本篇是讲解关于JavaWeb岗位面试方面的一些对于数据结构知识的整理,当然,不只是需要知道这个方面的内容,还需要掌握其他方面的知识,我都根据自己的经历来进行了整理,方便大家进行系统化的学习,只有多复习多研究,才能对技术有更好的掌握,才能拿到更好的offer。
Java基础:https://blog.csdn.net/Cs_hnu_scw/article/details/79635874
计算机网络:https://blog.csdn.net/Cs_hnu_scw/article/details/79896621
Web方向:https://blog.csdn.net/Cs_hnu_scw/article/details/79896165
数据库:https://blog.csdn.net/Cs_hnu_scw/article/details/79896384
操作系统:https://blog.csdn.net/Cs_hnu_scw/article/details/79896500
其他方面的知识:https://blog.csdn.net/Cs_hnu_scw/article/details/79896876
主要是掌握如下的模块的内容:
(1)线性结构:线性表,链表,栈,队列
(2)树型结构:树;二叉树;完全二叉树;满二叉树;哈夫曼树;排序二叉树;B树;B-树;B+树;b*树;红黑树;
(3)图:有向图,无向图
1:关于树的一些基本知识
答:(1)树的“度”的含义:是指非叶子节点中,其节点的分支条数,比如二叉树中,非叶子节点中的度最大为2;
(2)如果一颗深度为K的二叉树,如果它包含(2的K次幂-1)个节点,那么就是满二叉树;
(3)完全二叉树和满二叉树的区别:
完全二叉树:其倒数第二层是满的,而最后一层存在右子树不完全填满,则称为完全二叉树;
满二叉树:其所有的层数的节点数都是满的;
满二叉树是一种特别的完全二叉树;
(4)具有n个节点的完全二叉树的深度为log2(n+1);
2:遍历二叉树的方法有哪些?它们之间的区别在哪?
答:主要是分为两大类:广度优先遍历和深度优先遍历;
广度优先遍历:按照二叉树的层来进行逐层访问;
深度优先遍历:将先访问到树中最深层次的节点,然后又主要分为下面的三种类型:
(1)先序遍历(前序遍历)-----先访问根,再是左子树,其次是右子树
(2)中序遍历(对称遍历)-----先访问左子树,再是根,其次是右子树
(3)后序遍历----------先访问左子树,再是右子树,其次是根
注意:知道前序遍历和中序遍历或者中序遍历和后序遍历,都可以确定一棵树;但是,如果知道前序遍历和后序遍历,不一定可以确定一棵树,当且仅当树中只存在度为0和2,不存在度为1的情况,才能确定;https://blog.csdn.net/gyqjn/article/details/52709912
3:存储二叉树的结构有哪些?各自的特点是什么?
答:(1)顺序存储---使用一维数组存储二叉树;这样的方式的话,存储比较简单,主要是通过二叉树的性质,比如当前节点序号是i,那么对应的数组下标的i/2就表示是其父节点,如果2*i+1<=size(数组大小),那么表示有左节点,如果2*i+2<=size(数组大小),那么就表示有右节点,所以判断方便;但是缺点 在于,如果节点只有右节点,
(2)二叉链式存储:----主要是构建的节点有两个指针域,即left和right域,分别用于指向该节点的左节点和右节点
(3)三叉链式存储:-----基于二叉链式的改进,有三个指针域,即left和right以及parent域,分别用于指向该节点的左节点,右节点和父节点;
4:哈夫曼树的相关概念内容
答:定义:哈夫曼树又被称为最优二叉树,是一类带权路径最短的二叉树。哈夫曼树是二叉树的一种应用,在信息检索中常用;
节点之间的路径长度:从一个节点到另一个节点之间的分支数量称为两个节点之间的路径长度;
树的路径长度:从跟节点到树中的每一个节点的路径长度之和;
节点的带权路径长度:从该节点到根节点之间的路径长度与节点上权的乘积;
树的带权路径长度:树中所有叶子节点的带权路径长度之和;
5:对于具有n个叶子节点的哈夫曼树,为什么一共需要2*n-1个节点?
答:因为对于二叉树来说,存在着节点度数为0的叶子节点,度数为1的节点和度数为2的节点,而哈夫曼树中的非叶子节点都是由两个节点合并产生,所以不会出现度数为1的节点,而生成的非叶子节点的个数为叶子节点-1,因此n个叶子节点的哈夫曼树,一共需要2*n-1个节点;
比如: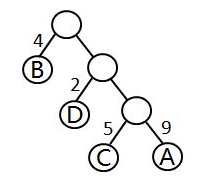
6:给定一组输入数据,能否确定唯一一颗哈夫曼树?
答:不能唯一确定:(1)因为无法保证每个数据的权重都没有重复,所以这样构造的哈夫曼树是不唯一;
(2)因为左右子树无法确定,所以也是不能唯一确定一颗哈夫曼树;
唯一能确定的是,这样构造出来的带权路径的总长度是唯一的哈夫曼树;
7:红黑树的特性要求有哪些?
答:(1)每个节点要么是红色,要么是黑色
(2)根节点永远是黑色
(3)所有的叶节点都是空节点(即null),并且是黑色
(4)每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
(5)从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
8:红黑树中如果黑色高度是N,那么最短和最长的路径分别是多少?
答:首先说一下什么叫过黑色高度-----------指的是从根节点到叶子节点的路径中包含的黑色节点数被称为黑色高度;
最短路径:则路径都是全黑,所以就是N-1;
最长路径:则是红色和黑色进行交替出现,所以就是2*(N-1);
9:基本的排序算法
答:
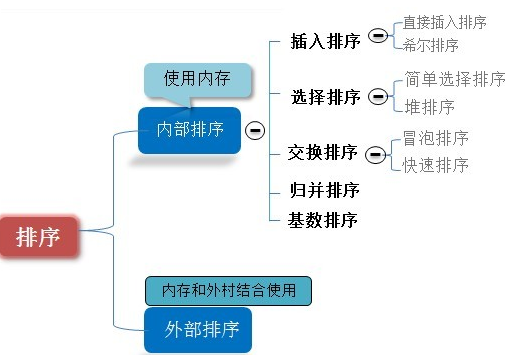

具体的各种算法可以参考这篇文章:https://blog.csdn.net/happy_wu/article/details/51841244
10:说说关于动态规划的思想?
答:动态规划简称就是DP,其思想主要在于,本质上是一种划分子问题的算法,站在任何一个子问题的处理上看,当前子问题的提出都要依据现有的类似结论,而当前问题的结论是后 面问题求解的铺垫。任何DP都是基于存储的算法,核心是状态转移方程;
比较经典的题目就是:“01”背包问题和矩阵相乘问题;
11:优先队列,阻塞队列,优先阻塞队列等多种队列的区别?
答:提示:队列都不能插入null元素;
优先队列(PriorityQueue):就是在队列中根据某一个特征值自动进行排序,优先队列分为两种,最大优先队列和最小优先队列,优先队列的一个最大特性就是,当插入元素或者删除元素的时候,队列会自动进行调整,保证队首元素一定是优先权最大/最小。正是由于优先队列的这种特性,优先队列可以被用在很多地方,比如作业调度,进程调度等。
特点:(1)其底层是通过堆来实现(默认是小堆);----具体是小堆还是大堆,需要根据队列元素中的比较器来判断
(2)就是会对插入的元素进行排序(可以根据队列的元素内容的comparable比较器的设置进行自定义,默认是用的从小到大)
(3)不允许插入null元素
阻塞队列(BlockingQueue):是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
其实现类有如下几种:
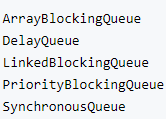
优先阻塞队列(PriorityBlockingQueue):(1)其是阻塞队列的一个实现类(2)其底层与优先队列一致,不过其内部进行了加锁处理(3)不允许插入null元素
ArrayBlockingQueue:是一个有边界的阻塞队列,它的内部实现是一个数组。有边界的意思是它的容量是有限的,我们必须在其初始化的时候指定它的容量大小,容量大小一旦指定就不可改变。
ArrayBlockingQueue是以先进先出的方式存储数据,最新插入的对象是尾部,最新移出的对象是头部。
DelayQueue:阻塞的是其内部元素,DelayQueue中的元素必须实现 java.util.concurrent.Delayed接口,这个接口的定义非常简单:
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
getDelay()方法的返回值就是队列元素被释放前的保持时间,如果返回0或者一个负值,就意味着该元素已经到期需要被释放,此时DelayedQueue会通过其take()方法释放此对象。
从上面Delayed 接口定义可以看到,它还继承了Comparable接口,这是因为DelayedQueue中的元素需要进行排序,一般情况,我们都是按元素过期时间的优先级进行排序
LinkedBlockingQueue:阻塞队列大小的配置是可选的,如果我们初始化时指定一个大小,它就是有边界的,如果不指定,它就是无边界的。说是无边界,其实是采用了默认大小为Integer.MAX_VALUE的容量 。它的内部实现是一个链表。
和ArrayBlockingQueue一样,LinkedBlockingQueue 也是以先进先出的方式存储数据,最新插入的对象是尾部,最新移出的对象是头部。
SynchronousQueue:队列内部仅允许容纳一个元素。当一个线程插入一个元素后会被阻塞,除非这个元素被另一个线程消费; 可以参考一下这篇文章进行理解:https://blog.csdn.net/yanyan19880509/article/details/52562039
12:大数据之位图法(BAT常问的问题)
答:参考:https://blog.csdn.net/little_bobo/article/details/60466736
https://blog.csdn.net/wenqiang1208/article/details/76724338
https://www.cnblogs.com/kex1n/p/7246512.html?utm_source=itdadao&utm_medium=referral
https://blog.csdn.net/u013291394/article/details/50211181
https://blog.csdn.net/v_july_v/article/details/6279498
https://blog.csdn.net/u010983881/article/details/75097358
13:
关于算法题的内容:
1:全排列问题
问题描述:
对于一个给定的序列 a = [a1, a2, a3, … , an],请设计一个算法,用于输出这个序列的全部排列方式。
例如:a = [1, 2, 3]
输出
[1, 2, 3]
[1, 3, 2]
[2, 1, 3]
[2, 3, 1]
[3, 2, 1]
[3, 1, 2]如果要按从小到大输出呢?算法又要怎么写?
2:“0”和“1”背包问题(DP问题)---------最经典的动态规划题目
3:矩阵连乘积问题(DP问题)
描述:
在科学计算中经常要计算矩阵的乘积。矩阵A和B可乘的条件是矩阵A的列数等于矩阵B的行数。若A是一个p×q的矩阵,B是一个q×r的矩阵,则其乘积C=AB是一个p×r的矩阵。计算C=AB总共需要p×q×r次乘法。
现在的问题是,给定n个矩阵{A1,A2,…,An}。其中Ai与Ai+1是可乘的,i=1,2,…,n-1。
要求计算出这n个矩阵的连乘积A1A2…An最少需要多少次乘法。
输入
输入数据的第一行是一个整树n(0 < n <= 10),表示矩阵的个数。
接下来的n行每行两个整数p,q( 0 < p,q < 100),分别表示一个矩阵的行数和列数。
输出
输出一个整数:计算连乘积最少需要乘法的次数
4:两个字符串的最大公共子序列(DP)
描述:比如给了两个字符数组,str1={A,B,B,D,C};str2={B,B,C,E},那么最大的公共子序列就是same={B,B,C}。只要满足相同的字符是递增的序号即可,不需要一定保持顺序就是连续的;
5:最大子段和(DP)
描述:比如给定一个数组 a={-2,11,-4,13,-5,-2},最大的子段和sum=20;
6:求链表的倒数第K个节点(类似:求链表的中点)
描述:输入一个链表,输出倒数第K个节点
7:求链表的反转
描述:输入一个链表,将其进行反转
8:判断链表中是否存在环
描述:输入一个链表,判断是否存在环
9:二叉树的镜像
描述:将二叉树的左右子树进行交换位置
10:将两个有序的链表进行合并成一个链表
描述:将两个已经有序的链表,合并成一个链表,并且保持着顺序还是有序的
11:子树结构的判断
描述:输入两个树,判断第二颗树是否是第一颗树的子树;
12:求二叉树的最长距离
描述:输入一颗树,判断其节点中的最长的距离(也就是二叉树中的某两个节点中的最大长度);
13:求大数级别的(X^Y)%N的结果
描述:求X的Y次方的取模的结果,其中X和Y以及N都是大数级别;(要想办法快速计算,要不然会超时)
14:位图法之计算数字出现次数(用于大数据的分析情况)
描述:比如有N个0---M之间的数字,那么如何找到出现次数只有1次的数字;
15:位图法之判断某个数字是否出现过(用于大数据量的分析情况)
描述:比如有N个0---M之间的数字,那么如何快速判断是否某个数字出现在这里面;
16:
关于上面这些算法题的解析程序(Java编写),如果有需要的可以进行留言,因为将程序贴出来会太多而导致不利于阅读,所以有需要的可以进行询问,另外也可以自己在网上找到类似的解析都是可以的哦。! 这并不是终点,而是我刚刚的开始,我会一直不断将知识点进行更新,欢迎大家进行关注和阅读!!!