4. GWAS分析介绍
大家好,我是飞哥。
前几天推荐了这本书,可以领取pdf和配套数据代码。这里,我将各个章节介绍一下,总结也是学习的过程。
引文部分是原书的谷歌翻译,正文部分是我的理解。
第一部分基础,分为六个章节,分别是:
- 第一章:基因组基础概念(这部分介绍过了,点击进入)
- 第二章:统计分析概念
- 第三章:群体遗传学
- 第四章:GWAS分析介绍
- 第五章:多基因效应
- 第六章:基因与环境互作
今天,介绍第四章的内容,GWAS分析介绍,看一下目录:

主要内容
4. GWAS分析介绍
大家好,我是飞哥。
前几天推荐了这本书,可以领取pdf和配套数据代码。这里,我将各个章节介绍一下,总结也是学习的过程。
引文部分是原书的谷歌翻译,正文部分是我的理解。
第一部分基础,分为六个章节,分别是:
- 第一章:基因组基础概念(这部分介绍过了,点击进入)
- 第二章:统计分析概念
- 第三章:群体遗传学
- 第四章:GWAS分析介绍
- 第五章:多基因效应
- 第六章:基因与环境互作
今天,介绍第四章的内容,GWAS分析介绍,看一下目录:
主要内容

本章节包括:
- 了解全基因组关联研究·
- 掌握基因分型和测序阵列的基础和局限性及其与连锁不定性和填充的关系
- 了解全基因组关联研究研究设计、元分析和数据分析计划
- 了解全基因组关联研究的统计推断、方法和异质性的基本方面
- 掌握质量控制的类型
- 了解NHGRI-EBI GWAS目录以概述全基因组关联研究
- 认识到在祖先、地理、时间,迄今为止全基因组关联研究的人口多样性及其对研究的影响
- 意识到了这一研究领域的未来方向
简介和背景
随着基因分型技术的发展、成本的降低和先进数据分析方法的发展,遗传关联研究的设计在过去几十年中发生了巨大的变化。尽管高通量的全基因组分析现在是标准的,但早期的研究只关注有限数量的“候选”基因座。候选基因研究一词是指这一领域的早期工作,其重点是预先确定的感兴趣的基因座,这些基因座被认为与所研究的性状有关。正如我们在关于基因-环境相互作用的第6章中详细讨论的那样,许多早期候选基因研究由于多种原因存在问题,主要是由于缺乏重复,虽然我们的目标是让这一领域的新研究人员避免犯类似的错误,但我们应该注意到,一些候选基因研究仍然成功地用于各种非行为医学表型。当时,许多性状的极端多基因性和候选基因作为药物靶点的失败(例如抑郁症)让许多人感到真正的惊讶。另一种选择是全基因组关联研究(GWAS),该研究同时测量了数百万个基因位点。
GWAS是目前用于确定单核苷酸多态性(SNP)与表型之间关联的主要方法。正如我们稍后更详细地讨论的那样,GWASs测试了数百万个单独的回归模型,以确定遗传变异和表型之间的关联。回顾第一章,表型可以是单基因性状。
受单个基因内变异的强烈影响。但许多是多基因复杂性状,是多基因变异及其与行为和环境因素相互作用的结果。GWAS的结果显示了每个单核苷酸多态性与特定性状或表型的关联。与候选基因研究相比,GWASs是无假设的,可以在所有基因型区域中寻找关联。正如前面在第1章中所讨论的,GWAS研究了将我们彼此区分开来的多态性。除了单卵(即同卵)双胞胎外,这是0.1%的位点差异是我们与众不同的原因。
由于许多性状是复杂的,并且与多个遗传位点(即多基因)相关,GWAS通常识别出许多遗传变异,每个变异对表型的影响很小。由于影响大小较小,需要非常大的数据源,GWAS发现通常会在多个数据源上进行许多GWAS分析,然后合并到一个元分析中。在GWASs中识别的大多数变体不被认为是生物学上的因果关系,而是由于连锁不平衡(LD),可以识别包含一个或多个生物学功能变体的区域。到2019年初,已经进行了近4000次GWASs,从不可知的角度确定了数千种基因变体[2,3]。已研究的特征包括许多常见的人类疾病,如乳腺癌、阿尔茨海默病和2型糖尿病,但也包括人体测量(身高、体重)和行为特征,如初生年龄或教育程度。
本章介绍了GWAS研究和基本概念。由于GWASs的结果通常是许多实际应用的基础,因此本章对于第二部分的后续应用章节至关重要,包括如何对遗传数据进行质量控制(QC)(第8章)。在本章中,我们将介绍GWAS方法学的基础知识,包括遗传数据收集、研究设计和方法方面的细节,以及纠正多重测试的必要性。接下来,我们将在第8章介绍个体水平和遗传标记水平QC的类型。第4节简要介绍了GWAS元分析和进一步的扩展。最后,我们对NHGRI-EBI GWAS目录,随后是2005年至2018年末GWA发现的简要历史。我们注意到GWAS样本中缺乏各种类型的多样性,例如缺乏祖先和人口多样性,以及受试者在特定国家集中。最后,我们做了一个简短的总结,并指出了未来的研究方向。
GWAS研究分析和元分析
数据分析流程
基因发现不仅是一项智力挑战,也是一项组织和后勤挑战。由于GWA的质量和成功传统上取决于收集大量样本,因此已成立了大型财团,进行独立的GWA,随后由领导该项目的核心小组进行元分析。图4.1描述了GWAS阶段,这可能是现代科学中最大类型的合作努力之一。考虑到所需的广泛专业知识、需要成立的财团以及长期和耗时的投资。这一领域的新研究人员很少会启动自己的独立GWA。然而,了解GWA的构思过程是有用的。
首先从一般可行性分析开始,研究人员需要了解表型、迄今为止研究的内容、测量和先前的遗传力估计或其他GWAS结果(如果可用)。这一研究领域在总结现有结果的在线工具和软件包方面继续蓬勃发展。例如,你可以参考对50多个双生子研究中许多人类性状遗传力的综合分析(见[4])。它还附带了一个名为MaTCH(双胞胎相关性和遗传力的元分析)的web应用程序,可通过http://match.ctglabnl/。还有其他网站,如SNPedia(https://www.snpedia.com/index,php/遗传力),该目录列出了与特定研究相关的遗传力估计值。Ben Neale的实验室还拥有一个令人难以置信的网站,用于检测英国生物库中许多性状的遗传力(http://www.nealelab.is/uk-biobank/).您还可以从复杂性状遗传学虚拟实验室(CTG-VL)生成结果的可视化,包括曼哈顿图和许多其他结果,用于GWAS后分析[5],ttps://genoma.io and http/atlas.ctglab.nI/。
下一步是隔离哪些数据源可能具有您感兴趣的表型,如果适用,组建或联系一个联盟,或获取现有或公开可用的数据(如英国生物银行)。组建一个财团需要花费大量的时间和精力,包括经常等待道德和准入许可,在某些情况下还需要处理付款以使用数据。尽管英国生物银行(约500000个)等大型数据集最近已经面世,但通常会形成大型联合体,将多个数据集组合在一起,以产生尽可能大的样本。在许多情况下,每个数据源的独立分析师负责执行
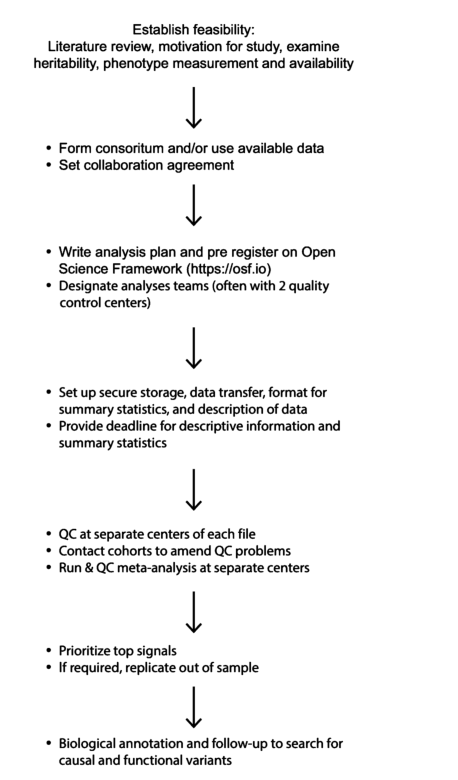
分析步骤:
- 确定可行性,查阅文献,查看遗传力,表型测定方法
- 从实验搜集数据,或者已有的数据,确定合作方案
- 撰写数据分析方案
- 数据存储,转换,分析,描述分析,汇总结果
- QC质控,单独分析和元分析
- 重点查看显著的位点
- 注释,查看结果
GWAS内部,并将结果发送回联合体领导人。这通常与数据的隐私和同意问题有关,如本书最后一部分第l4章所述,GWAS汇总统计的元分析因此是发现与表型相关的遗传变异的最常用方法。由于常见等位基因的遗传效应很小,我们从第一章之前的讨论中了解到,信号检测需要更大的样本量。由于单个GWASs的动力不足,研究人员需要进行元分析并合并多个数据源。
数据分析计划
这部分,主要是如何收集数据,包括设置问卷调查注意事项。还应该注意,应该包括一些协变量。然后常用的数据质控,使用的模型,有时候会考虑家系的作用。
如果您的目标是收集大量样本,请说明如何选择加入联盟和关键截止日期。
然后经常列出详细的样本纳入标准。例如,在我们对人类生殖的研究中,我们还检查了有史以来出生的儿童数量(NEB),只包括那些已经到了生育期结束的儿童(女性至少45岁,男性55岁),并澄清说,我们还希望分析人员将从未生过孩子的个人包括在内。这也是您指定任何祖先要求、相关协变量、基因分型率(>95?)和其他质量控制的地方(另见第8章)。
基因型和插补信息,包括插补前需要应用的任何推荐标记过滤器,我们将很快讨论。在前面提到的示例分析计划中,SNP call rate>95,HWE>10-6,MAF>5%这些价值背后的逻辑将在第8章中详细讨论。
用于关联测试的模型的ear规范。例如,在我们的研究中,我们要求对男性和女性的两种表型(AFB、NEB)的回归模型进行估计,然后合并。例如,一个方程是Y=m+SNP,β+Zy+e。许多研究还经常包括基于家庭的数据,其中82第4章应提供明确的案例说明,以考虑数据中的脆弱性结构或选择家庭成员。我们指定了线性回归模型,其中包括几个协变量(例如,控制人口分层、控制非线性效应的出生队列或任何研究特定协变量)。
为结果指定fle格式。例如,许多人经常选择费用联合体共享格式。!文件命名方案同样重要,因为您将收到数百个不同的文件。
数据交换和安全程序也很重要,最近在欧洲工作的许多人需要遵守GDPR(一般数据保护条例)(见第14章,道德)。
然后,还经常包括荟萃分析的描述。这包括标记排除筛选、基因组控制、显著性阈值以及顶级SNP的报告方式。
每个参与的数据源(在这一研究领域通常称为队列)单独运行分析,或者可以授权访问数据。每个研究的汇总统计结果通常会与特定数据源数据的一些描述性信息一起上传。然后将这些结果结合起来进行荟萃分析。
元分析
元分析是对来自多个独立研究的信息进行统计综合,从而提高功效,进而降低假阳性发现的风险【7】。还建议联合体中的所有研究人员签署一份合作协议,其中包括,例如,在当前联合体发布之前,不要发布该表型的GWAS,GWAS荟萃分析使用所谓的汇总数据,提供回归系数、标准误差、,依此类推,对于遵循预先指定的分析计划的群体中的每个遗传标记。因此,它不是单个级别的数据,而是汇总的汇总结果。我们2016年的生殖行为研究【6】。
例如,涉及一个元分析,它使用来自60多个不同数据源的汇总统计数据。在第8章中,我们描述了如何在个人层面上参与OC,然后再进行GWAS(例如,去除等位基因频率低的变体。插补质量低,等位基因频率与参考样本有很大差异,或由其他地方未复制的特定研究驱动的结果)。GWAS荟萃分析中一个重要且耗时的步骤是第二套质量控制,它基本上是协调各研究的结果。尽管提供了统一的分析计划,但此清理过程可能在初始项目中花费的时间最长,因为分析人员可能使用不同的软件,或者结果中存在其他不一致之处。Winkler等人在GIANT consortium工作的基础上,为meta-OC过程提供了一个优秀的协议。
统计推断、方法和异质性
表型数据
确定数据的类型,以及需要考虑的协变量
GWA研究的核心前提是对特定人群中的大量样本同时进行数百万个假设检验,或者换言之,对每个变量进行一个假设检验。每个遗传关联研究都采用统计推断来确定和量化遗传位点和表型之间的关联强度。关联方法的选择通常取决于表型的性质,以及它是二分型(即二分型)还是定量型(即连续型),但考虑潜在的混杂因素(如gsex、年龄、出生队列)也是常见的。
对于数量或连续特征(例如,初生年龄或体重指数),分析会在表型的连续分布范围内对个体进行比较,通常使用线性回归。在这里,我们比较了基于检验统计量的分布与任何标记无关联的零假设,并考虑了标准误差。删失数据生存模型的其他扩展也越来越可能。对于二元或二元性状,它通常使用逻辑回归来比较高(病例)值和低(对照)值。与典型的logistic模型一样,假设所研究性状的logit变换与等位基因呈线性关系,但通常用优势比来解释。
使用P-values和Z-scores
P-value一般用于单个数据的分析,Z-score可以用于元分析,表示结果。
第2章更详细地阐述了这类研究的统计基础。简而言之,目标是对遗传位点和正在研究的表型之间的每一个真实关联进行统计显著性估计。正如大多数读者所知,正如前面第2章所讨论的,统计显著性通常由p值决定。p值估计获得测试统计值的概率,该值与通过所选统计方法为潜在关联估计的值一样极端(即,在零下)。这并不是一个基因座与一个特征相联系的可能性。当我们进行这种回归时,我们使用t检验等检验统计量来检验特定遗传变异的β参数是否显著不同于零。检验统计量是用来衡量对无效假设支持程度的数据的数值总结。在零假设下,检验统计量可能具有已知的概率分布(例如,x’),或者估计其零分布。回想一下,无效假设是对特定人群之间没有显著差异的假设的统计检验,在GWAS的情况下,是病例和对照之间的差异。任何观察到的差异都归因于采样或实验误差。如果从遗传位点产生的检验统计量值与我们从无效假设中预期的值显著偏离,则有证据表明存在替代性组间存在显著差异(病例组与对照组)或与数量性状存在显著关系。
在荟萃分析中,p值的缺点是不能提供效应大小的总体估计,这一点已被广泛讨论。此外,无法评估数据集之间的异构性。还使用了一个相关的统计数据,即Z分数,它基于Z的平均值;值,即第i次研究的Z值,尽管p值和Z值高度相关,但使用Z值的优势在于,它们考虑了影响的方向,并且您能够引入权重(例如,如果您希望某项特定研究的权重更高或更低)。单核苷酸多态性被标记为或被视为“点击率”,以p值为衡量标准。
如前所述,商定的全基因组显著阈值为p<5×10-8。
这对应于Bonferroni校正,将在下一节中讨论。由于SNP、MAF、LD模式或阵列的变化,全基因组显著性阈值可能因人群而异。在LD较低的人群中,如非洲祖先群体,应使用更严格的阈值[9]。
矫正GWAS结果
常用的方法有:
- Bonferroni correction,一般用0.05/N,或者1/N来确定P值
- 置换检验
- FDR检验
第一种:Bonferroni矫正
DNA微阵列和下一代测序使我们能够检测大量串联基因组位点的相关性。GWAS结果中进行比较的程度称为多重测试问题。这是两种误报(l类错误)的可能性,如果多重比较的校正过于保守或功率不足,则会产生误报(2类错误)。我们测试了整个基因组中数百万个基因变体的关联,但只有很小一部分在全基因组显著性水平上与表型相关。
问题是,当我们进行这么多测试时,我们也面临着仅仅是偶然发现许多强大关联的危险。在GWAS中,对每个遗传位点和表型进行统计检验,以产生检验统计量和相关的p值。如果我们取标准p值0.05.
