把术语异常检测和新颖性检测互换,但是它们并不完全相同。在异常检测中,算法对可能包含异常值的数据集进行训练,目标通常是识别这些异常值(在训练集中)以及新实例中的异常值。在新颖性检测中,该算法在假定为“干净”的数据集上进行训练,其目的是严格在新实例中检测新颖性。某些算法最适合异常检测(例如隔离森林),而其他算法更适合新颖性检测(例如单类SVM)。
-
高斯混合模型(GMM)是一种概率模型,它假定实例是由参数未知的多个高斯分布的混合生成的。换句话说,我们假设数据可以分为有限数量的集群,每个集群具有椭圆的形状(但是集群可能具有不同的椭圆形状、大小、方向和密度),而我们不知道每个实例属于哪个簇。该模型可用于密度估计、聚类和异常检测。
-
使用高斯混合模型时,找到正确数量的集群的一种方法是将贝叶斯信息准则(BIC)或赤池信息准则(AIC)作为集群数量的函数绘制出来,然后选择使BIC或AIC最小化的集群数量。另一种技术是使用贝叶斯高斯混合模型,该模型可以自动选择集群数。
有关练习10~13的解答,请参见https://github.com/ageron/handson-ml2上提供的Jupyternotebook。
补充:半监督学习
半监督学习的研究一般认为始于 【Shahshahami and Landgrebe,1994】,该领域在二十世纪末、二十一世纪初随着现实应用中利用未标记数据的巨大需求涌现而蓬勃发展。国际机器学习大会(ICML))从 2008年开始评选"十年最佳论文",在短短6年中,半监督学习四大范型(paradigm)中基于分歧的方法、半监督 SVM、图半监督学习的代表性工作先后于2008年【Blum and Mitchell,1998】、2009年【Joachims,1999】、2013年【Zhu et al,2003】获奖。
生成式半监督学习方法出现最早 【Shahshahani and Landgrebe,1994】。由于需有充分可靠的领域知识才能确保模型假设不至于太坏,因此该范型后来主要是在具体的应用领域加以研究。
半监督 SVM的目标函数非凸,有不少工作致力于减轻非凸性造成的不利影响,例如使用连续统(continuation)方法,从优化一个简单的凸目标函数开始、逐步变形为非凸的 S3VM 目标函数 【Chapelle et al.,2006a】;使用确定性退火(deterministic annealing)过程,将非凸问题转化为一系列凸优化间题,然后由易到难地顺序求解【Sindhwani et al.,2006】;利用 CCCP 方法优化非凸函数【Collobert et al.,2006】等。
最早的图半监督学习方法【Blum and Chawla,2001】直接基于聚类假设,将学习目标看作找出图的最小割(mincut)。对此类方法来说,图的质量极为重要,13.4节的高斯距离图以及k近邻图、e近邻图都较为常用、此外已有一些关于构图的研究【Wang and Zhang,2006; Jebara et al.,2009】,基于图核(graph kernel)的方法也与此有密切联系【Chapelle et al,2008】。
基于分歧的方法起源于协同训练,最初设计是仅选取一个学习器用于预测【Blum and Mitchell,1998】。三体训练(tri-training)使用三个学习器,通过"少数服从多数"来产生伪标记样本,并将学习器进行集成【Zhou and Li,2005b】。后续研究进一步显示出将学习器集成起来更有助于性能提升,并出现了使用更多学习器的方法。更为重要的是,这将集成学习与半监督学习这两个长期独立发展的领域联系起来【Zhou,2009】。此外,这些方法能容易地用于多视图数据,并可自然地与主动学习进行结合 【周志华,2013】。
【Belkin et al.,2006】在半监督学习中提出了流形正则化(manifold regularization)框架,直接基于局部光滑性假设对定义在有标记样本上的损失函数进行正则化,使学得的预测函数具有局部光滑性。
半监督学习在利用未标记样本后并非必然提升泛化性能,在有些情形下甚至会导致性能下降.对生成式方法,其成因被认为是模型假设不准确 【Cozman and Cohen,2002】,因此需依赖充分可靠的领域知识来设计模型。对半监督SVM,其成因被认为是训练数据中存在多个"低密度划分",而学习算法有可能做出不利的选择;S4VM【i and Zhou.2015】通过优化最坏情形性能来综合利用多个低密度划分,提升了此类技术的安全性。更一般的"安全"(safe)半监督学习仍是一个未决问题。