4变异函数结构分析
4.1变异函数理论模型
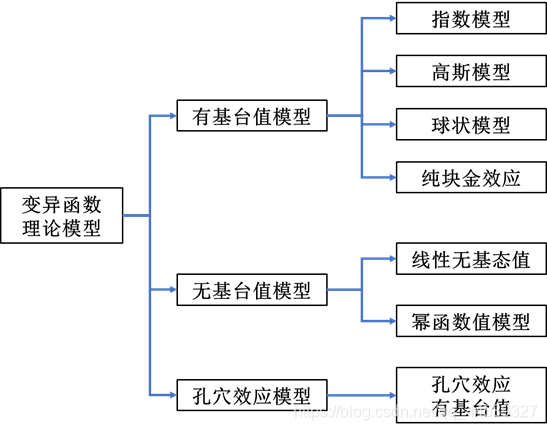
4.1.1有基态值模型
球状模型
γ(h)=⎩⎪⎨⎪⎧0C0+C(2a3h−2a31h3)C0+Ch=00<h≤ah>a
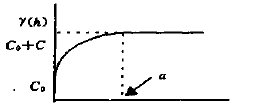
C0,C0+C,C,a分别为块金常数、基台值、拱高、变程,其中球状模型是应用最广的模型,一般只用于一维,二维,和三维数据,最适合用在当空间相关性随步长增加而线性递减的情况(即曲线的斜率是线性递减的)。
指数模型:
γ(h)={0C0+C(1−e−ah)h=0h>0
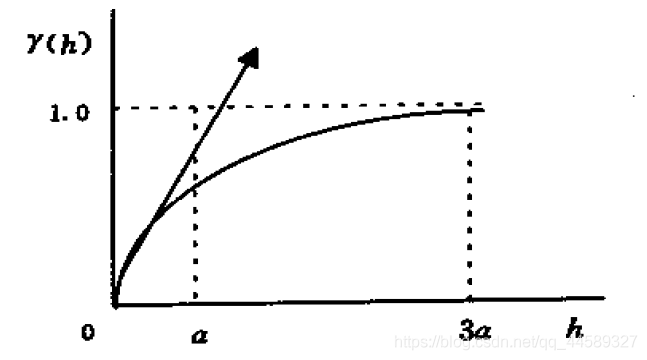
C0,C0+C,C,a分别为块金常数、基台值、拱高、该模型在原点处的切线和基台值相交时的所对应的步长,其中
3a约等于变程(对应于0.95*基台值)
适合一维或多维数据,由于指数模型在较大步长时也不能等于先验方差(相关系数也不能等于0),因此其变程定义为当变异函数为0.95
σ2(
σ2为先验方差)所对应的步长
高斯模型
γ(h)={0C0+C(1−e−a2h2)h=0h>0
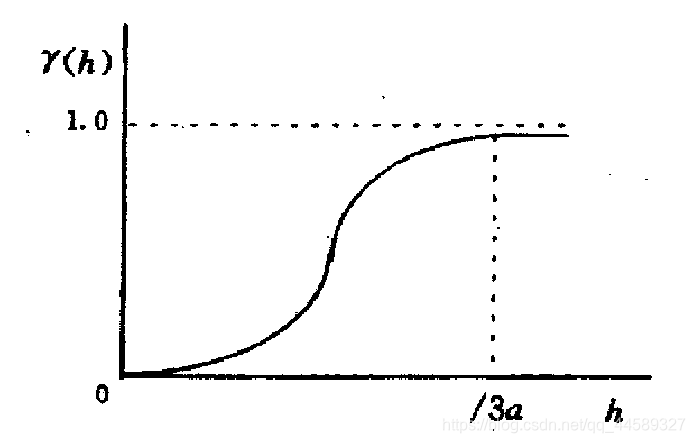
C0,C0+C,C,3
a分别为块金常数、基台值、拱高、约为变程,适合一维或多维数据,因此其变程定义为当变异函数为0.95
σ2(
σ2为先验方差)所对应的步长一般适用于当数据在短距离内呈现高度连续性的情况
三种常用模型比较
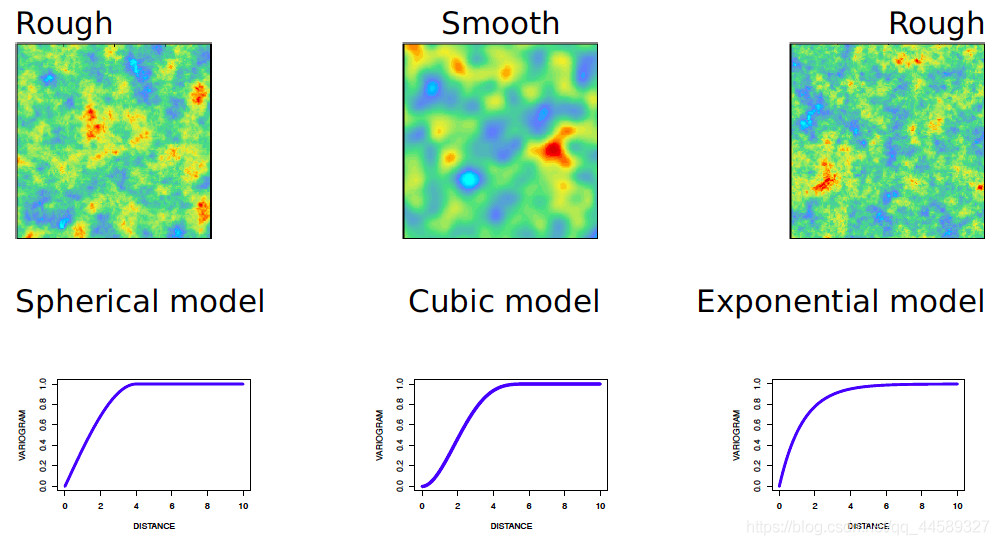
对于球状模型与指数模型来说,插值结果表面比较粗糙,而对于高斯模型来说,插值结果较为平滑,是因为高斯模型的空间相关性随步长先增加后降低,连续性较强。
线性有基态值模型
γ(h)=⎩⎨⎧0C0+AhC0+Ch=00<h<ah=a
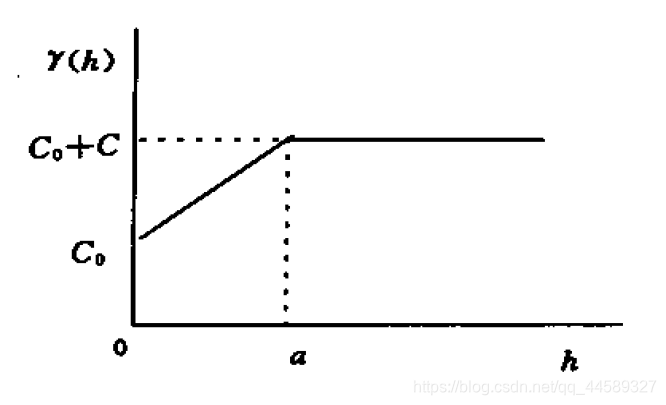
C0,C0+C,C,A分别为块金常数、基台值、拱高、斜率
纯块金效应模型
γ(h)={0C0h=0h>0

4.1.2无基态值模型
线性无基态值模型
γ(h)={0C0+Ahh=0h>0

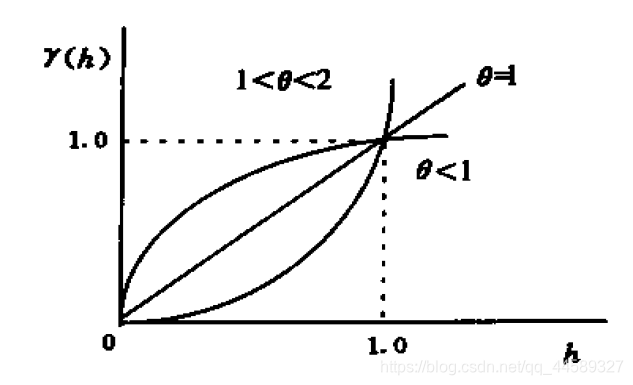
幂函数值模型
γ(h)=Ahθ 1<θ<2
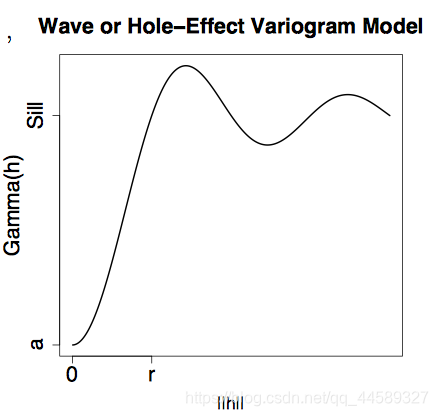
4.1.3孔穴效应模型
变异函数在h大于一定距离后并非单调递增,而是以一定的周期b进行波动,此时变异函数曲线显示出一种”孔穴效应(hole effect)”.
孔穴效应模型包括有基台值模型和无基台值模型
有基台值
孔穴效应模型一般用于当数据呈现出一定周期性的情况,孔穴效应模型的变程为:当变异函数的值等于先验方差时所对应的最短步长
γ(h)={0C0+C(1−πhrsin(πh/r))h=0h>0
4.1.4时空变异模型
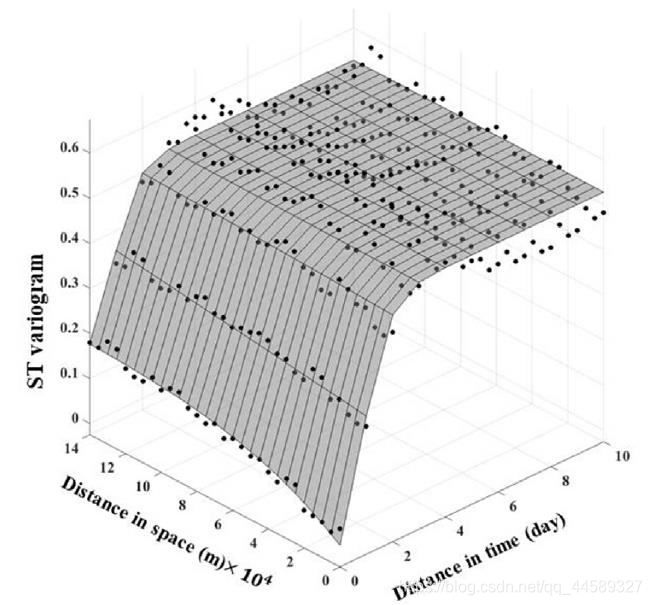
γ(hH,hV)=(c0+c)−c[1+w21(hH+αhV)2]−2ve−ξ1∣hH+αhV∣
三维情况下,理论模型比二维情况下要复杂,
c0+c基态值,当
hH,hV均为0,等于
c0+c−c=c0,d当二者趋近于无穷大,
c0+c,发现在随着距离的递增与时间递增,也是趋近于一个平面的,也有变程的概念,称为时空上的变程,时间上的变程在5-6d,空间上的变程在此例中还没出现,
4.1.5影响变异函数的主要因素
随着样点间距增大,样点差异性逐渐增大,某些小尺度下的结构特征将变得不明显,因此需确定采样最小尺度,从而保证精度且不过分增加采样强度。
