spss分析方法-缺失值分析
缺失值可能会导致严重的问题。如果带有缺失值的个案与不带缺失值的个案有着根本的不同,则结果将被误导。此外,缺失的数据还可能降低所计算的统计量的精度,因为计算时的信息比原计划的信息要少。
另一个问题是,很多统计过程背后的假设都基于完整的个案,而缺失值可能使所需的理论复杂化。
下面我们主要从下面四个方面来解说:
- 实际应用
- 理论思想
- 建立模型
- 分析结果
一、实际应用
众所周知,在诸如收入、交通事故等问题的研究中,因为被调查者拒绝回答或者由于调查研究中的损耗,会存在一些未回答的问题。
例如在一次人口调查中,15%的人没有回答收入情况,高收入者的回答率比中等收入者要低,或者在严重交通事故报告中,诸如是否使用安全带和酒精浓度等关键问题在很多个案中都没有记录,这些缺失的个案值便是缺失值。
缺失值主要表现为以下3种:(1)完全随机缺失(Missing Completely At Random,MCAR),表示缺失和变量的取值无关。例如,假设在研究年龄和收入的关系,如果缺失的数据和年龄或收入数值无关,则缺失值方式为MCAR。要评估MCAR是否为站得住脚的假设,可以通过比较回答者和未回答者的分布来评估观察数据。也可以使用单变量t-检验或Little's MCAR多变量检验来进行更正规的评估。如果MCAR假设为真,可以使用列表删除(listwise deletion)(完整个案分析),无须担心估计偏差,尽管可能会丧失一些有效性。如果MCAR不成立,列表删除、均值置换等逼近方法就可能不是好的选择。(2)随机缺失(Missing At Random,MAR),缺失分布中调查变量只依赖于数据组中有记录的变量。继续上面的例子,考虑年龄全部被观察,而收入有时有缺失,如果收入缺失值仅依赖于年龄,缺失值就为MAR。(3)非随机缺失。这是研究者最不愿意看到的情形,数据的缺失不仅和其他变量的取值有关,也和自身有关。如果收入缺失值依赖于收入值,则既不是MCAR,也不是MAR。
二、理论思想
SPSS主要对MCAR和MAR两种缺失值情况进行分析。
区别MCAR和MAR的含义在于:由于MCAR实际上很难遇到,应该在进行调查之前就考虑哪些重要变量可能会有非无效的未回答,还要尽量在调查中包括共变量,以便用这些变量来估算缺失值。
针对不同情况的缺失值,SPSS操作给出了以下3种处理方法:
(1)删除缺失值,这种方法适用于缺失值非常少的时候,它不需要专门的步骤,通常在相应的分析对话框的“选项”子对话框中进行设置。
(2)替换缺失值,利用“转换”菜单中的“替换缺失值”命令将所有的记录看成一个序列,然后采用某种指标对缺失值进行填充。
(3)缺失值分析过程,缺失值分析过程是SPSS专门针对缺失值分析而提供的模块。
缺失值分析过程有以下3个主要功能:(1)描述缺失值的模式。通过缺失值分析的诊断报告,用户可以明确地知道缺失值所在位置及其出现的比例是多少,还可以推断缺失值是否为随机缺失等。(2)利用列表法、成对法、回归法或EM(期望最大化)法等为含缺失值的数据估算平均值、标准误差、协方差和相关性,成对法还可显示成对完整个案的计数。(3)使用回归法或EM法用估算值填充(插补)缺失值,以此提高统计结果的可信度。
缺失数据可以是分类数据或定量数据(刻度或连续),尽管如此,SPSS只能为定量变量估计统计数据并插补缺失数据。对于每个变量,必须将未编码为系统缺失值的缺失值定义为用户缺失值。舍尔判别法利用投影的方法使多维问题简化为一维问题来处理。其通过建立线性判别函数计算出各个观测量在各典型变量维度上的坐标并得出样本距离各个类中心的距离,以此作为分类依据。
三、建立模型
缺失值分析案例:
题目:下表的某些人口统计数据值已被缺失值替换。该假设数据文件涉及某电信公司在减少客户群中的客户流失方面的举措,每个个案对应一个单独的客户,并记录各类人口统计和服务用途信息。下面将结合本数据文件详细说明如何得到数据文件的缺失值,从而认识SPSS的缺失值分析过程。
一、数据输入
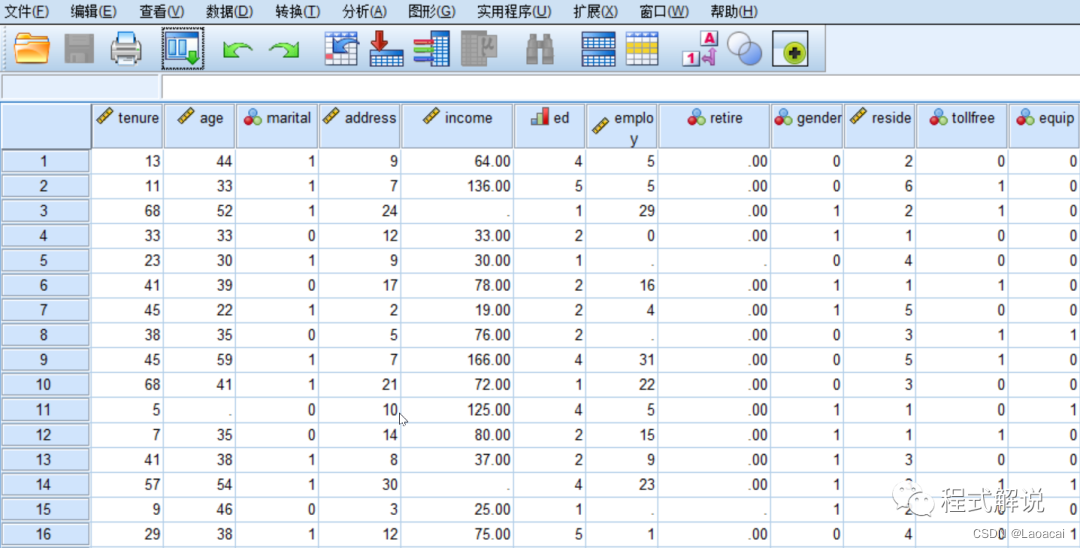
二、操作步骤
1、进入SPSS,打开相关数据文件,“分析”|“缺失值分析”命令2、选择“婚姻状况[marital]”“受教育水平[ed]”“退休[retire]”及“性别[gender]”4个变量进入“分类变量”列表框;选择“服务月数[tenure]”“年龄[age]”“在现住址居住年数[address]”“家庭收入(千)[income]”“现职位工作年数[employ]”及“家庭人数[reside]”6个变量进入“定量变量”列表框。
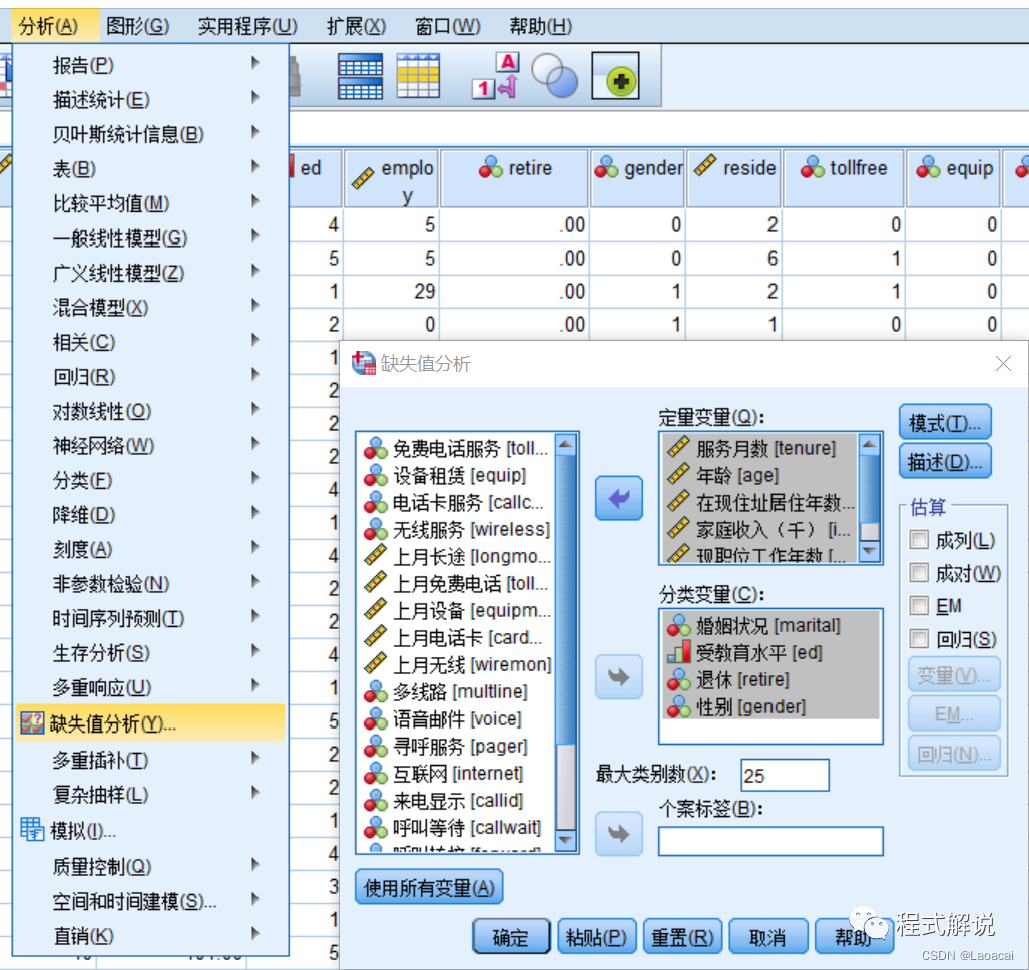
3、在“缺失值分析”对话框中单击“模式”按钮,弹出“缺失值分析:模式”对话框,选中“显示”选项组中的“个案表(按缺失值模式分组)”复选框,从“以下对象的缺失模式”列表框中选中income、ed、retire和gender 4个变量进入“以下对象的附加信息”列表框中。
其他采用默认设置。设置完毕后,单击“继续”按钮,回到“缺失值分析”对话框。
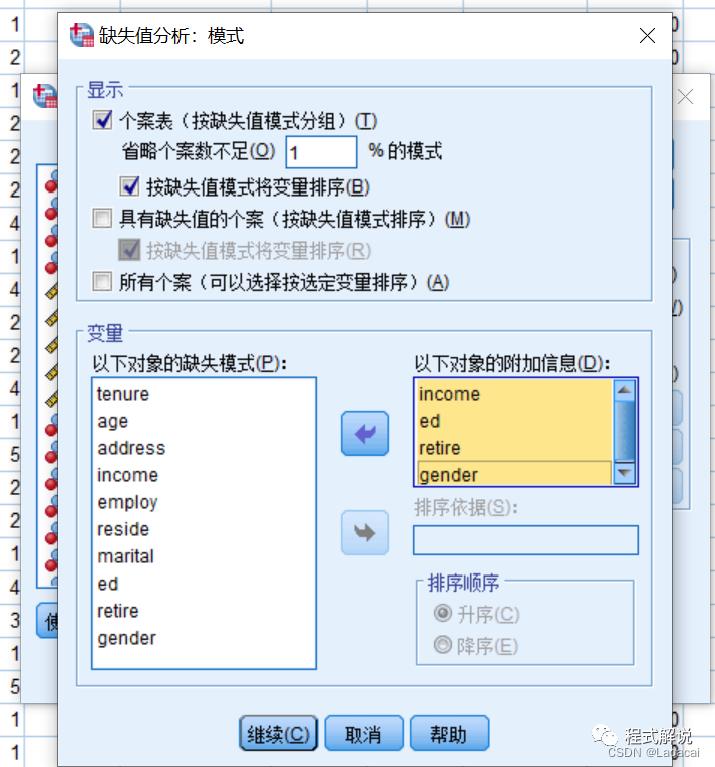
4、单击“描述”按钮,弹出“缺失值分析:描述”对话框。选中“单变量统计”复选框及“指示符变量统计”选项组中的“使用由指示符变量构成的组执行t检验”和“生成分类变量和指示符变量的交叉表”复选框,其他采用默认设置。

5、勾选EM,其余设置采用系统默认值即可。单击“确定”按钮,等待输出结果。
四、结果分析
1、单变量统计表下表给出了所有分析变量未缺失数据的频数、平均值和标准差,同时给出了缺失值的个数和百分比以及极值的统计信息。通过这些信息,我们可以初步了解数据的概貌特征,以employ一栏为例,employ变量的有效数据有904个,它们的平均值为11,标准差为10.113,缺失数据有96个,占数据总数的比例为9.6%,有15个极大值。

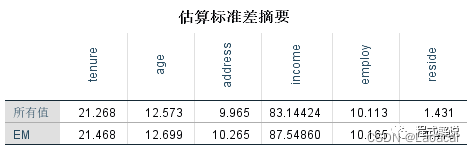
2、估算表下两个表使用EM法进行缺失值的估算后,总体数据的均值和标准差的变化情况,其中“所有值”为原始数据的统计特征,EM为使用EM法后总体数据的统计特征。

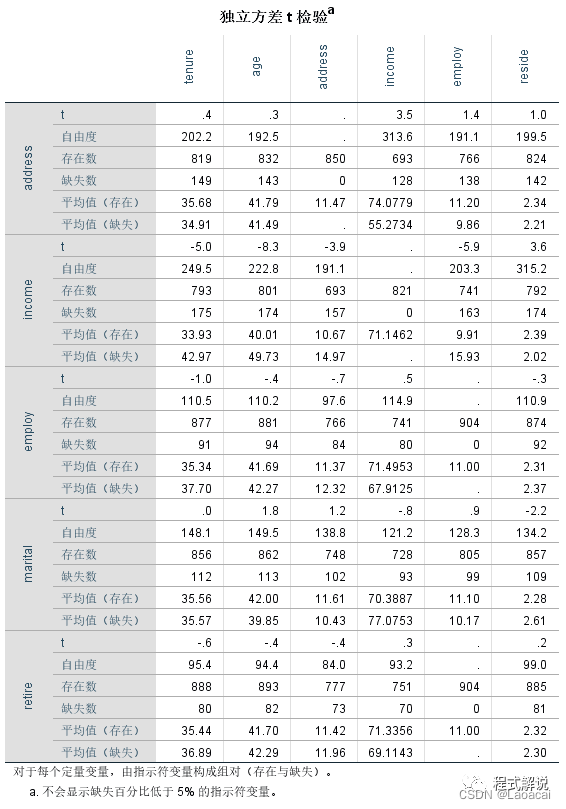
