目录
1 Global Attention全局注意力机制




权重计算函数
眼尖的同学肯定发现这个attention机制比较核心的地方就是如何对Query和key计算注意力权重。下面简单总结几个常用的方法:
扫描二维码关注公众号,回复:
9078333 查看本文章

1、多层感知机方法

主要是先将query和key进行拼接,然后接一个激活函数为tanh的全连接层,然后再与一个网络定义的权重矩阵做乘积。
这种方法据说对于大规模的数据特别有效。
2、Bilinear方法

通过一个权重矩阵直接建立q和k的关系映射,比较直接,且计算速度较快。
3、Dot Product

这个方法更直接,连权重矩阵都省了,直接建立q和k的关系映射,优点是计算速度更快了,且不需要参数,降低了模型的复杂度。但是需要q和k的维度要相同。
4、scaled-dot Product

上面的点积方法有一个问题,就是随着向量维度的增加,最后得到的权重也会增加,为了提升计算效率,防止数据上溢,对其进行scaling。
我个人通常会使用2和3,4。因为硬件机器性能的限制,1的方法计算比较复杂,训练成本比较高。
Local Attention
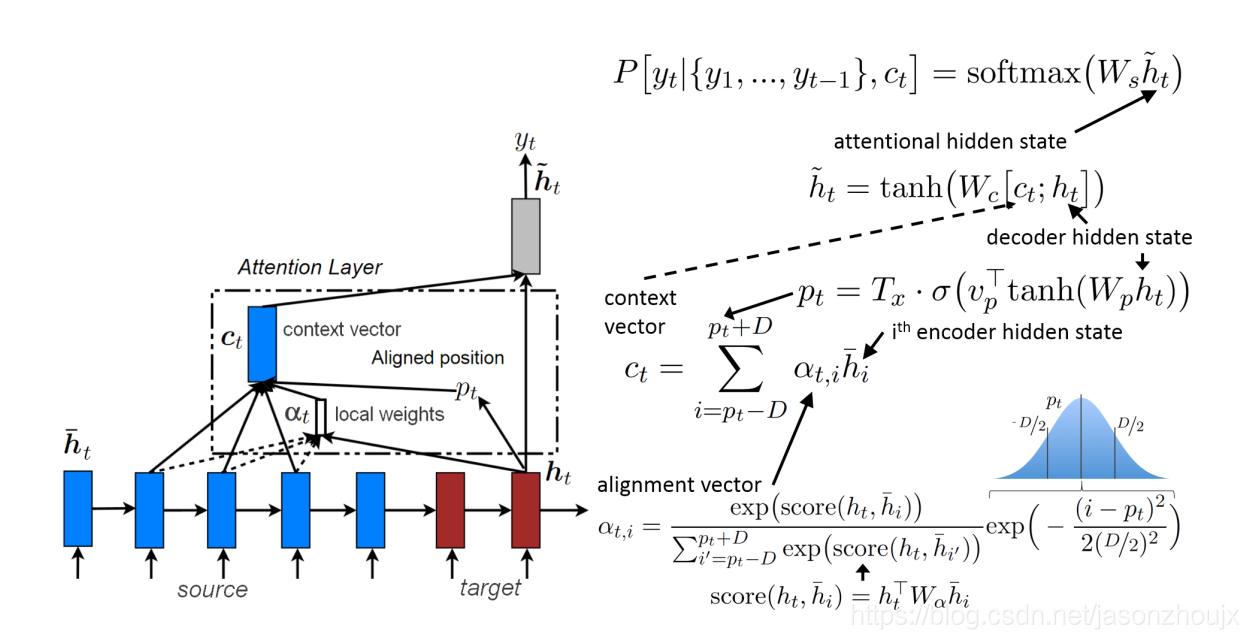
local attention机制选择性的关注于上下文所在的一个小窗口,这能减少计算代价。

关键值注意力(key-value attention)
自注意力(self-attention)
Multi-head attention

References:
NLP中的全局注意力机制(Global Attention)
