论文:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
提出了attention-based model的变种:Stochastic "Hard" Attention和Deterministic "Soft" Attention
文章中几个需要区分的向量:
1、annotation vector
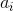
2、context vector
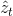
相同的框架:
1、编码器:卷积神经网络提取特征:
输入一幅图像产生一个标注y,表示为:

这里K是词汇表的大小,C是标注序列的长度,每一个y_i是一个K维的向量。使用CNN是为了提取一组特征向量,即annotation vector。特征提取器产生L个向量,每个向量是D维的,跟图想象中某一部分区域相关。
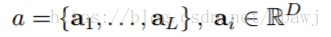
为了获得特征向量和二维图像之间的相关性,文中从底层的卷积层提取特征,区别于先前使用全连接层提取特征的工作。这样解码器能够选择性的关注于图像中的某一部分区域。
2、解码器:LSTM网络
使用LSTM网络产生最后的输出,本文中LSTM网络结构如图:
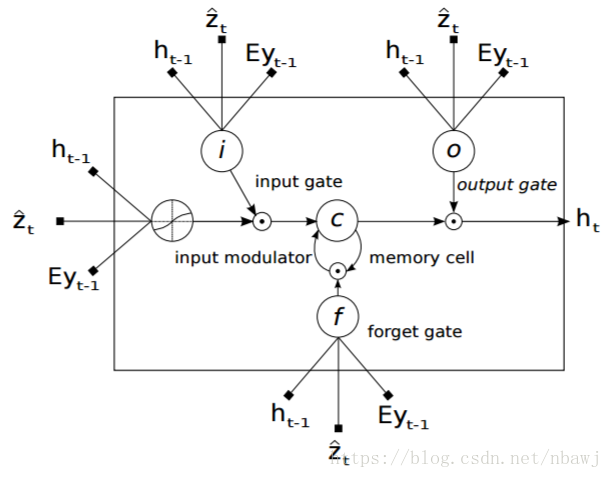
LSTM网络结构用公式表示为:
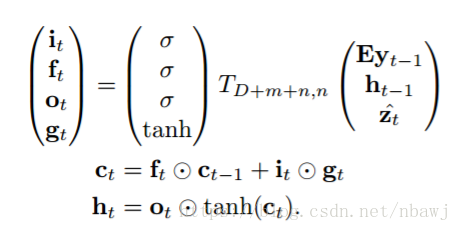
其中i_t, f_t, c_t, o_t, h_t 分别是输入门、忘记门、记忆单元、输出门和LSTM网络的隐藏层状态,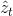
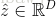
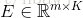
定义一个机制 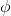
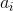



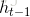
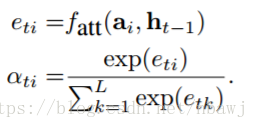
得到权重 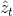
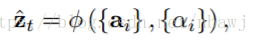
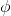
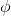
记忆单元和LSTM隐藏层状态的初始值通过如下公式计算得到:
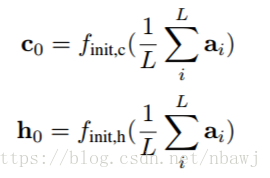
在解码器的输出部分,使用一个deep output layer计算输出单词的概率:

其中大写字母表示矩阵,L_o,L_h,L_z,E都是随机初始化之后需要学习的参数。
Stochastic "Hard" Attention:
在 hard attention 机制中,权重 
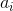

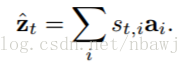
接下来的问题就是如何求解 
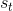
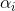
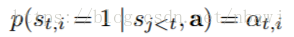
文章之后的部分都在用公式说明这个分布如何求解,具体需参考论文和这篇博客(Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制)。
Deterministic "Soft" Attention:
相比之下,在 soft attention 机制中,权重 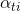

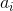
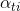

之后,就可以根据反向传播来进行训练了。
论文里还介绍了更多细节,比如分析了解码过程的一些情况;强迫使图像的每个区域在整个解码过程中的权重之和都相等(这种做法在目标函数中体现为一个惩罚项),来使图像的各个区域都对生成caption起到贡献;增加一个跟时间有关的维度因子可以让模型的注意力集中在图像的目标上。