大家好,我是飞哥。
前几天推荐了这本书,可以领取pdf和配套数据代码。这里,我将各个章节介绍一下,总结也是学习的过程。
引文部分是原书的谷歌翻译,正文部分是我的理解。
第一部分基础,分为六个章节,分别是:
- 第一章:基因组基础概念(这部分介绍过了,点击进入)
- 第二章:统计分析概念
- 第三章:人类进化入门
- 第四章:GWAS分析介绍
- 第五章:多基因评分和遗传结构介绍
- 第六章:基因与环境互作
今天,介绍第五章,多基因评分和遗传结构介绍,看一下目录:
主要内容

本章节包括:
- 定义和理解多基因评分的起源
- 理解使用多基因评分的过程和流程图
- 理解构建多基因评分的主要原则
- 了解多基因评分验证和预测的基础
- 掌握围绕表型共享遗传结构的概念以及检验这一点的潜在方法(相关性、多效性、多序列分析)
- 引入到多基因评分因果建模的应用中(遗传混杂、孟德尔随机、基因-环境相互作用)
- 认识到中心挑战、问题原因以及使用多基因评分的潜在解决方案
GWAS介绍
大多数表型和健康状况的遗传结构本质上是多基因的。多基因指的是这样一个事实,即它不是单个或少数变体,而是数百或数千个变体,每个变体对表型的影响都很小。
虽然有些单基因疾病如亨廷顿病具有单基因效应,但我们研究的大多数性状都是多基因的。随着全基因组关联研究(GWASs)和更大样本的增长,PGSs越来越成为定量遗传研究领域的主要工具。
本章的目的首先是让您了解多基因得分、它们是如何出现的,以及有效应用它们的核心挑战和潜在解决方案。第二个目标是为您提供如何在该领域开展自己研究的蓝图。我们在图5.1中的流程图概述了步骤,以及为第一次进入该字段的人员使用PGSs的可能性
包括PGS的数据、验证和处理、生成和预测的初始阶段。一些读者可能还想更深入地研究表型的共同遗传结构。然后是本章讨论的各种建模应用程序,然后应用于本书的第二部分和第二部分。在表5.1中,我们进一步总结了与PGSs合作的主要挑战,解释了这些挑战存在问题的原因,并提供了潜在的解决方案和关于该主题的进一步阅读。本章提供了必要的背景知识,您需要在第10章中创建和验证PGS,然后在第11-13章的各种情况下将其正确应用于统计模型。
第一层:搜集数据、整理数据
- 包括搜集GWAS的summary 结果
- 表型数据和基因型数据检测

第二层:验证和处理
- 群体结构,亲缘关系
- 查看共有变异(提升稀有变异)
- 消失和隐藏的遗传力
- 生物路径相关性分析

第三层:计算多基因评分和预测
- 选择显著性位点和权重
- 根据P值选择
- 对PGS如何影响性状进行可视化

第四层:检查表型的共享遗传结构
- 预测表型
- 表型相关:通过LD Score回归计算
- pleiotropy
- 多性状分析:MTAG

第五层:模型应用
- 预测个体风险
- 孟德尔随机化分析
- genetic confounding
- 基因与环境互作

多基因评分
Polygenic score
什么是PGS?
什么是多基因评分?多基因评分(PGS)是多个遗传位点与表型之间关系的数值总结。PGS有时被称为多基因谱评分、遗传谱评分、基因型评分,或者在讨论疾病时,被称为多基因风险评分。我们采用更中性的polvgenic评分,因为当我们讨论非疾病相关的行为表型时,用“风险”来表述就不那么直观了。Polvgenic得分直接来自我们在第4章中概述的GWASs中的全基因组关联。我们使用这些数据的汇总统计数据来估计单核苷酸多态性(SNP)如何结合来解释感兴趣的特征。
实际上,PGS是整个基因组表型相关等位基因的线性组合,通常由GWAS效应大小加权。因此,这是一个单一的定量指标,可以解释为个体相对于群体的表型遗传倾向的指标。对于我们感兴趣的大多数性状而言,单个SNP(如第1章所述,单基因)是弱预测因子。复杂的性状与许多遗传变异有关,每一个变异都只占变异的一小部分。PGSs是一种跨基因组聚合这些信息的解决方案。
一般来说,我们可以将一个人的多基因得分定义为一个人在M基因座的基因型的加权和。个体i的PGS可以计算为每个SNPj=1的等位基因计数A(0、1或2)的总和。⋯…M、 乘以重量w,
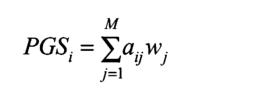
这里的权重w是GWAS系数的变换,这个方程表明它是多个SNP对表型影响的线性组合。PGS的基础模型通常也是加性的,因为我们计算得分中每个SNP的“风险等位基因”数量。然而,我们注意到,隐性或显性模型可用于构建PGS。由于其结构中包含大量SNP,V也遵循正态分布(见方框5.1)。另一个假设是,由于假设SNP效应是独立的,因此不存在基因-基因相互作用(或上位性)。
PGS的来源
PGS符合正态分布。
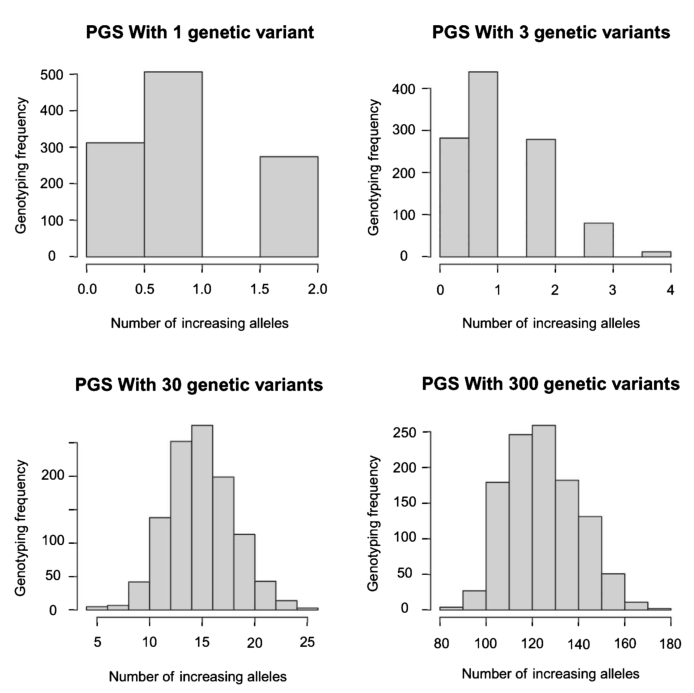
多基因评分可以被认为是许多独立遗传信号的总和。统计学中概率论的一个中心前提,即中心极限定理,确定了当许多独立的随机变量相加时,它们的总和趋向于正态分布,而与单个变量的原始分布无关。这通常被非正式地称为“钟形曲线”正如我们下面的模拟所示,等位基因的数量越多,越接近正态分布。
因此,多基因评分往往具有正态分布,因为评分中包含的SNP数量足够大[19]。
Risch、Merikangas及其同事在1996年的《科学》杂志上证明,对于复杂的表型,GWASs比当时使用的全基因组连锁研究具有更强大的能力【24】。第一份精神分裂症GWAS于2008年出版【25】。随后,2009年发表在《自然》杂志上的一项更大规模的研究(约13000例病例:35000例对照)[26]。
2009年,国际精神分裂症协会“未能”确定预测这种高度遗传性精神障碍的任何特定SNP,这是创建PGSs的关键转变之一。研究团队决定深入挖掘并调查所有SNP的作用,以费希尔1918年的无穷小模型的形式重新审视多基因遗传的最经典理论之一【27】。回想一下,无穷小模型假设定量(连续)表型由无限多个基因座控制,每个基因座的影响非常小。该研究小组并没有寻找少数具有更大预测能力的基因,而是声称可能存在数千个verv小个体效应,这些效应共同解释了遗传力的很大一部分。然而,那些来自样本量较小的GWAS的变异不会出现在GWAS中,因为它们没有达到全基因组意义,例如,考虑一个SNP,其中一个风险等位基因只会增加精神分裂症的相对风险5?需要用极小的标准误差来估计如此小的影响,才能低于5×10-8的显著性阈值,这是GWAS中全基因组显著性的标准标准(见第4章)。因此,即使在相对较大的样本中,它也很可能未被检测到。因此,研究小组首先只计算出包含高度显著SNP的得分,然后通过不断将p值阈值放宽到0.5来重新计算得分,基本上包括所有SNP中的50个。他们使用这组分数并生成了一个不属于原始GWAS的样本来预测精神分裂症。他们发现,随着p值阈值的放宽,方差的解释增加了。
这意味着即使被认为是“无意义”的遗传变异也可以解释表型的变化,尽管它们的个体效应和机制尚不明确。
虽然这项最初的研究已经表明精神分裂症是高度多基因的,但后来的研究更精确地量化了期望值,发现约8300个独立的SNP对该表型有贡献【28】。从那时起,不同群体的多个GWASs已经发表,更大的研究导致更精确的PGS估计。
构建PGS
在第10章中,我们展示了如何构建PGS的实用性,然后介绍了如何在性状预测的多个应用程序中验证和应用它们。作为混杂因素,并在第11章中检查基因与环境的相互作用。我们在第4章中详细讨论了发现。在本节中,我们将重点介绍构建PGS的陷阱和危险,但请注意,一些解决方案涉及详细的统计技术,这些技术仍然超出了本入门教材的范围。
GWAS分析需要大样本
随着时间的推移,GWASs的样本量快速增长并非巧合(见图4.5)。为了估计单核苷酸多态性对表型的影响,减少抽样误差非常重要,这可以通过在发现遗传标记时包含大量样本来实现。我们反复指出,复杂的表型受大量影响很小的未知SNP的影响,因此需要大量的发现样本。如第4章所述,对于许多常见性状,发现样本量目前已达到100万左右。多位作者已经证明了SNP效应的准确性,以及通过扩展PGSs,如何随着样本量的增加而增加[1,2,29]。其他人现在越来越质疑,我们是否已经达到了回报减少的程度,现在应该将重点从发现更多的基因座转移到更深入地理解基因座的生物学功能。
筛选合适的SNP
我们在第10章中探讨了构建PGS需要两个关键决策:要包含的遗传变异的数量以及如何衡量其影响。最常用的方法是直接的最小二乘预测法[30]。由于我们在第10章(第10.3节)中讨论了修剪和阈值方法以及权重,因此在此不再重复。可以只选择GWAS重要SNP(p值<5×10-8)、介于两者之间的某个或所有SNP(p值<=1)。选择取决于表型和您将执行的应用程序类型。更严格的p值阈值通常被认为更适合非多基因性状,而更宽松的阈值对多基因性状表现最好。研究人员现在意识到,在性状不是多基因的情况下,实际上是非常罕见的,只有全基因组的显著变异被包括在内,以提高预测得分的准确性。当所有SNP都包含在高度多基因性状的PGS计算中时,你可以期望得到更多的预测结果。
然而,我们将很快讨论的一个挑战是在分析中包含更多变体以增加预测的权衡,这反过来又增加了非因果变体的潜在“噪音”,但也增加了作为代理SNP的因果变体(见框10.2)。
验证和预测PGS
PGS的验证巩固了其有用性。如果在此初始阶段得出错误的决定或结论,PGS可能缺乏准确性和准确性。验证也与预测内在地交织在一起。在本节中,我们将重点介绍基本和常见的错误,这些错误可能导致PGS的高估或结果的误解,有时会使用文献中的示例。预测是对R2的估计,R2是回归模型解释的方差比例。从这个意义上说,我们注意到预测是一个有点误导性的术语,因为我们通常有兴趣了解通过在模型中包含特定PGS可以解释的可变性量。大多数应用研究人员通常有兴趣了解与基线模型相比,将PG输入模型时R2的增量增加。
