RETHINKING DATA AUGMENTATION: SELF-SUPERVISION AND SELF-DISTILLATION
重新思考数据增强:自我监督和自我蒸馏
这篇论文的思想非常直观,如图,首先,Data Augmentation相关的方法会对通过对原始图片进行一些变换(颜色、旋转、裁切等)来扩充原始训练集合,提高模型泛化能力;
Multi-task learning将正常分类任务和self-supervised learning的任务(比如旋转预测)放到一起进行学习。
作者指出通过data augmentation或者multi-task learning等方法的学习强制特征具有一定的不变性,会使得学习更加困难,有可能带来性能降低。因此,作者提出将分类任务的类别和self-supervised learning的类别组合成更多类别(例如 (Cat, 0),(Cat,90)等),用一个损失函数进行学习。
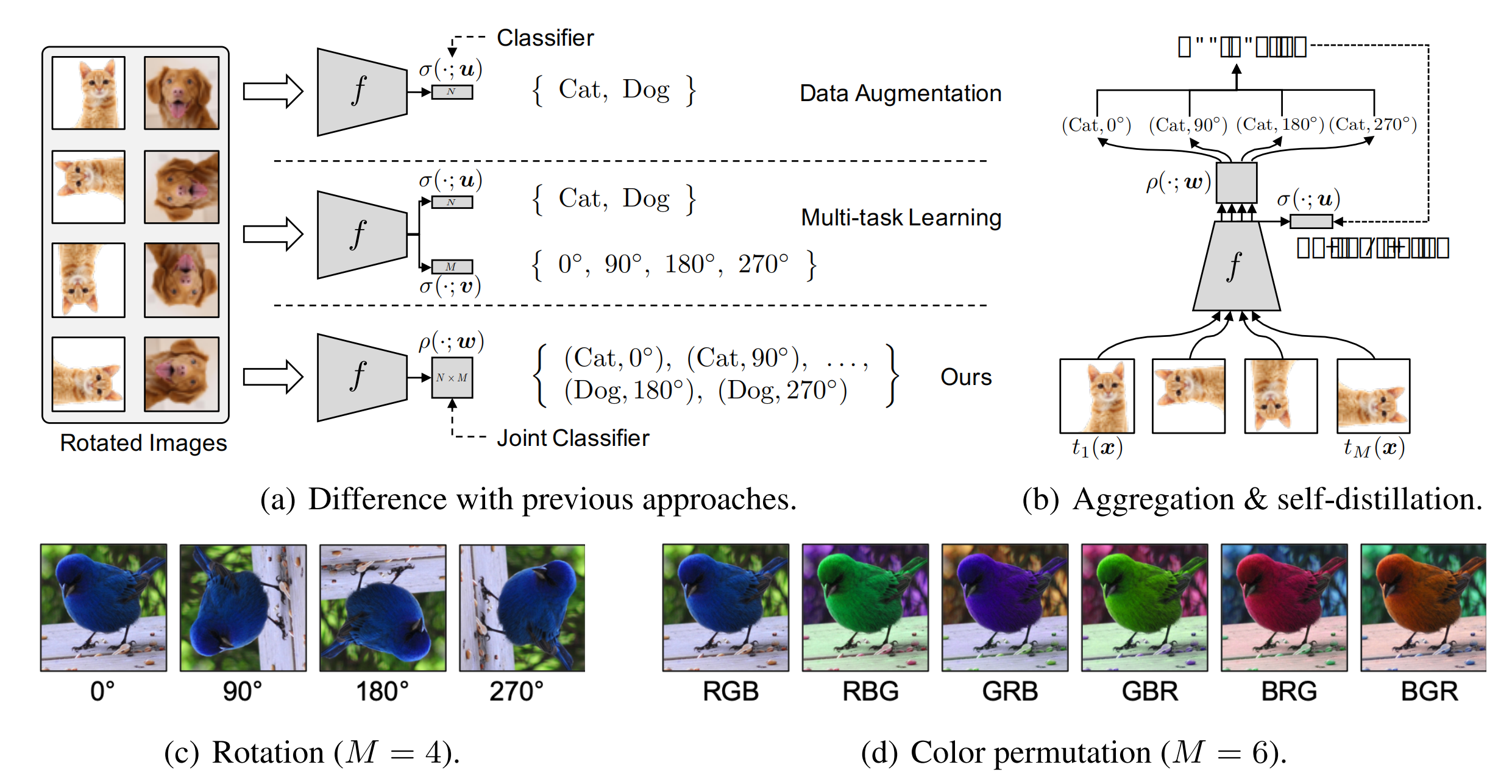
Figure 1: (a) An overview of our self-supervised data augmentation and previous approaches with self-supervision.