即使给定的遗传变异与我们的表型无关,我们也有1/20的机会发现显著的关联。这就是所谓的类型1错误或假阳性。由于在GWAS中,我们实际上并行执行了数百万次测试,如果我们采用标准的0.05显著性阈值,我们很可能会获得许多误报。为了解决这个多重测试问题,最常用和最直接的修正是Bonferroni修正。简单地说,我们将所选的显著性阈值(p值)除以所执行的测试数量。如果进行了10次测试,我们只会声明,如果p值小于0.005,结果才是显著的。在基因组的情况下,我们正在测试100万个独立的遗传变异是否存在常见的序列变异,因此,Bonferronicorrected p值的显著性为p<5×10-8。这与统计学中独立性的基本假设有关,或者说你应该从你的样本中得到反映你会在人群中发现。
如果数据中存在最小的依赖性,而您违反了这一假设,则会产生有偏差的结果。GWASs的一个统计问题是,附近基因变体的基因型之间往往存在着很强的相关性。或者换句话说,实际测试100万个遗传变异实际上更像是测试70万到80万个不相关的遗传变异。因此,在GWAS中,采用统计阈值,以p<5×10-8(即p<0.0000000-5)作为全基因组统计显著性的标准,而p<5×10-6通常用于表示“提示性命中”
第二种:置换检验
有人认为,Bonferroni校正过于保守,导致假阴性结果的比例增加,并假设每个基因变异都是独立于其他变异进行测试的,这是独立的。虽然对替代方法的详细解释超出了本介绍性书籍的范围,但还有其他方法可以纠正多次测试。基于排列的测试多次对表型进行排列,然后每次重新计算统计测试,以产生可用于假设测试的经验零分布。
将其视为标签的洗牌可能更为直观。为了计算基于排列的p值,结果度量标签被随机排列或洗牌多次(例如1000-1000000),这有效地消除了基因型和表型之间的任何真正关联。然后对所有置换数据集进行统计测试。
这提供了无关联零假设下检验统计量和p值的经验分布。然后将从观察数据中获得的原始检验统计量或p值与p值的经验分布进行比较,以确定经验调整的p值。基于置换的测试是计算密集型的,尤其是当需要许多置换时,这对于精确计算非常小的p值是必要的[1]。
第三种:FDR
另一种技术是Benjamini-Hochberg错误发现率(FDR),它比Bonferroni校正更保守。它控制所有信号中误报的预期比例,FDR值低于固定阈值,并假设SNP是独立的。该方法将误报的预期比例降至最低,但不具有统计意义。一个限制是,FDR方法仍然假设SNP和p值是独立的。
而是一个“标签”换句话说,它们是标记,因为附近的变体实际上可能是驱动关联的因素。请记住,这是一项相关性研究,而不是因果关系研究,因此需要进一步的生物学和下游工作,以了解标记或其附近标记的生物学功能。在第10章第10.2节中,我们提供了一个更详细的案例研究,说明如何使用FTO(通常被称为“脂肪基因”)实现这一目标。第8章描述了我们在GWAS期间进行的各种其他诊断检查,包括使用森林图和分位数-分位数(Q-Q)图按性别或数据源检查结果的异质性。第9章还详细介绍了控制人口分层的机制,这是第3章前面介绍的一个概念。
曼哈顿图
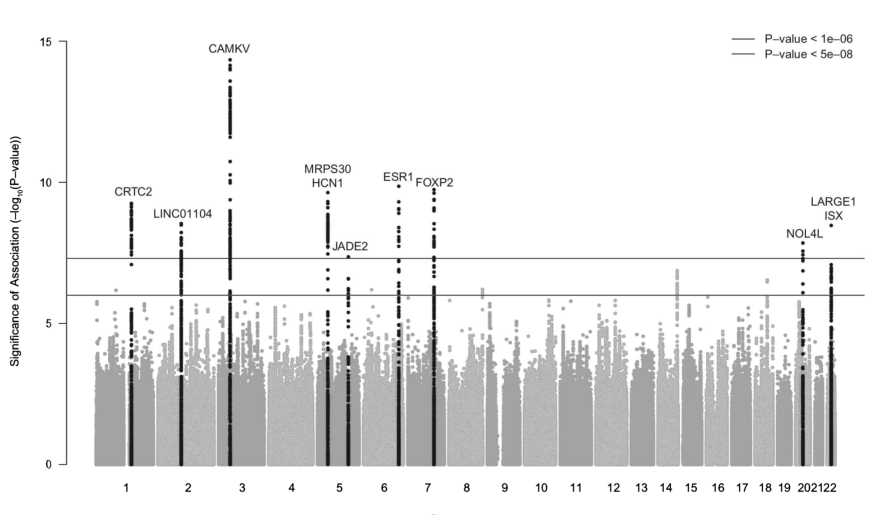
GWAS的主要结果通常显示在所谓的曼哈顿图中,图4.2显示了第一次分娩时的年龄特征。该图是一个散点图,绘制了p值(轴)的负对数(以10为底)和按染色体(x轴)位置排序的SNP关联的重要性。图中的顶行代表了p<5×10-8的全基因组显著阈值。图中的底红线显示了p<5×10的提示性命中阈值。
图中所示的单核苷酸多态性是标记,许多不会是实际的因果变异
二分类性状和数量性状
二分类一般用卡方检验,连续性状用F检验
为了评估二分性特征,卡方检验通常用于测试病例和对照组之间分布频率的差异。它计算病例和对照组的预期等位基因频率,就好像SNP与表型无关一样。然后以卡方统计量(X)的形式测量与该期望的偏差。假设SNP和性状不相关,则这些偏差偶然发生的概率的p值报告测试。如果p值低于定义的显著性阈值(在控制多次测试后,稍后讨论),则发现是显著的。
然后,我们通常还会估计影响大小,这对于理解关联的大小或强度很重要。为了计算二分性状的效应大小,可以使用不同的方法,如优势比(OR)。这是给定表型相关等位基因的表型概率除以给定非相关等位基因的表型概率。请注意,这不应在个人层面上解释为“个人风险”,而是与另一个基因组相比的风险计算。p值表示遗传关联是否符合我们选择的统计显著阈值,但不能用于比较遗传关联。这是因为p值受到样本量、统计检验能力以及所研究关系之外的其他因素的强烈影响。正是出于这个原因,我们使用效应大小来比较两个SNP:为了正确评估关联的强度和解释,你需要知道遗传关联的p值和效应大小估计。
为了评估数量性状,如身高,我们通常使用线性回归,目的是将性状与每个感兴趣的SNP相关联。与之前的测试一样,回归模型以p值和β系数定义的效应大小的形式产生显著性度量。然后对每个单核苷酸多态性进行回归分析,以确定全基因组显著性阈值(p≤5×10-8). 为了解释数量性状的效应大小,我们使用β系数,其中每个风险等位基因的出现对应于数量性状的增加,等于Beta系数。例如,假设我们将基因型AA、AG和GG的SNP与身高(厘米)相关联。如果我们发现A是“身高等位基因,β系数为0.5,则预测每个A等位基因对个体身高的贡献为0.5厘米。
效应大小、样本大小和统计能力是本分析中相互关联的重要方面。虽然我们在这里没有详细探讨这一点,但力量还取决于其他因素,如基因变体的MAF。罕见的因果变异比常见的因果变异更难检测,因为重要关联的统计能力很低,需要非常大的样本量。或者,在病例对照研究中,重要的不仅是样本量,还有病例和对照的相对数量。相同数量的案例和控件是功率的最佳选择。
固定效应模型和随机效应模型
正如我们在第2章中所讨论的,固定效应模型依赖于假设每个风险等位基因在每个数据集中的真实效应是相同的。虽然这个假设可能很脆弱,但与随机效应模型相比,这些模型能够最大限度地提高发现率[14]。我们没有详细描述各种固定效应模型,但包括反向方差加权和Cochran-Mantel-Haenszel。随机效应模型并不认为所有研究在功能上都是等效的,因为它们的能力有限,所以很少用于发现。当这些模型的目的是试图将观察到的关联推广到人群之外,并估计相关变体的平均效应大小以及不同人群的平均效应大小,以便进行预测时,更常用这些模型。
权重、FDR和填充
当多个数据源组合在一起时,一些研究会有更多的数据,因此在荟萃分析结果中应该比较小的研究更重要或权重更大。最常用的最佳权重是逆方差加权(每个研究根据其平方标准误差的倒数进行加权)。错误发现率(FDR)是指对已发现但被视为误报的关联比例的估计。这里,我们计算所谓的Q值,这是声称关联可能的最小FDR。正如我们的应用章节所示,我们还测试了插补的可靠性。当存在MAFs低的多态性时,这可能是一个问题,因为MAFs<5的填充SNP被重新排除在分析之外。
数据来源方差异质
一些表型可能难以测量或具有很高的测量变异性。在大型GWA研究中,通常需要协调不同的数据源并构建一个可比较的表型。因为已经收集了大多数表型。通常很难进行完全协调的分析。例如,2018年的一项研究考察了受教育年限的遗传基础,详细考察了表型分类的差异如何影响结果【15】。
他们得出结论,在可能的情况下,最详细的措施是最好的。然而,在协调多个数据集时,许多GWA通常协调到最常见的分类,因此通常最不详细的分类。
除第3章详细讨论的基于祖先的异质性外,可能存在诸如出生队列、国家或性别等不一致性。在第3章中,我们展示了即使在荷兰或英国等相对较小的国家,也存在不同的人口分层模式。GWAS通常会结合来自多个国家和历史时期的数据,以获得足够大的样本量。隐含的假设是,遗传学对个体的影响在时间和地点上是普遍的。在先前发表在《自然-人类行为》上的一项研究中,我们证明了事实并非如此,并且结合这些不同的数据集有可能掩盖差异,尤其是行为表型【16】。在所谓的“大型分析”中,我们证明,当数据合并时,对教育和第一个孩子出生时间的遗传影响中,约有40%是隐藏的或淡化的,这增加到75个或是出生过的孩子的数量。相反,我们发现与身高相关的遗传变异在不同人群中似乎是相同的。性别差异也可能导致异质性,这就是为什么一些分析,如与生殖或生殖行为相关,分别检查雌性、雄性和汇总结果【6,17】。显然,这可以扩展到考虑其他类型的异质性,如年龄或生命历程影响或社会经济地位。
基因型数据质控
对遗传数据进行分析以进行GWAS需要了解这种情况下的统计推断,但也需要进行大量质量检查,称为质量控制(QC)。QC是处理遗传数据的核心方面之一。我们在第8章中讨论了与GWASs相关的OC(见第8.5节)。QC对于可靠的GWAS结果是必要的,因为原始基因型数据本身就存在问题(见方框4.2)。例如,您可能有很大比例的个体缺失数据,或者个体中缺失基因型的比率很高,或者其他与低样本质量相关的问题。正如我们在第8章中更详细地概述的那样,QC可分为个体的质控和SNP的质控
个体水平QC经常检查(1)DNA数据质量差,(2)常染色体杂合度高或低,(3)性别信息不一致,(4)重复或相关个体,以及,(5)祖先差异。第二组质量控制分析侧重于基因型的数据质量或我们在第8章中根据标记OC讨论的内容。在这里,我们采取几个步骤来消除可能在研究中引入偏见的变体,即:(1)排除低呼叫率SNP;(2) 去除等位基因频率极低的SNP(罕见变体);(3) 识别和排除极端偏离哈迪-温伯格平衡的变体;(4) 在病例对照研究中,排除单核苷酸多态性组间的极端差异通话率;(5)在处理插补SNP的情况下,排除插补质量低的变异研究。
NHGRI-EBI GWAS目录
什么是NHGRI-EBI GWAS目录
该领域的新手通常想知道哪些表型已经被研究过,以及已经鉴定的各种SNP。主要资源是NHGRI-EBI GWAS目录(以下简称目录),包括所有已发布GWAS的数据,位于https://www.ebi.ac.uk/gwas/.它是由美国生产的。
国家人类基因组研究所(NHGRI)[19]与欧洲生物信息学研究所(EBI)[20]。要列入目录,研究必须符合非常严格的标准(见www.ebi.ac.uk/gwas/docs/methods),包括基于阵列的gwas和对100000多个全基因组覆盖的SNP的分析。目录中报告的SNP性状关联是那些p值至少小于1×10-5的性状关联。目录研究人员通过自动PubMed搜索找到研究,然后手动整理它们以进行评估和纳入。所有GWAS性状都映射到实验因子本体(EFO)[21]中的术语,这是一个用于分子生物学的变量本体,包括疾病、解剖学、细胞类型、细胞系、化合物和分析信息。例如,如果您搜索“心血管疾病”,目录将提供该特定特征及其子特征的所有研究和关联的结果和可视化结果。在这个例子中,潜台词可能是“心肌梗死”或“冠心病”?图4.3显示了NHGRI-EBI GWAS目录,说明了根据所有(人类)染色体的基因组位置报告的遗传关联。每一条线都链接到一个与p值阈值为p的性状相关的基因座≤5×10-8,每个圆圈都有颜色编码,以表示一个独特的特征。他们根据17个主要特征类别进行分组,如消化系统疾病、血液学测量、癌症或药物反应。可以通过出版物、变体、性状或基因搜索目录,这些信息会随着新出版物不断更新。
GWAS历史介绍
以下是几篇关于GWASs的优秀叙述性评论,描述了基本原理和科学结论,并强调了关键里程碑【2,22,23】。尽管第一份GWAS于2005年出版。maior突破是Wellcome Trust Case Control Consortium于2007年发表的一篇论文【24】,由于需要合作整合多个数据源,该论文被誉为外交方面的杰作【23】。
如前所述,要进行成功的GWAS,需要大样本量以提供足够的统计能力[25]。这意味着大多数GWASs发布到数据通常将来自多个数据源的单独分析的汇总结果汇集到元分析中,以获得尽可能大的样本量。过去几十年来,技术、方法、理论、计算能力和资金的进步极大地改变了GWAS的格局。
在我们之前的工作中,Mills和Rahal(2019)[3]对2005年至2018年10月的13年间的所有GWASs进行了系统和计算审查。我们使用NHGRI-EBI GWAS目录,并将其链接到PubMed等外部数据库。重要的是要注意,除了创建此aliving数据库之外,我们还包括了在公开的GitHub站点上使用的所有代码(https://github.com/crahal/GWASReview).
换句话说,随着每个目录的更新,我们的数据库以及这里描述的数字和数字将随着时间的推移自动更新。如图4.4所示,随着时间的推移,发布的GWASs数量、样本量、关联数量和研究的疾病都有显著增长。
在上面的面板中,我们看到随着时间的推移,发表的研究数量大幅增加(根据样本大小划分)。在这里,随着时间的推移,我们看到样本量的惊人增长,在2018年末和2019年初发布的样本有时包含100多万个个体。这些较大的研究主要归功于英国生物银行(约50万个人)[26、27],以及参与这项研究的23andMe等大型直接面向消费者的公司[28]。左下角的面板显示了发现的关联数量与GWASs中使用的参与者数量之间的强正相关关系。右下角的面板显示了独特特征数量的增长以及发布GWASs的期刊数量的增长。截至2018年10月,我们发现发表了3639项研究,涵盖了5849个独特的研究材料(论文中归因于性状的标识符),涉及3508个独特的性状,映射到2532个EFO性状。这些特征包括从身高到男性类型的秃顶、阿尔茨海默病、乳腺癌、咖啡消费或神经质。每次研究的平均命中数为15.3,最强风险等位基因的平均p值为1.3729×10-6。55岁左右?报告的关联符合p的标准阈值≤5×10-8.
GWAS多样性的确定
或者是该领域的新研究人员,有必要注意到目前基因样本缺乏多样性。正如我们在前几章中所讨论的,受试者祖先多样性的差异与人口分层等技术问题有关[29]。减少了连锁不平衡【30】、遗传多样性和混合【31】,但也由于文化不信任和数据的社会滥用而拒绝参与研究【32,33】。图4.5显示,尽管GWASs的数量和性状随着时间的推移确实呈爆炸式增长,但它仍然主要存在于欧洲祖先群体中,非欧洲群体更常在复制阶段进行检查。这意味着这些非欧洲人群经常被用来测试欧洲祖先群体会在其他祖先群体中复制,因此通常不会作为这些群体中基本基因发现的基础。
图4.5按常用的六大祖先类别显示了祖先群体。欧洲血统的人受到的检查最多。从2007-2008年高达95%的受试者到2017年的88%不等。特别是自201l年以来,对亚洲人群的研究一直在强劲而稳定地增长(见方框4.3)。如Mills和Rahal(2019年,表2)[3]所述,这主要是日本、中国和韩国人口。随着时间的推移,对非洲人口的研究最少,人们希望非洲基因组变异项目和其他促进多样性的项目将继续增加和改变这些趋势。
与GWA研究相关的多样性几乎只讨论了与祖先相关的多样性,但我们在GWA审查中还发现,地理、环境、时间和人口(如年龄、性别)的多样性明显不足【3】。正如我们所注意到的,尽管目前世界人口中约76.2%居住在亚洲或非洲,但72%的基因发现来自仅居住在三个国家(美国、英国和冰岛)的参与者。正如我们在本章和其他地方所阐述的,需要做更多的工作来了解环境暴露和地理集中如何影响结果。例如,在美国、墨西哥和英国,有肥胖倾向的人面临的环境刺激与其他一些肥胖率明显较低的国家截然不同如日本、韩国、意大利和荷兰。我们还发现出生队列、历史时期和生命历程阶段缺乏时间和人口多样性。GWASs中最常用的数据通常是年龄过大、社会经济地位较高、女性人数较多的数据,而且通常还包括“健康志愿者”的选择,如英国生物银行[35]。
结论和未来的方向
自2005年第一次GWAS以来,这一研究领域发生了重大变化。我们向读者介绍了NHGRI-EBI GWAS目录,其中包含迄今为止所有已发布GWAS的摘要。我们还记录了这一领域是如何迅速发展的,这不仅是因为研究的研究、疾病和关联的数量之多,还因为样本量的不断扩大。截至2019年,许多大型研究的综合样本超过100万例。然而,我们注意到,这种增长甚至没有跨越不同的祖先或地理群体,大多数研究仍在欧洲祖先群体中进行。尤其是亚洲研究,随着世界各地(如非洲)的新投资,进一步增加了多样性。一个新兴而令人兴奋的研究领域将是非欧洲祖先群体遗传多样性的发现。我们还应该注意到,组建这些大型财团也可能是过去的事情。
随着英国生物银行(UK Biobank)等大型数据集和23andMe等直接面向消费者的公司数量的不断增加,收集许多小型数据队列以生成大型样本的情况似乎越来越不常见。
读者还将对GWA研究所依据的方法学有一个基本的了解。虽然这仍然是一本介绍性的书,但我们希望您已经初步了解了这种类型的研究是如何进行的,GWASs中统计推断的意义,以及为什么以及如何需要更正多次测试。
本书第8章还介绍了个人和遗传标记水平上质量控制(QC)的重要性以及实际应用。
我们对GWAS的简要历史表明,这是一个快速发展的研究领域。
正如我们在关于伦理问题和未来方向的第14章和第15章中所阐述的,GWAS也并非完全没有争议。有人担心,长长的优先“热门”名单并没有带来一些人承诺的个性化药物、新疗法和风险预测工具。尽管超出了本书的支持范围,但许多GWAS命中的生物学后续研究已经找到了与已知生物途径相关的变体,但也找到了其他未被临床靶向的变体。
越来越多的研究不仅在研究常见的变异,也在研究罕见的变异。测序数据的进一步发展也可能揭示令人兴奋的新发现、研究领域和新方法。分析和合成GWAS数据的新方法也出现了,例如复杂性状遗传学虚拟实验室为GWAS后分析所做的工作(https://genoma.io/updates).
练习:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vAJKG9MP-1656835668257)(C:\Users\df\AppData\Roaming\Typora\typora-user-images\image-20220624102004288.png)]
本章节包括:
- 了解全基因组关联研究·
- 掌握基因分型和测序阵列的基础和局限性及其与连锁不定性和填充的关系
- 了解全基因组关联研究研究设计、元分析和数据分析计划
- 了解全基因组关联研究的统计推断、方法和异质性的基本方面
- 掌握质量控制的类型
- 了解NHGRI-EBI GWAS目录以概述全基因组关联研究
- 认识到在祖先、地理、时间,迄今为止全基因组关联研究的人口多样性及其对研究的影响
- 意识到了这一研究领域的未来方向
简介和背景
随着基因分型技术的发展、成本的降低和先进数据分析方法的发展,遗传关联研究的设计在过去几十年中发生了巨大的变化。尽管高通量的全基因组分析现在是标准的,但早期的研究只关注有限数量的“候选”基因座。候选基因研究一词是指这一领域的早期工作,其重点是预先确定的感兴趣的基因座,这些基因座被认为与所研究的性状有关。正如我们在关于基因-环境相互作用的第6章中详细讨论的那样,许多早期候选基因研究由于多种原因存在问题,主要是由于缺乏重复,虽然我们的目标是让这一领域的新研究人员避免犯类似的错误,但我们应该注意到,一些候选基因研究仍然成功地用于各种非行为医学表型。当时,许多性状的极端多基因性和候选基因作为药物靶点的失败(例如抑郁症)让许多人感到真正的惊讶。另一种选择是全基因组关联研究(GWAS),该研究同时测量了数百万个基因位点。
GWAS是目前用于确定单核苷酸多态性(SNP)与表型之间关联的主要方法。正如我们稍后更详细地讨论的那样,GWASs测试了数百万个单独的回归模型,以确定遗传变异和表型之间的关联。回顾第一章,表型可以是单基因性状。
受单个基因内变异的强烈影响。但许多是多基因复杂性状,是多基因变异及其与行为和环境因素相互作用的结果。GWAS的结果显示了每个单核苷酸多态性与特定性状或表型的关联。与候选基因研究相比,GWASs是无假设的,可以在所有基因型区域中寻找关联。正如前面在第1章中所讨论的,GWAS研究了将我们彼此区分开来的多态性。除了单卵(即同卵)双胞胎外,这是0.1%的位点差异是我们与众不同的原因。
由于许多性状是复杂的,并且与多个遗传位点(即多基因)相关,GWAS通常识别出许多遗传变异,每个变异对表型的影响很小。由于影响大小较小,需要非常大的数据源,GWAS发现通常会在多个数据源上进行许多GWAS分析,然后合并到一个元分析中。在GWASs中识别的大多数变体不被认为是生物学上的因果关系,而是由于连锁不平衡(LD),可以识别包含一个或多个生物学功能变体的区域。到2019年初,已经进行了近4000次GWASs,从不可知的角度确定了数千种基因变体[2,3]。已研究的特征包括许多常见的人类疾病,如乳腺癌、阿尔茨海默病和2型糖尿病,但也包括人体测量(身高、体重)和行为特征,如初生年龄或教育程度。
本章介绍了GWAS研究和基本概念。由于GWASs的结果通常是许多实际应用的基础,因此本章对于第二部分的后续应用章节至关重要,包括如何对遗传数据进行质量控制(QC)(第8章)。在本章中,我们将介绍GWAS方法学的基础知识,包括遗传数据收集、研究设计和方法方面的细节,以及纠正多重测试的必要性。接下来,我们将在第8章介绍个体水平和遗传标记水平QC的类型。第4节简要介绍了GWAS元分析和进一步的扩展。最后,我们对NHGRI-EBI GWAS目录,随后是2005年至2018年末GWA发现的简要历史。我们注意到GWAS样本中缺乏各种类型的多样性,例如缺乏祖先和人口多样性,以及受试者在特定国家集中。最后,我们做了一个简短的总结,并指出了未来的研究方向。
GWAS研究分析和元分析
数据分析流程
基因发现不仅是一项智力挑战,也是一项组织和后勤挑战。由于GWA的质量和成功传统上取决于收集大量样本,因此已成立了大型财团,进行独立的GWA,随后由领导该项目的核心小组进行元分析。图4.1描述了GWAS阶段,这可能是现代科学中最大类型的合作努力之一。考虑到所需的广泛专业知识、需要成立的财团以及长期和耗时的投资。这一领域的新研究人员很少会启动自己的独立GWA。然而,了解GWA的构思过程是有用的。
首先从一般可行性分析开始,研究人员需要了解表型、迄今为止研究的内容、测量和先前的遗传力估计或其他GWAS结果(如果可用)。这一研究领域在总结现有结果的在线工具和软件包方面继续蓬勃发展。例如,你可以参考对50多个双生子研究中许多人类性状遗传力的综合分析(见[4])。它还附带了一个名为MaTCH(双胞胎相关性和遗传力的元分析)的web应用程序,可通过http://match.ctglabnl/。还有其他网站,如SNPedia(https://www.snpedia.com/index,php/遗传力),该目录列出了与特定研究相关的遗传力估计值。Ben Neale的实验室还拥有一个令人难以置信的网站,用于检测英国生物库中许多性状的遗传力(http://www.nealelab.is/uk-biobank/).您还可以从复杂性状遗传学虚拟实验室(CTG-VL)生成结果的可视化,包括曼哈顿图和许多其他结果,用于GWAS后分析[5],ttps://genoma.io and http/atlas.ctglab.nI/。
下一步是隔离哪些数据源可能具有您感兴趣的表型,如果适用,组建或联系一个联盟,或获取现有或公开可用的数据(如英国生物银行)。组建一个财团需要花费大量的时间和精力,包括经常等待道德和准入许可,在某些情况下还需要处理付款以使用数据。尽管英国生物银行(约500000个)等大型数据集最近已经面世,但通常会形成大型联合体,将多个数据集组合在一起,以产生尽可能大的样本。在许多情况下,每个数据源的独立分析师负责执行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R98ZEGiC-1656835655879)(C:\Users\df\AppData\Roaming\Typora\typora-user-images\image-20220624094239840.png)]
分析步骤:
- 确定可行性,查阅文献,查看遗传力,表型测定方法
- 从实验搜集数据,或者已有的数据,确定合作方案
- 撰写数据分析方案
- 数据存储,转换,分析,描述分析,汇总结果
- QC质控,单独分析和元分析
- 重点查看显著的位点
- 注释,查看结果
GWAS内部,并将结果发送回联合体领导人。这通常与数据的隐私和同意问题有关,如本书最后一部分第l4章所述,GWAS汇总统计的元分析因此是发现与表型相关的遗传变异的最常用方法。由于常见等位基因的遗传效应很小,我们从第一章之前的讨论中了解到,信号检测需要更大的样本量。由于单个GWASs的动力不足,研究人员需要进行元分析并合并多个数据源。
数据分析计划
这部分,主要是如何收集数据,包括设置问卷调查注意事项。还应该注意,应该包括一些协变量。然后常用的数据质控,使用的模型,有时候会考虑家系的作用。
如果您的目标是收集大量样本,请说明如何选择加入联盟和关键截止日期。
然后经常列出详细的样本纳入标准。例如,在我们对人类生殖的研究中,我们还检查了有史以来出生的儿童数量(NEB),只包括那些已经到了生育期结束的儿童(女性至少45岁,男性55岁),并澄清说,我们还希望分析人员将从未生过孩子的个人包括在内。这也是您指定任何祖先要求、相关协变量、基因分型率(>95?)和其他质量控制的地方(另见第8章)。
基因型和插补信息,包括插补前需要应用的任何推荐标记过滤器,我们将很快讨论。在前面提到的示例分析计划中,SNP call rate>95,HWE>10-6,MAF>5%这些价值背后的逻辑将在第8章中详细讨论。
用于关联测试的模型的ear规范。例如,在我们的研究中,我们要求对男性和女性的两种表型(AFB、NEB)的回归模型进行估计,然后合并。例如,一个方程是Y=m+SNP,β+Zy+e。许多研究还经常包括基于家庭的数据,其中82第4章应提供明确的案例说明,以考虑数据中的脆弱性结构或选择家庭成员。我们指定了线性回归模型,其中包括几个协变量(例如,控制人口分层、控制非线性效应的出生队列或任何研究特定协变量)。
为结果指定fle格式。例如,许多人经常选择费用联合体共享格式。!文件命名方案同样重要,因为您将收到数百个不同的文件。
数据交换和安全程序也很重要,最近在欧洲工作的许多人需要遵守GDPR(一般数据保护条例)(见第14章,道德)。
然后,还经常包括荟萃分析的描述。这包括标记排除筛选、基因组控制、显著性阈值以及顶级SNP的报告方式。
每个参与的数据源(在这一研究领域通常称为队列)单独运行分析,或者可以授权访问数据。每个研究的汇总统计结果通常会与特定数据源数据的一些描述性信息一起上传。然后将这些结果结合起来进行荟萃分析。
元分析
元分析是对来自多个独立研究的信息进行统计综合,从而提高功效,进而降低假阳性发现的风险【7】。还建议联合体中的所有研究人员签署一份合作协议,其中包括,例如,在当前联合体发布之前,不要发布该表型的GWAS,GWAS荟萃分析使用所谓的汇总数据,提供回归系数、标准误差、,依此类推,对于遵循预先指定的分析计划的群体中的每个遗传标记。因此,它不是单个级别的数据,而是汇总的汇总结果。我们2016年的生殖行为研究【6】。
例如,涉及一个元分析,它使用来自60多个不同数据源的汇总统计数据。在第8章中,我们描述了如何在个人层面上参与OC,然后再进行GWAS(例如,去除等位基因频率低的变体。插补质量低,等位基因频率与参考样本有很大差异,或由其他地方未复制的特定研究驱动的结果)。GWAS荟萃分析中一个重要且耗时的步骤是第二套质量控制,它基本上是协调各研究的结果。尽管提供了统一的分析计划,但此清理过程可能在初始项目中花费的时间最长,因为分析人员可能使用不同的软件,或者结果中存在其他不一致之处。Winkler等人在GIANT consortium工作的基础上,为meta-OC过程提供了一个优秀的协议。
统计推断、方法和异质性
表型数据
确定数据的类型,以及需要考虑的协变量
GWA研究的核心前提是对特定人群中的大量样本同时进行数百万个假设检验,或者换言之,对每个变量进行一个假设检验。每个遗传关联研究都采用统计推断来确定和量化遗传位点和表型之间的关联强度。关联方法的选择通常取决于表型的性质,以及它是二分型(即二分型)还是定量型(即连续型),但考虑潜在的混杂因素(如gsex、年龄、出生队列)也是常见的。
对于数量或连续特征(例如,初生年龄或体重指数),分析会在表型的连续分布范围内对个体进行比较,通常使用线性回归。在这里,我们比较了基于检验统计量的分布与任何标记无关联的零假设,并考虑了标准误差。删失数据生存模型的其他扩展也越来越可能。对于二元或二元性状,它通常使用逻辑回归来比较高(病例)值和低(对照)值。与典型的logistic模型一样,假设所研究性状的logit变换与等位基因呈线性关系,但通常用优势比来解释。
使用P-values和Z-scores
P-value一般用于单个数据的分析,Z-score可以用于元分析,表示结果。
第2章更详细地阐述了这类研究的统计基础。简而言之,目标是对遗传位点和正在研究的表型之间的每一个真实关联进行统计显著性估计。正如大多数读者所知,正如前面第2章所讨论的,统计显著性通常由p值决定。p值估计获得测试统计值的概率,该值与通过所选统计方法为潜在关联估计的值一样极端(即,在零下)。这并不是一个基因座与一个特征相联系的可能性。当我们进行这种回归时,我们使用t检验等检验统计量来检验特定遗传变异的β参数是否显著不同于零。检验统计量是用来衡量对无效假设支持程度的数据的数值总结。在零假设下,检验统计量可能具有已知的概率分布(例如,x’),或者估计其零分布。回想一下,无效假设是对特定人群之间没有显著差异的假设的统计检验,在GWAS的情况下,是病例和对照之间的差异。任何观察到的差异都归因于采样或实验误差。如果从遗传位点产生的检验统计量值与我们从无效假设中预期的值显著偏离,则有证据表明存在替代性组间存在显著差异(病例组与对照组)或与数量性状存在显著关系。
在荟萃分析中,p值的缺点是不能提供效应大小的总体估计,这一点已被广泛讨论。此外,无法评估数据集之间的异构性。还使用了一个相关的统计数据,即Z分数,它基于Z的平均值;值,即第i次研究的Z值,尽管p值和Z值高度相关,但使用Z值的优势在于,它们考虑了影响的方向,并且您能够引入权重(例如,如果您希望某项特定研究的权重更高或更低)。单核苷酸多态性被标记为或被视为“点击率”,以p值为衡量标准。
如前所述,商定的全基因组显著阈值为p<5×10-8。
这对应于Bonferroni校正,将在下一节中讨论。由于SNP、MAF、LD模式或阵列的变化,全基因组显著性阈值可能因人群而异。在LD较低的人群中,如非洲祖先群体,应使用更严格的阈值[9]。
矫正GWAS结果
常用的方法有:
- Bonferroni correction,一般用0.05/N,或者1/N来确定P值
- 置换检验
- FDR检验
第一种:Bonferroni矫正
DNA微阵列和下一代测序使我们能够检测大量串联基因组位点的相关性。GWAS结果中进行比较的程度称为多重测试问题。这是两种误报(l类错误)的可能性,如果多重比较的校正过于保守或功率不足,则会产生误报(2类错误)。我们测试了整个基因组中数百万个基因变体的关联,但只有很小一部分在全基因组显著性水平上与表型相关。
问题是,当我们进行这么多测试时,我们也面临着仅仅是偶然发现许多强大关联的危险。在GWAS中,对每个遗传位点和表型进行统计检验,以产生检验统计量和相关的p值。如果我们取标准p值0.05.
即使给定的遗传变异与我们的表型无关,我们也有1/20的机会发现显著的关联。这就是所谓的类型1错误或假阳性。由于在GWAS中,我们实际上并行执行了数百万次测试,如果我们采用标准的0.05显著性阈值,我们很可能会获得许多误报。为了解决这个多重测试问题,最常用和最直接的修正是Bonferroni修正。简单地说,我们将所选的显著性阈值(p值)除以所执行的测试数量。如果进行了10次测试,我们只会声明,如果p值小于0.005,结果才是显著的。在基因组的情况下,我们正在测试100万个独立的遗传变异是否存在常见的序列变异,因此,Bonferronicorrected p值的显著性为p<5×10-8。这与统计学中独立性的基本假设有关,或者说你应该从你的样本中得到反映你会在人群中发现。
如果数据中存在最小的依赖性,而您违反了这一假设,则会产生有偏差的结果。GWASs的一个统计问题是,附近基因变体的基因型之间往往存在着很强的相关性。或者换句话说,实际测试100万个遗传变异实际上更像是测试70万到80万个不相关的遗传变异。因此,在GWAS中,采用统计阈值,以p<5×10-8(即p<0.0000000-5)作为全基因组统计显著性的标准,而p<5×10-6通常用于表示“提示性命中”
第二种:置换检验
有人认为,Bonferroni校正过于保守,导致假阴性结果的比例增加,并假设每个基因变异都是独立于其他变异进行测试的,这是独立的。虽然对替代方法的详细解释超出了本介绍性书籍的范围,但还有其他方法可以纠正多次测试。基于排列的测试多次对表型进行排列,然后每次重新计算统计测试,以产生可用于假设测试的经验零分布。
将其视为标签的洗牌可能更为直观。为了计算基于排列的p值,结果度量标签被随机排列或洗牌多次(例如1000-1000000),这有效地消除了基因型和表型之间的任何真正关联。然后对所有置换数据集进行统计测试。
这提供了无关联零假设下检验统计量和p值的经验分布。然后将从观察数据中获得的原始检验统计量或p值与p值的经验分布进行比较,以确定经验调整的p值。基于置换的测试是计算密集型的,尤其是当需要许多置换时,这对于精确计算非常小的p值是必要的[1]。
第三种:FDR
另一种技术是Benjamini-Hochberg错误发现率(FDR),它比Bonferroni校正更保守。它控制所有信号中误报的预期比例,FDR值低于固定阈值,并假设SNP是独立的。该方法将误报的预期比例降至最低,但不具有统计意义。一个限制是,FDR方法仍然假设SNP和p值是独立的。
而是一个“标签”换句话说,它们是标记,因为附近的变体实际上可能是驱动关联的因素。请记住,这是一项相关性研究,而不是因果关系研究,因此需要进一步的生物学和下游工作,以了解标记或其附近标记的生物学功能。在第10章第10.2节中,我们提供了一个更详细的案例研究,说明如何使用FTO(通常被称为“脂肪基因”)实现这一目标。第8章描述了我们在GWAS期间进行的各种其他诊断检查,包括使用森林图和分位数-分位数(Q-Q)图按性别或数据源检查结果的异质性。第9章还详细介绍了控制人口分层的机制,这是第3章前面介绍的一个概念。
曼哈顿图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U8GGy3fe-1656835655880)(C:\Users\df\AppData\Roaming\Typora\typora-user-images\image-20220624100503067.png)]
GWAS的主要结果通常显示在所谓的曼哈顿图中,图4.2显示了第一次分娩时的年龄特征。该图是一个散点图,绘制了p值(轴)的负对数(以10为底)和按染色体(x轴)位置排序的SNP关联的重要性。图中的顶行代表了p<5×10-8的全基因组显著阈值。图中的底红线显示了p<5×10的提示性命中阈值。
图中所示的单核苷酸多态性是标记,许多不会是实际的因果变异
二分类性状和数量性状
二分类一般用卡方检验,连续性状用F检验
为了评估二分性特征,卡方检验通常用于测试病例和对照组之间分布频率的差异。它计算病例和对照组的预期等位基因频率,就好像SNP与表型无关一样。然后以卡方统计量(X)的形式测量与该期望的偏差。假设SNP和性状不相关,则这些偏差偶然发生的概率的p值报告测试。如果p值低于定义的显著性阈值(在控制多次测试后,稍后讨论),则发现是显著的。
然后,我们通常还会估计影响大小,这对于理解关联的大小或强度很重要。为了计算二分性状的效应大小,可以使用不同的方法,如优势比(OR)。这是给定表型相关等位基因的表型概率除以给定非相关等位基因的表型概率。请注意,这不应在个人层面上解释为“个人风险”,而是与另一个基因组相比的风险计算。p值表示遗传关联是否符合我们选择的统计显著阈值,但不能用于比较遗传关联。这是因为p值受到样本量、统计检验能力以及所研究关系之外的其他因素的强烈影响。正是出于这个原因,我们使用效应大小来比较两个SNP:为了正确评估关联的强度和解释,你需要知道遗传关联的p值和效应大小估计。
为了评估数量性状,如身高,我们通常使用线性回归,目的是将性状与每个感兴趣的SNP相关联。与之前的测试一样,回归模型以p值和β系数定义的效应大小的形式产生显著性度量。然后对每个单核苷酸多态性进行回归分析,以确定全基因组显著性阈值(p≤5×10-8). 为了解释数量性状的效应大小,我们使用β系数,其中每个风险等位基因的出现对应于数量性状的增加,等于Beta系数。例如,假设我们将基因型AA、AG和GG的SNP与身高(厘米)相关联。如果我们发现A是“身高等位基因,β系数为0.5,则预测每个A等位基因对个体身高的贡献为0.5厘米。
效应大小、样本大小和统计能力是本分析中相互关联的重要方面。虽然我们在这里没有详细探讨这一点,但力量还取决于其他因素,如基因变体的MAF。罕见的因果变异比常见的因果变异更难检测,因为重要关联的统计能力很低,需要非常大的样本量。或者,在病例对照研究中,重要的不仅是样本量,还有病例和对照的相对数量。相同数量的案例和控件是功率的最佳选择。
固定效应模型和随机效应模型
正如我们在第2章中所讨论的,固定效应模型依赖于假设每个风险等位基因在每个数据集中的真实效应是相同的。虽然这个假设可能很脆弱,但与随机效应模型相比,这些模型能够最大限度地提高发现率[14]。我们没有详细描述各种固定效应模型,但包括反向方差加权和Cochran-Mantel-Haenszel。随机效应模型并不认为所有研究在功能上都是等效的,因为它们的能力有限,所以很少用于发现。当这些模型的目的是试图将观察到的关联推广到人群之外,并估计相关变体的平均效应大小以及不同人群的平均效应大小,以便进行预测时,更常用这些模型。
权重、FDR和填充
当多个数据源组合在一起时,一些研究会有更多的数据,因此在荟萃分析结果中应该比较小的研究更重要或权重更大。最常用的最佳权重是逆方差加权(每个研究根据其平方标准误差的倒数进行加权)。错误发现率(FDR)是指对已发现但被视为误报的关联比例的估计。这里,我们计算所谓的Q值,这是声称关联可能的最小FDR。正如我们的应用章节所示,我们还测试了插补的可靠性。当存在MAFs低的多态性时,这可能是一个问题,因为MAFs<5的填充SNP被重新排除在分析之外。
数据来源方差异质
一些表型可能难以测量或具有很高的测量变异性。在大型GWA研究中,通常需要协调不同的数据源并构建一个可比较的表型。因为已经收集了大多数表型。通常很难进行完全协调的分析。例如,2018年的一项研究考察了受教育年限的遗传基础,详细考察了表型分类的差异如何影响结果【15】。
他们得出结论,在可能的情况下,最详细的措施是最好的。然而,在协调多个数据集时,许多GWA通常协调到最常见的分类,因此通常最不详细的分类。
除第3章详细讨论的基于祖先的异质性外,可能存在诸如出生队列、国家或性别等不一致性。在第3章中,我们展示了即使在荷兰或英国等相对较小的国家,也存在不同的人口分层模式。GWAS通常会结合来自多个国家和历史时期的数据,以获得足够大的样本量。隐含的假设是,遗传学对个体的影响在时间和地点上是普遍的。在先前发表在《自然-人类行为》上的一项研究中,我们证明了事实并非如此,并且结合这些不同的数据集有可能掩盖差异,尤其是行为表型【16】。在所谓的“大型分析”中,我们证明,当数据合并时,对教育和第一个孩子出生时间的遗传影响中,约有40%是隐藏的或淡化的,这增加到75个或是出生过的孩子的数量。相反,我们发现与身高相关的遗传变异在不同人群中似乎是相同的。性别差异也可能导致异质性,这就是为什么一些分析,如与生殖或生殖行为相关,分别检查雌性、雄性和汇总结果【6,17】。显然,这可以扩展到考虑其他类型的异质性,如年龄或生命历程影响或社会经济地位。
基因型数据质控
对遗传数据进行分析以进行GWAS需要了解这种情况下的统计推断,但也需要进行大量质量检查,称为质量控制(QC)。QC是处理遗传数据的核心方面之一。我们在第8章中讨论了与GWASs相关的OC(见第8.5节)。QC对于可靠的GWAS结果是必要的,因为原始基因型数据本身就存在问题(见方框4.2)。例如,您可能有很大比例的个体缺失数据,或者个体中缺失基因型的比率很高,或者其他与低样本质量相关的问题。正如我们在第8章中更详细地概述的那样,QC可分为个体的质控和SNP的质控
个体水平QC经常检查(1)DNA数据质量差,(2)常染色体杂合度高或低,(3)性别信息不一致,(4)重复或相关个体,以及,(5)祖先差异。第二组质量控制分析侧重于基因型的数据质量或我们在第8章中根据标记OC讨论的内容。在这里,我们采取几个步骤来消除可能在研究中引入偏见的变体,即:(1)排除低呼叫率SNP;(2) 去除等位基因频率极低的SNP(罕见变体);(3) 识别和排除极端偏离哈迪-温伯格平衡的变体;(4) 在病例对照研究中,排除单核苷酸多态性组间的极端差异通话率;(5)在处理插补SNP的情况下,排除插补质量低的变异研究。
NHGRI-EBI GWAS目录
什么是NHGRI-EBI GWAS目录
该领域的新手通常想知道哪些表型已经被研究过,以及已经鉴定的各种SNP。主要资源是NHGRI-EBI GWAS目录(以下简称目录),包括所有已发布GWAS的数据,位于https://www.ebi.ac.uk/gwas/.它是由美国生产的。
国家人类基因组研究所(NHGRI)[19]与欧洲生物信息学研究所(EBI)[20]。要列入目录,研究必须符合非常严格的标准(见www.ebi.ac.uk/gwas/docs/methods),包括基于阵列的gwas和对100000多个全基因组覆盖的SNP的分析。目录中报告的SNP性状关联是那些p值至少小于1×10-5的性状关联。目录研究人员通过自动PubMed搜索找到研究,然后手动整理它们以进行评估和纳入。所有GWAS性状都映射到实验因子本体(EFO)[21]中的术语,这是一个用于分子生物学的变量本体,包括疾病、解剖学、细胞类型、细胞系、化合物和分析信息。例如,如果您搜索“心血管疾病”,目录将提供该特定特征及其子特征的所有研究和关联的结果和可视化结果。在这个例子中,潜台词可能是“心肌梗死”或“冠心病”?图4.3显示了NHGRI-EBI GWAS目录,说明了根据所有(人类)染色体的基因组位置报告的遗传关联。每一条线都链接到一个与p值阈值为p的性状相关的基因座≤5×10-8,每个圆圈都有颜色编码,以表示一个独特的特征。他们根据17个主要特征类别进行分组,如消化系统疾病、血液学测量、癌症或药物反应。可以通过出版物、变体、性状或基因搜索目录,这些信息会随着新出版物不断更新。
GWAS历史介绍
以下是几篇关于GWASs的优秀叙述性评论,描述了基本原理和科学结论,并强调了关键里程碑【2,22,23】。尽管第一份GWAS于2005年出版。maior突破是Wellcome Trust Case Control Consortium于2007年发表的一篇论文【24】,由于需要合作整合多个数据源,该论文被誉为外交方面的杰作【23】。
如前所述,要进行成功的GWAS,需要大样本量以提供足够的统计能力[25]。这意味着大多数GWASs发布到数据通常将来自多个数据源的单独分析的汇总结果汇集到元分析中,以获得尽可能大的样本量。过去几十年来,技术、方法、理论、计算能力和资金的进步极大地改变了GWAS的格局。
在我们之前的工作中,Mills和Rahal(2019)[3]对2005年至2018年10月的13年间的所有GWASs进行了系统和计算审查。我们使用NHGRI-EBI GWAS目录,并将其链接到PubMed等外部数据库。重要的是要注意,除了创建此aliving数据库之外,我们还包括了在公开的GitHub站点上使用的所有代码(https://github.com/crahal/GWASReview).
换句话说,随着每个目录的更新,我们的数据库以及这里描述的数字和数字将随着时间的推移自动更新。如图4.4所示,随着时间的推移,发布的GWASs数量、样本量、关联数量和研究的疾病都有显著增长。
在上面的面板中,我们看到随着时间的推移,发表的研究数量大幅增加(根据样本大小划分)。在这里,随着时间的推移,我们看到样本量的惊人增长,在2018年末和2019年初发布的样本有时包含100多万个个体。这些较大的研究主要归功于英国生物银行(约50万个人)[26、27],以及参与这项研究的23andMe等大型直接面向消费者的公司[28]。左下角的面板显示了发现的关联数量与GWASs中使用的参与者数量之间的强正相关关系。右下角的面板显示了独特特征数量的增长以及发布GWASs的期刊数量的增长。截至2018年10月,我们发现发表了3639项研究,涵盖了5849个独特的研究材料(论文中归因于性状的标识符),涉及3508个独特的性状,映射到2532个EFO性状。这些特征包括从身高到男性类型的秃顶、阿尔茨海默病、乳腺癌、咖啡消费或神经质。每次研究的平均命中数为15.3,最强风险等位基因的平均p值为1.3729×10-6。55岁左右?报告的关联符合p的标准阈值≤5×10-8.
GWAS多样性的确定
或者是该领域的新研究人员,有必要注意到目前基因样本缺乏多样性。正如我们在前几章中所讨论的,受试者祖先多样性的差异与人口分层等技术问题有关[29]。减少了连锁不平衡【30】、遗传多样性和混合【31】,但也由于文化不信任和数据的社会滥用而拒绝参与研究【32,33】。图4.5显示,尽管GWASs的数量和性状随着时间的推移确实呈爆炸式增长,但它仍然主要存在于欧洲祖先群体中,非欧洲群体更常在复制阶段进行检查。这意味着这些非欧洲人群经常被用来测试欧洲祖先群体会在其他祖先群体中复制,因此通常不会作为这些群体中基本基因发现的基础。
图4.5按常用的六大祖先类别显示了祖先群体。欧洲血统的人受到的检查最多。从2007-2008年高达95%的受试者到2017年的88%不等。特别是自201l年以来,对亚洲人群的研究一直在强劲而稳定地增长(见方框4.3)。如Mills和Rahal(2019年,表2)[3]所述,这主要是日本、中国和韩国人口。随着时间的推移,对非洲人口的研究最少,人们希望非洲基因组变异项目和其他促进多样性的项目将继续增加和改变这些趋势。
与GWA研究相关的多样性几乎只讨论了与祖先相关的多样性,但我们在GWA审查中还发现,地理、环境、时间和人口(如年龄、性别)的多样性明显不足【3】。正如我们所注意到的,尽管目前世界人口中约76.2%居住在亚洲或非洲,但72%的基因发现来自仅居住在三个国家(美国、英国和冰岛)的参与者。正如我们在本章和其他地方所阐述的,需要做更多的工作来了解环境暴露和地理集中如何影响结果。例如,在美国、墨西哥和英国,有肥胖倾向的人面临的环境刺激与其他一些肥胖率明显较低的国家截然不同如日本、韩国、意大利和荷兰。我们还发现出生队列、历史时期和生命历程阶段缺乏时间和人口多样性。GWASs中最常用的数据通常是年龄过大、社会经济地位较高、女性人数较多的数据,而且通常还包括“健康志愿者”的选择,如英国生物银行[35]。
结论和未来的方向
自2005年第一次GWAS以来,这一研究领域发生了重大变化。我们向读者介绍了NHGRI-EBI GWAS目录,其中包含迄今为止所有已发布GWAS的摘要。我们还记录了这一领域是如何迅速发展的,这不仅是因为研究的研究、疾病和关联的数量之多,还因为样本量的不断扩大。截至2019年,许多大型研究的综合样本超过100万例。然而,我们注意到,这种增长甚至没有跨越不同的祖先或地理群体,大多数研究仍在欧洲祖先群体中进行。尤其是亚洲研究,随着世界各地(如非洲)的新投资,进一步增加了多样性。一个新兴而令人兴奋的研究领域将是非欧洲祖先群体遗传多样性的发现。我们还应该注意到,组建这些大型财团也可能是过去的事情。
随着英国生物银行(UK Biobank)等大型数据集和23andMe等直接面向消费者的公司数量的不断增加,收集许多小型数据队列以生成大型样本的情况似乎越来越不常见。
读者还将对GWA研究所依据的方法学有一个基本的了解。虽然这仍然是一本介绍性的书,但我们希望您已经初步了解了这种类型的研究是如何进行的,GWASs中统计推断的意义,以及为什么以及如何需要更正多次测试。
本书第8章还介绍了个人和遗传标记水平上质量控制(QC)的重要性以及实际应用。
我们对GWAS的简要历史表明,这是一个快速发展的研究领域。
正如我们在关于伦理问题和未来方向的第14章和第15章中所阐述的,GWAS也并非完全没有争议。有人担心,长长的优先“热门”名单并没有带来一些人承诺的个性化药物、新疗法和风险预测工具。尽管超出了本书的支持范围,但许多GWAS命中的生物学后续研究已经找到了与已知生物途径相关的变体,但也找到了其他未被临床靶向的变体。
越来越多的研究不仅在研究常见的变异,也在研究罕见的变异。测序数据的进一步发展也可能揭示令人兴奋的新发现、研究领域和新方法。分析和合成GWAS数据的新方法也出现了,例如复杂性状遗传学虚拟实验室为GWAS后分析所做的工作(https://genoma.io/updates).
练习:
