一、SegNet
分割是计算机视觉的主要任务之一。 对于图像的每个像素,您必须指定类(包括背景)。 语义分割只告诉像素类,实例分割将类划分为不同的实例。
分割模型有不同的神经架构,但它们几乎所有架构都具有相同的结构。 第一部分是从输入图像中提取特征的编码器,第二部分是解码器,它将这些特征转换为具有相同高度和宽度以及一些通道数的图像,可能等于类别的数量。
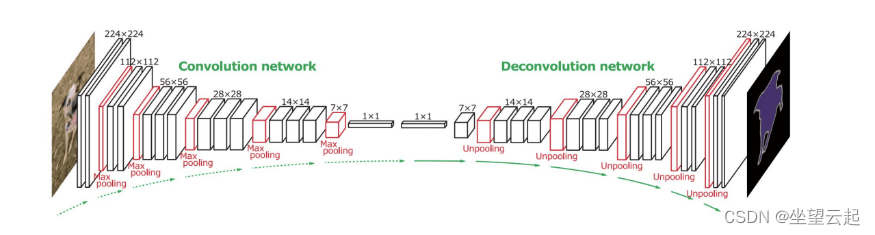
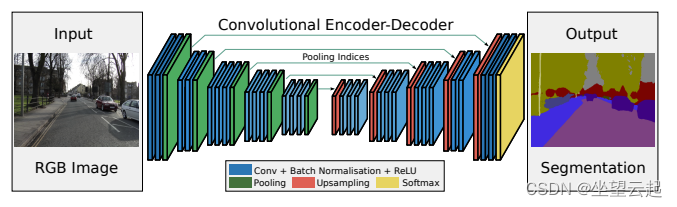
最简单的编码器-解码器架构称为 SegNet。 它在编码器中使用带有卷积和池化的标准 CNN,在解码器中使用包括卷积和上采样的反卷积 CNN。 它还依靠批量归一化来成功训练多层网络。
论文地址
https://arxiv.org/pdf/1511.00561.pdf![]() https://arxiv.org/pdf/1511.00561.pdf
https://arxiv.org/pdf/1511.00561.pdf
二、示例数据集
黑色素瘤发病率的增加最近促进了用于皮肤镜图像分类的计算机辅助诊断系统的发展。 PH² 数据集是为研究和基准测试目的而开发的,以便于对皮肤镜图像的分割和分类算法进行比较研究。 PH² 是一个皮肤镜图像数据库,购自葡萄牙马托西纽什佩德罗伊斯帕诺医院皮肤科。
https://www.fc.up.pt/addi/ph2%20database.html![]() https://www.fc.up.pt/addi/ph2%20database.html
https://www.fc.up.pt/addi/ph2%20database.html
百度网盘下载
链接:https://pan.baidu.com/s/1I8Zwwn8XZPkzRwchKBgWZg?pwd=uyi9
提取码:uyi9三、Pytorch代码参考
1、导入包
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch import nn
from torch import optim
from tqdm import tqdm
import numpy as np
import torch.nn.functional as F
from skimage.io import imread
from skimage.transform import resize
import os
torch.manual_seed(42)
np.random.seed(42)
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
train_size = 0.9
lr = 1e-3
weight_decay = 1e-6
batch_size = 32
epochs = 302、下载处理数据
下面的代码从原始位置下载数据集并解压缩。 您需要安装 unrar 实用程序才能使此代码正常工作,您可以在 Linux 上使用 sudo apt-get install unrar 安装它,或者在此处下载适用于 Windows 的命令行版本。
#!apt-get install rar
!wget https://www.dropbox.com/s/k88qukc20ljnbuo/PH2Dataset.rar
!unrar x -Y PH2Dataset.rar现在我们将定义加载数据集的代码。 我们将所有图像转换为 256x256 大小,并将数据集拆分为训练和测试部分。 此函数返回训练和测试数据集,每个数据集都包含原始图像和概述痣的蒙版。
def load_dataset(train_part, root='PH2Dataset'):
images = []
masks = []
for root, dirs, files in os.walk(os.path.join(root, 'PH2 Dataset images')):
if root.endswith('_Dermoscopic_Image'):
images.append(imread(os.path.join(root, files[0])))
if root.endswith('_lesion'):
masks.append(imread(os.path.join(root, files[0])))
size = (256, 256)
images = torch.permute(torch.FloatTensor(np.array([resize(image, size, mode='constant', anti_aliasing=True,) for image in images])), (0, 3, 1, 2))
masks = torch.FloatTensor(np.array([resize(mask, size, mode='constant', anti_aliasing=False) > 0.5 for mask in masks])).unsqueeze(1)
indices = np.random.permutation(range(len(images)))
train_part = int(train_part * len(images))
train_ind = indices[:train_part]
test_ind = indices[train_part:]
train_dataset = (images[train_ind, :, :, :], masks[train_ind, :, :, :])
test_dataset = (images[test_ind, :, :, :], masks[test_ind, :, :, :])
return train_dataset, test_dataset
train_dataset, test_dataset = load_dataset(train_size)现在让我们绘制数据集中的一些图像,看看它们的样子:
def plotn(n, data, only_mask=False):
images, masks = data[0], data[1]
fig, ax = plt.subplots(1, n)
fig1, ax1 = plt.subplots(1, n)
for i, (img, mask) in enumerate(zip(images, masks)):
if i == n:
break
if not only_mask:
ax[i].imshow(torch.permute(img, (1, 2, 0)))
else:
ax[i].imshow(img[0])
ax1[i].imshow(mask[0])
ax[i].axis('off')
ax1[i].axis('off')
plt.show()
plotn(5, train_dataset)
我们还需要数据加载器将数据输入我们的神经网络。
train_dataloader = torch.utils.data.DataLoader(list(zip(train_dataset[0], train_dataset[1])), batch_size=batch_size, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(list(zip(test_dataset[0], test_dataset[1])), batch_size=1, shuffle=False)
dataloaders = (train_dataloader, test_dataloader)3、定义和训练
class SegNet(nn.Module):
def __init__(self):
super().__init__()
self.enc_conv0 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=(3,3), padding=1)
self.act0 = nn.ReLU()
self.bn0 = nn.BatchNorm2d(16)
self.pool0 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv1 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3,3), padding=1)
self.act1 = nn.ReLU()
self.bn1 = nn.BatchNorm2d(32)
self.pool1 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3,3), padding=1)
self.act2 = nn.ReLU()
self.bn2 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(kernel_size=(2,2))
self.enc_conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), padding=1)
self.act3 = nn.ReLU()
self.bn3 = nn.BatchNorm2d(128)
self.pool3 = nn.MaxPool2d(kernel_size=(2,2))
self.bottleneck_conv = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), padding=1)
self.upsample0 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv0 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=(3,3), padding=1)
self.dec_act0 = nn.ReLU()
self.dec_bn0 = nn.BatchNorm2d(128)
self.upsample1 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=(3,3), padding=1)
self.dec_act1 = nn.ReLU()
self.dec_bn1 = nn.BatchNorm2d(64)
self.upsample2 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=(3,3), padding=1)
self.dec_act2 = nn.ReLU()
self.dec_bn2 = nn.BatchNorm2d(32)
self.upsample3 = nn.UpsamplingBilinear2d(scale_factor=2)
self.dec_conv3 = nn.Conv2d(in_channels=32, out_channels=1, kernel_size=(1,1))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
e0 = self.pool0(self.bn0(self.act0(self.enc_conv0(x))))
e1 = self.pool1(self.bn1(self.act1(self.enc_conv1(e0))))
e2 = self.pool2(self.bn2(self.act2(self.enc_conv2(e1))))
e3 = self.pool3(self.bn3(self.act3(self.enc_conv3(e2))))
b = self.bottleneck_conv(e3)
d0 = self.dec_bn0(self.dec_act0(self.dec_conv0(self.upsample0(b))))
d1 = self.dec_bn1(self.dec_act1(self.dec_conv1(self.upsample1(d0))))
d2 = self.dec_bn2(self.dec_act2(self.dec_conv2(self.upsample2(d1))))
d3 = self.sigmoid(self.dec_conv3(self.upsample3(d2)))
return d3应该特别提到用于分割的损失函数。 在经典的自动编码器中,需要测量两个图像之间的相似性,可以使用均方误差来做到这一点。 在分割中,目标掩码图像中的每个像素代表类号(沿第三维单热编码),因此我们需要使用特定于分类的损失函数 - 交叉熵损失,对所有像素进行平均。 如果掩码是二元的将使用二元交叉熵损失 (BCE)。
model = SegNet().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = nn.BCEWithLogitsLoss()训练循环:
def train(dataloaders, model, loss_fn, optimizer, epochs, device):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
for epoch in tqdm_iter:
model.train()
train_loss = 0.0
test_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
loss = loss_fn(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs)
loss = loss_fn(preds, labels)
test_loss += loss.item()
train_loss /= len(train_dataloader)
test_loss /= len(test_dataloader)
tqdm_dct = {'train loss:': train_loss, 'test loss:': test_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()train(dataloaders, model, loss_fn, optimizer, epochs, device)4、评估模型
model.eval()
predictions = []
image_mask = []
plots = 5
images, masks = test_dataset[0], test_dataset[1]
for i, (img, mask) in enumerate(zip(images, masks)):
if i == plots:
break
img = img.to(device).unsqueeze(0)
predictions.append((model(img).detach().cpu()[0] > 0.5).float())
image_mask.append(mask)
plotn(plots, (predictions, image_mask), only_mask=True)四、Tensorflow代码参考
1、导入包
import tensorflow as tf
import tensorflow.keras.layers as keras
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
from skimage.io import imread
from skimage.transform import resize
import os
import tensorflow.keras.optimizers as optimizers
import tensorflow.keras.losses as losses
from tensorflow.keras.preprocessing.image import ImageDataGenerator
tf.random.set_seed(42)
np.random.seed(42)
train_size = 0.8
lr = 3e-4
weight_decay = 8e-9
batch_size = 64
epochs = 1002、处理数据集
!apt-get install rar
!wget https://www.dropbox.com/s/k88qukc20ljnbuo/PH2Dataset.rar
!unrar x -Y PH2Dataset.rardef load_dataset(train_part, root='PH2Dataset'):
images = []
masks = []
for root, dirs, files in os.walk(os.path.join(root, 'PH2 Dataset images')):
if root.endswith('_Dermoscopic_Image'):
images.append(imread(os.path.join(root, files[0])))
if root.endswith('_lesion'):
masks.append(imread(os.path.join(root, files[0])))
size = (256, 256)
images = np.array([resize(image, size, mode='constant', anti_aliasing=True,) for image in images])
masks = np.expand_dims(np.array([resize(mask, size, mode='constant', anti_aliasing=False) > 0.5 for mask in masks]), axis=3)
indices = np.random.permutation(range(len(images)))
train_part = int(train_part * len(images))
train_ind = indices[:train_part]
test_ind = indices[train_part:]
X_train = tf.cast(images[train_ind, :, :, :], tf.float32)
y_train = tf.cast(masks[train_ind, :, :, :], tf.float32)
X_test = tf.cast(images[test_ind, :, :, :], tf.float32)
y_test = tf.cast(masks[test_ind, :, :, :], tf.float32)
return (X_train, y_train), (X_test, y_test)(X_train, y_train), (X_test, y_test) = load_dataset(train_size)def plotn(n, data):
images, masks = data[0], data[1]
fig, ax = plt.subplots(1, n)
fig1, ax1 = plt.subplots(1, n)
for i, (img, mask) in enumerate(zip(images, masks)):
if i == n:
break
ax[i].imshow(img)
ax1[i].imshow(mask[:, :, 0])
plt.show()3、定义模型和训练
class SegNet(tf.keras.Model):
def __init__(self):
super().__init__()
self.enc_conv0 = keras.Conv2D(16, kernel_size=3, padding='same')
self.bn0 = keras.BatchNormalization()
self.relu0 = keras.Activation('relu')
self.pool0 = keras.MaxPool2D()
self.enc_conv1 = keras.Conv2D(32, kernel_size=3, padding='same')
self.relu1 = keras.Activation('relu')
self.bn1 = keras.BatchNormalization()
self.pool1 = keras.MaxPool2D()
self.enc_conv2 = keras.Conv2D(64, kernel_size=3, padding='same')
self.relu2 = keras.Activation('relu')
self.bn2 = keras.BatchNormalization()
self.pool2 = keras.MaxPool2D()
self.enc_conv3 = keras.Conv2D(128, kernel_size=3, padding='same')
self.relu3 = keras.Activation('relu')
self.bn3 = keras.BatchNormalization()
self.pool3 = keras.MaxPool2D()
self.bottleneck_conv = keras.Conv2D(256, kernel_size=(3, 3), padding='same')
self.upsample0 = keras.UpSampling2D(interpolation='bilinear')
self.dec_conv0 = keras.Conv2D(128, kernel_size=3, padding='same')
self.dec_relu0 = keras.Activation('relu')
self.dec_bn0 = keras.BatchNormalization()
self.upsample1 = keras.UpSampling2D(interpolation='bilinear')
self.dec_conv1 = keras.Conv2D(64, kernel_size=3, padding='same')
self.dec_relu1 = keras.Activation('relu')
self.dec_bn1 = keras.BatchNormalization()
self.upsample2 = keras.UpSampling2D(interpolation='bilinear')
self.dec_conv2 = keras.Conv2D(32, kernel_size=3, padding='same')
self.dec_relu2 = keras.Activation('relu')
self.dec_bn2 = keras.BatchNormalization()
self.upsample3 = keras.UpSampling2D(interpolation='bilinear')
self.dec_conv3 = keras.Conv2D(1, kernel_size=1)
def call(self, input):
e0 = self.pool0(self.relu0(self.bn0(self.enc_conv0(input))))
e1 = self.pool1(self.relu1(self.bn1(self.enc_conv1(e0))))
e2 = self.pool2(self.relu2(self.bn2(self.enc_conv2(e1))))
e3 = self.pool3(self.relu3(self.bn3(self.enc_conv3(e2))))
b = self.bottleneck_conv(e3)
d0 = self.dec_relu0(self.dec_bn0(self.upsample0(self.dec_conv0(b))))
d1 = self.dec_relu1(self.dec_bn1(self.upsample1(self.dec_conv1(d0))))
d2 = self.dec_relu2(self.dec_bn2(self.upsample2(self.dec_conv2(d1))))
d3 = self.dec_conv3(self.upsample3(d2))
return d3model = SegNet()
optimizer = optimizers.Adam(learning_rate=lr, decay=weight_decay)
loss_fn = losses.BinaryCrossentropy(from_logits=True)
model.compile(loss=loss_fn, optimizer=optimizer)def train(datasets, model, epochs, batch_size):
train_dataset, test_dataset = datasets[0], datasets[1]
model.fit(train_dataset[0], train_dataset[1],
epochs=epochs,
batch_size=batch_size,
shuffle=True,
validation_data=(test_dataset[0], test_dataset[1]))train(((X_train, y_train), (X_test, y_test)), model, epochs, batch_size)4、验证模型
predictions = []
image_mask = []
plots = 5
for i, (img, mask) in enumerate(zip(X_test, y_test)):
if i == plots:
break
img = tf.expand_dims(img, 0)
pred = np.array(model.predict(img))
predictions.append(pred[0, :, :, 0] > 0.5)
image_mask.append(mask)
plotn(plots, (predictions, image_mask)) https://github.com/bashendixie/ml_toolset/tree/main/%E6%A1%88%E4%BE%8B101%20%E4%BD%BF%E7%94%A8SegNet%E8%BF%9B%E8%A1%8C%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2
https://github.com/bashendixie/ml_toolset/tree/main/%E6%A1%88%E4%BE%8B101%20%E4%BD%BF%E7%94%A8SegNet%E8%BF%9B%E8%A1%8C%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2