(b) Illustrations of our aggregation method utilizing all augmented samples and self-distillation method transferring the aggregated knowledge into itself.
(c) Rotation-based augmentation.
(d) Color-permutation-based augmentation.
比较有意思的一点是,作者通过简单变换证明:如果 wij=ui ,论文方法就退化成Data Augmentation;如果 wij=ui+vj ,论文方法就退化成Multi-task Learning的方法,这里 u,v,w 是对应的分类器权重。所以,作者提出的方法本身就包含了Data Augmentation和Mult-task Learning方法,同时具有更大的使用范围。
在实际物体分类过程中,可以将不同旋转角度的分类结果进行加和,即: p(Cat) = p(Cat,0)+p(Cat,90) +p(Cat,180)+p(Cat,270),但是这样测试时间会变成原来的4倍。所以,作者提出了第二个模块,self-distillation(自蒸馏)。如下图,self-distillation思路是在学习的过程中限制不同旋转角度的平均特征表示和原始图片的特征表示尽可能接近,这里使用KL散度作为相似性度量。

最终,整个方法的优化目标如下:
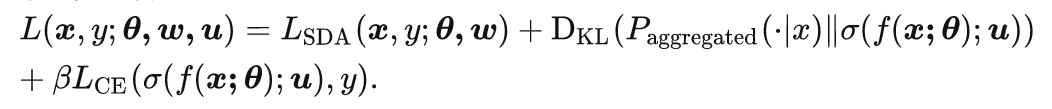
S4L: Self-Supervised Semi-Supervised Learning
S4L:自我监督半监督学习
S^4L这一篇paper,非常像上面图(a)中multit-ask learning的策略,即有标签数据上面加一个正常的分类损失,无标签数据上加一个self-supervised的损失,具体公式如下:
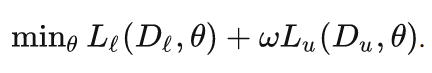
作者提出了两个算法,一个是 S^4L-Rotation,即无监督损失是旋转预测任务;另一个是S^4L-Exemplar,即无监督损失是基于图像变换(裁切、镜像、颜色变换等)的triplet损失。
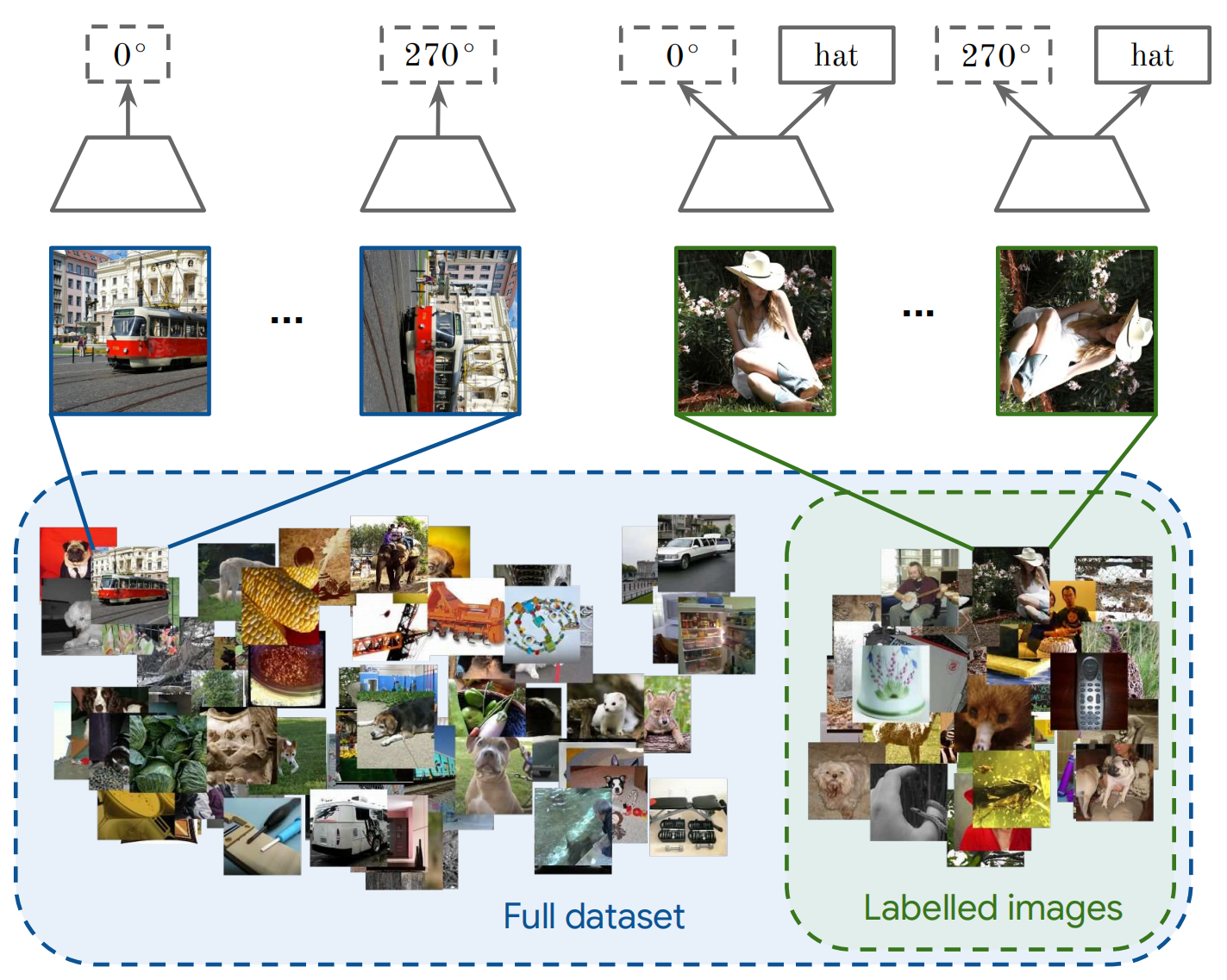
Our model makes use of both labeled and unlabled images. The first step is to create four input images for any image by rotating it by 0◦, 90◦, 180◦ and 270◦ (inspired by [9]). Then, we train a single network that predicts which rotation was applied to all these images and, additionally, predicts semantic labels of annotated images. This conceptually simple technique is competitive with existing semi-supervised learning methods.
我们的模型同时使用了标记和未标记的图像。 第一步是通过旋转 0°、90°、180° 和 270°为任何图像创建四个输入图像。 然后,我们训练一个单一的网络来预测哪些旋转应用于所有这些图像,此外,预测注释图像的语义标签。 这种概念上简单的技术与现有的半监督学习方法具有竞争力。
所有的实验在10%或者1%标签的Imagenet上进行,同时作者自己从训练集划分出一小部分作为验证集进行参数调节。实验过程中,作者观察到weight decay的调节和学习率策略对最终性能有很重要的影响。
Boosting Few-Shot Visual Learning with Self-Supervision
通过自我监督促进 Few-Shot 视觉学习
Boosting Few-Shot Visual Learning with Self-Supervision | Papers With Code
ICCV 2019
创新点
将小样本分类任务与自监督学习任务相结合,通过提高特征提取网络的表征能力,来改善小样本分类效果
核心思想
本文提出一种利用额外自监督任务提高小样本学习能力的算法,本文的核心思想就在于将额外的自监督学习任务与小样本分类任务结合起来,二者共用一个特征提取网络,利用自监督学习任务提高特征提取网络的表征能力,从而改善小样本分类任务的效果,该算法的实现方式如下图所示:
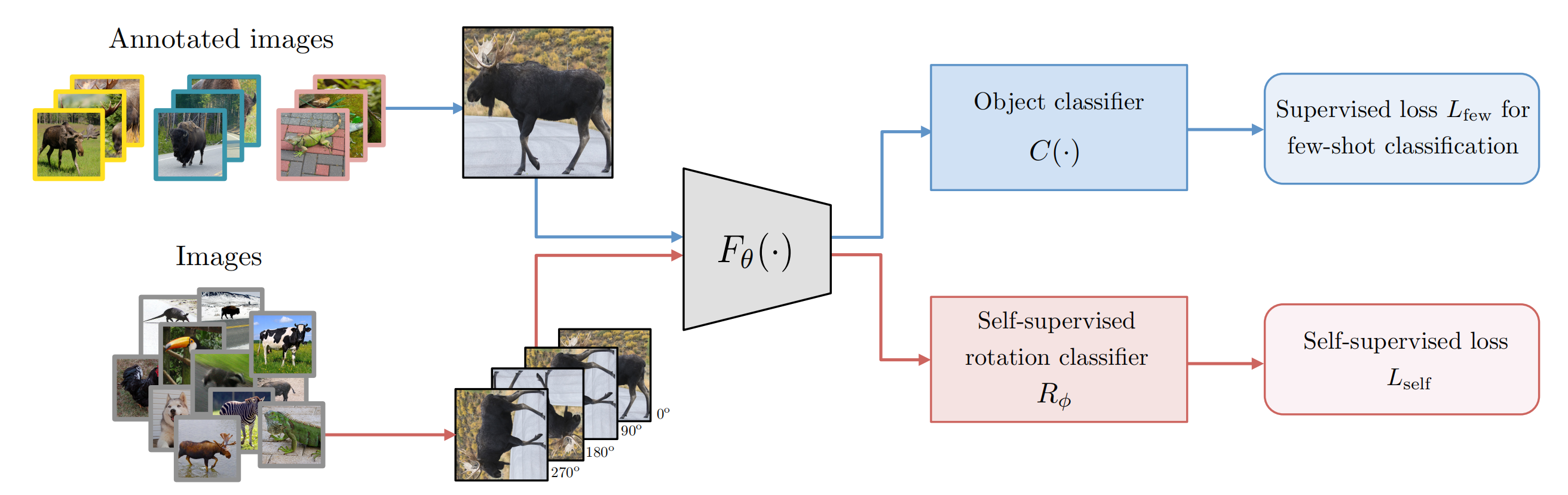
图1:在小样本学习系统的第一个学习阶段结合自监督图像旋转预测和监督基类识别。 我们在多任务设置中使用带注释(顶部分支)和未注释(底部分支)数据训练特征提取器 Fθ(·)。
我们使用带注释的数据来训练对象分类器 C(·),使用少样本分类损失。
对于自我监督任务,我们从带注释的集合中采样图像(也可以选择从不同的非注释图像集中)。 在这里,我们为每个输入图像生成四个旋转,用 Fθ(·) 处理它们,并用自监督损失训练旋转分类器 Rφ。 patch相位置预测的 pipeline 自我监督的与此类似。
3.2.1 Auxiliary loss based on self-supervision
在第一学习阶段,我们通过引入辅助自监督损失将自监督学习引入小样本学习,
More formally, let be the self-supervised loss applied to the set
of training examples in
deprived of their class labels. The loss
is a function of the parameters θ of the feature extractor and of the parameters φ of a network only dedicated to the self-supervised task. The first training stage of few-shot learning now reads
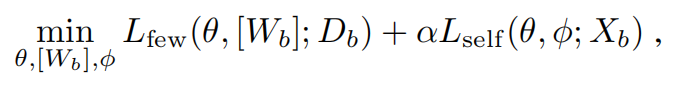
where stands either for the PN few-shot loss (3) or for the CC one (5), with additional argument
in the latter case (hence the bracket notation). The positive hyperparameter α controls the importance of the self-supervised term2 . An illustration of the approach is provided in Figure 1.
For the self-supervised loss, we consider two tasks in the present work: predicting the rotation incurred by an image, [14], which is simple and readily incorporated into a few-shot learning algorithm; predicting the relative location of two patches from the same image [6], a seminal task in self-supervised learning. In a recent study, both methods have been shown to achieve state-of-the-art results [28].
本文选择的小样本分类算法有PN和CC(基于余弦相似性的方法,如Dynamic和Imprinting),本文选择的自监督学习任务有图像旋转预测和图块相对位置预测(图中表示的是图像旋转预测任务)。下面简单介绍以下两个自监督学习任务:
图像旋转预测:作者将原始图像分别旋转0°,90°,180°和270°后输入到特征提取网络Fθ 中,再利用一个旋转分类器R ϕ 预测当前输入图像的旋转角度,损失函数如下:

图块相对位置预测:作者将图像分成3*3的九个图块,将外围的八个图块分别与中间图块级联后,输入到特征提取网络F θ 中,再利用一个相对位置分类器P ϕ 输出当前图块与中间图块的相对位置,损失函数如下:

将小样本分类损失函数与自监督损失函数相加就得到了最终的混合损失函数:

值得注意的是,因为自监督学习任务不需要额外的标注信息,因此对于自监督学习任务可以拓展到其他的大规模无标记数据集中,与带有标注的数据集共同构成一个半监督学习过程,损失函数如下:
算法评价:
本文在本质上讲就是一个多任务融合的方法,将小样本分类任务(用有标签的数据监督学习)与自监督学习任务(用没有标签的数据无监督学习)相结合,两个任务共用一个特征提取网络,一个混合损失函数。在对自监督学习任务进行训练的过程中可以提高特征提取网络的表征能力,而且自监督任务不需要标注信息,因此这也解决了数据集缺少多个任务标注信息的问题,并且可以进一步拓展到半监督学习中,利用大规模的无标注图像对网络进行训练。
论文阅读笔记《Boosting Few-Shot Visual Learning with Self-Supervision》_深视的博客-CSDN博客