本篇是讲解关于JavaWeb岗位面试方面的一些对于Web知识的整理,当然,不只是需要知道这个方面的内容,还需要掌握其他方面的知识,我都根据自己的经历来进行了整理,方便大家进行系统化的学习,只有多复习多研究,才能对技术有更好的掌握,才能拿到更好的offer。
Spring的精华:https://blog.csdn.net/cs_hnu_scw/article/details/78677502
Hibernate的精华:https://blog.csdn.net/cs_hnu_scw/article/details/78762294
Java基础:https://blog.csdn.net/Cs_hnu_scw/article/details/79635874
数据结构:https://blog.csdn.net/Cs_hnu_scw/article/details/79896717
数据库:https://blog.csdn.net/Cs_hnu_scw/article/details/79896384
操作系统:https://blog.csdn.net/Cs_hnu_scw/article/details/79896500
计算机网络:https://blog.csdn.net/Cs_hnu_scw/article/details/79896621
其他方面的知识:https://blog.csdn.net/Cs_hnu_scw/article/details/79896876
1:Spring中获取连接池的方式有哪些?
答:(1)DBCP数据源
(2)C3P0数据源
(3)Spring的数据源实现类(DriverManagerDataSource)
(4)获取JNDI数据源
(5)Druid数据源----阿里开源
2:forward和redirect的区别有哪些?
答:(1)地址栏显示:前者不变,而后者会进行修改
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
(2)数据共享:前者是共享的,而后者是不能共享的
forward:转发页面和转发到的页面可以共享request里面的数据.
redirect:不能共享数据.
(3)发生的方式:前者是在服务器端,而后者是发生在客户端
(4)运用场景:forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
(5)效率:前者效率高,而后者效率低
注意:redirect默认是302码,包含两次请求和两次响应
3:Http返回码301和302之间的区别?
答:共同点:都是进行重定向返回的状态码
不同点:301是代表永久性转移;而302是短暂性转移,会发生网址劫持的情况;尽量使用301而不要使用302
4:PreparedStatement与Statement的区别?
答:(1)preparedStatement是继承的Statement接口,它们两者都是接口;
(2)preparedStatement是通过占位符,能够进行预编译的,而Statement不能,其每次执行SQL语句都需要重新进行处理;
(3)preparedStatement安全性更好,因为其能够防止SQL的注入
(4)preparedStatement对于重复执行的代码的执行效率更快,对于批处理效率相对Statemet好
(5)PreaparedStatement代码的维护性和可读性更加好
稍微补充一点额外知识:CallableStatement,其是PreparedStatement的子类,主要是用于调用数据库的存储过程;
5:JSP中静态Include和动态Include的区别?
答:(1)动态include是通过<jsp:include page = "hello.jsp">,而静态include是通过<%@ include file="hello.html"%>
(2)动态的可以包含相同的变量,而静态的是不可以包含相同变量
(3)动态的是先分别编译每个jsp,然后再使用的时候进行的包含在一起,是先编译再包含;而静态的是先包含在一起,然后再进行一起编译,是先包含,后编译
(4)如果被包含的页面经常更新,那么应该使用动态包含,因为使用静态包含,可能不会及时的进行更新;
(5)静态的include是通过伪码实现,不会检查文件的改变,适用于静态页面;
6:JSP有哪些内置对象?作用分别是什么?
答:一共是9个。
(1)HttpServletRequest类的request对象:代表请求对象,主要用于接受客户端通过HTTP协议链接传输到服务器端的数据
(2)HttpServletResponse类的response对象:代表响应对象,主要用于向客户端发送数据
(3)JspWriter类的out对象:主要用于向客户端输出数据,Out类的基类是JspWriter
(4)HttpSession类的session对象:主要用来分别保存每个用户信息和会话状态
(5)ServletContex类的application对象:主要用于保存所有应用系统中的公有数据,它是一个共享的内置对象,即一个容器中的多个用户共享一个application读写,只要没有关闭服务器,application对象一直存在
(6)PageContext类的PageContext对象:管理网页属性,代表了页面的上下文。PageContext对象的创建和初始化都是由容器自动完成。
(7)ServletConfig类的Config对象:代码片段配置对象,用于初始化Servlet的配置参数。
(8)Object类的Page对象:代表了当前正在运行的JSP页面,也就是说,page对象代表了JSP编译后的Servlet。page对象只能在当前的JSP范文之内使用。
(9)exception对象:处理JSP文件执行时发生的错误和异常,只有在错误页面里才可以使用;
7:JSP中的基本动作指令和作用?