3、独立方差t检验表独立方差t测试结果,用户可以从中找出影响其他定量变量的变量的缺失值模式,即通过单个方差t统计量结果,检验缺失值是否为完全随机缺失。可以看出,年龄大的人倾向于不报告收入水平,当收入值缺失时,age的均值是49.73,当收入值完整时,age的均值为40.01。通过income一栏的t统计量可以看出,income的缺失将明显影响其他定量变量,这就说明income的缺失不是完全随机缺失。
4、分类变量和定量变量交叉表以marital为例给出了分类变量与其他定量变量间的交叉表。该表给出了在不同婚姻情况下,各分类变量非缺失的个数和百分比,以及各种缺失值的个数和百分比,图中标识了系统缺失值的取值,以及各变量在不同婚姻情况中的分布情况。

5、表格模式输出结果下表给出了表格模式输出结果(缺失值样式表),它给出了缺失值分布的详细信息,X为使用该模式下缺失的变量。由图可以看出,所有显示的950个个案中,9个变量值都完整的个案数有475个,缺失income值的个案有109个,同时缺失address和income值的个案有16个,其他数据的解释类似。

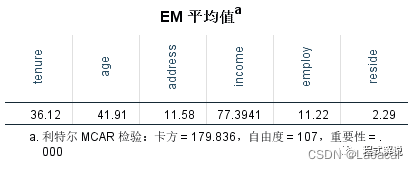
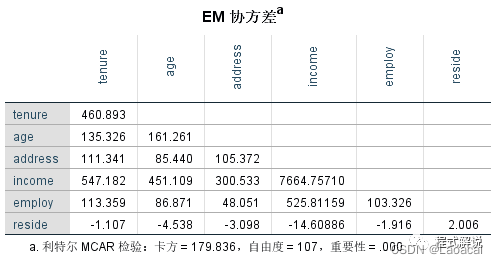
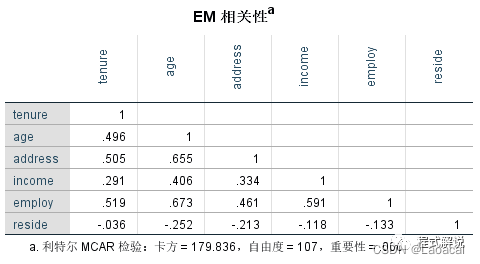
6、EM估算统计表下面三个表给出了EM算法的相关统计量,包括EM平均值、协方差和相关性。从EM平均值输出结果中可知,age变量的平均值为41.91,从EM协方差输出结果中可知,age和tenture间的协方差值为135.326,从EM相关性输出结果中可知,age与tenture的相关系数为0.496。另外,从三个表格下方的利特尔的MCAR检验可知,卡方检验的显著性值明显小于0.05,因此,我们拒绝了缺失值为完全随机缺失(MCAR)的假设,这也验证了3、独立方差t检验表所得到的结论。
参考案例数据:
- spss统计分析从入门到精通 (第四版) 杨维忠,陈胜可,刘荣 清华大学出版社
(获取更多知识,前往gz号程式解说)
原文来自https://mp.weixin.qq.com/s/CsMIoA_vu8HJoPvW16oNFg
