
1. 基因组基础概念
大家好,我是飞哥。
前几天推荐了这本书,可以领取pdf和配套数据代码。这里,我将各个章节介绍一下,总结也是学习的过程。
引文部分是原书的谷歌翻译,正文部分是我的理解。
这本书共有三大部分,分别是:

- Foundations,基础
- Working with Genetic Data,实战
- Applications and Advanced Topics,进阶
第一部分基础,分为六个章节,分别是:
- 第一章:基因组基础概念
- 第二章:统计分析概念
- 第三章:基因型数据参数
- 第四章:GWAS分析
- 第五章:多基因效应
- 第六章:基因与环境互作
今天,介绍第一章的内容,看一下目录:

本书写作的目的
2003年,人类基因研究首次对人类基因组进行测序,这在理解和纳入研究的方式上引发了一场革命。随着计算能力、数据可用性和新技术的进步,这一研究领域打破了我们如何看待疾病和行为的许多传统。遗传学现已超越生物学、流行病学、医学、心理学、精神病学、统计学和人口学、社会学和经济学等社会科学。有史以来第一次有可能将大规模分子遗传信息整合到跨广泛主题的研究中。许多人认为,统计遗传数据分析只适用于数量遗传或统计研究学科范围内的广泛研究团队和高度专业化的科学家。这本书的目的是向来自不同学科背景的应用研究人员展示如何理解、应用和处理你自己研究课题的遗传数据。本书中的知识将使您能够正确、负责任地理解和解释数据,并将其作为蓝图应用于您自己的数据和研究。我们还希望,通过使这种类型的数据分析更容易获得,我们朝着更崇高的目标努力,既要使作为非人道遗传学研究对象的人多样化,又要使研究人员本身和所涉及的主题多样化。
这本书的目的是向学生和研究人员介绍新兴的概念数据,以及统计遗传数据分析的方法,以一种方便、实用和我们希望参与的方式。这本书是为那些在分子生物学、人类遗传学或细胞生物学方面没有很强背景,但希望将遗传数据整合到研究中的人编写的。这本书的编写考虑到了广泛的可访问性,将吸引来自多学科背景的学生和研究人员,他们是这一研究领域的新手。在统计学或生物统计学课程的第一级掌握统计方法的基本知识是最好的。我们的方法是实践和应用的,重点是包装基本概念,这个“做和不做”,以及如何实际运行和解释分析。我们只提供材料的基本数学和统计处理,并为那些想深入挖掘的人提供参考。考虑到遗传学的深远影响,我们预计来自医学和社会科学的学生和研究人员会感兴趣,他们将越来越多地将统计与对他们的思维和工作方式进行科学的遗传数据分析。
我本身是学习动植物数量遗传学的,工作中也经常用到生物统计、数量遗传学、GWAS和GS,但是对于GWAS,人类上面研究得更系统,所以阅读此书,我认为可以加深对基因组数据分析的理解,毕竟,不同软件不同代码只是工具,而理解背后的意义,会“知其然亦知其所以然”。人类的GWAS分析有其特定的概念,比如多基因得分,比如GbyE,对于动植物上面分子标记辅助和基因组选择,也是非常有帮助的。
谁适合读这本书
这本书是为当前和有抱负的学生和研究人员准备的,他们来自任何以经验为导向的医学、生物学、行为学或社会科学学科,希望了解人类统计遗传数据分析的主要概念,同时也是寻求进入和开展这项研究的解决方案的从业者。读者可以通过动手电脑练习获得应用分子遗传数据分析的蓝图,重点是实体解释。这是一本介绍性的书,写给那些在分子生物学、人类遗传学或统计遗传学方面没有很强背景,但希望整合遗传学的人,他们研究的数据。在非统计或生物统计学课程的第一级掌握统计方法的基本知识是最好的。如果您首先在R和Rstudio中从事一些背景教程工作,并且对于一些更高级的应用程序,您将对Python有一个基本的了解,那么您将从本书中获得最大的收获(请参见附录1)。我们还共同致力于统计遗传数据分析的基本术语和实践方面,而不是其背后的数学、统计学和生物学。读者可以参考进一步阅读部分和每个章节中的参考资料了解更多信息
这本书的对象可以是:医学、生物学、行为学或者社会科学,只要牵涉到基因遗传数据,就可以用到里面的分析方法。编程语言是R和Python,还有plink、GCTA独立的软件。
第一章节的主要内容

目的了解这本书的动机、目的、目标受众和结构定义、认识和描述人类基因组研究中使用的基本术语理解人类细胞核中DNA的组织以及术语基因组、基因和染色体概述孟德尔定律。有性生殖和遗传重组定义了遗传多态性和术语等位基因、单核苷酸多态性次要等位基因频率和唯一识别物了解单基因、多基因、全基因效应和多基因评分要求掌握基因与蛋白质关系的基本知识掌握分子生物学的中心法则:转录和翻译了解多态性位点是纯合还是杂合的,了解显性和隐性性状的遗传关系认识到遗传力的意义,常见的误称、类型和缺失遗传性讨论
染色体、基因、DNA和SNP
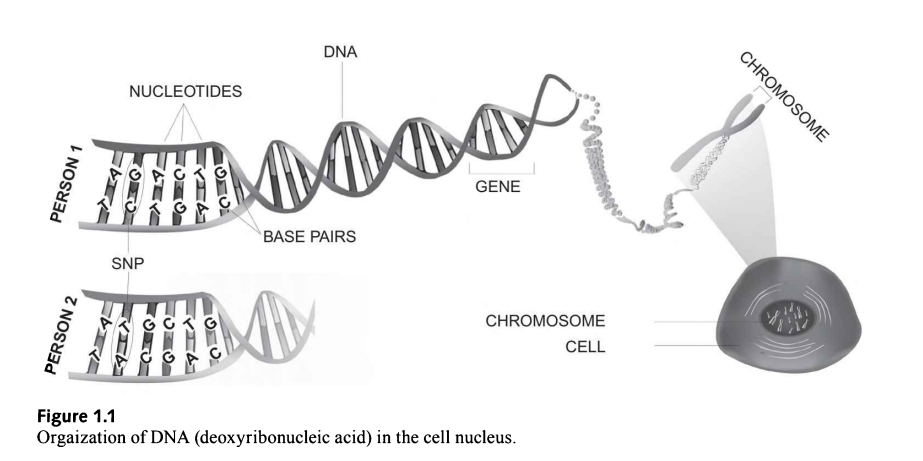
上图介绍了不同物质的关系,细胞中是染色体,染色体是双螺旋的DNA构成,一段DNA构成基因,DNA由碱基对构成,SNP的概念。
孟德尔定律、有性繁殖和基因重组
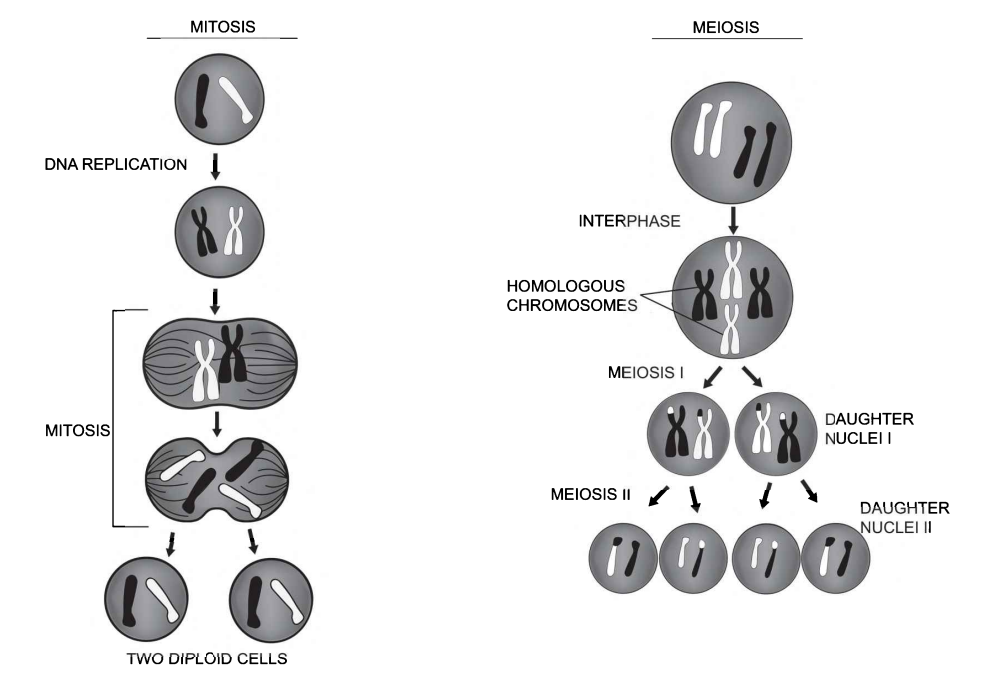
孟德尔分离定律和自由组合定律,以及摩尔根的连锁定律,是遗传学的三大定律。
等位基因、SNP和次等位基因频率(MAF)
MAF的区间划分:

- MAF < 0.01,稀有变异(rar variants)
- MAF 在[0.01,0.05],低频率(low-frequency)
- MAF > 0.05,正常变异(common)
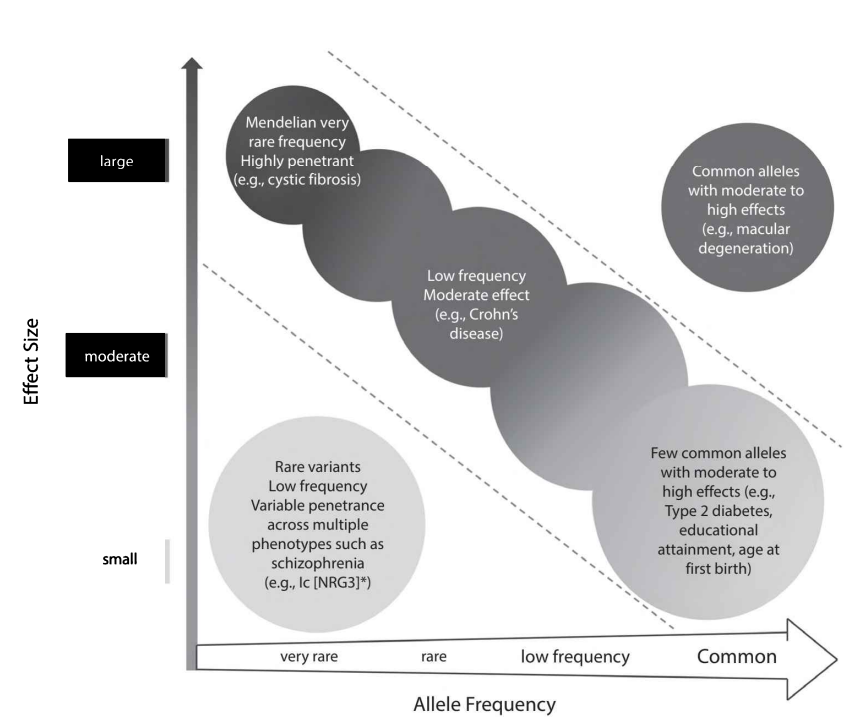
基因频率(MAF)和基因效应(Effect)的区间划分。
单基因、多基因和全基因效应
- 单基因:Monogenic
- 多基因:Polygenic
- 全基因:omnigenic
纯合子、杂合子、显性隐性基因

纯合子和杂合子是基因是否是纯合的,显性和隐性是表型的变化。
广义遗传力和狭义遗传力
广义遗传力:
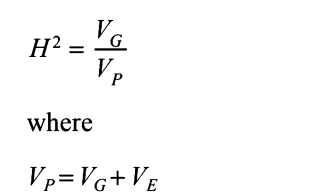
狭义遗传力:
G进一步剖分,下面公式中Vi后面的VG应该是GbyE的部分,这里应该是印刷错误。

关于遗传力常见的误区

- 第一个:遗传力与个人无关。比如肥胖的遗传率是25%,它的意思不是说一个人肥胖的原因是有25%的原因来源于遗传,75%的原因来源于环境。而是说明肥胖指标BMI 25%的差异与个体间的遗传差异有关系。
- 第二个:单个群体内的参数。遗传力估计不能用来比较不同群体或国家之间的遗传差异。例如,身高的可持续性估计为80%,并不意味着荷兰和美国之间的平均身高差异主要是由于基因差异造成的。虽然每个特定群体内的变异可能是基因遗传导致的,但群体之间的差异可能是环境的。需要注意的是,对于某些表型,例如色素沉着或肤色的差异,他们在很大程度上是遗传的,虽然肯定有环境因素。
- 第三个:这与遗传不同。遗传是后代与其亲生父母之间的关系。它不仅衡量遗传因素,而且还衡量家庭成员共享的环境、文化和其他因素。
- 第四个:遗传力很低并不一定意味着遗传贡献很小。低遗传力可归因于表型相关基因缺乏变异或高的环境变异。一个直截了当的例子是,尽管颈椎的数量与遗传成分高度相关,但每个人的颈椎数量都是一样的。变异很小,因此没有或很少有遗传因素引起的变异。
Family遗传力,SNP遗传力和GWAS遗传力
第一种:Family遗传力
MZ:monozygotic,同卵双胞胎,同卵全同胞
DZ:异卵全同胞
假定A是加性方差组分,C是共同环境,则同卵双胞胎是A,异卵双胞胎是A/2,E是残差方差组分,
那么:A + C + E =1
r M Z = A + C rMZ = A + C rMZ=A+C
r D Z = A / 2 + C rDZ = A/2 + C rDZ=A/2+C
那么遗传力的计算方法是:
h 2 f a m i l y = A A + C + E = A = 2 ∗ ( r M Z − r D Z ) h2_{family} = \frac{A}{A+C+E} = A = 2*(rMZ - rDZ) h2family=A+C+EA=A=2∗(rMZ−rDZ)
用它来估算遗传力,是狭义遗传力的最高值。
第二种:SNP遗传力
是使用全部的SNP估算的狭义遗传力,可以使用GCTA的GREML进行估计方差组分,计算遗传力。这里相当于GBLUP中的遗传力的计算。
第三种:GWAS遗传力
这是由GWAS定位出的显著性的位点或者基因,可以解释的百分比计算而来,它是最低的。
消失的遗传力
Missing and hidden heritability
消失的遗传力,是家系遗传力和GWAS遗传力的差,它又可以分为:still-missing和hidden两部分。它形成的主要原因是:
- 非加性效应
- 稀有大效应位点
- 共同环境效应

Still-missing遗传力,是家系遗传力和SNP遗传力的差。主要是有稀有变异以及结构变异(structural variants)导致,会随着分子标记的发展而降低。

Hidden 遗传力,是SNP遗传力和GWAS遗传力的差。主要是有与统计方法,无法检测出小效应的SNP变异,这部分的变异不是消失了,而是隐藏起来了,主要是因为显著性的阈值

