本篇是讲解关于JavaWeb岗位面试方面的一些对于数据库知识的整理,当然,不只是需要知道这个方面的内容,还需要掌握其他方面的知识,我都根据自己的经历来进行了整理,方便大家进行系统化的学习,只有多复习多研究,才能对技术有更好的掌握,才能拿到更好的offer。
Java基础:https://blog.csdn.net/Cs_hnu_scw/article/details/79635874
数据结构:https://blog.csdn.net/Cs_hnu_scw/article/details/79896717
Web方向:https://blog.csdn.net/Cs_hnu_scw/article/details/79896165
操作系统:https://blog.csdn.net/Cs_hnu_scw/article/details/79896500
计算机网络:https://blog.csdn.net/Cs_hnu_scw/article/details/79896621
其他方面的知识:https://blog.csdn.net/Cs_hnu_scw/article/details/79896876
1:如何定位查询较慢的SQL语句?
答:(方法一:慢查询日志)MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow-queries[=file_name]选项启动时,mysqld 会写一个包含所有执行时间超过long_query_time 秒的SQL语句的日志文件,通过查看这个日志文件定位效率较低的SQL 。
1,slow_query_log
这个参数设置为ON,可以捕获执行时间超过一定数值的SQL语句。
2,long_query_time
当SQL语句执行时间超过此数值时,就会被记录到日志中,建议设置为1或者更短。
3,slow_query_log_file
记录日志的文件名。
4,log_queries_not_using_indexes
这个参数设置为ON,可以捕获到所有未使用索引的SQL语句,尽管这个SQL语句有可能执行得挺快
(1)使用方法
MySQL在Windows系统中的配置文件一般是是my.ini找到[mysqld]下面加上
代码如下:
log-slow-queries = F:/MySQL/log/mysqlslowquery。log
slow_query_log = 1
long_query_time = 2
(2) 查看慢SQL日志是否启用
mysql> show variables like 'log_slow_queries';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| log_slow_queries | ON |
+------------------+-------+
1 row in set (0.00 sec)
(3) 查看执行慢于多少秒的SQL会记录到日志文件中
mysql> show variables like 'long_query_time';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| long_query_time | 1 |
+-----------------+-------+
1 row in set (0.00 sec)
这里value=1, 表示1秒
(方法二:通过explanin关键字:用来分析SQL语句的执行状态)
(方法三:通过profile关键字:用来分析SQL语句的执行详细),可以通过下面的文章进行详细了解,它们的使用;
https://blog.csdn.net/cs_hnu_scw/article/details/78774680
2:数据库的存储过程的特点?
答:存储过程优点:1、存储过程增强了SQL语言灵活性。存储过程可以使用控制语句编写,可以完成复杂的判断和较复杂的运算,有很强的灵活性;
2、减少网络流量,降低了网络负载。存储过程在数据库服务器端创建成功后,只需要调用该存储过程即可,而传统的做法是每次都将大量的SQL语句通过网络发送至数据库服务器端然后再执行;
3、存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
4、系统管理员通过设定某一存储过程的权限实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
可以参考:https://blog.csdn.net/gaohuanjie/article/details/50996175
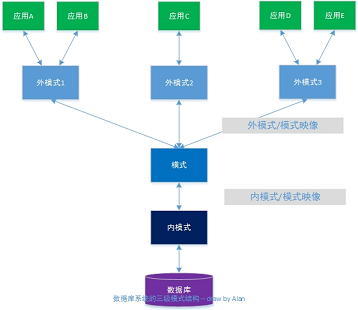
3:数据库的三级模式是什么?
答:数据库的三级模式结构是指:数据库系统是由外模式、模式和内模式三级构成,如图
1. 模式(Schema)
模式也称为:逻辑模式,它是DB中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。模式层是数据库模式结构的中间层,既不涉及到数据的物理存储细节和硬件环境,也与具体的应用程序、应用开发工具以及高级程序设计语言无关(C、C++、JAVA等)。
模式就是数据库数据在逻辑上的视图,且一个数据库只有一个模式。实际工作中,模式就等同于程序员创建一个具体的数据库的全部操作,如:这是一个MySQL数据库,有2张表,每个表的名字,属性的名字、类型、取值范围,主键,外键,索引,其他完整性约束等等。
DBMS提供模式描述语言(模式DDL)来严格地定义模式。
2. 外模式
外模式也称为:子模式(subschema)/用户模式,它是数据库用户(应用程序员、最终用户)能够看到的使用的局部数据的逻辑结构和特征的描述,是数据库的数据视图,是与某一个应用有关的数据的逻辑表示。
外模式通常是模式的子集。一个数据库可以有多个外模式。同一个外模式可以为某一用户的多个应用系统所使用,但一个应用系统只能使用一个外模式。
外模式是保证数据库安全性的一个有力措施。每个用户只能看见和访问所对应的外模式中的数据,数据库中的其余数据是不可见的。
DBMS提供子模式描述语言(子模式DDL)来严格地定义子模式。
3. 内模式
内模式也称为:存储模式(Storage schema),一个数据库只有一个内模式。它是数据库物理结构和存储方式的描述,是数据在数据库内部的表示方式。如:记录的存储方式是堆存储,还是按照某些属性值的升(降)存储,还是按照属性值聚簇(cluster)存储;索引按照什么方式组织,是B+树索引,还是hash索引等等。
DBMS提供内模式描述语言(内模式DDL/存储模式DDL)来严格定义内模式。
二级映像功能和数据的独立性
数据库的3级模式是对数据的3个抽象级别。它使得用户能够逻辑地抽象地处理数据,而不必再去关心数据在计算机中的具体表示方式与存储方式。实际上,为了能够实现在这3个抽象层次之间的联系和转换,DBMS在这三级模式之间设计了两层映像:
外模式/模式映像
模式/内模式映像
这两层映像保证了数据库中的数据能够具有较高的逻辑独立性和物理独立性。
1. 外模式/模式映像
由上可知:一个DB只有一个模式,但可以有多个外模式。
所以,对于每一个外模式,数据库系统都有一个外模式/模式映像,它定义了这个外模式与模式的对应关系。外模式的描述中通常包含了这些映像的定义。
当模式改变时(增加新的关系、新的属性、改变属性的数据类型等),由数据库管理员对各个外模式/模式映像作相应的改变,可以使得外模式保持不变。而又由于应用程序应该是依据外模式编写的,从而应用程序不必修改,这就保证了数据与程序的逻辑独立性。
总结:外模式/模式映像保证了当模式改变时,外模式不用变 — 逻辑独立性。
2. 模式/内模式映像
由上可知:一个DB只有一个模式,也只有一个内模式,所有模式/内模式映像是唯一的,它定义了数据全局逻辑结构与存储结构之间的对应关系。
当数据库的存储结构改变时(例如选用了另一个存储结构),由数据库管理员对模式/内模式映像作出相应的改变,可以使得模式保持不变,从而应用程序也不必改变。这就保证了数据和程序的物理独立性。
总结:模式/内模式映像保证了当内模式改变时,模式不用变 — 物理独立性。
4:数据库备份和恢复的方法?
答:主要要了解mysqldump和binlog(二进制文件)这两种的方法;
可以参考这篇非常不错的博文:https://blog.csdn.net/enweitech/article/details/51612858
5:下面SQL语句执行的顺序是什么?
select foo,count(foo)from pokes where foo>10group by foo having count (*)>5 order by foo
答:FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
6:在mysql中,字段类型中的char,varchar,blob,text的区别?
答:它们的存储方式和数据的检索方式都不一样
(1)char:存储定长数据很方便(最多不可以超过255字符),CHAR字段上的索引效率级高,必须在括号里定义长度,可以有默认值,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间(自动用空格填充),且在检索的时候后面的空格会隐藏掉,所以检索出来的数据需要记得用什么trim之类的函数去过滤空格。
(2)varchar:存储变长数据(最多不可以超过65535字节),但存储效率没有CHAR高,必须在括号里定义长度,可以有默认值。保存数据的时候,不进行空格自动填充,而且如果数据存在空格时,当值保存和检索时尾部的空格仍会保留。另外,varchar类型的实际长度是它的值的实际长度+1,这一个字节用于保存实际使用了多大的长度。
(3)BLOB被视为二进制字符串,BLOB列没有字符集,并且排序和比较基于列值字节的数值值,在大多数方面,可以将BLOB列视为能够足够大的VARBINARY列
(4)text:存储可变长度的非Unicode数据,最大长度为2^31-1个字符。text列不能有默认值,存储或检索过程中,不存在大小写转换,后面如果指定长度,不会报错误,但是这个长度是不起作用的,意思就是你插入数据的时候,超过你指定的长度还是可以正常插入。
结论:
(1)经常变化的字段用varchar;
(2)知道固定长度的用char;
(3)尽量用varchar;
(4)超过255字节的只能用varchar或者text;
(5)能用varchar的地方不用text;
(6)能够用数字类型的字段尽量选择数字类型而不用字符串类型的(电话号码),这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接回逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够;
(7)如果是要存储二进制流的内容(比如图片),那么可以采取用Blob;
7:什么情况下应该对字段建立索引?
答:(1)经常查询的字段;
(2)唯一性强的字段,比如像性别字段,区分度不大,所以不适合建立;
(3)出现在where条件查询的字段,因为如果不会出现在where字段之后,那么建立索引也就没有必要了;
(4)不经常修改的字段,因为对于经常修改的字段,那么还要进行索引的维护,这是需要消耗时间和空间;
(5)不会出现null值的字段;
8:字段存在索引但是会发现无效的情况有哪些?
答:(1)进行了模糊匹配,使用"%Like"
(2)使用了or查询,两端的字段某个不存在索引
(3)进行了函数操作字段,比如abs()函数
(4)对字段进行了运算,比如使用!= 或者< ,>等
(5)对于Bolb和text字段,只能使用前缀索引
(6)join条件字段类型不一致的时候
(7)对于字段出现null的情况,并且这种字段是不适合建立索引
9:数据库中的内连接,左连接,右连接,全连接,交叉连接?
答:内连接:内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。(有下面三种)
1.1.等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。1.2.不等值连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>。
1.3.自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
全连接:完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值;(注意:在mysql中是不支持这种方式的,而只能通过先左连接,然后使用union all 再与右连接的方式)
交叉连接:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
具体的例子:https://www.cnblogs.com/zxlovenet/p/4005256.html
10:数据库的安全性如何保证?
答:(1)设置用户的权限:保证非法用户的非法侵入;
(2)定义视图:通过这样把不同权限用户所能看到的数据和操作的数据进行隔离;
(3)数据加密:保证数据的保密性;
(4)启动事务管理和故障恢复:防止意外情况的发生,保证数据的一致性和完整性,主要的措施是日志记录和数据复制;
(5)数据库备份和恢复:防止数据非法丢失和意外情况发现,保证数据可进行一定恢复;
(6)审计追踪机制:主要是对于数据的更新,删除操作进行日志记录,方便后续的审查;
(7)加强服务器的安全:因为数据库都是存放在服务器中的,所以需要保证服务器的安全;
11: