文章目录
前言
好久没有冒泡了,是时候来波大的了,也是由于特殊需求,不得不重启关于目标检测的一些内容。既然如此,那么刚好把以前要做的yolo目标检测相关的代码进行复现,并且好好把这个目标检测说清楚一点儿。
此外本文基于Pytorch进行编写,有空后期tensorflow也可以试试。
在阅读这篇博文之前,如果读者真的是还没有接触过这个目标检测的话,我建议可以先看看这几篇文章再来:
在代码部分还参考了原先这篇博文的设计:
嘿~全流程带你基于Pytorch手撸图片分类“框架“–HuClassify
那么本文两个目标:
一. 理论
- 搞清楚什么是目标检测
- 目标检测的重难点
- 相关目标检测算法思想
- 如何设计一个目标检测算法
二. 编码
- voc数据集的细节
- 目标检测网络
- 目标分类网络
- 相关算法
其中的理论部分像我说不会太深入只是快速入门,编码部分的话倒是有很多相关算法的实现。那么编码的话在目标检测部分的网络,我们也是直接使用yolo的网络,当然这里还是会做改动的。这篇博文的更多的一个目的其实还是说搭建一个简单的目标检测平台,这样感兴趣的朋友可以自己DIY,对我本人的话也是有DIY的需求。
那么废话不多说,马上发车了!
目标检测
要说到目标检测的话,那么我们就不得不先说到图片分类了。
因为图片分类在我们的目标检测当中是非常重要的但是二者的区别也是存在的,不过他们之间却有很多相似的地方。
图片分类
图片分类是一个非常经典的问题,给定一张图片然后对这个图片进行分类,它的任务非常简单,并且设计一个这样的网络也非常简单。
你只需要使用一定量的卷积,最后和一定量的全连接网络输出一组大小和类别的最后一个维度一样的tensor就行了,然后使用交叉熵作为你的损失函数。
比如最简单的分类网络:LeNet

class LeNet(nn.Module):
def __init__(self,classes):
super().__init__()
self.feature = Sequential(
nn.Conv2d(3,6,kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.classifiar = nn.Sequential(
nn.Linear(16*5*5,120), # B
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,classes)
)
def forward(self,x):
x = self.feature(x)
x = x.view(x.size()[0],-1)
x = self.classifiar(x)
return x
def initialize_weights(self):
#参数初始化,随便给点权重,这样的话会加快一点速度(训练)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
我们只需要输入一张图片就阔以得到这张图片的类别。
但是这还是远远不够的。
目标检测
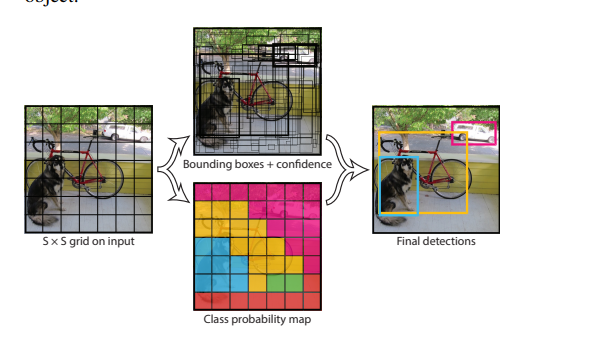
目标检测则是在图片分类的基础上,我们还需要知道我们对应的一个物体的位置,比如下面这张图:

我们知道这是一只猫,但是在图片场景当中并不是只有一只猫,猫只是图片当中的一个很明显的特征,如果做图片分类的话,你说这个是猫可以,但是我说这是个草貌似也可以。所以现在的任务是我不仅仅要知道这个图片有猫,我还要知道这个猫在图片的位置。

单目标检测
现在我们假设,我们的图片只有一个物体,就如上面的图片一样。那么如果我们需要想办法让神经网络得到这样一个框的,当然在此基础上,我们还需要得到对应的概率,也就是,如果图片只有一个目标的话,我们只需要在原来的基础上想办法多生成一组对应的框的坐标就可以了。也就是说,我们以上面的LeNet网络为例子。我们可以这样干。
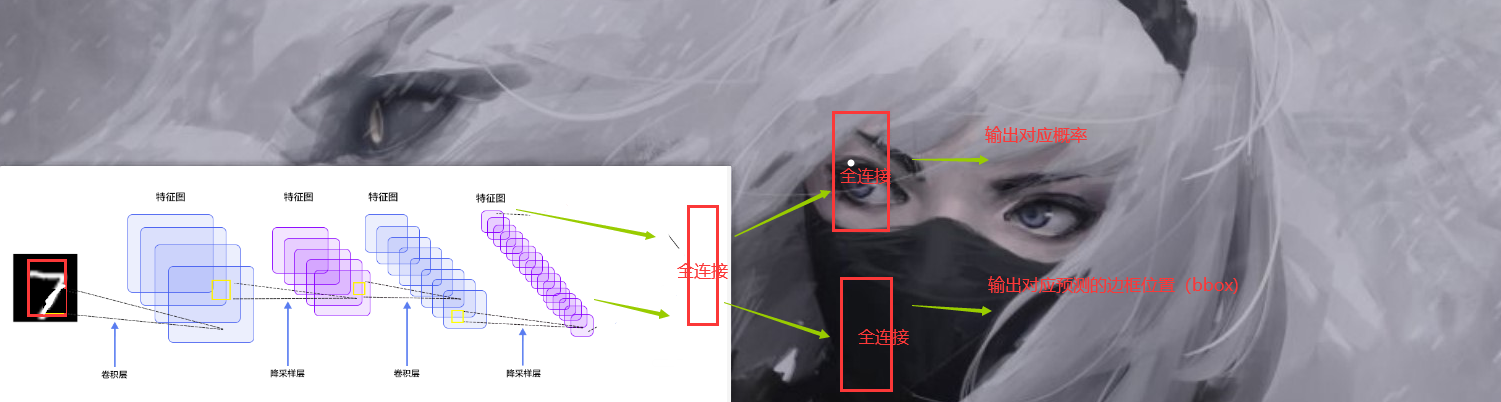
我们只要把原来的那个直接输出概率的那一个全连接层拆掉,然后再来几个全连接层之后分别预测就完了。
至于损失函数,这也好办,一个是交叉熵得到Loss1 还有一个是求方差,求对应的框的点和标注的框的误差就完了得到Loss2 之后Loss=Loss1+Loss2
多目标检测
然而理想是很丰满的,但是现实很残酷。现在的图片当中往往都是有多个目标的,而且哪怕是同一个目标,在一张图片当中也可能有多个,那问题不就尴尬了,比如下面的图片:

所以我们需要解决这个问题。
问题分析
首先我们来想想,我们现在面临的问题,首先对于一张图片,对送进神经网络的图片来说(假设数据集不是我们 自己搞的)我们是不知道当前这个图片它是有几个目标的,所以如果是按照咱们先前那个对LeNet的改动的话,我们是压根就不知道要生成几个框,做几个概率的预测的。假设我们知道了,或者说我们一股脑直接生成一堆框,那么我们需要如何筛选这些有用的框出来?并且我们怎么区别这些框对应的类别是啥?最后我们的损失函数又要怎么设计?
那么如果我们能够找到一种方式能够搞定上面的问题,那么多目标检测应该就能够实现了,换句话说能够通用的目标检测算法就ok了。
滑动窗口
前面分析了我们如果想要实现那个多目标检测,我们需要解决的问题。那么第一个问题,如何生成框。回到一开始的方式,我们是直接输入了一张图片,然后,对这张图片生成一个框,然后做预测等操作,那么既然如此,那么我就直接这样,我把一张图片直接分成一个个区域,相当于截图一样,一个一个区域截图,然后分别送进神经网络。然后你懂的,我们套用刚刚提出的方法。

也就是下面这样
我可以生成不同的滑动窗口,然后疯狂搞。
理论上只要电脑不冒烟,我就可以一直搞。只要效率显然…
所以还需要优化一下。
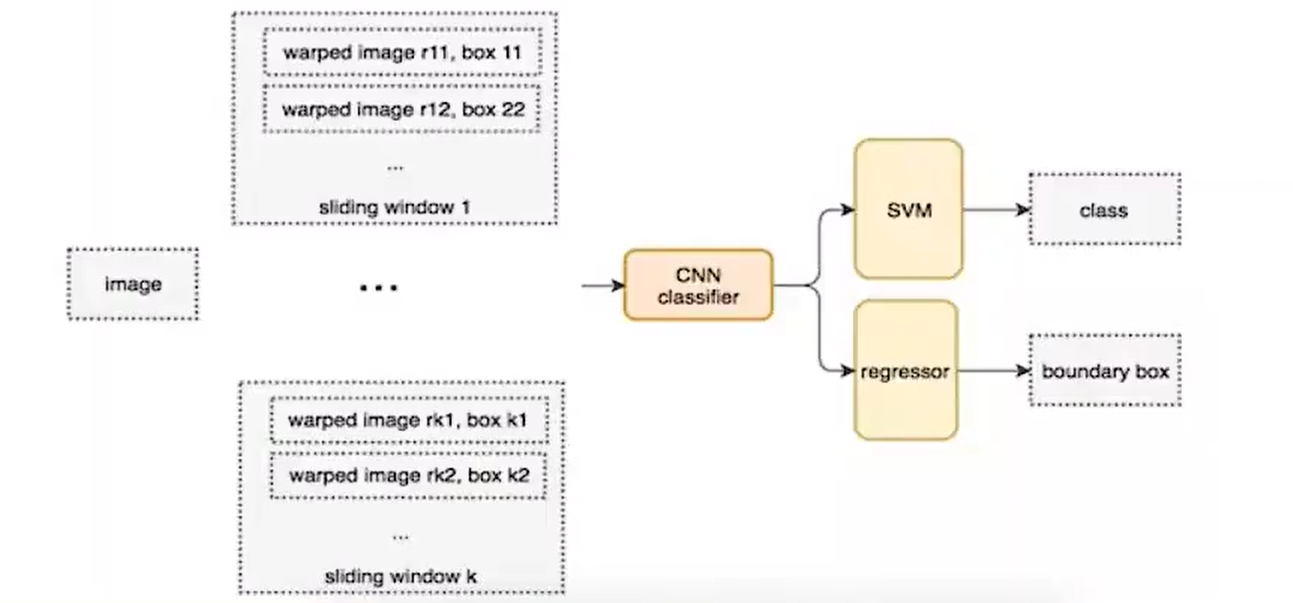
RCNN
那么这个时候,你可能会想了,刚刚的问题难度在于我们很难去得到这些框,因为做分类对我们来说还是非常简单的事情,但是做检测,偏偏有个预测框很难弄。如果我们可以直接得到一堆候选框,然后对每一个框所属的类别进行预测之后再采用某一种方法去筛选出合适的框不久变得简单了嘛。
那么这个时候RCNN出现了,在2014年的时候,那个时候我应该还是个小学生。它的流程是这样的:
- 对于一张图片,找出默认2000个候选区域
- 2000个侯选区域做大小变换,输入AlexNet当中,得到特征向量 [2000,4096]
- 经过20个类别的SVM分类器,对于2000个候选区域做判断,得 到[2000,20]得分矩阵
- 2000个候选区域做NMS,取出不好的,重度高的一些候选 区域,得到剩下分数高,结果好的相
- 修正候选框,bbox的回归微调
那么现在既然提到了RCNN,那么我们现在就不得不先提到两个概念了,第一是IOU,第二是NMS算法也就是那个筛选算法。
不过在这里我先说一些IOU,因为NMS在代码阶段会详细介绍,我们需要手动实现这个算法,当然IOU也需要,但是它非常简单。
就是这个东西

我们可以用这个玩意来衡量这两个生成的框是不是重合了,重合了多少,如果重合太多的话,是不是说他们两个框都在预测同一个物体,那么我们就可不可以把概率低的给干掉。而这个的话其实也是NMS的思想,具体还是看下文。
那么这里解决了可以自动生成框的问题,但是这里的分类器用的还是SVM,并且这个SVM肯定也是需要先训练好的,不然很难完成分类呀。而且在训练SVM的时候,我们是把经过了一个神经网络的数据给SVM的,那么意味还需要对AlexNet做处理,需要缓存很多中间数据然后训练。
而且每一个框都要进入神经网络,2000个要进去似乎也没有比暴力好到那儿去。
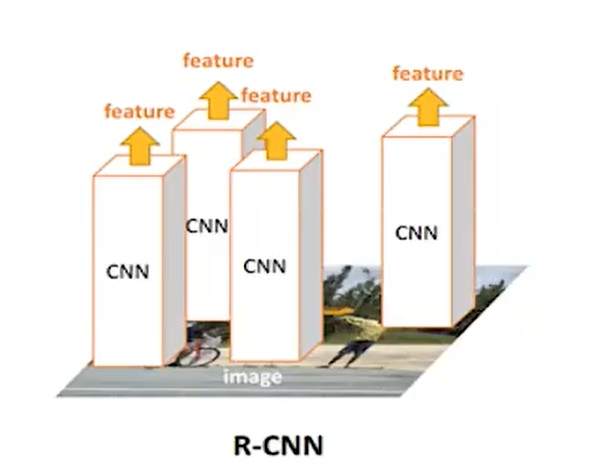
SPPNet
前面说了RCNN,其实最大的一个改进相对于滑动窗口来说,似乎就是多了一个方式去生成候选框。实际上后面那些SVM我们也未尝不可以和AlexNet直接合并成一个大网络然后对2000个候选框做分类,而不是分开来。
但是最大的问题并不是这个,问题在于我们还是需要进入2000次卷积。
那么有没有办法可以减少卷积咧,有SPPNet!
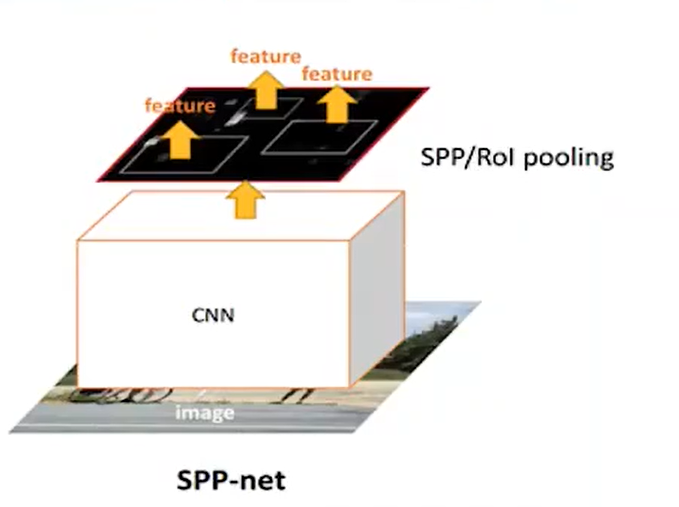
首先候选框还是咱们RCNN那种方式提取出来的,但是它直接把一张图片输入进一个卷积里面。
然后得到一个特征向量,之后这个特征向量里面包含了原来的候选框的信息,他们之间存在这样的映射关系:
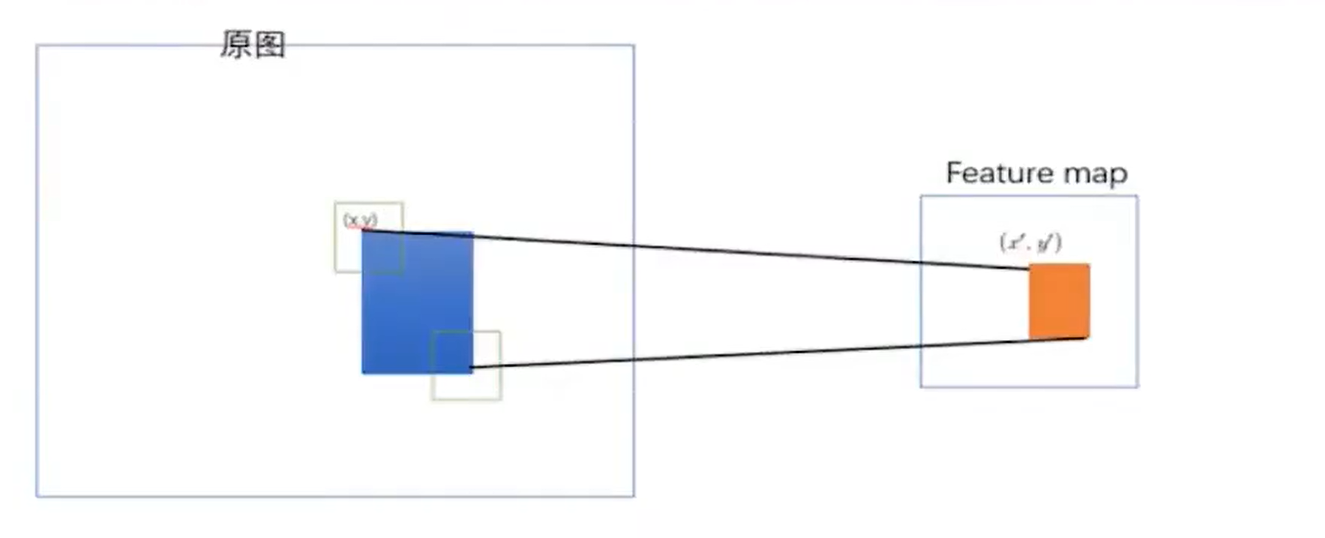
这个映射关系的不是咱们的重点,这里就忽略了,感兴趣的可以自己去了解,不够这个拿到feature map 绝对是目标检测史上最重要的一点之一!不过在这里还没有太大体现。
那么后面的操作其实就和RCNN类似了,只是中间又加了一些池化等等操作
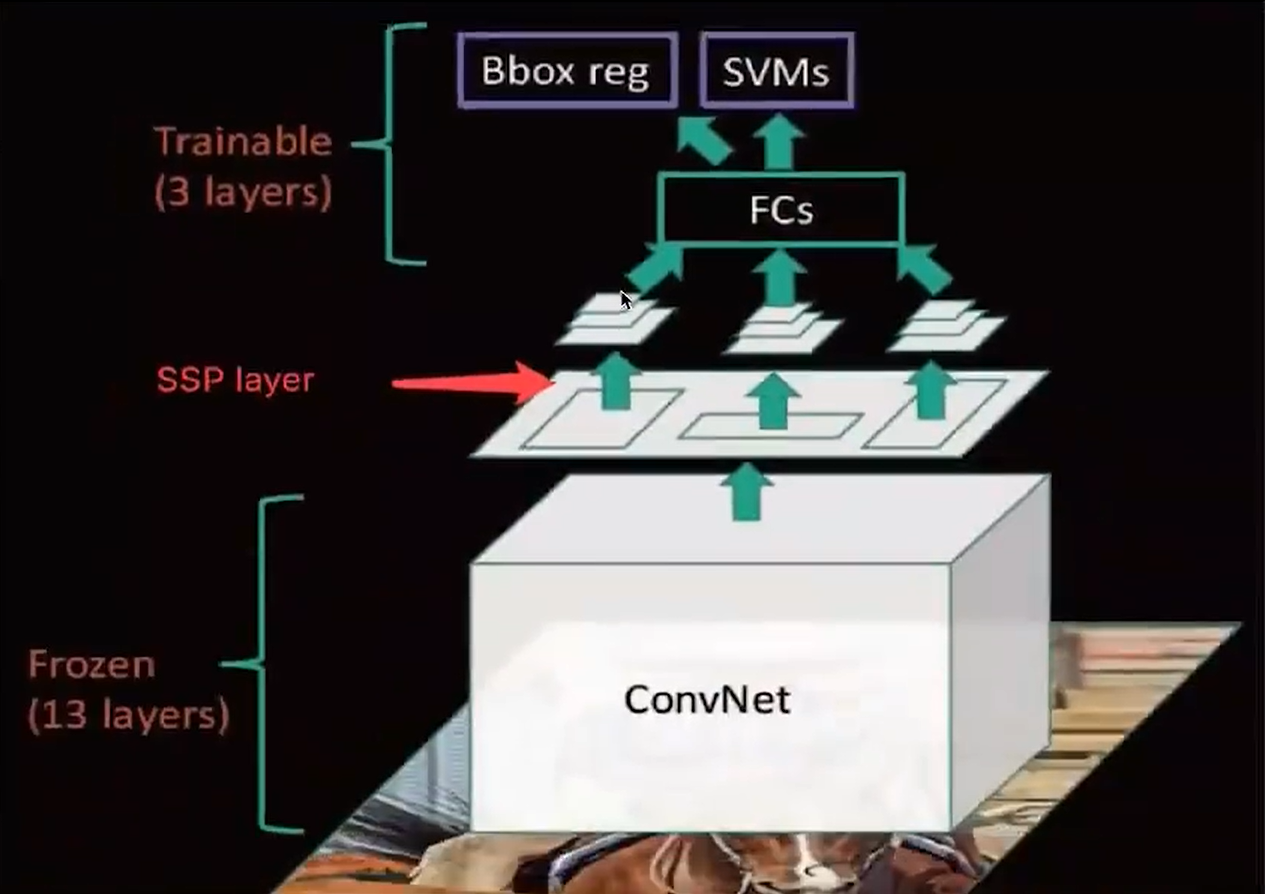
至于缺点:
1. 训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
2. 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器,SPPNet)反向传播效率 低
Fast-RCNN
当我把标题单独放在外面的时候,我想你应该知道了这玩意的重要性。
来我们直接看到整个图:
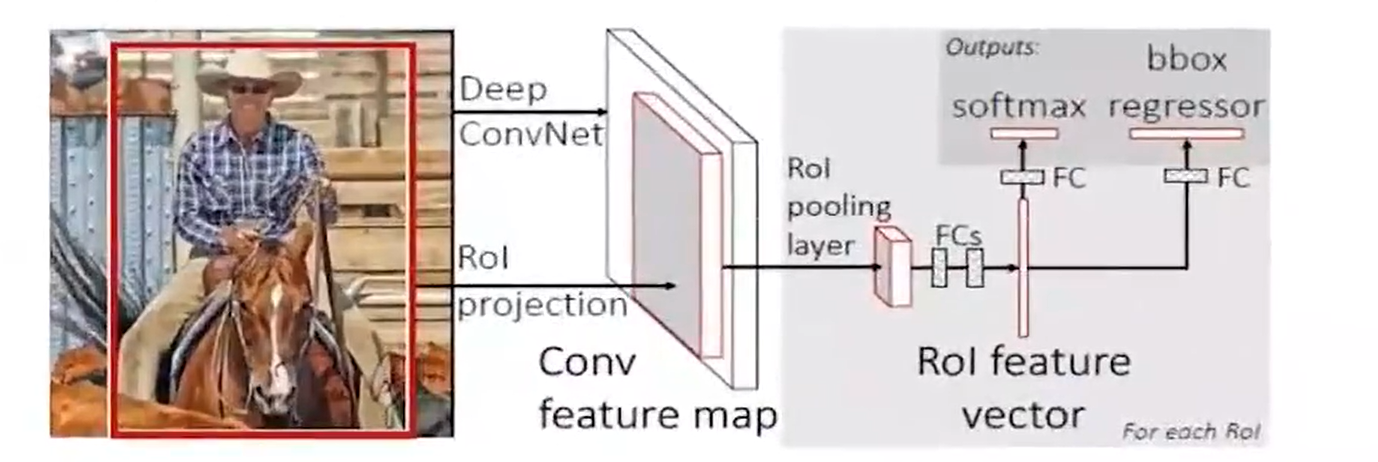
前面的部分其实和SPPNet很像,也就是一个卷积,但是后面全部变成 net,这个好像有点像咱们一开始瞎扯提到的方式了,也就是在后半部分。不过有点可惜的是总体上FastRCNN 的改进其实是把SPPNet后面的东西改了,前面的候选框其实还是使用RCNN的那一套机制,也就是SS算法。
不够尽管如此,fast rcnn 总算是和咱们现在的目标检测算法的样子有点像了,因为我们终于废弃了SVM,终于让我们的神经网络去做更多的事情了。
并且提到了咱们的多任务损失,而且不用把网络拆来了训练了,而是可以做到端到端了。
并且速度有了很大的提升
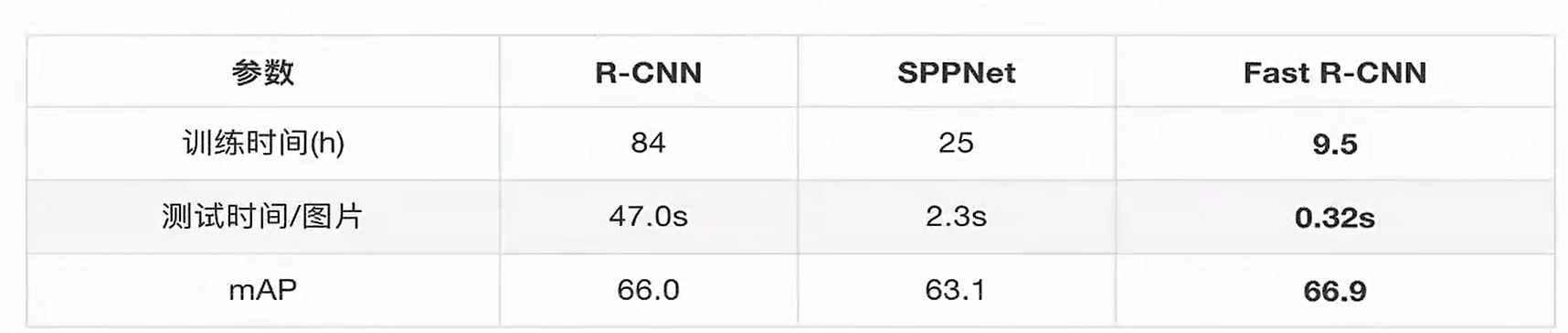
之后它的网络图是这样的:
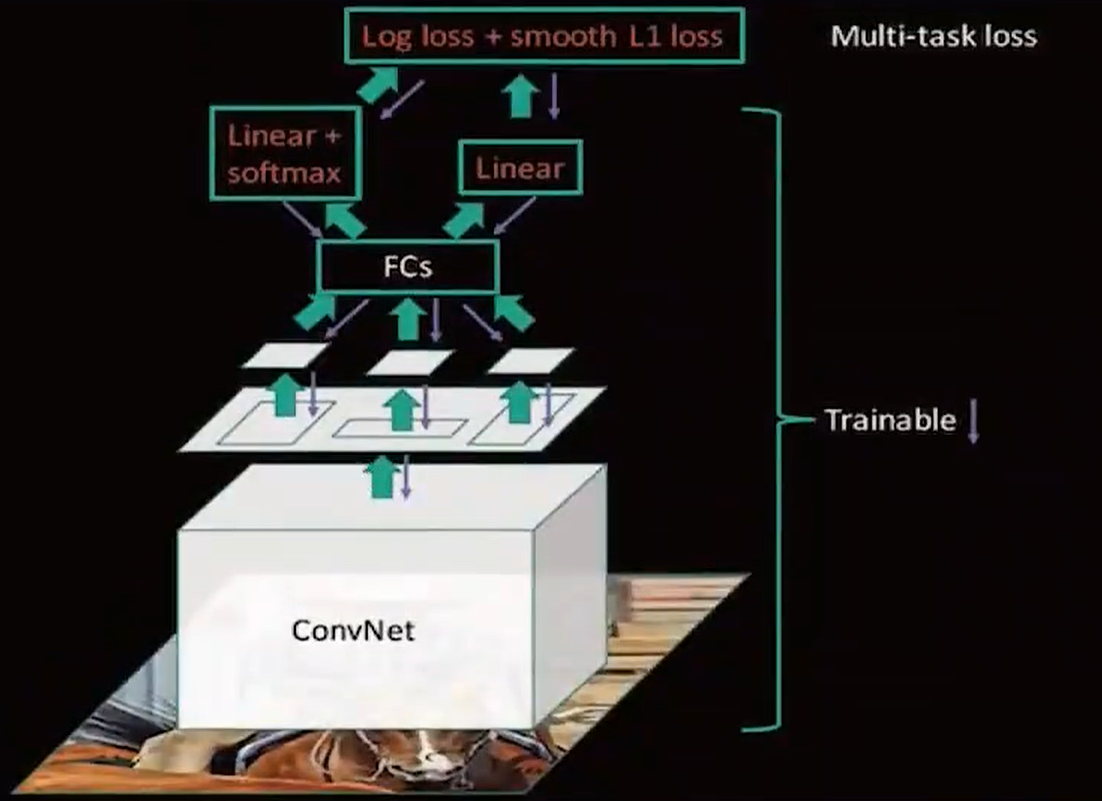
那么虽然已经很快了,那么还有办法嘛?原来RCNN 可是2000个候选区域啊。能不能缩减!有没有办法?
(这里面还有很多细节没有提到,需要读者自行搜索,不过不影响本文观看)
答案是有!
Faster RCNN
前面我们的FastRCNN 已经让神经网络做了很多事情了,那么为什么不能把候选框的提取也做了,让神经网络做到更多的事情?并且还有哪些东西是可以加强改进的?feature map 能不能利用起来?
嘿!还真能。
我们直接在feature map上面做提取,在上面生成候选区域,然后再执行后续操作,后续操作和咱们fast rcnn是一样的,我们只需要对这些候选框和分类器处理。于是我们的网络结构就变成了这样
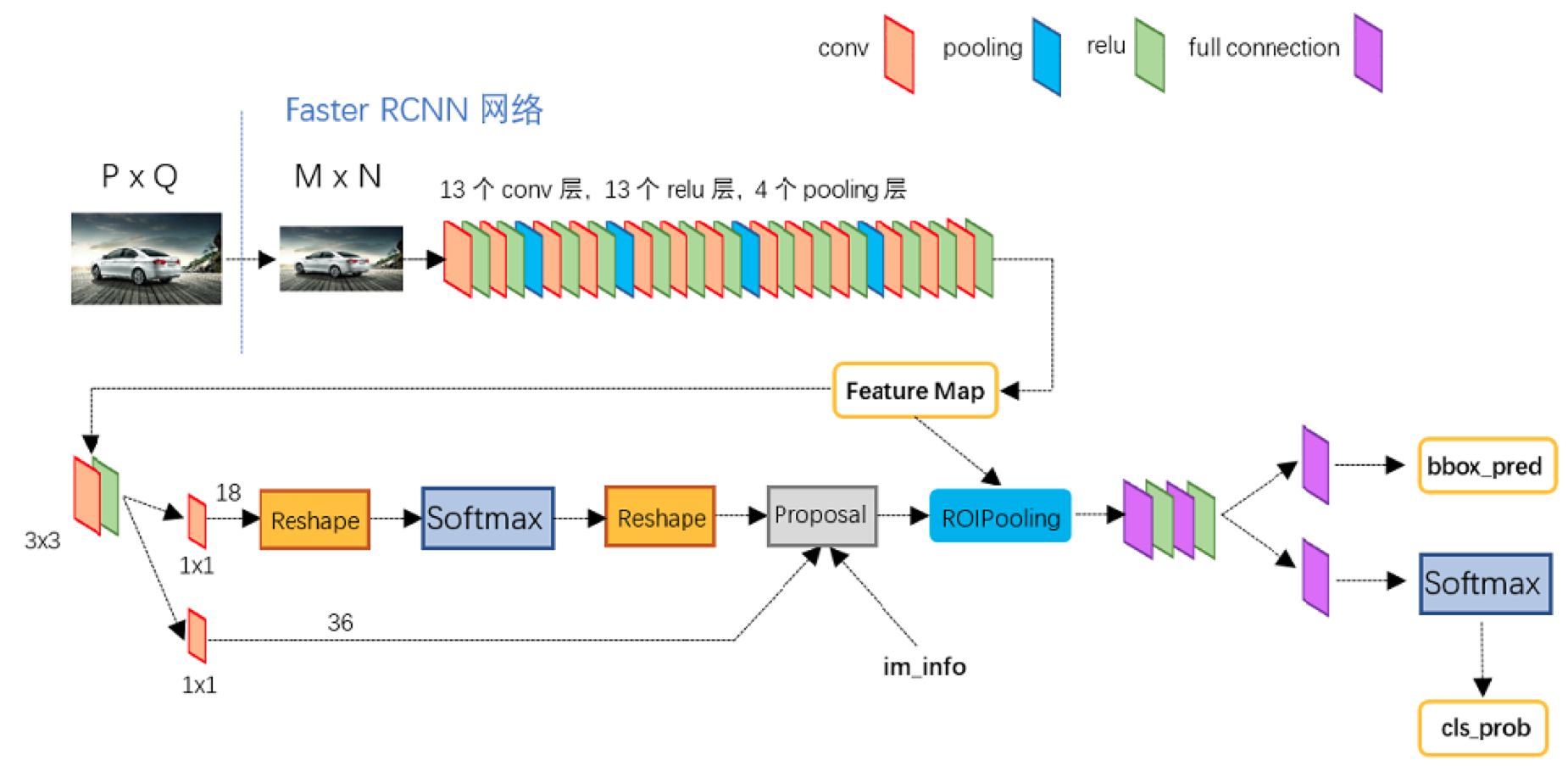
在feature后面提取的网络叫做RPN
RPN 工作流程
说到这个玩意咱们就必须提一下,因为这个东西的工作流程绝对是非常重要的,这意味着我们可以做出更大的改进在后面!
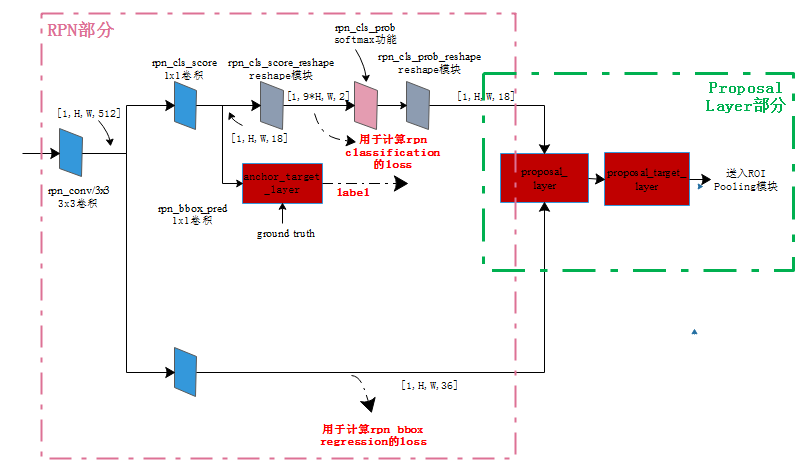
我们知道它的工作地方实在feature map上面
那么他如何工作呢。
这里引入一个名称叫做anchor 其实也就是bbox,那个预测框。
他是这样的,在那个feature map 的基础上,每一个网格,都会生成9个框,假设那个特征是20x20 的那么他有9个就是20x20x9 如果要具体表示的话,xmin,ymin,xmax,ymax(左上角,右下角)那就是20x20x36的张量
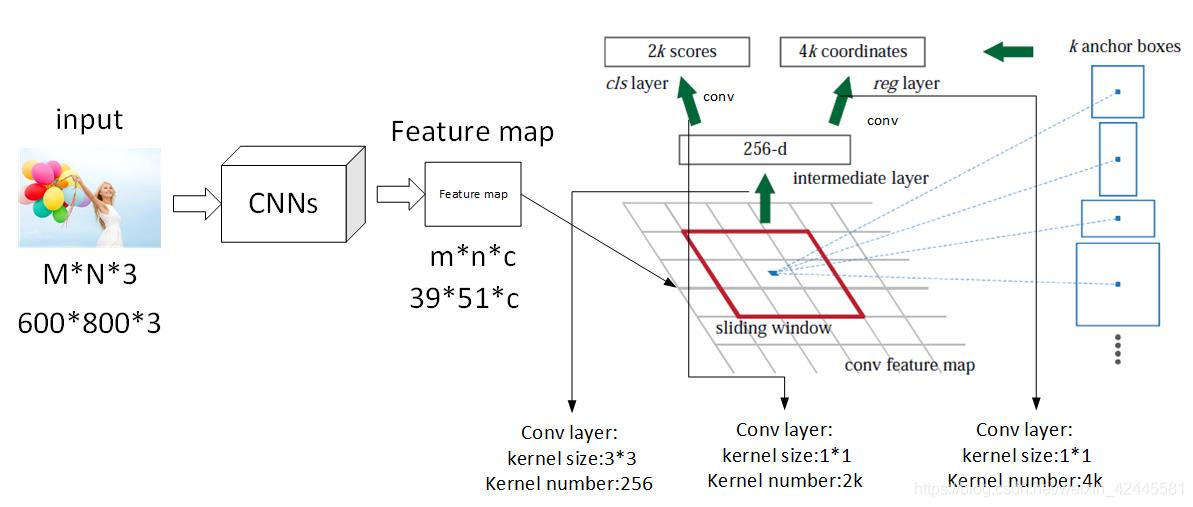
那么这里为什么是9个呢,因为是这样的,原作者设计了三种比例三种大小的样式,因为图片当中物体的大小是不一样的。
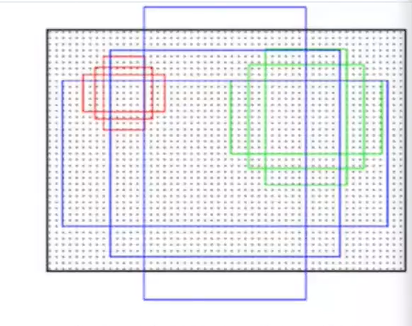
那么刚好对应的就是9个组合。之后的部分我就不细说了。
Yolo
那么到这里,你可能又有疑问了,那个RPN一样的网络能不能放在featur map 前面呢?如果我一开始就指定好图片的网格,然后不同的网格去生成候选框会怎么样?
没错大名鼎鼎的yolo出来了:(这里是v1)
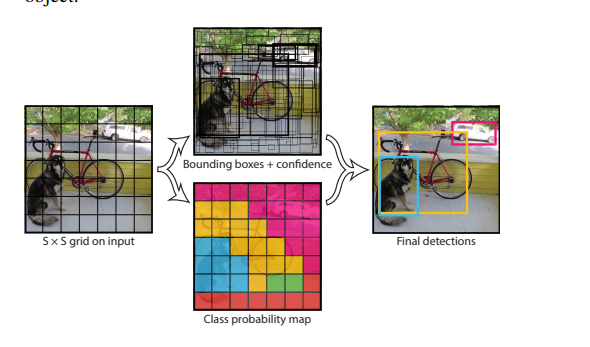
我先直接这样认为分成7x7的格子然后每个格子产生候选框,这里是2个候选框。
之后得到7x7x30的张量.
这里解释一下30里面包含了啥。
这里面存储了 两大类信息。
第一个 是 边框信息,起点,宽高,可信度。
第二个是 类别的条件概率,这里主要是20个类。
之后我们通过NMS对这些候选框进行筛选。
然后进入损失函数,这部分我们后面说,它的损失函数是这样的

我们接下来要自制的目标检测框架其实也是基于yolov1的。
小结
那么对于理论部分我们就先到这里,这里面的话还是有很多细节是没有说到的,例如Fast rcnn 里面,我们NMS处理以后,我们的那些剩下的框虽然是知道了所属的分类,但是我们回归的时候我们是和那些手动标注的框进行回归?这部分我没有说,由于篇幅问题,这部分也是需要读者自行探索,其实读者也可以大胆猜测一下和IOU有没有关系咧?此外还有其他的优秀算法没有介绍到,比如SSD等等。
当然前面的大部分内容只是做了解即可,因为更加完整的将在代码部分进行。
编码
接下来我们将针对yolov1 算法进行实现然后将其封装进去咱们自己搭建的平台。
那么对我们的编码实现里面最主要的其实有三个大点:
- 图片数据怎么处理,怎么对图片进行预处理
- IOU, NMS 算法的具体实现
- 损失函数的设计
首先是咱们的第一点,对图片是否需要,如何进行预处理。
神经网络实现
我们这边的话是打算直接集成yolov1的神经网络结构。

所以的话我们需要先编写神经网络。但是呢,为了更好地提高网络识别的精度和训练效率,我们这边还要考虑预训练一个神经网络模型。
所以为了实现这个效果我们需要对这个网络做一点点的改动,提取出一个骨干网络出来。
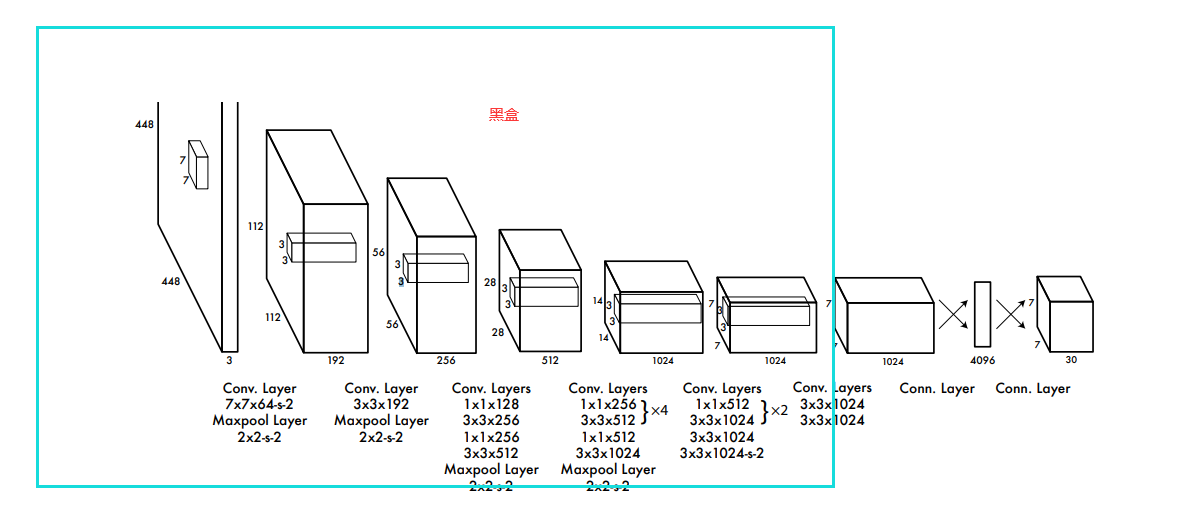
其中BackBone就是我们的核心网络,也就是其中的10几个卷积,后面两个一个是特征提取网络一个是我们用于目标识别的网络。我们预训练是训练特征提取网络,这个网络是依托与骨干网络的。他们之间的关系是这样的:

特征提取网络其实就是在骨干网络的基础上用于分类,这样一来就得到了权重,当我们训练目标检测网络的时候,我们可以把先前预训练的特征网络当中的骨干网络的权重提取出来作为初始化权重,这也就是迁移学习。
骨干网络
import torch.nn as nn
import torch
from collections import OrderedDict
class Convention(nn.Module):
def __init__(self,in_channels,out_channels,conv_size,conv_stride,padding,need_bn = True):
"""
这边对Conv2d进行一个封装,参数一致
但是多加了LeakReLU,和归一化,原因不多说了
:param in_channels:
:param out_channels:
:param conv_size:
:param conv_stride:
:param padding:
:param need_bn:
"""
super(Convention,self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, conv_size, conv_stride, padding, bias=False if need_bn else True)
self.leaky_relu = nn.LeakyReLU()
self.need_bn = need_bn
if need_bn:
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
return self.bn(self.leaky_relu(self.conv(x))) if self.need_bn else self.leaky_relu(self.conv(x))
def weight_init(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class BackboneNet(nn.Module):
"""
骨干网络,因为那个论文中也提到了预训练的概念
那么这个预训练其实是说训练这个骨干网络,而这个
网络的话其实是7x7x30的前半部分
那个yolo是24卷积+2个全连接得到7x7x1024之后flatten4096
最后变成7x7x30,然后就是NMS,预训练需要先训练一个
分类的网络,所以这部分是不一样的
"""
def __init__(self):
super(BackboneNet,self).__init__()
"""
用于特征提取的16个卷积
"""
self.Conv_Feature = nn.Sequential(
Convention(3, 64, 7, 2, 3),
nn.MaxPool2d(2, 2),
Convention(64, 192, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(192, 128, 1, 1, 0),
Convention(128, 256, 3, 1, 1),
Convention(256, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
nn.MaxPool2d(2, 2),
)
self.Conv_Semanteme = nn.Sequential(
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
)
这里可以看到这个网络啥也没有,就是一个最基本的骨架。
特征提取网络(预训练)
import torch
import torch.nn as nn
from Models.Backbone import BackboneNet, Convention
class YOLOFeature(BackboneNet):
def __init__(self,classes_num = 20):
"""
原文说的就是20个所以咱们也就来个20
:param classes_num:
"""
super(YOLOFeature,self).__init__()
self.classes_num = classes_num
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.linear = nn.Linear(1024, self.classes_num)
def forward(self, x):
x = self.Conv_Feature(x)
x = self.Conv_Semanteme(x)
x = self.avg_pool(x)
x = x.permute(0, 2, 3, 1)
x = torch.flatten(x, start_dim=1, end_dim=3)
x = self.linear(x)
return x
"""
初始化权重
"""
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_normal_(m.weight.data)
m.bias.data.zero_()
elif isinstance(m, Convention):
m.weight_init()
目标检测网络
最后是咱们的目标检测网络。
import torch.nn as nn
import torch
from Models.Backbone import BackboneNet, Convention
class YOLO(BackboneNet):
def __init__(self, B=2, classes_num=20):
super(YOLO, self).__init__()
self.B = B
self.classes_num = classes_num
self.Conv_Back = nn.Sequential(
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 2, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
)
self.Fc = nn.Sequential(
nn.Linear(7 * 7 * 1024, 4096),
nn.LeakyReLU(inplace=True, negative_slope=1e-1),
nn.Linear(4096, 7 * 7 * (B * 5 + classes_num)),
nn.Sigmoid()
)
self.sigmoid = nn.Sigmoid()
"""
batchx7x7x30让最后一个维度对应的类别为概率和为1
"""
# self.softmax = nn.Softmax(dim=3)
def forward(self, x):
x = self.Conv_Feature(x)
x = self.Conv_Semanteme(x)
x = self.Conv_Back(x)
x = x.permute(0, 2, 3, 1)
x = torch.flatten(x, start_dim=1, end_dim=3)
x = self.Fc(x)
x = x.view(-1,7,7,(self.B*5 + self.classes_num))
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
"""
在pytorch当中注释部分的操作属于inplace操作,而且在官方文档当中,明确表明
在多交叉熵当中,pytorch不需要使用softmax,因为在计算的时候是包括了这部分的操作的
并且在yolov1的损失函数当中,计算的类别损失也不是交叉熵
"""
x = self.sigmoid(x)
return x
def initialize_weights(self, net_param_dict):
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_normal_(m.weight.data)
m.bias.data.zero_()
elif isinstance(m, Convention):
m.weight_init()
self_param_dict = self.state_dict()
for name, layer in self.named_parameters():
if name in net_param_dict:
self_param_dict[name] = net_param_dict[name]
self.load_state_dict(self_param_dict)
这里要特别注意我注释的这段代码:
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
接下来我会更加详细地说明
数据集编码
现在我们已经知道了咱们这边的目的有两个,一个是要预训练,一个是要目标检测
预训练数据集
其中咱们的预训练是训练一个基本的过程。
那么在这里的话,其实很简单,我们训练的话我们只需要把那个特征网络拿过来,重点是咱们的这个预训练数据集怎么来。
那么这边的话,如果是老盆友,或者是看来刚刚开头推荐观看的文章的朋友应该知道,这边的话我们可以直接把咱们的HuDataSet拿过来。
首先这个数据集的定义非常简单:
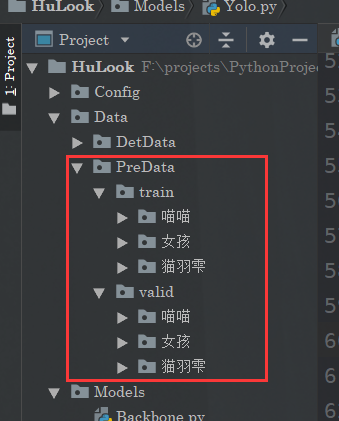
相信你一眼就知道了是怎么一回事。分训练很验证集,然后每个分类的标签放在对应的文件夹下面就可以了。
核心代码如下:
from Config.Config import *
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from Utils.ReaderProcess.ReadDict import ReadDict
class MyDataSet(Dataset):
def __init__(self, data_dir,ClassesName, transform=None):
self.ClassesName = ClassesName
self.label_name = ReadDict.ReadModelClasses(self.ClassesName)
self.data_info = self.get_img_info(data_dir)
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
def get_img_info(self,data_dir):
data_info = list()
label_dict=ReadDict.ReadModelClasses(self.ClassesName)
for root, dirs, _ in os.walk(data_dir): #
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = label_dict[sub_dir]
data_info.append((path_img, int(label)))
return data_info
目标检测数据集
这里的话我们采用VOC数据集,数据集的基本样式其实很简单。

一个是Annotations注解,还有一个是图片
注解里面是xml文件
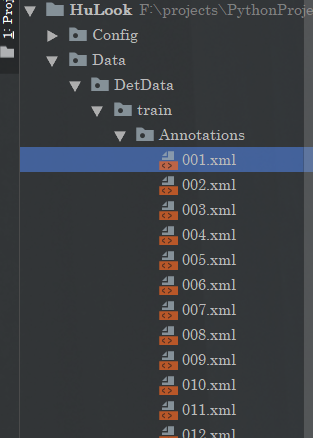
里面包括了类别和手动标注的框的位置。
<annotation>
<folder>images</folder>
<filename>001.jpg</filename>
<path>F:\projects\PythonProject\yolov5-5.0\mydata\images\001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1200</width>
<height>701</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>猫羽雫</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>647</xmin>
<ymin>23</ymin>
<xmax>932</xmax>
<ymax>282</ymax>
</bndbox>
</object>
</annotation>
由于我们需要进行目标检测,但是呢,我们除了要提取里面的标签信息的话,还要把里面的标签(类别,方框)信息进行转化,转化的目的也是为了复合神经网络的输出方便损失函数计算。
VOC标签解析
解析的话很简单,就这个
for object_xml in objects_xml:
bnd_xml = object_xml.find("bndbox")
class_name = object_xml.find("name").text
if class_name not in self.class_dict: # 不属于我们规定的类
continue
xmin = round((float)(bnd_xml.find("xmin").text))
ymin = round((float)(bnd_xml.find("ymin").text))
xmax = round((float)(bnd_xml.find("xmax").text))
ymax = round((float)(bnd_xml.find("ymax").text))
class_id = self.class_dict[class_name]
"""
这里解析存储的是5个值,缩放,归一化后的坐标和对应的类别的标签
"""
coords.append([xmin, ymin, xmax, ymax, class_id])
完整与之配合的代码是这样的:
这里还使用了部分数据增强
import torch
from torch.utils.data import Dataset
import os
import cv2
import xml.etree.ElementTree as ET
import torchvision.transforms as transforms
import numpy as np
import random
from Utils import image
from Config.ConfigTrain import *
class VOCDataSet(Dataset):
def __init__(self, imgs_path="../DataSet/VOC2007+2012/Train/JPEGImages",
annotations_path="../DataSet/VOC2007+2012/Train/Annotations",
is_train=True, class_num=Classes,
label_smooth_value=0.05, input_size=448, grid_size=64): # input_size:输入图像的尺度
self.label_smooth_value = label_smooth_value
self.class_num = class_num
self.imgs_name = os.listdir(imgs_path)
self.input_size = input_size
self.grid_size = grid_size
self.is_train = is_train
self.transform_common = transforms.Compose([
transforms.ToTensor(), # height * width * channel -> channel * height * width
transforms.Normalize(mean=(0.408, 0.448, 0.471), std=(0.242, 0.239, 0.234)) # 归一化后.不容易产生梯度爆炸的问题
])
self.imgs_path = imgs_path
self.annotations_path = annotations_path
self.class_dict = {
}
class_index = 0
"""
读取配置标签
"""
for class_name in ClassesName:
self.class_dict[class_name] = class_index
class_index+=1
def __getitem__(self, item):
img_path = os.path.join(self.imgs_path, self.imgs_name[item])
annotation_path = os.path.join(self.annotations_path, self.imgs_name[item].replace(".jpg", ".xml"))
img = cv2.imread(img_path)
tree = ET.parse(annotation_path)
annotation_xml = tree.getroot()
objects_xml = annotation_xml.findall("object")
coords = []
for object_xml in objects_xml:
bnd_xml = object_xml.find("bndbox")
class_name = object_xml.find("name").text
if class_name not in self.class_dict: # 不属于我们规定的类
continue
xmin = round((float)(bnd_xml.find("xmin").text))
ymin = round((float)(bnd_xml.find("ymin").text))
xmax = round((float)(bnd_xml.find("xmax").text))
ymax = round((float)(bnd_xml.find("ymax").text))
class_id = self.class_dict[class_name]
"""
这里解析存储的是5个值,缩放,归一化后的坐标和对应的类别的标签
"""
coords.append([xmin, ymin, xmax, ymax, class_id])
coords.sort(key=lambda coord: (coord[2] - coord[0]) * (coord[3] - coord[1]))
if self.is_train:
transform_seed = random.randint(0, 4)
if transform_seed == 0: # 原图
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 1: # 缩放+中心裁剪
img, coords = image.center_crop_with_coords(img, coords)
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 2: # 平移
img, coords = image.transplant_with_coords(img, coords)
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 3: # 明度调整 YOLO在论文中称曝光度为明度
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
H, S, V = cv2.split(img)
cv2.merge([np.uint8(H), np.uint8(S), np.uint8(V * 1.5)], dst=img)
cv2.cvtColor(src=img, dst=img, code=cv2.COLOR_HSV2BGR)
img = self.transform_common(img)
else: # 饱和度调整
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
H, S, V = cv2.split(img)
cv2.merge([np.uint8(H), np.uint8(S * 1.5), np.uint8(V)], dst=img)
cv2.cvtColor(src=img, dst=img, code=cv2.COLOR_HSV2BGR)
img = self.transform_common(img)
else:
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
ground_truth = self.encode(coords)
"""
这里传入的coords是经过图片增强,然后归一化之后的
之后的话,我们需要经过encode目的是的为了制作方便后期和pred对比的label
"""
return img,ground_truth
def __len__(self):
return len(self.imgs_name)
def encode(self, coords):
feature_size = self.input_size // self.grid_size
ground_truth = np.zeros([feature_size, feature_size, 10 + self.class_num],dtype=float)
for coord in coords:
# positive_num = positive_num + 1
# bounding box归一化
xmin, ymin, xmax, ymax, class_id = coord
ground_width = (xmax - xmin)
ground_height = (ymax - ymin)
center_x = (xmin + xmax) / 2
center_y = (ymin + ymax) / 2
index_row = (int)(center_y * feature_size)
index_col = (int)(center_x * feature_size)
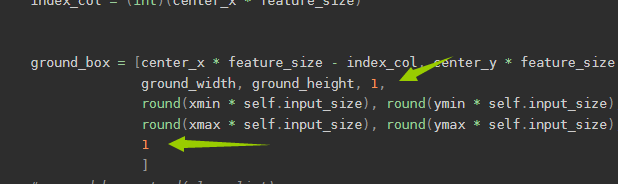
ground_box = [center_x * feature_size - index_col, center_y * feature_size - index_row,
ground_width, ground_height, 1,
round(xmin * self.input_size), round(ymin * self.input_size),
round(xmax * self.input_size), round(ymax * self.input_size),
round(ground_width * self.input_size * ground_height * self.input_size)
]
# ground_box.extend(class_list)
class_ = [0 for _ in range(self.class_num)]
class_[class_id]=1
ground_box.extend(class_)
ground_truth[index_row][index_col] = np.array(ground_box,dtype=float)
return ground_truth
格式转化
现在请把目光转移到这里来:
def encode(self, coords):
feature_size = self.input_size // self.grid_size
ground_truth = np.zeros([feature_size, feature_size, 10 + self.class_num],dtype=float)
for coord in coords:
# positive_num = positive_num + 1
# bounding box归一化
xmin, ymin, xmax, ymax, class_id = coord
ground_width = (xmax - xmin)
ground_height = (ymax - ymin)
center_x = (xmin + xmax) / 2
center_y = (ymin + ymax) / 2
index_row = (int)(center_y * feature_size)
index_col = (int)(center_x * feature_size)
ground_box = [center_x * feature_size - index_col, center_y * feature_size - index_row,
ground_width, ground_height, 1,
round(xmin * self.input_size), round(ymin * self.input_size),
round(xmax * self.input_size), round(ymax * self.input_size),
1
]
# ground_box.extend(class_list)
class_ = [0 for _ in range(self.class_num)]
class_[class_id]=1
ground_box.extend(class_)
ground_truth[index_row][index_col] = np.array(ground_box,dtype=float)
return ground_truth
我们把VOC的格式解析出来了,也做了数据增强之后做了归一化得到了几个标注的框。但是由于在论文当中是这样的:
作者将一张图片划分为了7x7的网格,让每一格子预测两个框,所以我们真实标注的框也需要转化为这种格式,我们需要手动把我们的结果转化为7x7x(10+类别个数)的样子,因为网络最后的输出就是7x7x(10+类别个数)
当然 实际上,我们标注的框转化之后一个格子应该是只有一个物体的,所以这里我们转化的话其实不用那么严格只需要7x7x(5+类别个数)就可以了,但是这里为了对得到,同时方便后面转化,这里还存储了实际上图片的框的坐标(以这个格子为中心)
那么一来在实际计算损失的时候,我们只需要这样:
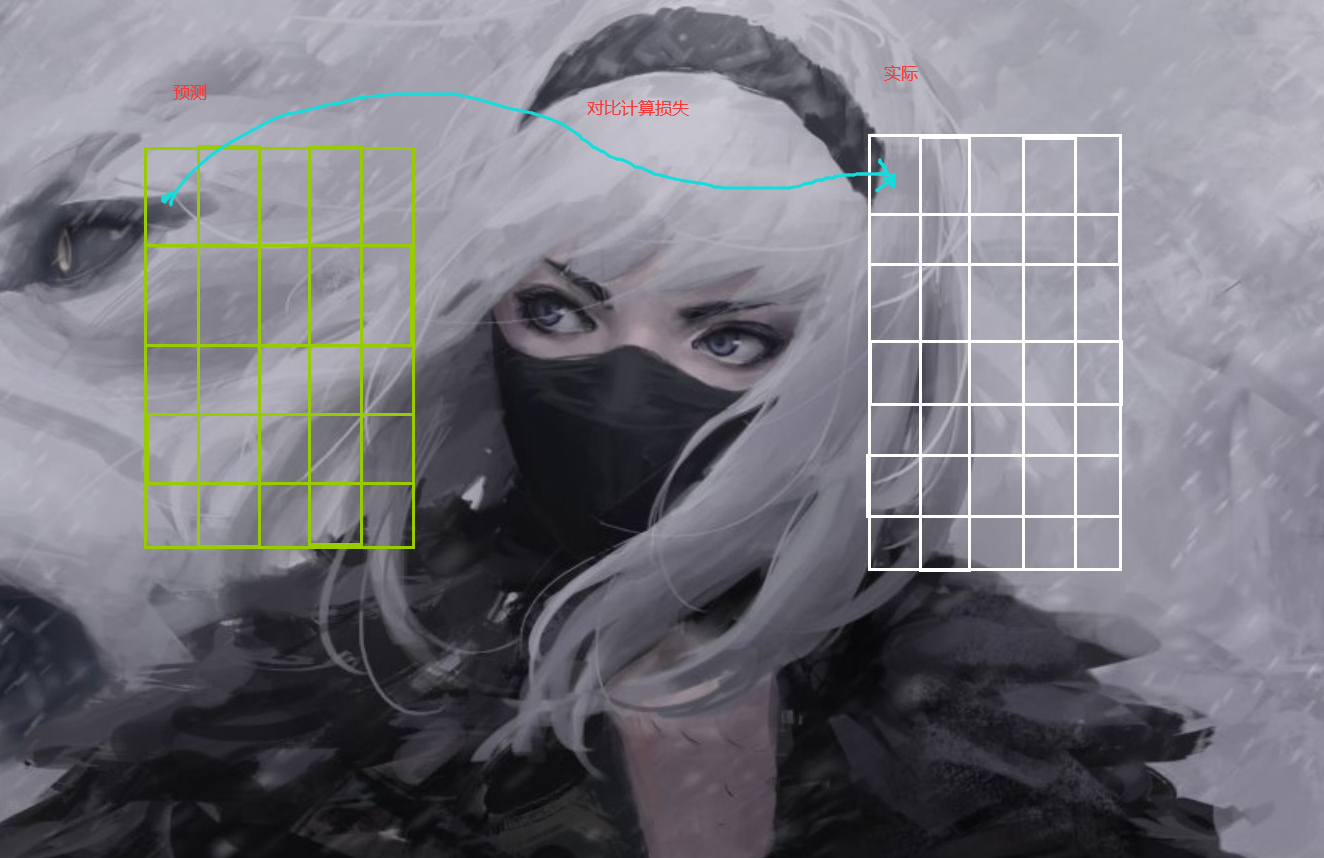
所以因为这个特性,我们需要把标签这样进行转化,方便损失函数计算,而且损失函数的计算是一个一个格子来对比计算的,也就是一个一个的grad cell。
损失函数(目标检测)
之后咱们的损失函数,前面说了为啥要转化标签,那么现在咱们可以来看看损失函数了。

这里提一下正负样本的概念,这里的话其实也简单,就是一个一个格子去对比,然后呢有些格子是没有目标的,但是我们预测的时候每个格子都是预测了两个框的,那么这两个框显然是没有用的,那么这个玩意就是负样本,同理如果对应的格子有目标,但是两个框的IOU不一样(与实际的框)那么IOU低的也算是负样本。
import sys
import torch.nn as nn
import math
import torch
import torch.nn.functional as F
from Config.ConfigTrain import ClassesName
class YOLOLoss(nn.Module):
def __init__(self, S=7, B=2, Classes=20, l_coord=5, l_noobj=0.5, epcoh_threshold=400):
"""
:param S:
:param B:
:param Classes:
:param l_coord:
:param l_noobj:
:param epcoh_threshold:
有物体的box损失权重设为l_coord,没有物体的box损失权重设置为l_noobj
在论文当中应该是正样本和负样本之间的一个权重,因为我们不仅仅要预测有物体的,原来没有物体的也不能有物体
"""
super(YOLOLoss, self).__init__()
self.S = S
self.B = B
self.Classes = Classes
self.l_coord = l_coord
self.l_noobj = l_noobj
self.epcoh_threshold = epcoh_threshold
def iou(self, bounding_box, ground_box, gridX, gridY, img_size=448, grid_size=64):
"""
计算交并比
:param bounding_box:
:param ground_box:
:param gridX:
:param gridY:
:param img_size:
:param grid_size:
:return:
由于predict_box 返回的是x y w h 这种格式,所以我们还是需要进行转换回原来的xmin ymin xmax ymax
也就是左上右下
"""
predict_box = [0, 0, 0, 0]
predict_box[0] = (int)(gridX + bounding_box[0].item() * grid_size)
predict_box[1] = (int)(gridY + bounding_box[1].item() * grid_size)
predict_box[2] = (int)(bounding_box[2].item() * img_size)
predict_box[3] = (int)(bounding_box[3].item() * img_size)
predict_coord = list([max(0, predict_box[0] - predict_box[2] / 2),
max(0, predict_box[1] - predict_box[3] / 2),
min(img_size - 1, predict_box[0] + predict_box[2] / 2),
min(img_size - 1, predict_box[1] + predict_box[3] / 2)])
predict_Area = (predict_coord[2] - predict_coord[0]) * (predict_coord[3] - predict_coord[1])
ground_coord = list([ground_box[5].item() , ground_box[6].item() , ground_box[7].item() , ground_box[8].item() ])
ground_Area = (ground_coord[2] - ground_coord[0]) * (ground_coord[3] - ground_coord[1])
"""
转化为原来左上右下之后进行计算
"""
CrossLX = max(predict_coord[0], ground_coord[0])
CrossRX = min(predict_coord[2], ground_coord[2])
CrossUY = max(predict_coord[1], ground_coord[1])
CrossDY = min(predict_coord[3], ground_coord[3])
if CrossRX < CrossLX or CrossDY < CrossUY: # 没有交集
return 0
interSection = (CrossRX - CrossLX) * (CrossDY - CrossUY)
return interSection / (predict_Area + ground_Area - interSection)
def forward(self, bounding_boxes, ground_truth, batch_size=32, grid_size=64,
img_size=448): # 输入是 S * S * ( 2 * B + Classes)
# 定义三个计算损失的变量 正样本定位损失 样本置信度损失 样本类别损失
loss = 0
loss_coord = 0
loss_confidence = 0
loss_classes = 0
iou_sum = 0
object_num = 0
mseLoss = nn.MSELoss()
for batch in range(len(bounding_boxes)):
for indexRow in range(self.S): # 先行 - Y
for indexCol in range(self.S): # 后列 - X
"""
这里额外统计了三个损失
"""
bounding_box = bounding_boxes[batch][indexRow][indexCol]
predict_box_one = bounding_box[0:5]
predict_box_two = bounding_box[5:10]
ground_box = ground_truth[batch][indexRow][indexCol]
# 1.如果此处ground_truth不存在 即只有背景 那么两个框均为负样本
if (ground_box[4]) == 0: # 面积为0的grount_truth 表明此处只有背景
loss = loss + self.l_noobj * torch.pow(predict_box_one[4], 2) + torch.pow(
predict_box_two[4], 2)
loss_confidence += self.l_noobj * math.pow(predict_box_one[4].item(), 2) + math.pow(
predict_box_two[4].item(), 2)
else:
# print(ground_box[4].item(), ClassesName[int(ground_box[10].item())])
object_num = object_num + 1
predict_iou_one = self.iou(predict_box_one, ground_box, indexCol * 64, indexRow * 64)
predict_iou_two = self.iou(predict_box_two, ground_box, indexCol * 64, indexRow * 64)
# 改进:让两个预测的box与ground box拥有更大iou的框进行拟合 让iou低的作为负样本
if predict_iou_one > predict_iou_two: # 框1为正样本 框2为负样本
predict_box = predict_box_one
iou = predict_iou_one
no_predict_box = predict_box_two
else:
predict_box = predict_box_two
iou = predict_iou_two
no_predict_box = predict_box_one
# 正样本:
# 定位
loss = loss + self.l_coord * (torch.pow((ground_box[0] - predict_box[0]), 2) + torch.pow(
(ground_box[1] - predict_box[1]), 2) + torch.pow(
torch.sqrt(ground_box[2] + 1e-8) - torch.sqrt(predict_box[2] + 1e-8), 2) + torch.pow(
torch.sqrt(ground_box[3] + 1e-8) - torch.sqrt(predict_box[3] + 1e-8), 2))
loss_coord += self.l_coord * (
math.pow((ground_box[0] - predict_box[0].item()), 2) + math.pow(
(ground_box[1] - predict_box[1].item()), 2) + math.pow(
math.sqrt(ground_box[2] + 1e-8) - math.sqrt(predict_box[2].item() + 1e-8),
2) + math.pow(
math.sqrt(ground_box[3] + 1e-8) - math.sqrt(predict_box[3].item() + 1e-8), 2))
# 置信度
loss = loss + torch.pow(predict_box[4] - iou, 2)
loss_confidence += math.pow(predict_box[4].item() - iou, 2)
iou_sum = iou_sum + iou
# 分类
ground_class = ground_box[10:]
predict_class = bounding_box[self.B * 5:]
loss = loss + mseLoss(ground_class, predict_class)
loss_classes += mseLoss(ground_class, predict_class).item()
# 负样本 置信度:
loss = loss + self.l_noobj * torch.pow(no_predict_box[4] - 0, 2)
loss_confidence += math.pow(no_predict_box[4].item() - 0, 2)
return loss/batch_size, loss_coord/batch_size, loss_confidence/batch_size, loss_classes/batch_size, iou_sum, object_num
那么在这里的话我也要说说,刚刚注释的这个代码:
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
它为什么不行了,第一个这个代码本身存在inplace操作。
第二如果真的需要使用交叉熵作为分类的损失函数的话,pytorch内部的交叉熵损失函数自己是计算了softmax的
第三,就是咱们的sunshine函数里面压根不是交叉熵来算类别损失的,人家就是MSE。
之后是关于置信度confidence的计算,这个玩意是表示这里面有没有(这个格子里面)物体的,首先预测的时候,那个值是预测出来的,计算损失的时候,那个c(在有物品的情况下)是等于1的,这个在咱们voc数据集里面可以看到,有物品直接为1
但是呢,实际计算的时候,这个c呢是咱们那个预测框和实际框的IOU。
这个论文当中也有描述。
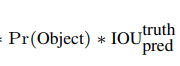
训练部分
接下来是咱们的训练部分,这个呢,有两个一个是预训练一个是实际训练。
预训练得到的一个模型还可以用于图片分类。
预训练
这部分其实很简单就不多说了。
import argparse
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torch.optim as optim
from Models.FeatureNet import YOLOFeature
from Utils import ModelUtils
from Config.ConfigPre import *
from Utils.DataSet.MyDataSet import MyDataSet
from Utils.DataSet.TransformAtions import TransFormAtions
import os
from Utils import SaveModel
from Utils import Log
from torch.utils.tensorboard import SummaryWriter
def train():
ModelUtils.set_seed()
# 初始化驱动
device = None
if (torch.cuda.is_available()):
if (not opt.device == 'cpu'):
div = "cuda:" + opt.device
# 这边后面还得做一个检测,看看有没有坑货,乱输入
device = torch.device(div)
print("\033[0;31;0m使用GPU训练中:{}\033[0m".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("\033[0;31;40m使用CPU训练\033[0m")
else:
device = torch.device("cpu")
print("\033[0;31;40m使用CPU训练\033[0m")
# 创建 runs exp 文件
EPX_Path = SaveModel.CreatRun(0,"pre")
# 日志相关的准备工作
wirter = None
openTensorboard = opt.tensorboardopen
path_board = None
if (openTensorboard):
path_board = EPX_Path + "\\logs"
wirter = SummaryWriter(path_board)
fo = Log.PrintLog(EPX_Path)
# 准备数据集
transformations = TransFormAtions()
train_data_dir = opt.train_dir
if (not train_data_dir):
train_data_dir = Data_Root + "\\" + Train
if (not os.path.exists(train_data_dir)):
raise Exception("训练集路径错误")
train_data = MyDataSet(data_dir=train_data_dir, transform=transformations.train_transform,ClassesName=ClassesName)
valid_data_dir = opt.valid_dir
if (not valid_data_dir):
valid_data_dir = Data_Root + "\\" + Valid
if (not os.path.exists(valid_data_dir)):
raise Exception("测试集路径错误")
valid_data = MyDataSet(data_dir=valid_data_dir, transform=transformations.valid_transform,ClassesName=ClassesName)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=opt.batch_size, num_workers=opt.works, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=opt.batch_size)
# 开始进入网络训练
# 1 开始初始化网络,设置参数啥的
# 1.1 初始化网络
net = YOLOFeature(Classes)
net.initialize_weights()
net = net.to(device)
# 1.2选择交叉熵损失函数,做分类问题一般是选择这个损失函数的
criterion = nn.CrossEntropyLoss()
# 1.3设置优化器
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.09) # 选择优化器
# 设置学习率下降策略,默认的也可以,那就不设置嘛,主要是不断去自动调整学习的那个速度
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.01)
# 2 开始进入训练步骤
# 2.1 进入网络训练
Best_weight = None
Best_Acc = 0.0
for epoch in range(opt.epochs):
loss_mean = 0.0
correct = 0.0
total = 0.0
current_Acc_ecpho = 0.0
bacth_index = 0.
val_time = 0
net.train()
print("正在进行第{}轮训练".format(epoch + 1))
for i, data in enumerate(train_loader):
bacth_index+=1
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# print(inputs.shape,labels.shape)
outputs = net(inputs)
# print(outputs.shape, labels.shape)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum()
# 打印训练信息,进入对比
loss_mean += loss.item()
current_Acc = correct / total
current_Acc_ecpho+=current_Acc
if (i + 1) % opt.log_interval == 0:
loss_mean = loss_mean / opt.log_interval
info = "训练:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}" \
.format \
(
epoch, opt.epochs, i + 1, len(train_loader), loss_mean, current_Acc
)
print(info, file=fo)
if (opt.show_log_console):
info_print = "\033[0;33;0m" + info + "\033[0m"
print(info_print)
loss_mean = 0.0
# tensorboard 绘图
if (wirter):
wirter.add_scalar("训练准确率", current_Acc_ecpho, (epoch))
wirter.add_scalar("训练损失均值", loss_mean, (epoch))
current_Acc_ecpho/=bacth_index
# 保存效果最好的玩意
if (current_Acc_ecpho > Best_Acc):
Best_weight = net.state_dict()
Best_Acc = current_Acc_ecpho
scheduler.step() # 更新学习率
# 2.2 进入训练对比阶段
if (epoch + 1) % opt.val_interval == 0:
correct_val = 0.0
total_val = 0.0
loss_val = 0.0
current_Acc_val = 0.0
current_Acc_ecpho_val = 0.
batch_index_val = 0.0
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
batch_index_val+=1
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
loss_val += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum()
current_Acc_val = correct_val / total_val
current_Acc_ecpho_val+=current_Acc_val
info_val = "测试:\tEpoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format \
(
epoch, opt.epochs, j + 1, len(valid_loader), loss_val, current_Acc_val
)
print(info_val, file=fo)
if (opt.show_log_console):
info_print_val = "\033[0;31;0m" + info_val + "\033[0m"
print(info_print_val)
current_Acc_ecpho_val/=batch_index_val
if (wirter):
wirter.add_scalar("测试准确率", current_Acc_ecpho_val, (val_time))
wirter.add_scalar("测试损失总值", loss_val, (val_time))
val_time+=1
# 最后一次的权重
Last_weight = net.state_dict()
# 保存模型
SaveModel.Save_Model(EPX_Path, Best_weight, Last_weight)
fo.close()
if (wirter):
print("tensorboard dir is:", path_board)
wirter.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--log_interval', type=int, default=10)
# 训练几轮测试一次
parser.add_argument('--val_interval', type=int, default=1)
parser.add_argument('--train_dir', type=str, default='')
parser.add_argument('--valid_dir', type=str, default='')
# 如果是Mac系注意这个参数可能需要设置为1,本地训练,不推荐MAC
parser.add_argument('--works', type=int, default=2)
parser.add_argument('--show_log_console', type=bool, default=True)
parser.add_argument('--device', type=str, default="0", help="默认使用显卡加速训练参数选择:0,1,2...or cpu")
parser.add_argument('--tensorboardopen', type=bool, default=True)
opt = parser.parse_args()
train()
# tensorboard --logdir = runs/train/epx2/logs
这部分还是简单的。
目标检测训练
之后就是咱们目标检测算法的实现,这个其实核心流程都是一样的,就是多了一些东西用来做记录
import argparse
import gc
import torch
from torch.utils.data import DataLoader
import torch.optim as optim
from Models.Yolo import YOLO
from Models.YoloLoss import YOLOLoss
from Utils import ModelUtils
from Config.ConfigTrain import *
from Utils.DataSet.VOC import VOCDataSet
import os
from Utils import SaveModel
from Utils import Log
from torch.utils.tensorboard import SummaryWriter
def train():
ModelUtils.set_seed()
# 初始化驱动
device = None
if (torch.cuda.is_available()):
if (not opt.device == 'cpu'):
div = "cuda:" + opt.device
device = torch.device(div)
torch.backends.cudnn.benchmark = True
print("\033[0;31;0m使用GPU训练中:{}\033[0m".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("\033[0;31;40m使用CPU训练\033[0m")
else:
device = torch.device("cpu")
print("\033[0;31;40m使用CPU训练\033[0m")
# 创建 runs exp 文件
EPX_Path = SaveModel.CreatRun(0,"detect")
# 日志相关的准备工作
wirter = None
openTensorboard = opt.tensorboardopen
path_board = None
if (openTensorboard):
path_board = EPX_Path + "\\logs"
wirter = SummaryWriter(path_board)
fo = Log.PrintLog(EPX_Path)
train_data_dir_image = opt.train_dir_image
train_data_dir_Ann = opt.train_dir_Ann
if (not train_data_dir_image):
train_data_dir_image = TrainImage
if (not os.path.exists(train_data_dir_image)):
raise Exception("训练集路径错误")
if (not train_data_dir_Ann):
train_data_dir_Ann = TrainAnn
if (not os.path.exists(train_data_dir_Ann)):
raise Exception("训练集路径错误")
train_data =VOCDataSet(imgs_path=train_data_dir_image,
annotations_path=train_data_dir_Ann,
is_train=True)
valid_data_dir_image = opt.valid_dir_image
valid_data_dir_Ann = opt.valid_dir_Ann
if (not valid_data_dir_image):
valid_data_dir_image = ValImage
if (not os.path.exists(valid_data_dir_image)):
raise Exception("训练集路径错误")
if (not valid_data_dir_Ann):
valid_data_dir_Ann = ValAnn
if (not os.path.exists(valid_data_dir_Ann)):
raise Exception("训练集路径错误")
valid_data = VOCDataSet(imgs_path=valid_data_dir_image,
annotations_path=valid_data_dir_Ann,
is_train=False)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=opt.batch_size, num_workers=opt.works, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=opt.batch_size)
# 1 开始初始化网络,设置参数啥的
net = YOLO(B=2,classes_num=Classes)
#加载预训练权重
if(PreWeight):
# 1.1 初始化网络
preweight = torch.load(PreWeight)
net.initialize_weights(preweight)
net = net.to(device)
loss_func = YOLOLoss(S=7,B=2,Classes=Classes).to(device)
# 1.3设置优化器
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.09) # 选择优化器
# 设置学习率下降策略,默认的也可以,那就不设置嘛,主要是不断去自动调整学习的那个速度
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.01)
# 2 开始进入训练步骤
# 2.1 进入网络训练
Best_weight = None
TotalLoss = 0.
ValLoss = 0.
ValTime = 0.
Best_loss = float("inf")
for epoch in range(opt.epochs):
"""
下面是一些用来记录当前网络运行状态的参数
"""
train_loss = 0
val_loss = 0
# train_iou = 0
# val_iou = 0
# train_object_num = 0
# val_object_num = 0
train_loss_coord = 0
val_loss_coord = 0
train_loss_confidence = 0
val_loss_confidence = 0
train_loss_classes = 0
val_loss_classes = 0
log_loss_mean_train = 0.
# log_loss_mean_val = 0.
net.train()
print("正在进行第{}轮训练".format(epoch + 1))
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.float().to(device), labels.float().to(device)
outputs = net(inputs)
optimizer.zero_grad()
loss = loss_func(bounding_boxes=outputs, ground_truth=labels,batch_size = opt.batch_size )
batch_loss = loss[0]
batch_loss.backward()
optimizer.step()
log_loss_mean_train+=batch_loss
train_loss+=batch_loss
train_loss_coord+=loss[1]
train_loss_confidence+=loss[2]
train_loss_classes+=loss[3]
# train_iou+=train_iou+loss[4]
# train_object_num+=loss[5]
# update weights
if (i + 1) % opt.log_interval == 0:
log_loss_mean_train = log_loss_mean_train / opt.log_interval
info = "训练:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f}" \
.format \
(
epoch, opt.epochs, i + 1, len(train_loader), log_loss_mean_train
)
print(info, file=fo)
if (opt.show_log_console):
info_print = "\033[0;33;0m" + info + "\033[0m"
print(info_print)
log_loss_mean_train = 0.0
#总体损失
TotalLoss+=train_loss
# tensorboard 绘图
if (wirter):
wirter.add_scalar("总体损失值",TotalLoss,epoch)
wirter.add_scalar("每轮损失值",train_loss,epoch)
wirter.add_scalar("每轮预测预测框损失值",train_loss_coord,epoch)
wirter.add_scalar("每轮预测框置信度损失",train_loss_confidence,epoch)
wirter.add_scalar("每轮预测类别损失值",train_loss_classes,epoch)
# 保存效果最好的玩意
if (train_loss < Best_loss):
Best_weight = net.state_dict()
Best_loss = train_loss
scheduler.step() # 更新学习率
# 2.2 进入训练对比阶段
if (epoch + 1) % opt.val_interval == 0:
"""
这部分和训练的那部分是类似的,可以忽略这部分的代码
"""
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.float().to(device), labels.float().to(device)
outputs = net(inputs)
loss = loss_func(outputs, labels)
batch_loss = loss[0]
# log_loss_mean_val += batchLoss
val_loss += batch_loss
val_loss_coord += loss[1]
val_loss_confidence += loss[2]
val_loss_classes += loss[3]
# val_iou += train_iou + loss[4]
# val_object_num += loss[5]
info_val = "测试:\tEpoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} ".format \
(
epoch, opt.epochs, (j+1), len(valid_loader), val_loss
)
print(info_val, file=fo)
if (opt.show_log_console):
info_print_val = "\033[0;31;0m" + info_val + "\033[0m"
print(info_print_val)
ValLoss+=val_loss
if (wirter):
wirter.add_scalar("测试总体损失",ValLoss, (ValTime))
wirter.add_scalar("每次测试总损失总值", val_loss, (ValTime))
wirter.add_scalar("每轮测试预测框损失值", val_loss_coord, ValTime)
wirter.add_scalar("每轮测试预测框置信度损失", val_loss_confidence, ValTime)
wirter.add_scalar("每轮测试预测类别损失值", val_loss_classes, ValTime)
ValTime+=1
# 最后一次的权重
Last_weight = net.state_dict()
# 保存模型
SaveModel.Save_Model(EPX_Path, Best_weight, Last_weight)
fo.close()
if (wirter):
print("tensorboard dir is:", path_board)
wirter.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=4)
parser.add_argument('--lr', type=float, default=0.01)
#每5个batch输出一次结果
parser.add_argument('--log_interval', type=int, default=2)
# 训练几轮测试一次
parser.add_argument('--val_interval', type=int, default=10)
parser.add_argument('--train_dir_image', type=str, default='')
parser.add_argument('--train_dir_Ann', type=str, default='')
parser.add_argument('--valid_dir_image', type=str, default='')
parser.add_argument('--valid_dir_Ann', type=str, default='')
# 如果是Mac系注意这个参数可能需要设置为1,本地训练,不推荐MAC
parser.add_argument('--works', type=int, default=0)
parser.add_argument('--show_log_console', type=bool, default=True)
parser.add_argument('--device', type=str, default="cpu", help="默认使用显卡加速训练参数选择:0,1,2...or cpu")
parser.add_argument('--tensorboardopen', type=bool, default=True)
opt = parser.parse_args()
train()
# tensorboard --logdir = runs/train/epx2/logs
分类与目标检测
之后就是咱们的后处理阶段,其实也就是咱们的使用部分。
这里也是两个部分,一个是图片分类的实现,还有一个就是咱们目标检测的实现。
图片分类
这里面也是两个部分,一个是预训练模型,进行前向传播,还有一个是进行识别后的处理。
import argparse
from PIL import Image
from Utils.DataSet.MyDataSet import MyDataSet
from Utils.DataSet.TransformAtions import TransFormAtions
import argparse
import torch
from torch.utils.data import DataLoader
from Models.FeatureNet import YOLOFeature
from Config.ConfigPre import *
import outProcessClassfiy
def detect():
ways = opt.valid_imgs
transformations = TransFormAtions()
net = YOLOFeature(Classes)
state_dict_load = torch.load(opt.path_state_dict)
net.load_state_dict(state_dict_load)
if(ways):
test_data = MyDataSet(data_dir=opt.valid_dir, transform=transformations.valid_transform,ClassesName=ClassesName)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
net.eval()
with torch.no_grad():
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
# 输出处理器
outProcessClassfiy.Function(predicted.numpy()[0])
else:
#指定的是单张图片,少给我来奇奇怪怪的输入,这个版本容错很差滴!!!
path_img = opt.valid_dir
if(".jpg" not in path_img):
raise Exception("小爷打不开这图片")
image = Image.open(path_img)
image = transformations.valid_transform(image)
image = torch.reshape(image, (1, 3, 32, 32))
net.eval()
with torch.no_grad():
out = net(image)
outProcessClassfiy.Function(out.argmax(1).item())
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# False表示识别单张图片,True表示多张图片,此时指定路径即可。
parser.add_argument('--valid_imgs',type=bool,default=False)
parser.add_argument('--valid_dir', type=str, default=r'F:\projects\PythonProject\HuLook\Data\PreData\train\猫羽雫\1.jpg')
parser.add_argument('--path_state_dict', type=str, default=r'runs\trainpre\epx0\weights\best.pth')
opt = parser.parse_args()
detect()
之后是咱们的后处理
from Config.ConfigPre import *
def Function(out):
print("类别为:", ClassesName[out])

目标检测
这个也是类似的,但是的话,这里就不去拆什么后置处理器了哈
那么这里要注意的就是编码的时候opencv是不支持中文的,解决方案的话也不难,需要自己准备一个字体文件就完了,当然咱们的项目工程里面是带了一个的。
import cv2
import torchvision.transforms as transforms
from Models.Yolo import YOLO
import argparse
import torch
from Config.ConfigTrain import *
import numpy as np
from PIL import Image,ImageDraw,ImageFont
def iou(box_one, box_two):
LX = max(box_one[0], box_two[0])
LY = max(box_one[1], box_two[1])
RX = min(box_one[2], box_two[2])
RY = min(box_one[3], box_two[3])
if LX >= RX or LY >= RY:
return 0
return (RX - LX) * (RY - LY) / ((box_one[2]-box_one[0]) * (box_one[3] - box_one[1]) + (box_two[2]-box_two[0]) * (box_two[3] - box_two[1]))
def NMS(bounding_boxes,S=7,B=2,img_size=448,confidence_threshold=0.5,iou_threshold=0.0,possible_pred=0.4):
bounding_boxes = bounding_boxes.cpu().detach().numpy().tolist()
predict_boxes = []
nms_boxes = []
grid_size = img_size / S
for batch in range(len(bounding_boxes)):
for i in range(S):
for j in range(S):
gridX = grid_size * j
gridY = grid_size * i
if bounding_boxes[batch][i][j][4] < bounding_boxes[batch][i][j][9]:
bounding_box = bounding_boxes[batch][i][j][5:10]
else:
bounding_box = bounding_boxes[batch][i][j][0:5]
class_possible = (bounding_boxes[batch][i][j][10:])
bounding_box.extend(class_possible)
possible = max(class_possible)
if (bounding_box[4] < confidence_threshold
):
continue
if(bounding_box[4]*possible < possible_pred):
continue
# print(bounding_box[4]*possible)
centerX = (int)(gridX + bounding_box[0] * grid_size)
centerY = (int)(gridY + bounding_box[1] * grid_size)
width = (int)(bounding_box[2] * img_size)
height = (int)(bounding_box[3] * img_size)
bounding_box[0] = max(0, (int)(centerX - width / 2))
bounding_box[1] = max(0, (int)(centerY - height / 2))
bounding_box[2] = min(img_size - 1, (int)(centerX + width / 2))
bounding_box[3] = min(img_size - 1, (int)(centerY + height / 2))
predict_boxes.append(bounding_box)
while len(predict_boxes) != 0:
predict_boxes.sort(key=lambda box:box[4])
assured_box = predict_boxes[0]
temp = []
classIndex = np.argmax(assured_box[5:])
#print("类别:{}".format(ClassesName[classIndex))
assured_box[4] = assured_box[4] * assured_box[5 + classIndex]
#修正置信度为 物体分类准确度 × 含有物体的置信度
assured_box[5] = classIndex
nms_boxes.append(assured_box)
i = 1
while i < len(predict_boxes):
if iou(assured_box,predict_boxes[i]) <= iou_threshold:
temp.append(predict_boxes[i])
i = i + 1
predict_boxes = temp
return nms_boxes
def detect():
transform = transforms.Compose([
transforms.ToTensor(), # height * width * channel -> channel * height * width
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
image_dir = opt.valid_dir
img_data = cv2.imread(image_dir)
img_data = cv2.resize(img_data, (448, 448), interpolation=cv2.INTER_AREA)
train_data = transform(img_data)
train_data = train_data.unsqueeze(0)
net = YOLO(B=2,classes_num=Classes)
state_dict_load = torch.load(opt.path_state_dict)
net.load_state_dict(state_dict_load)
net.eval()
with torch.no_grad():
bounding_boxes = net(train_data)
NMS_boxes = NMS(bounding_boxes,confidence_threshold=opt.confidence,iou_threshold=opt.iou,possible_pred=opt.possible_pre)
font = ImageFont.truetype(r'font/simsun.ttc', 20, encoding='utf-8')
for box in NMS_boxes:
img_data = cv2.rectangle(img_data, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 1)
"""
处理中文
"""
pil_img = Image.fromarray(cv2.cvtColor(img_data, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pil_img)
draw.text((box[0], box[1]),"{}:{}".format(ClassesName[box[5]], round(box[4], 2)),(148,175,100),font)
print("class_name:{} confidence:{}".format(ClassesName[int(box[5])],round(box[4],2)))
img_data = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
if(opt.show_img):
cv2.imshow("img_detection", img_data)
cv2.waitKey()
cv2.destroyAllWindows()
if(opt.save_dir):
cv2.imwrite(opt.save_dir, img_data)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--valid_dir', type=str, default=r'F:\projects\PythonProject\HuLook\Data\DetData\train\images\002.jpg')
parser.add_argument('--path_state_dict', type=str, default=r'F:\projects\PythonProject\HuLook\runs\traindetect\epx0\weights\best.pth')
parser.add_argument("--iou",type=float,default=0.2)
parser.add_argument("--confidence",type=float,default=0.5)
parser.add_argument("--possible_pre",type=float,default=0.35)
parser.add_argument("--show_img",type=bool,default=True)
parser.add_argument("--save_dir",type=str,default="")
opt = parser.parse_args()
detect()
项目获取
那么整个玩意咱们就搞定了,考虑到特殊原因,项目上传至码云:https://gitee.com/Huterox/hu-look
此外由于咱们训练出来的权重文件太大了,所以这理的话就不上传入权重文件了。
当然其实还有一个原因是,咱们的这个权重文件只是用来做测试的,所以实际的意义不大。
不过你以为这就完了嘛,不,接下来是咱们的这个玩意如何使用!
项目使用
预训练数据集
这个的话其实可以考虑省去,我们可以选择直接训练,问题不大。
这个预训练数据集就和前面说的一样,按照类别放在不同的文件夹下面。
例如我这里准备这几种图片:
(我这个是用于测试的数据集所以很小,就几十张图片)
预训练
这部分的话需要打开配置
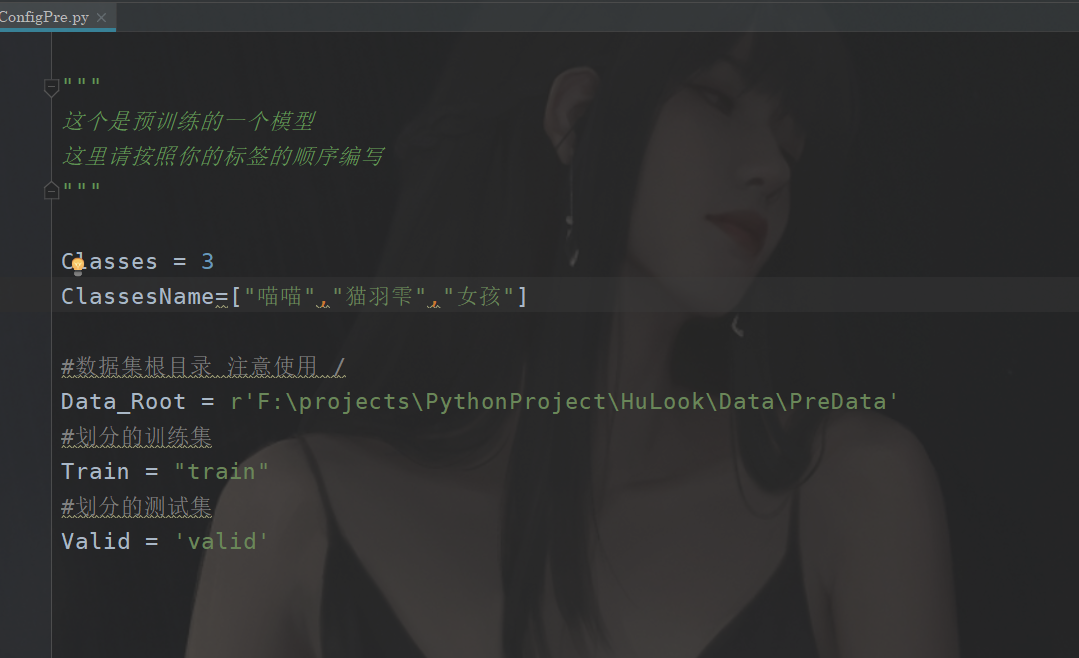
配置一下就好了
当然在训练文件当中也是可以配置的
训练完毕后,你可以打开tensorboad
我们的训练过程当中的数据都在这儿
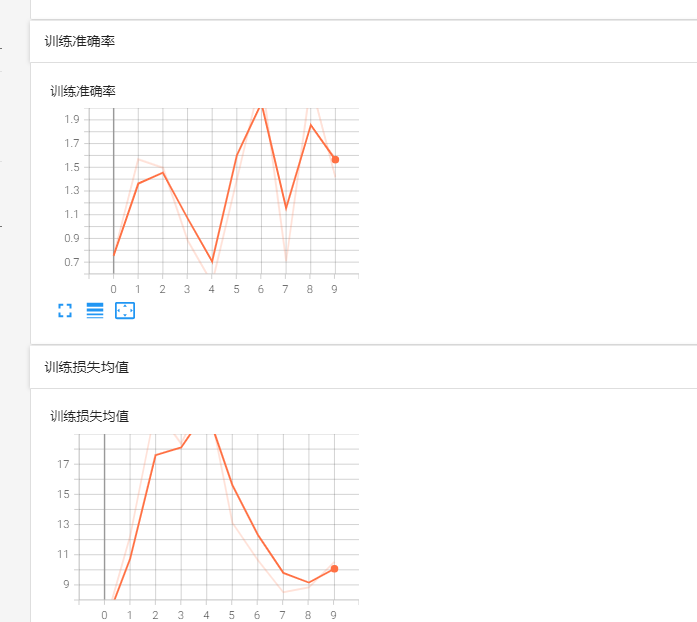
之后的话,预训练完之后,这个网络是具备图片分类功能的,可以使用
进行图片分类。
不过这里注意的是,预训练的只是一个用于分类的网络,目的为了让骨干网络具备权重。所以准备的数据集最好是一张图片里面只有一个目标,因为那玩意只是用来分类的。
目标检测数据集
这部分的话就是咱们的voc数据集,和正常的一样就可以了,咱们可以直接使用labelimg进行标注。
那个怎么使用前面的博客有,那么在咱们这里的话还是需要手动划分一下训练集和验证集的。
然后里面的内容就和voc一样了
训练目标检测
之后就是咱们的训练
还是先到配置处
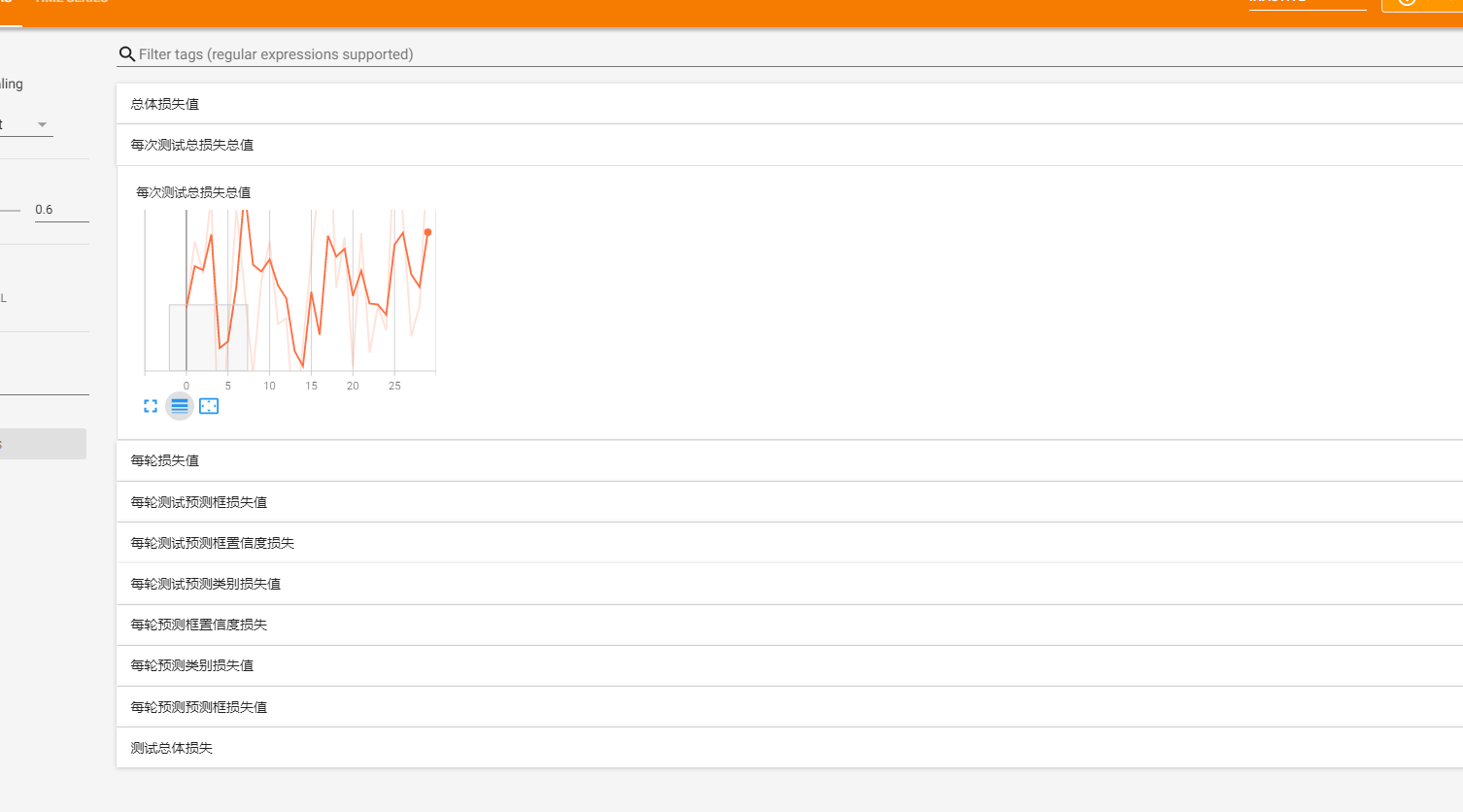
之后打开tensorboard
tensorboard --logdir=runs/traindetect/epx0/logs
识别
这个就不用我说了,打开detect
我们可以看到是识别的情况
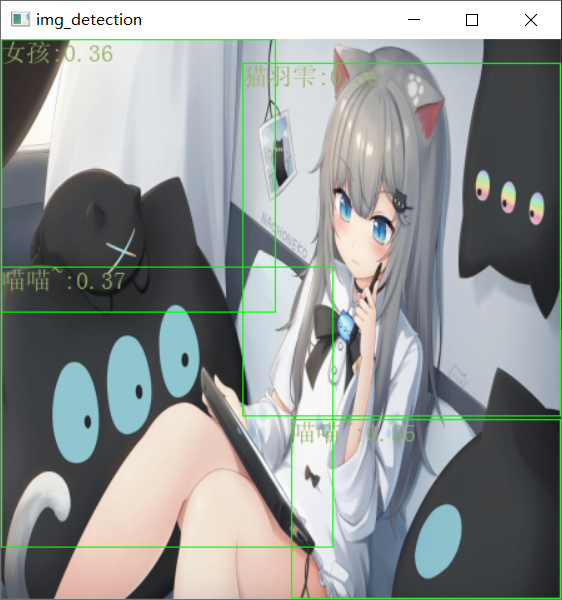
这里的话由于咱们的数据集太那啥了,而且数据集本身设置的就不好,所以导致这里的效果也不好,同时这其实我不上传权重的原因之一,只是用来做测试的。
总结
以上就是全部内容了,全网应该找不到比我这个还全的了吧?如果阔以的话给个start~