基线模型是最简单的预测,当添加其他变量时,您可以使用它作为基准点。在此,我们通常还包括人口分层变量(例如,前10或20个PCA)和其他相关协变量。在第10章和第1l章中,我们将演示如何进行预测,以及如何处理下面讨论并在表5.1中总结的一些问题。
独立的样本
在进行预测时,您使用的数据必须是一个独立的样本,也就是说,发现样本和目标样本之间没有重叠。换句话说,您使用的目标样本不应该是原始GWAS中包含的数据集之一,或者您需要将其从GWAS摘要结果中删除。我们在第7章(第7.3.3节)中讨论了如何以及在何处获取GWAS汇总统计数据。
如果您试图使用原始GWAS中使用的相同数据来验证或预测得分的表现,以同时估计SNP对表型的影响,那么您通过过度拟合高估了预测的准确性[3]。为了确保关联结果不会与您的基因型数据重叠,最好首先检查发现分析中包括哪些队列。该信息通常在已发布的GWAS文章中补充材料的初始表格中报告。许多作者越来越多地拥有一条准备好结果的管道,并准备好申请研究中的每个队列。越来越多的研究也将PGS作为其数据的一部分(如健康和退休研究)。如果不是这样,最好直接询问进行研究的研究人员,询问他们是否愿意分享荟萃分析的结果,不包括你想要分析的队列。请注意,这确实需要一定的努力,也需要原始作者的努力。或者,也可以使用另一个足够大的数据集和GWAS在单个非常大的研究中计算的汇总统计数据。一种解决方案是使用Ben Neale实验室的信息,该实验室利用英国生物库公开产生了4000多个表型的结果,还包含20个主成分和协变量(例如,年龄、年龄2、性别、年龄*性别)(http∶//www.nealelab。is/uk biobank/)。他们还生成了特定性别的结果,并包含了用于运行分析的所有代码,GitHub(https://github.com/Nealelab/UK生物银行GWAS)。偏差的程度还取决于各种因素,包括性状的遗传力、研究中的遗传异质性和样本量,我们将在稍后讨论缺失遗传力和隐性遗传力。如果vou计划使用的基因分型数据的样本量远小于整个GWA的样本量,则偏差可能是有限的。然而,这方面仍然需要考虑。
目标样本中有相似祖先
在选择目标样本时,祖先组成不应与初始基线样本有显著差异。回顾第4章,大多数GWASs都是对欧洲血统的人进行的,由于等位基因频率、LD和遗传结构的差异,这些结果不能直接转移到其他人群。Martin及其同事利用1000基因组参考小组,使用欧洲祖先GWAS汇总统计数据,计算了八种表型的PGSs。
他们得出的结论是,这些来自大规模GWASs的发现对其他群体的可移植性有限,我们在前面讨论了与人口分层的关系(第3章)。例如,由于祖先群体之间的等位基因频率不同(见方框3.2),使用从一个祖先群体衍生到一个非常不同的祖先群体的PGS将导致目标群体中非常不精确和有偏差的分数,即使表型是高度遗传的。在第9章(第9.4节)的后面,我们将如何通过不同主成分的聚类来区分人口中的不同祖先群体进行分类。
亲缘关系、群体分层和频率差异
当您选择要为研究分析的数据时,必须意识到由于人口分层,目标样本中PGS的潜在通货膨胀。例如,在弗雷明翰心脏病研究中,一项将PGS用于身高的研究表明,当相关个体被纳入分析时,R2从0.15膨胀到0.25【8】。Wray等人[3]还研究了从样本中移除相关个体时的差异,并通过与R2膨胀相关的不同人群分层主成分进行控制。正如我们在表5.1中所概述的,他们建议在发现和验证阶段使用传统上不相关的个体。在后面描述质量控制(QC)的章节中,我们将演示如何删除相关人员。这一错误发生在已发表的研究中,例如,Belgard及其同事[7]认为2014年分子精神病学孤独症基因研究[31]缺乏对人口分层的控制。
研究人员可能遇到的另一个问题是病例组和对照组之间人群分层的差异偏差。这可能会导致R2的虚假预测,但可以通过在单独的样本中执行严格的QC或验证结果来应对。
变异仅由缺失罕见变异的常见遗传标记解释
这里有各种用于识别SNP的全基因组“SNP芯片”,我们将在第7章中详细讨论。直到2018年左右,大量收集的数据收集了有关常见遗传变异的信息。我们讨论了这种基因分型的局限性以及其他地方的未来方向(见第7.2.3节和第15章)。由于LD,我们在GWAS中识别并在PGSs中使用的许多SNP可能不是实际的因果SNP,但可能在LD中有一个或多个因果变体。在大多数芯片上测得的SNP(直到最近)都有常见的等位基因,并且不可能是完全或中度LD,也不可能是罕见的变体。如果一个遗传变异与适应性相关,那么选择可以将一个等位基因的频率降低[32]。如果单核苷酸多态性对适应性有很大影响,那么因果变异的频率就会很低。迄今为止在许多GWASs中发现的SNP不太可能解释所有遗传变异,因为它忽略了罕见变异的贡献,因为这些变异没有被基因型SNP“标记”。例如,这解释了身高的家族遗传力约为0.7至0.8,与基于SNP或标记的较低估计值0.4之间的差异【33,34】。
这一讨论还与家族估计数的潜在膨胀有关,但也与“仍然缺失遗传力”一词有关,该术语指的是未被SNP完全标记的基因组变体。这使得Visscher和其他人认为,我们可以从动物研究中学习,因为这项工作解释了在牲畜(以及可能的人类)中,某些因果变异事实上很罕见,并且在具有常见SNP的贫血症患者中【10】。因此,该领域现在正朝着将罕见变异纳入预测的方向发展。例如,Ganna及其同事于2018年进行的一项研究【35】量化了罕见和超罕见编码变异对13个数量性状和10种疾病的影响。他们发现了罕见的有害编码变体对复杂性状的影响,结论是可能存在广泛的多效性风险。
消失的遗传力
我们试图解释的表型变异是遗传和环境因素及其相互作用的组合。因此,使用多基因评分是量化遗传因素的一种方法。回想一下第一章(第1.6节)中缺失的遗传力讨论,我们讨论了GWASs出人意料的低预测能力,以及从多基因性的角度思考的兴起。请记住,缺失遗传力是双胞胎研究估计值与GWAS遗传力估计值之间相对较大的遗传力之间的差距,而隐藏遗传力是基于SNP的遗传力(Yang及其同事[33]GREML模型)与GWAS遗传力之间的差异。由于首次发现的单核苷酸多态性仅解释了遗传力的一小部分[36],因此出现了一系列研究,研究非加性遗传效应[37],上位效应[38],异质性和/或基因-环境相互作用[11],以及因共有的环境因素[39]和罕见的非基因型变体的作用而导致的双胞胎研究的夸大估计[34]。
实现h’高水平估计的唯一方法是,我们能够识别影响该性状的所有遗传变异,并准确估计其影响。正如我们在本书中所注意到的,错误可能通过多种因素潜入分析中,如缺乏准确或协调的表型测量,需要重复测量,或如我们在下一章所述,由于与环境因素的相互作用[11,12]。
PGS R2显著增加的一个例子是后续GWASs的演变,如2型糖尿病研究(见第7章)和教育年限。例如,关于教育程度的第一个MetaGWA(40)产生了三个重要点击,第二个74个重要点击,第三个在2018年,超过1100个。加上包含了更多的遗传变异,这三项研究之间的主要区别在于样本量,从第一项研究中的约125000个个体增加到110多万个。同时,R从大约2?最初的GWA大约是7-10?相比之下,2018年的研究。全基因组研究中基于单核苷酸多态性的估计值约为20-25[1l,40],代表了我们可以期望通过加性模型发现的上限。
预测和理解生物学机制之间的权衡
重要的是要记住,对于PGSs,我们正在处理一个定量结构,并且表型的基础生物学非常复杂。由于多态性,单基因中常见的变异是弱预测因子。然而,单个基因对于理解生物学和因果功能至关重要。正是从研究这些单一基因的细胞调节功能中获得的知识,使我们能够超越相关性,了解基因型与表型之间的联系机制。与多基因评分的权衡是,由于必须结合来自PGS中许多SNP的信息,我们往往会进一步远离支撑表型的特定生物学。
这对我们进行的许多定量分析都有影响。正如我们在第10章中所展示的,当你在计算高度多基因性状的PGS时包括所有SNP,你会获得更多的预测结果。然而,这样做,你就失去了生物学上的特异性。然而,我们应该清楚,这不仅仅是生物学特异性和SNP阈值之间的严格二分法。的确,如果我们在理解机制的情况下构建一个分数(即,仅使用具有已知因果路径的SNP),该分数将具有更少的SNP和较差的表现。然而,如果我们仅从全基因组重要SNP构建评分,我们对潜在机制的理解仍不会比使用所有SNP的评分更好。如果我们采用只包含许多独立SNP得分的PGS,那么缺乏生物学特异性可以说是所有多基因得分的一个特性。
因此,在最大限度地预测和理解生物学机制之间进行权衡。例如,在2018年《柳叶刀》对肥胖遗传学的回顾中,古达齐(Goodarzi)[13]总结了尽管已分离出300多个与体重指数、臀围比和其他肥胖特征相关的单核苷酸多态性,但对肥胖缺乏认真的生物学功能理解阻止了临床相关的减肥干预。因此,许多研究现在努力超越预测,提高精度。如疾病风险预测干预、基因-环境相互作用分析或孟德尔随机回归。我们在讨论分数的应用时,回到了机制预测权衡的具体问题。
表型共享的遗传结构
直到现在,我们已经讨论了相对隔离的特定性状的PGSs,然而,特别是对于复杂表型,单个性状的PGSs通常与多个表型相关。如图5.1所示,在使用PGSs时,重要的是要了解许多表型下通常存在一个共同的遗传结构。
虽然远未详尽无遗,但在本节中,我们将介绍一些用于解开这种共享遗传结构的主要技术。
预测其它表型
PGS通常具有共同的遗传结构,许多疾病和性状具有共同的病因。例如,精神分裂症和双相情感障碍是相互交织的疾病。
在研究它们或设计潜在的治疗方法时,了解它们的共同发生是至关重要的。例如,精神分裂症的PGSs被用来预测双相情感障碍[42]。这项研究表明,这两种表型之间在某种程度上存在共同的遗传病因学,表明相同的基因与这两种结果相关。相反,精神分裂症的得分不能预测非精神健康状况,如冠心病、克罗恩病、高血压或1型或2型糖尿病。
生殖特征也被证明是高度相关的。2016年发布的一份大规模GWAS研究了两个生殖行为特征,即初生年龄(AFB)和出生儿童数量(NEB)44]。PGSs被用来研究它们与各种生育和非生育性状的关联。其中包括初潮年龄、更年期年龄、失声年龄(男孩)和首次性交年龄。虽然PGS对出生儿童数量的预测能力相对较低,但当进入回归模型预测无子女情况时,结果却令人震惊。NEB的PGS可以预测生育期结束时保持无子女的概率,PGS的标准偏差增加一个,女性保持无子女的概率减少约9个【44】。
45].初生时(较晚)年龄的PGS同样与自然绝经时的早衰和晚年【44】。生物学功能研究还表明,生殖特征(和不孕特征,如子宫内膜异位症)之间存在共同的病因。
表型相关和遗传相关
任何表型也具有高度的遗传相关性。在这里,区分表型和基因型相关性很重要。尽管可能发生,但表型相关性并不自动意味着遗传相关性。即使表型部分可遗传。遗传相关性也并不意味着生物学上的因果关系。在本节中,我们重点讨论表型之间的遗传相关性或重叠。遗传相关是对一对性状间加性遗传效应比例的估计。例如,考虑两个遗传性状,如精神分裂症和双相情感障碍,它们通常具有很高的表型相关性。!对于遗传相关性,我们感兴趣的是检查是否也存在遗传相关性,或者换句话说,这两个性状是否共享相同的基因。
用于检查遗传重叠的最常用方法是LD评分回归,由Bulik Sullivan等人于2015年开发【46】。在第12章中,我们演示了如何使用LDSC软件包(https://github.com/bulik/LDSC)从GWAS汇总统计数据中估计遗传相关性(见附录1)。LDSC利用数据的LD结构来估计遗传相关程度。该方法最初要求GWAS对来自GWASs的所有SNP进行汇总统计,并提供一个参考样本,从中可以估计LD,以便估计LD得分回归。该方法基于以下关系正式编写:
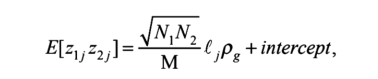
这里是性状k的GWA中SNPj的Z得分(k=1…,20),N是性状k的GWA样本量,l是SNPi的LD得分,M是GWA中包含的SNP数量,p性状1和2之间的遗传协方差,回归截距用截距表示。回归2,2的斜率√NN,l,可以用来估计这两个性状之间的遗传协方差。也可以估计这两个性状h2的遗传力h2,来自性状l和2的单变量LD得分回归。因此,遗传相关性的估计值为:
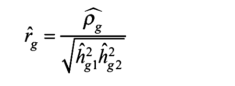
在第12章中,我们演示了如何估计这些LD分数以及对结果的解释。在这一章中,我们还展示了如何通过LDHub网站获得遗传相关性(http://ldsc.broadinstitute.org/ldhub/)[47]. 这是一个在线数据库,可以记录用作LD评分回归的web界面。该网站不断更新,但包括数百个性状的SNP遗传力和遗传相关结果。你还可以下载数百个性状之间的遗传重叠。
图5.2提供了跨多个性状的遗传相关性示例。在这里,我们展示了我们2016年的研究,其中我们使用LD评分回归来检验生殖行为表型(初生年龄[AFB]、出生儿童数量[NEB])与27个相关表型相关性之间的相关性。这包括发育或与生育有关的特征(如初潮年龄、更年期、失声、多囊卵巢综合征(PCOS)、首次性交年龄、出生体重)、行为(受教育年限、三种吸烟特征)、个性和神经精神(如神经质、精神分裂症、幸福感、孤独症),心脏代谢(如LDL胆固醇甘油三酯、2型糖尿病)和人体测量(BM、身高、腰臀比)。如图5.2所示,AFB主要与人类发育和行为特征呈正相关,而与PCOS、心脏代谢和人体测量特征呈负相关。一旦控制了多项测试,NEB仅与教育年限和首次性交年龄显著负相关。两个最显著的相关性是AFB、首次性交年龄和教育年限。事实上,受教育年限与AFB的相关性为0.70,我们在那里和相关论文中对此进行了探讨。虽然LD分数回归是一种识别性状之间可能关系的有力工具,但它不允许我们建立因果方向或关系,也不允许我们调整潜在的中介因素。
许多性状之间的关系非常复杂,具有潜在的双向机制。我们将在第13章“孟德尔随机化”和第15章(深入探讨未来的研究方向)中探讨其中的一些关系。
Pleiotropy
顺向性是指单个基因影响多个性状的现象。它源于希腊术语pleion,它指的是more和tropos,意思是“方式”。因此,多效性基因是指那些对表型表现出多重影响的基因。例如,如果一个多效性基因发生突变,它可能同时影响多个表型。这归因于基因编码被许多细胞或具有相同信号功能的不同靶点所使用。100多年前,德国遗传学家路德维希·普莱特(LudwigPlate)于1910年提出了多效性的主题【48】。它影响了进化生物学以及生理和医学遗传学的许多领域。自1910年以来。这个术语的含义已经演变,特别是随着我们在本书中研究的分子遗传数据的引入。衰老是指个体随着年龄的增长而发生的生理变化。
Paaby和Rockman概述了几种不同类型的多效性,指出讨论中经常遇到关于多效性的各种含义以及如何研究这些机制的概念困难[49]。在这本入门教材中,我们能够简单介绍不同类型的多效性,其中许多是在分子生物学水平上研究的。分子基因多效性研究一个分子基因所具有的功能数量,例如当一个基因与多种蛋白质相互作用并催化多种反应时。例如,这是对基因中蛋白质-蛋白质相互作用物及其催化反应数量的生化研究。发育多效性是指突变(而非分子基因)是研究的单位,在这里,研究人员经常检查表型不同方面的遗传和进化自主性,与适应度无关。这里的关键问题通常包括对分子多效性的检查以及顺式调节2与蛋白质编码变体的相对重要性,远远超出了本教科书的范围。选择多效性是研究表型何时对适合度有多重影响。这种多效性的一个关键特征是,性状被认为是由选择决定的,而不是个体的内在属性。这些例子可以追溯到一些基本的进化文本,这些文本提出了一个对抗性多效性模型,该模型考察了构成性对抗性多效性和多效性权衡基础的衰老或突变的进化,这是适应的基础【50】。一些人认为拮抗性多效性在遗传疾病中很常见【51】。镰状细胞病是一种常见的拮抗性多效性,当基因的多重效应对适应性产生相反影响时。
图5.3提供了一个非常简单的基因型-表型图,说明了加性多效性效应。在这张图中,基因G1、G2和G3代表了不同的基因,这些基因对三种不同的表型P1起作用。P2和P3。例如,Gl影响P1和P2,G2影响P2和P3,G3影响P2和P3。注意,多效性通常是指遗传相关性的同义词。然而,为了更精确,区分直接多效性和间接多效性是有用的。前面所有的例子都提到了直接多效性,即一个基因对多种表型有直接因果影响。这与前面讨论的共同原因模型是平行的。间接多效性是指对P1产生因果影响的基因,而P1反过来又对P2产生因果影响。这是指第2章中讨论的中介模型,其中P1是基因和P2之间的中介。在这两种情况下,我们将观察到两种表型之间的遗传相关性;然而,导致这一观察的机制确实不同,在后一种模型中,尽管我们观察到一种关联,但基因和P2之间可能没有生物学联系。
最近有两项研究使用PGSs研究冰岛和美国的教育程度与出生儿童数量之间的多效性【52,53】。这两项研究都发现,教育程度PGS显著预测了儿童数量,基于回归模型的遗传协方差可用于量化预期的进化变化。毫不奇怪,进化变化的直接证据虽然很重要,但却非常少。例如,在美国,由于自然选择的结果,每代人减少一周的教育。即使结果被重新缩放考虑到缺失的遗传力,遗传选择预测教育的变化不超过1.5个月左右。正如我们在其他地方提到的[12],考虑基因与环境的相互作用,如教育扩张的收益,并考虑到变化是缓慢的,需要稳定并持续几代人,这一点至关重要。上述研究也未考虑死亡率选择。
现在人们一致认为多效性是不明确的。Pickrell及其同事[55]研究了42种表型以证明多效性,并表明几个基因座与大量性状相关。然后,他们利用这些基因座来识别具有多重遗传原因的表型,并开发出一种方法来识别具有因果关系的成对性状。这里他们展示了BMI是如何导致甘油三酯水平升高的。其他研究人员检查了整个GWAS目录,以确定多效性的患病率,目录中报告的44个基因与一个以上的表型相关[56]。这些作者表明,多效性的程度与基因的平均效应大小呈正相关,与具有给定数量的相关表型的基因的效应大小方差呈负相关。正如第1章简要介绍的那样,多效性普遍存在的知识导致其他人,如Boyle等人【57】认为基因调控网络是如此相互关联,所有基因都以基因模型的形式影响核心疾病相关基因的功能。Gratten和Visscher【58】认为这种“普遍的多效性”具有真正的个性化医学和基因组编辑的含义,我们将在第14章和第15章中返回。
多性状分析
WAS通常优先考虑易于在不同队列中一致测量的表型。在许多情况下,可能很难协调或测量感兴趣的表型。因此,Rietveld及其同事引入了代理表型法[59]。代理表型法通过两个阶段的方法识别常见遗传变异,首先对表型进行GWA,然后使用独立样本测量原始GWA中发现的SNP与相关表型的关联。上述作者将教育程度与第二阶段的认知能力、记忆力和无痴呆症联系起来。
Turley及其同事于2018年【60】对GWAS(MTAG)进行了多重RAIT分析,这是一种允许对不同性状的GWAS汇总统计数据进行联合分析的方法。在这里,作者展示了如何将MTAG应用于GWAS的抑郁症状、神经质和主观幸福感结果,产生了更多在原始个人GWAS中未分离的相关位点,并将PGSs解释的方差增加到与理论预期相符的水平。与32.9相比。上述性状在单性状GWAS中鉴定出13个全基因组重要位点。MTAG使相关位点的数量分别增加到64、37和49个。这一增长与样本量较小的神经质GWAS尤其相关。在第12章中,我们提供了MTAG的一个示例应用程序。
多基因评分和因果模型
在本书第2章的早期,我们概述了在我们的介绍性统计章节中可能出现的各种类型的多元因果模型。在回归模型中,PGS可以被视为标准的连续变量,并且对于许多表型,目前已经在相对较小的样本(N<1000)中进行了很好的预测分析(见方框5.2)。在本节中,我们将概述本书后面将探讨的一些中心应用程序。这些包括检查基因混杂、基因-环境相互作用和孟德尔随机分组。
基因混杂
遗传混杂是指一个或多个外来变量至少部分解释了PGS与表型之间的关联(或缺乏关联)的情况。2000年。埃里克·特克海默是行为遗传学的创始人之一,他概述了行为的三条定律,遗传学[61]。虽然“一切都是可遗传的”一课很重要,但承认“一切都是环境的”同样重要如果我们研究各种疾病、行为和特征,它们在很大程度上往往与非遗传因素有关。研究人员一致表明,社会经济环境是健康、认知能力和其他多种表型中最可靠和重复的预测因子【62-64】。
孟德尔随机化
我们在第2章中详细阐述了,有多种策略来估计因果效应。
最理想的情况是进行随机对照试验。然而,就我们研究的许多结果而言,这根本不可行,也不道德。一种旨在近似这一点的替代设计是工具变量法,在这一研究领域被称为孟德尔随机法。因为我们有一整章专门讨论这个主题(第13章),所以我们在这里只简单地讨论一下。孟德尔随机化(MR)是一种利用遗传信息检验变量之间是否存在因果关系的技术。例如,高胆固醇会导致高血压吗?正如我们在第13章中所注意到的,MR已经证明使用PGSs非常有效。该技术依赖于一些需要牢记的重要假设。在MR中,通过诱导对感兴趣的性状具有强烈生物学效应的基因,将因PGSs中的直接多效性而产生的“噪音”风险降至最低是至关重要的。因此,如果MR中使用PGS,建议不要使用高p值阈值。
这可能违反方法所需的假设。有关此问题的详细讨论,请参阅Hemani等人[65]的讨论和第13章。
混杂因素控制
为了描述这一点,我们使用了文献中的两个例子:精神分裂症与父母第一次出生时的年龄之间的关系[66],与平均生育年龄相比,孩子很小(即少女怀孕)和很老都有不同的社会经济和心理健康结果。第一次出生时年龄的低尾和高尾的个体分布显示。例如,儿童被诊断为精神分裂症的可能性更高。这有着相当大的影响,因为在许多国家,第一胎年龄已经推迟了大约4-6年[67]。问题是,下一代是否会有更高的精神分裂症患病率,或者,考虑到U型关联,父母的生育年龄与精神分裂症之间的这种关系是否是因果关系。如果基因混淆了这种关系,这种关联可能是特定于某些人群的。因此,父母出生时年龄分布在不同时间或人群之间的变化可能不会影响该疾病的流行。当然,对于父母的童年年龄与子女的健康和幸福之间的联系,还有许多其他的解释。这包括资源和社会经济地位、关系稳定性和教育方面的差异,这些差异在年长父母中表现得更高,从而影响孩子以后的结果【68】。
一种假说认为,基因混淆了父母初生年龄与儿童精神分裂症发展之间的关系。多基因性是这一假说的关键。从遗传学角度来看,父母可能具有发展为精神分裂症的遗传倾向。例如,精神分裂症的倾向可能导致与少女怀孕相关的突然和危险的性行为,或导致找伴侣的问题,从而推迟或阻止分娩。由于父母将基因传给子女,父母年龄较大或较年轻的子女可能比其他人更容易患精神分裂症,因此也更容易被诊断。根据这一假设,我们预计第一胎年龄与精神分裂症之间的亲子关系不是因果关系,而是由基因造成的。但我们如何检验这个假设呢?PGS的应用使这一点相对简单,几项研究分析了精神分裂症患者PGS在初生婴儿各年龄段的分布情况【66,69】。
这些研究表明,父母患精神分裂症的风险分布与子女患精神分裂症的风险分布形状相同。青少年父母和35岁以上父母的精神分裂症PGS均升高。这表明,基因遗传至少在一定程度上混淆了父母生育时机与儿童心理健康之间的关系。因此,在研究这种关联时不考虑遗传的模型可能有偏差估计。更准确地说,他们可能高估了父母生育年龄对子女心理健康状况的因果影响。关于推迟生育对人口健康的影响的说法也可能具有误导性。
基因与环境互作以及异质性
基因与环境相互作用是这一研究领域的核心和新兴课题。
由于第6章介绍了详细的理论、基因-环境相互作用的讨论、许多实例和方法学问题,因此我们在此仅简要总结与PGSs相关的要点。在第二章中,我们还提供了几个应用示例,让您了解如何从技术上处理关键问题。
首先,在PGS应用的背景下,重申与基因环境研究相关的“交互”的含义是有用的。在这里,我们区分基因对表型的直接影响和与环境的交互作用。第一个例子表明,保持环境条件不变,基因在个体之间变化时会导致表型差异。第二种情况描述了基于不同基因型对环境暴露的不同反应。相互作用意味着在不同的环境中,基因对表型的影响会有所不同。
第6章对这些方面进行了说明。
例如,Domingue及其同事利用健康和退休研究阐明了美国对失去配偶的不同反应【70】。与生活中的其他压力事件一样,失去配偶可能会导致抑郁症。然而,抑郁症状的发生程度和持续时间在个体之间有所不同。正如我们在第6章所阐述的,他们测试了一种称为素质压力模型的理论,即主观幸福感的遗传倾向可能会缓冲失去配偶的不利影响,他们表明。虽然失去配偶后抑郁症状普遍增加,但与幸福感遗传分数较低的人相比,幸福感PGSs较高的美国成年人确实经历了较少的抑郁症状。在另一项研究中,Domingue及其同事【72】表明,PGS对吸烟的影响在出生队列中增加。
在基因-环境相互作用研究中使用PGSs的建议可能很复杂,也可能有细微差别。在第6章的表6.2中,我们列出了多重挑战,为什么它们存在问题,以及潜在的解决方案,我们在此不再重复。在这类研究中,我们感兴趣的是模拟在不同环境中具有差异效应的遗传效应。然而,指定不同环境的能力仍然具有挑战性。理论上,考虑到可能的环境相互作用,运行GWAS是理想的。实际上,这些研究的动力不足。即使在英国生物银行(UK Biobank)等拥有50万个体的大型样本中,也很难区分某些关键环境因素,因为样本是有选择性的,由更健康、社会经济地位更高的个体组成[73]。
在没有能力做到这一点的情况下,我们还可以分离出哪些SNP应该包括在分析中。第10章详细讨论了单核苷酸多态性的选择,其中123多基因评分和遗传结构我们演示了如何创建和验证PGS。Rosenquist及其同事【74】利用FTO基因中的一个单一变体表明出生队列与肥胖的遗传易感性相互作用。因为FTO有一种异常高效的变体,所以可以在该论文中使用一种变体。在许多工业化国家,食物供应不受限制,加上久坐不动的生活方式越来越多,这意味着在最近出生的人群中,肥胖等位基因的潜在“风险”更大。相反,Barcellos等人[75]的一项研究表明,提高教育水平有助于减少健康不平等。使用包含2018年GWAS教育成就所有等位基因的PGS。他们测试了PGS是否会缓和教育对健康的影响。他们利用1972年英格兰和威尔士义务教育一年增长的自然实验,发现教育缩小了肥胖基因风险最高和最低三分之一人群在不健康体型方面的健康差距。
结论
大多数应用研究人员将执行的大部分工作可能是将PGSs应用于多种表型和各种环境。在这一广阔而充满活力的研究领域中,很难知道从何处着手。本章的目标不仅是定义PGS并提供它们如何出现的背景,而且让研究人员了解他们需要采取的一些更实际的步骤。因此,在图5.1和附带的讨论中,我们提供了一个流程图,从数据到验证和处理,生成PGS并将其用于预测,以及思考共享遗传架构和建模应用的方法。我们的目标是,除了提供潜在的解决方案和进一步的阅读之外,还将fag特殊的挑战和问题领域,我们在表5.1中进行了总结。
PGSs是一种有用的工具,可将遗传信息汇总到一个变量中,以应用于进一步的统计分析。我们试图对它们的使用以及潜在的限制提出一个平衡的观点。也许最成问题的是,由于基于GWASs和迄今为止研究的人口历史上缺乏多样性,它们在历史上不太适用于各种人口和群体。希望在未来几年内,这种情况会有所改变。我们还注意到,鉴于缺失、仍然缺失和隐藏的遗传力问题,PGS仍然是性状真实遗传力的代表。随着GWASs样本量的增加,以及超越常见变体的趋势,该领域将继续扩大。除了缺乏多样性之外,当前GWAS设计中的另一个重要缺陷是,在GWAS中发现的单核苷酸多态性信号可能被夸大了,因为正如Kong及其同事[76]最近所显示的那样,他们还标记了父母养育的影响。
尽管一些研究人员仍将重点放在R2上,但对于某些研究问题来说,最大化预测并不总是最终和有用的目标。了解主要遗传标记的基本生物学和功能可能使我们比统计解决方案和预测。由于多效性普遍存在,PGS通常也有一个共同的遗传结构。在这方面,探索相关表型、预测相关表型或进行多序列分析可能是富有成效的途径。我们还预计,在未来一段时间内将取得相当大的进展,包括更好地测量表型,或从多种手段(如病历)中获得所谓的“深层表型”,以及优化预测的机器学习算法。尽管PGS取得了巨大进展,但目前尚不清楚是否有可能创建一种全基因组PGS,以充分识别临床风险显著增加的个体。PGS越来越多地与筛查、干预和生命规划的临床措施结合使用,但仍存在相当大的争议。在最后的伦理学讨论(第14章)和未来方向(第15章)中,我们将讨论PGSs在临床应用中的使用。
练习:
