前言:最近忙于考研复习,好久没有敲代码了,本人目前只是学生,写博客的目的只是为了记录自己的学习过程,当然,如果能为他人提供一些帮助,那更好了。
一.Tesseract 简介
Tesseract 是Ray Smith 在1985 - 1995年间在惠普布里斯托实验室开发的一个ocr引擎(OCR (Optical Character Recognition,光学字符识别)),也是目前由谷歌支持的开源OCR项目。
有两种方式 动态库方式 libtesseract 和 执行程序方式 tesseract.exe 使用Tesseract 此处只介绍第二种方式
二.Tesseractor在Eclipse下的使用步骤
1.官网下载tesseract.exe
网址:https://github.com/tesseract-ocr/tesseract/wiki
此处我也提供了百度网盘链接(https://pan.baidu.com/s/1dmpqQ8Cm7Cd5zaLC0ZOZaw),包括安装文件和中文字库,版本是3.02.02(注:3.0以前不支持中文识别)
2.安装可执行程序tesseract.exe
下面为网盘文件tess4jAll解压之后的目录
安装完成之后的目录
3.将解压之后的中文训练字库文件夹下的文字库放到安装完成之后的Tesseract-OCR\tessdata 文件夹下面
红线标记的即为中文字库,此处已导入
4.Eclipse 创建Tesseract 测试类 (项目右击-build path 导入相关jar包-tess4j-3.2.1.jar,不导入的话,不能使用Tesseract 功能类)
识别图片准备
中文图片

英文图片

测试类代码
/**
* Tesseract测试类
*/
import java.awt.image.BufferedImage;
import java.io.File;
import javax.imageio.ImageIO;
import net.sourceforge.tess4j.Tesseract;
public class TesseactOCR {
/**
*
* @param imagePath
* 图片路径
* @param ZH_CN
* 是否使用中文训练库,true-是
* @return 识别结果
*/
public static String identifying(String imagePath, boolean ZH_CN) {
try {
File imageFile = new File(imagePath); // 创建一个图片文件
if (!imageFile.exists()) { // 如果图片不存在,给出提示并返回
return "The image is not exit ...";
}
BufferedImage textImage = ImageIO.read(imageFile); // 将图片加载到内存
Tesseract instance = Tesseract.getInstance(); // 创建Tesseract对象
instance.setDatapath("C:\\Program Files (x86)\\Tesseract-OCR\\tessdata");// 设置训练库(此处路径为你所安装的Tesseract-OCR下的tessdata文件夹路径)
if (ZH_CN) // 默认是英文识别 ,如果要识别中文则需要指定中文语言
instance.setLanguage("chi_sim");// 导入中文识别字库
String str = null; // 定义变量,接收识别结果
str = instance.doOCR(textImage);// 调用识别方法,得到识别结果
return str; // 返回识别结果
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
String str = identifying("D:\\tmp\\testch.jpg", true); // 第一个参数为识别图片路径,第二个参数为是否识别中文中文识别对比效果
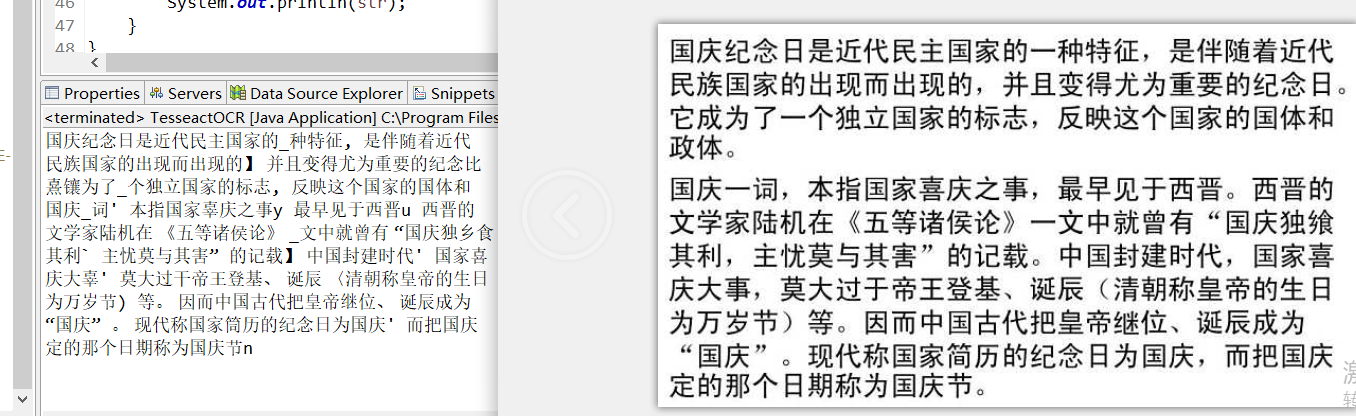
英文识别对比效果
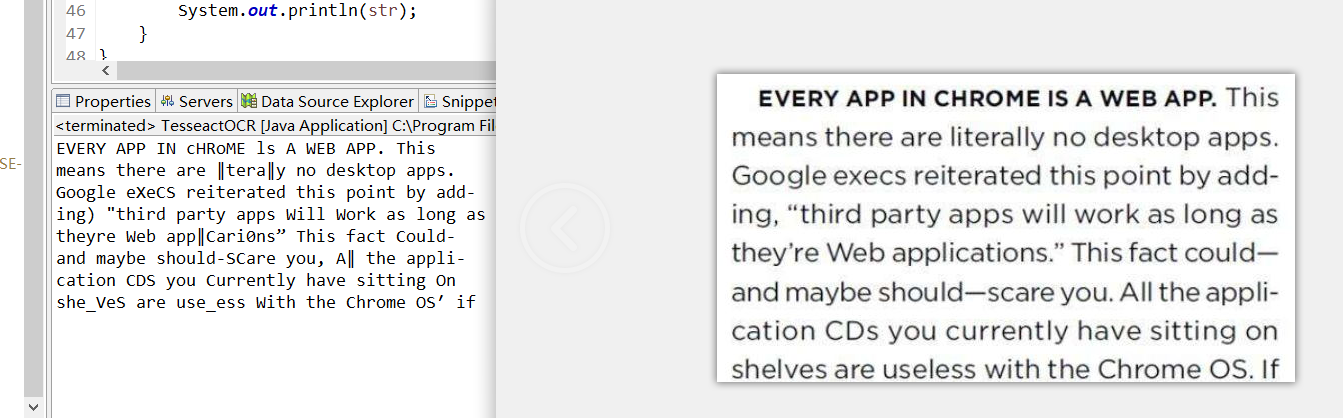
总结:由此可看出,图片识别率过低,对此可以有两种方法改进
1.对图片进行预处理,比如灰度化,二值化,对比度增强等
2.中文字库训练,纠正错误(读者可自行百度学习)
安装jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
5.异常分析
1. Exception in thread “main” java.lang.Error: Invalid memory access
没有设置训练库的位置
2. Exception in thread “main” java.lang.UnsupportedClassVersionError: net/sourceforge/tess4j/Tesseract :
JDK版本低于1.7,使用1.7或更高的版本。