答:(1)jsp:include:在页面被请求的时候引入一个文件
(2)jsp:useBean:寻找或者实例化一个JavaBean
(3)jsp:setProperty:设置JavaBean的属性
(4)jsp:getProperty:输出某个JavaBean的属性
(5)jsp:forward:把请求转到一个新的页面
(6)jsp:plugin:根据浏览器类型为java插件生成object或embed标记
8:Spring的事务传播特性和隔离级别分别是如何?
答:事务传播特性主要是分为7类:
PROPAGATION_REQUIRED -- 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS -- 支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY -- 支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW -- 新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED -- 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER -- 以非事务方式执行,如果当前存在事务,则抛出异常。
PROPAGATION_NESTED -- 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。
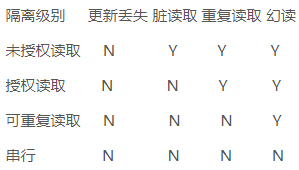
隔离级别主要分为4类:
1.未授权读取(Read Uncommitted):也称未提交读。允许脏读取但不允许更新丢失,如果一个事务已经开始写数据则另外一个数据则不允许同时进行写操作但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。事务隔离的最低级别,仅可保证不读取物理损坏的数据。与READ COMMITTED 隔离级相反,它允许读取已经被其它用户修改但尚未提交确定的数据。
2. 授权读取(Read Committed):也称提交读。允许不可重复读取但不允许脏读取。这可以通过“瞬间共享读锁”和“排他写锁”实现,读取数据的事务允许其他事务继续访问该行数据,但是未提交写事务将会禁止其他事务访问该行。SQL Server 默认的级别。在此隔离级下,SELECT 命令不会返回尚未提交(Committed) 的数据,也不能返回脏数据。
3. 可重复读取(Repeatable Read):禁止不可重复读取和脏读取。但是有时可能出现幻影数据,这可以通过“共享读锁”和“排他写锁”实现,读取数据事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。在此隔离级下,用SELECT 命令读取的数据在整个命令执行过程中不会被更改。此选项会影响系统的效能,非必要情况最好不用此隔离级。
4. 串行(Serializable):也称可串行读。提供严格的事务隔离,它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作事务访问到。事务隔离的最高级别,事务之间完全隔离。如果事务在可串行读隔离级别上运行,则可以保证任何并发重叠事务均是串行的。
温馨提示:
(1)关于操作数据库中出现的脏读,不可重复读,幻读
脏读:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。不可重复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
幻读:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
不可重复读的重点是修改: 同样的条件,你读取过的数据,再次读取出来发现值不一样了
幻读的重点在于新增或者删除: 同样的条件,第 1 次和第 2 次读出来的记录数不一样
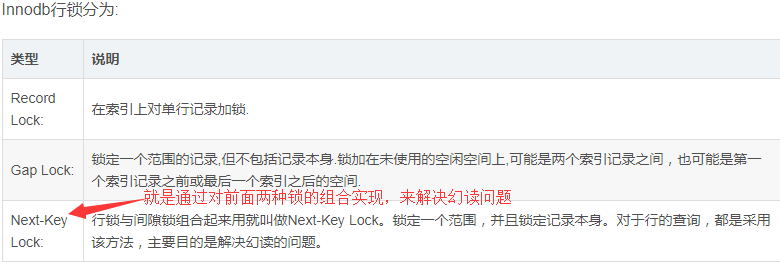
(2)问:Mysql5.6(Innodb)以后其数据库本身是如何解决幻读问题的?
答:首先,Innodb引擎默认的隔离级别是可重复读,所以,它本身是能够解决了脏读和不可重复读的问题,但是对于幻读是不能够解决的,但是,它本身又提供了一种机制来解决这种幻读的问题,就是通过NextKey lock方式,其实就是使用一种锁的机制;具体的过程如下:
9:Http中的request和response的头都含有什么字段?
答:https://blog.csdn.net/selinda001/article/details/79338766
10:JavaWeb的高并发处理的一些优化方式有哪些?