支撑大小,即取样尺寸、形状和方向。小支撑尺度采样,样本内的差异一般小于样本间的差异,而大支撑度采样则样本内变异增大,从而消除样本间的差异
样本数量(此为样点对的数目)在小距离上比在大距离上多。一般,统计计算时样本的数量越多,结果越精确,但在实际工作中,一般要求在变程以内各距离上的点对数目不应小于20对
变程范围内的特异值(异常值)会导致块金常数增大,即变异函数的随机成分增加,自相关性减弱。但是变异函数模型块金效应越小越好(特异值会使方差变大使得总体的值提升,特异值在区域的中心会比区域的边上对计算结果影响更大,因为在区域中心,特异值在各种滞后距下,对更多的点进行配对,如果在区域边缘,进行配对的概率就小,参与到试验变异函数计算次数就少,因此特别是在短距离范围内情况下,特异质的影响会更大)
比例效应会导致实验变异函数值产生畸变,使基台值和块金值增大,导致结构特征不明显,使克里金估计精度降低,可通过对原始数据取对数来消除比例效应影响(存在比例效应,数据是不符合正态分布的,数据有一定的趋势,不符合平稳假设)
4.2变异函数的套合结构
套合结构,就是把分别出现在不同距离h上或不同方向上同时起作用的变异性组合起来,对全部有效的结构信息,作定量化的概括,以表示区域化变量的主要特征
套合结构可以表示为多个变异函数之和,每一个变异函数代表一个方向一种特定尺度上的变异性。
单一方向上的套合
套合结构中每一个变异函数代表同一方向上的一种特定尺度的变异,并可以用不同的变异函数理论模型来拟合,即单一方向的套合结构
r(h)=r0(h)+r1(h)+......+rn(h)=i=0∑nri(h)
ri(h)可以是相同的或不同的理论模型
举例:
土壤是一个不均匀、具有高度空间异质性的复合体,它与土壤母质、气候、水文、地形和生物等因素有关,分析土壤空间变异的因素,可将其变异分为系统变异(土壤形成因素相互作用造成)和随机变异(可以观测到的,但与土壤形成印务无关且不能直接分析的)两大类,
由h分开的两个点
x和
x+h的土壤某一性质
Z(x)和
Z(x+h)。当h趋近于0时,可以认为两点间的差异完全是由取样和测定误差造成,当
h逐步增大,如
h=10m,差异可能还要加上诸如水分等因素,当
h=100m时,在新的变异要考虑地形的作用
若设由取样和测定误差引起变异为
ϒ0(h),由水分引起的变异为
ϒ1(h),由地形引起的变异为
ϒ2(h),则当两点相距100m时,实际上两点的土壤变异性质为
ϒ(h)=ϒ0(h)+ϒ1(h)+ϒ2(h)
ϒ0(h)代表微观上的变异,变程
a0极小,可用纯块金效应模型模拟,
ϒ1(h)代表由水分引起的变异若用球状模型模拟且变程为
a1=10m,
ϒ2(h)代表由地形引起的变异若用球状模型模拟且变程为
a2=100m
最终得出的套合模型结果如下:
r(h)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧c0c0+c1{23a1h−21(a1h)3}+c2{23a2h−21(a2h)3}c0+c1+c2{23a2h−21(a2h)3}c0+c1+c2h=00<h≤a1a1<h≤a2h>a2
4.3变异函数理论模型的最优拟合
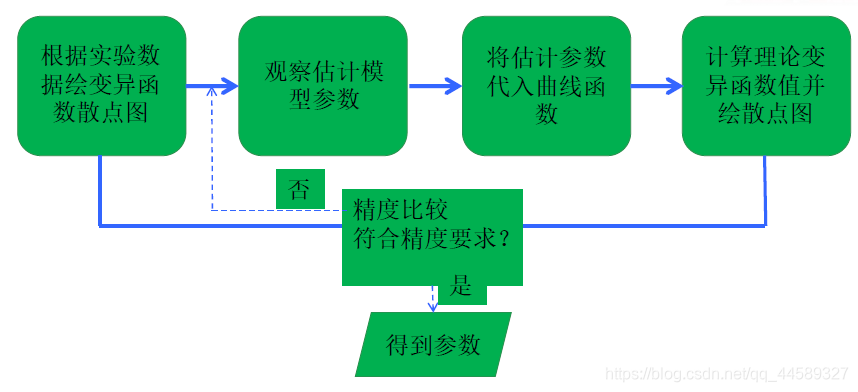
为了定量地描述整个区域的变量特征,需要根据实验变异函数值,选择合适的理论模型来拟合一条最优的理论变异函数曲线,用以更精确反映变量的变化规律
变异函数理论模型的最优拟合主要包括步骤:
4.3.1确定变异函数模型形态
根据变异函数散点图判断,
有基台值模型,无基台值模型,空穴效应模型?
是否存在单一方向上不同尺度的套合情况?
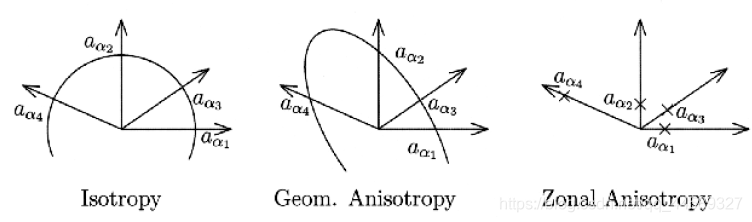
是否存在各向异性?
4.3.2模型参数的最优估计
对于不同模型,待估参数有所不同
参数估计通常有下列两种方法:
4.3.2.1人工拟合

4.3.2.2自动拟合
自动拟合主要是根据步长
(h)和变异函数
r(h)之间的关系来确定变异函数模型参数
普通最小二乘拟合
利用最小二乘法估计变异函数模型参数的核心思想:
(r,s,a)mink=1∑kˉ(γ^k−γ(hk;r,s,a))2
其中
γk^代表根据实验数据所得到的变异函数值
γ(hk;r,s,a)代表理论变异函数模型,其参数为
r,s,a变程,基台值,块金常数
缺点:不应该把变异函数靠近原点附近的点与其他点平等对待,因为原点附近的点对于反映空间自相关性更加重要
加权最小二乘拟合
加权回归法的核心思想:以样点对的个数作为权重,因为距离小的样点对要比距离大的样点对多,因此小距离权重大,突显了原点附近点的重要性
r,s,amink=1∑wk(γ^k−γ(hk;r,s,a))2
权重:
wk=γ(hk;r,s,a)2∣Nk∣,k=1,..,kˉ
4.3.3模型拟合评价
模型拟合评价包括
1.最优曲线检验:对参数和方程本身进行显著性检验。
2.模型比较:通过平均误差,决定系数(R2)等统计指标对不同的模型进行比较,从中选出最优拟合模型
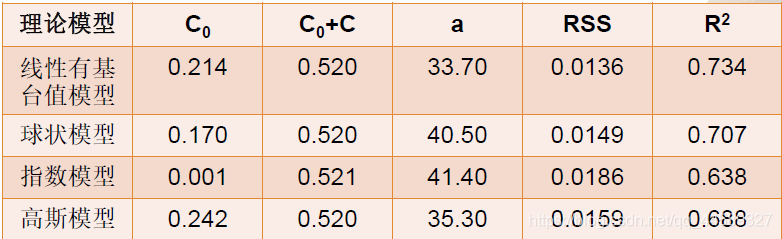
线性有基台值模型的残差最小,决定系数最大,其次是球状模型,基台值基本相同,但线性有基台值模型的变程最小,其次是高斯模型和球状模型。块金值是指数模型的最小,其次是球状模型和线性有基台值模型。
对这5个参数,显然最重要的是考虑决定系数R2的大小,其次是考虑残差RSS的大小,然后再考虑变程和块金值的大小,根据这个原则,选择球状模型作为本实例的变异函数理论模型是比较合适的,这个理论模型除了具有较高的拟合精度外,对变程内的模拟可以得到满意的结果
4.4基于优化搜索算法的参数拟合
对于结构复杂的变异函数理论模型,特别是套合结构模型,参数复杂,难以用一般的通用方法求解出模型中的参数。但一些智能优化算法,如遗传算法、模拟退火算法、蚁群算法能够使用统一的流程求解出接近最优的参数。
以遗传算法为例,介绍该算法在求解套合结构模型时的流程
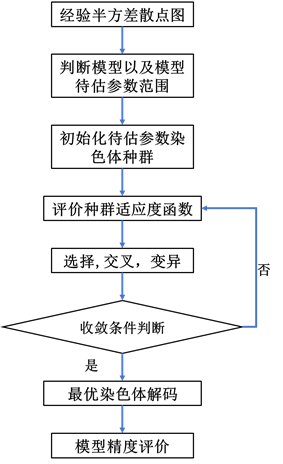
1.多尺度套合模型的规范表达
在单一模型中均带有块金值
c0,为实现套合模型将块金值部分表达为纯块金模型,即
r(h)=c,单一模型就转变为块金模型与一个代表空间相关的函数
ri(h),每个的函数可表达为
cf(h,a),当
h大于变程时,
r(h)的值为前面若干模型系数
c的和,其结果也成为基台值,因此可将套合模型表示为若干个模型叠加,即
r(h)=r0(h)+r1(h)+⋯+rn(h)=∑i=0nri(h)=∑i=0ncifi(h,ai)
其中
a0=0,ai>ai−1,fi中
h取值范围为
[0,+∞],对于每个
ri(h)当
h>ai时对于球状与线性模型
fi=1对于指数模型与高斯模型
fi=0.95因为指数与高斯模型中
h=a,r(h)=c0+c(1−e−3)=c0+0.95c,因此在计算时要考虑这个近似值,避免跳跃
2.编码策略与初始化种群
需要求解参数为
2n+1个(第一个模型总为纯块金)在实际计算中令
ci=∑j=0icj,从经验半方差图识别
ci取值区间,并有以下约束:
ci>0,ci>ci−1,ai>0,ai>ai−1
假设需要顾及
m(m<=2n+1)个参数,每个参数的取值范围和估值精度分别是
Umin,Umax和
Qi,则将
m个参数分别以
L1,L2,……,Lm为长度进行二进制编码,其中
Li=ceil(log2(QiUmaxi−Umini))
则每条染色体长度为
∑i=1mLi染色体中每个参数编码对应的解码公式为:
mi=Uimin+(k=1∑Libk2k−1)×2Li−1Umaxi−Umini
3.确定个体适应度评价函数
根据统计学思想,对理论模型的最优拟合实质上就是让理论变异函数值和实际变异函数值之间的方差最小,然而在实际计算中,实际变异函数曲线上个点的重要性是不同的,往往滞后距小的点的重要性要大于滞后距大的点,因此采用以滞后距的倒数作为权系数参与适应度评价函数的构建,最终函数形式为( 函数值越大,个体适应度越高)
fi=∑i=1N(h)wi∗(r∗(hi)−r(hi))21
其中
wi=hi∑i=1N(h)hi
4.遗传操作
遗传算法主要包括3个基本算子,即选择、交叉和变异,为此,需确定交叉概率
Pc和变异概率
Pm,3个过程执行以后,将产生新一代种群,并记录适应度最高的染色体。
采用轮盘赌法,利用比例介于各个个体适应度的概率觉得其遗传下一代的可能性。若种群数位
T,个体适应度为
fi,则每个个体被选取的概率为
Pi=∑k=1Tfkfi,当个体选择的概率确定后,产生
[0,1]之间的均匀随机数来决定哪个可以遗传到下一代后续计算。
采用单点交叉,只有一个交叉点位置,按照交叉概率随机选择经过选择操作后种群个体交叉对象,两两配对,然后随机产生交叉位置,从而产生新个体。

采样多点交叉

实验基本位变异法,按照变异概率,随机选择需要变异的个体,再个体在随机选择变异位置,将0变1,1变为0,从而产生新个体。
5.收敛条件判断
收敛条件判断常常有两种,历代以来适应度值相差小于某个阈值,还有一种是设置最大迭代次数。
课堂讨论题
1.如何改进上述算法,在用户不能确定理论变异函数类型时,能自动匹配模型类型并进行参数估计
对给定的
n个套合模型中,每个模型附加一个模型类型编码,模型类型编码长度由模型类型的个数决定,构建基本模型类型函数库,假如模型库中有4个常用模型(线性有基台值、球状、指数、高斯),那么模型类型编码长度就是两位,假定00,01,10,11可以分别代表上述四个模型。
假定用
n模型进行套合,那么要求解的估计参数就有
3n+1个,其中有
[c0,c1,...,cn]以及对应的变程
[a1,a2,...,an]以及模型类型参数
type1,type2,...,typen,因此每个种群对应的解空间定义如下:
S=[c0,c1,…cn,a1,a2,…an,type1,type2,…,typen]
在交叉和变异时,交叉对模型类型的染色体片段不进行交叉,在变异时大概率来进行模型类型的变异
2 如何在程序设计或功能界面上提高此算法的运行效率,使算法能够尽快找到较好的解
采用自适应双交叉点遗传算法
根据适应度动态调节交叉概率和遗传概率大小
交叉概率
Pc 和变异概率
Pm 对遗传算法性能有很大的影响,直接影响算法收敛性1。虽然
Pc 较大的时候种群更容易产生新个体,但是当其变大时,优良个体在种群中保留率也降低。对
Pm 来说,若其过大则本算法相当于普通的随机算法,失去了遗传算法的意义。直接给出Srinvivas提出的自适应遗传算法(Adaptive GA, AGA)方法
对于适应值高于群体平均适应值的个体,对应于较低的交叉概率和变异概率,使该个体得以保护进入下一代;而低于平均适应值的个体,相对应于较高的交叉概率和变异概率,使该个体被淘汰掉。因此,自适应遗传算法能够提供相对某个解的最佳交叉概率和变异概率
Pc={Pc1−fmax−favg(Pc1−Pc2)(f′−favg),Pc1,f′≥favgf′<favgPm={Pm1−fmax−favg(Pm1−Pm2)(fmax−f),Pm1,f≥favgf′<favg
fmax——群体中最大的适应度值
favg——每代群体的平均适应度值
f′——要交叉的两个个体中较大的适应度值
f——要变异的个体的适应度值
Pc1=0.9,Pc2=0.6,Pm1=0.1,Pm2=0.001
3.通过学习的内容,谈谈对参数拟合问题有何启发
4.5结构分析步骤
1.区域化变量选择
- 根据具体研究目的而定,要有明确物理意义,最好能定量表示。
- 支撑大小、形状与取样,测试方法应相同。
2.数据获取与审议
- 审议内容包括取样设计,样点间距离的大小,取样方法,数据的代表性,数据均匀性,时空一致性,原始数据的记录,是否存在系统误差等
3.数据统计分析
数据统计分析指对取样数据计算平均值、方差、变异系数、偏度、峰度等统计指标,并进行相关、正态、趋势、各向异性等特性分析,目的在于对数据特性进行初步了解,提出简单明晰的解释
4.变异函数计算
5.变异函数结构分析
结构分析的目的在于通过分析各种实验变异函数来分析所研究区域化现象的主要结构特征,包括各向同性,各向异性,块金效应,套合结构等
6.变异函数最优拟合及检验
为了研究区域化现象,需要根据实验变异函数散点图拟合理论变异函数模型。理论模型的优劣可通过统计指标来检验
7.变异函数理论模型的专业分析