整体而言,hidden遗传力,会随着样本量的增大而降低。still-missing遗传力会随着分子标记的发展(可以捕捉更多的变异)而降低。

常见性状的遗传力
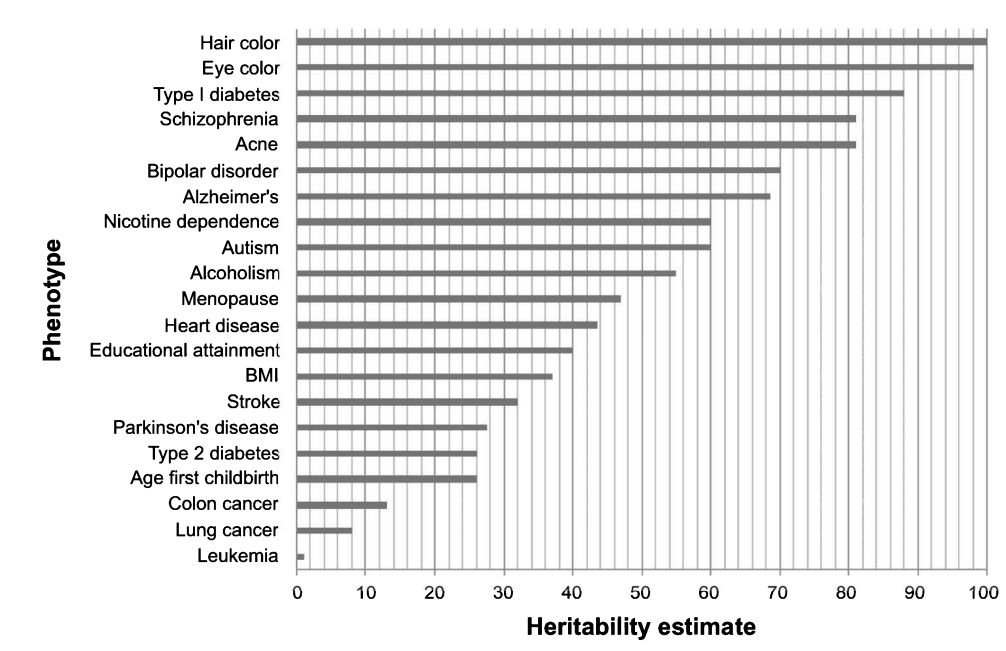
总结
进入数量统计遗传学的学科领域可能令人望而生畏。在这一章中,我们的目的是提供这一研究领域的主要构建块和基本概念的直升机视图。我们认识到这是一篇快速而简略的文章,并鼓励有兴趣的读者在你对这些概念更熟悉的时候,进一步深入研究更详细的文献。本章将为您提供基本知识,以区分主要概念,如表型、DNA、基因组、基因、染色体和基本过程。遗传多态性为您理解这个主题提供了基础,包括术语等位基因、单核苷酸多态性(SNP)和次要等位基因频率(MAF)。在这本书中,你会发现我们经常研究的许多复杂性状都是高度多基因的。掌握基因如何与蛋白质相关的过程以及分子生物学的中心记录似乎很重要。本书中我们研究的许多主题都是由孟德尔定律和我们对有性生殖过程中基因重组的理解以及显性和隐性性状的传播所决定的。最后,我们总结了遗传力、常见误称、不同类型以及缺失和隐性遗传力的概述。在下一章中,我们将从人类基因组的基础知识转移到一本统计入门,然后介绍人类进化。在这里,我们将遗传学的基本概念从这一介绍性章节链接到人类传播和进化的较长历史所支持的统计概念
飞哥总结
第一章部分,主要介绍基因组数据的基础概念,包括染色体、基因、DNA,MAF等概念,让我受到很大启发的是对于遗传力的介绍,包括狭义遗传力和广义遗传力,还介绍了具有人类特色划分的家系遗传力、SNP遗传力和GWAS遗传力,并将消失的遗传力分为了两部分:still-missing和hidden,前者会随着检测技术和分子标记的进展而降低,比如讲拷贝数变异、结构变异放到模型中。第二个hidden会随着样本数的增加而降低,因为这部分主要是受到显著性阈值的影响。
想到前几天发的番茄处理消失遗传力的论文,按照这本书中的定义,应该解决的是消失遗传力中still-missing的部分。