答:高并发可以分为用户量并发和数据并发
针对用户量的并发的解决方式可以从下面的方面进行考虑:
(1)网页静态化(纯HTML):主要是提高反应速度和提高安全性与稳定性(因为不容易被攻击);
(2)图片服务器分离:主要是减轻服务器压力,比如jQuery中的lazyload.js就能够实现这样的懒加载方式
(3)ajax请求:主要是不需要页面进行重新刷新获取
(4)服务器的负载均衡:主要是减轻服务器的压力,这里可以通过Nginx反向代理来进行;
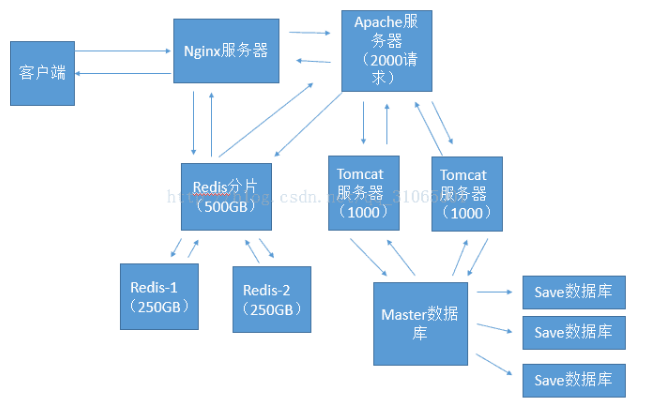
(5)数据库集群:主要是减轻数据库的压力,这里主要是通过master/slave(主从)数据库进行;
(6)使用缓存服务器缓存数据:主要是对于查询频繁的内容进行缓存,这里主要是通过redis进行;
针对数据并发可以从下面的方面进行考虑:
(1)对于方法采取synchronize机制
(2)通过spring的事务隔离级别:主要是用四种
(3)通过数据库的锁机制:表锁和行锁
(4)通过悲观锁和乐观锁
11:Web安全方面的知识点
答:(1)SQL注入:主要发生在登录系统的用户名和密码场景,利用SQL的拼接而导致的问题,所以,可以通过预处理命令来进行对SQL的处理;
(2)密码安全:主要是如果密码存储是以明文的形式,那么当数据泄露之后,就很容易进行用户密码的窃取,所以,可以通过MD5加密,或者SHA和盐值加密;
(3)Cookie安全:主要是通过判断本地是否有对应系统的Cookie值,从而进行修改,以达到直接登录系统的目的,所以,可以通过对Cookie值进行安全性的加密处理,再进行保存;
(4)XSS(跨站脚本攻击):主要是由于编写了脚本内容,导致在页面解析的时候进行脚本语言的解析,通常发生在评论区功能,所以,可以通过字符过滤掉非法字符的形式或者转义字符进行防范;
(4)CSRF(跨站请求伪造):攻击可以在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击站点,从而在并未授权的情况下执行在权限保护之下的操作;比如用户访问了一个转账的网页(通过get提交),而后面又访问了一个非法链接(而这个链接正好是指向转账网页,那么当点击之后就会发生又一次转账,而受害用户却还不知道),所以,针对这情况,可以采取HTTP referer字段(在http请求头里面,有referer字段用于判断网页的链接源地址),请求中添加token验证,
可以参考这篇文章的CSRF攻击内容:https://www.ibm.com/developerworks/cn/web/1102_niugang_csrf/
(5)SYN攻击:主要是由于tcp是一种全连接的方式,而SYN就是利用发送大量的半连接请求,消耗CPU和系统资源,从而导致服务器崩溃;所以,可以利用验证码的方式来进行预防;

可以参考看看这篇文章:https://blog.csdn.net/willie_chen/article/details/50381173
12:请说说关于JDBC的基本操作流程
答:
1)加载(注册)数据库驱动(到JVM)。-------Class.forname("com.mysql.jdbc.Driver");
2)建立(获取)数据库连接。---------Connection con=DriverManager.getConnection(url,username,password);
3)创建(获取)数据库操作对象。------------Statement st = con.createStatement();
4)定义操作的SQL语句。-------------String sql = "select * from student";
5)执行数据库操作。---------------ResultSet rst = st.excuteQuery(sql);
6)获取并操作结果集。 ---------while(rst.next){ 进行操作 }
7)关闭对象,回收数据库资源(关闭结果集-->关闭数据库操作对象-->关闭连接)。----rst.close(); st.close();con.close();
13: