看《算法》真的是需要数学基础的,像我这样小学时候数学经常100分的人,但是在大学四年没怎么碰过数学之后,连等比数列求和公式都会忘了的人,再看《算法》,真是有一种要死要活的感觉。
不过好在相较于广袤到你找不到方向的大学物理,细小到你摸不着头脑的电路,算法还算比较人性化的知识了,作为一名准程序猿,学习算法还是不可或缺的要求吧。
好记性不如烂笔头,不过在计算机这方面,我觉得烂笔头不如破键盘,写在本子上的代码总是极丑的,记录在博客上,还是一种蛮不错的办法。
《算法》第四版这本书确实看起来非常非常厉害,起码大牛嘴边经常挂着的“艺术般的代码”在《算法》里面简直是琳琅满目,目不暇接,接踵而至,至。。。至于我这样的俗人总是难以消化艺术般的东西,所以只好把这些艺术品陈列至此,然后时不时地消化一下,简直美滋滋!

1.1 基础编程模型
首先,来一个让我大吃一惊的代码吧,代码写的好,真是一种艺术,下面就是艺术展示时间。
欧几里得算法
欧几里得算法(我老喜欢念成欧里几得):一开始看到这个名字我是真的忘记这是个啥子了,查了百度才知道,原来就是计算最大公约数,嗨…
//欧几里得算法
public static int gcd(int p, int q) {
if (q == 0) return p;
int r = p % q;
return gcd(q, r);
}这代码写的就不谈了,能写出这样的代码,实乃家居必备,装逼利器之良技。
不过关于为什么要学习算法这个东西,我是深有感触的,就是两个字——【优化】。经常玩游戏的童鞋应该会对此表示赞同(我举五体赞同)。优化差的代表——《仙剑6》,优化牛逼的代表——《黑魂2》(这个不解释,我的辣鸡联想笔记本都能玩)。总之,同等硬件水平下,同一个目的的代码,使用良好的算法后,效果会提升一大截!
不过瞎扯这些东西也是闲着蛋疼,还是老老实实地记录一下那些实用的代码吧。
二分查找算法
二分查找应该是一个非常著名的算法了吧,有一个题目就是:
假如有16个铁球,体积全部相同,但有一个和其他所有铁球的质量不等,那么使用天枰可以花多少次去找出这个铁球。
上面这个就相当于二分查找的一个例子,下面是关于二分查找的算法实现。
public class BinarySearch{
public static int rank(int key, int[] a) {
int lo = 0;
int hi = a.length - 1;
while(lo <= hi) {
int mid = lo + (hi - lo) / 2;
if (key < a[mid]) hi = mid - 1;
else if (key > a[mid]) lo = mid + 1;
else return mid;
}
return -1;
}
}当输入的值key超出了数组a的范围时,返回值为-1
注意:使用二分查找的时候一定要将数组a中的元素排序,比如使用Arrays.sort()方法。
矩阵相乘(方阵)
int N = a.length;
double[][] c = new double[N][N];
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
//计算行i和列j的点乘
for (int k = 0; k < N; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}判断一个数是否为素数
素数就是除了1和本身不再有其他的因数
public static boolean isPrime(int N) {
if(N < 2) return false;
for (int i = 2; i * i <= N; i++)
if (N % i == 0) return false;
return true;
}上面的判断是i*i<=N而不是i<=N,这个很有意思,值得思考,想明白是需要花点儿时间的,这也算是优化算法后的代码,减少了时间复杂度。
二分查找的递归实现
public static int rank(int key, int[] a) {
return rank(key, a, 0, a.length -1);
}
public static int rank(int key, int[] a, int lo, int hi) {
if (lo > hi) return -1;
int mid = lo + (hi - lo) / 2;
if (key < a[mid]) return rank(key, a, lo, mid - 1);
else if(key > a[mid]) return rank(key , a, mid + 1, hi);
else return mid;
}递归实现二分查找就不谈了,看起来比之前的二分查找结构要清晰一些。
根据离散概率随机返回的int值(出现i的概率为a[i])、随机将double数组中的元素排序
这两个算法实现的方法使用的是《算法》作者提供的标准库中StdRandom方法。其实和Math.Random是差不多的,下面直接看一下表格吧。

模拟T次掷骰子

1.3背包、队列、栈(Bag、Queue、Stack)
这一节的知识我觉得还是很有必要记录一下的,因为非常重要吧!
首先看一下定容栈的实现:
定容栈
public class FixedCapacityStackOfStrings{
private String[] a;
private int N;
public FixedCapacityStackOfStrings(int cap)
{ a = new String[cap]; }
public boolean isEmpty() { return N == 0; }
public int size() { return N; }
public void push(String item) { a[N++] = item; }
public String pop() { return a[--N]; }
}这样,就可以创建一个容量为cap的空栈。不过这种栈有许多缺点,第一个就是它只能处理String对象,如果需要一个double值的栈,就得用类似的代码实现另外一个类。
于是,泛型就是专门来解决这个问题的。
不过由于某些历史和技术原因,创建泛型数组在java中是不允许的,我们需要使用类型转换——:
a = (Item[]) new Object[cap];接下来就看一下泛型定容栈的实现:
public class FixedCapacityStackOfStrings<Item>{
private Item[] a;
private int N;
public FixedCapacityStackOfStrings(int cap)
{ a = (Item[]) new Object[cap]; }
public boolean isEmpty() { return N == 0; }
public int size() { return N; }
public void push(Item item) { a[N++] = item; }
public Item pop() { return a[--N]; }
}和最初的定容栈相比,差不多就是把String换成了Item,不过这样就可以使用泛型了。
然后是关于调整数组大小的:

迭代
在Java中,使用接口机制来指定一个类所必须实现的方法。对于迭代的集合数据类型,Java已经为我们定义了所需接口,要使一个类可迭代,第一部就是在声明中加入implements Iterable,对应的接口为:
public interface Iterable<Item>{
Iterator<Item> iterator();
}迭代器都是泛型的,因此我们可以使用参数类型Item来帮助用例遍历它们指定的任意类型的对象。对于一直使用的数组表示法,我们需要逆序迭代遍历这个数组,因此我们将迭代器命名为ReverseArrayIterator,并添加一下方法:
public interface Iterator<Item>{
return new ReverseArrayIterator();
}迭代器是一个实现了hasNext()和next()方法的类的对象,由以下接口所定义:
public interface Iterator<Item>{
boolean hasNext();
Item next();
void remove();
}虽然上面接口中指定了一个remove()方法,但是《算法》里面的remove()总为空,因为希望避免在迭代中穿插能够修改数据结构的操作,对于ReverseArrayIterator,这些方法都只需要一行代码,他们的实现在栈类的一个嵌套类中:
private class ReverseArrayIterator implements Iterator<Item>{
private int i = N;
public boolean hasNext() { return i > 0; }
public Item next() { return a[--i]; }
public void remove() { }
}不过使用迭代的时候别忘记导入了:
import java.util.Iterator;迭代就这么多了,接下来是一个比较重要的
下压(LIFO)栈(能够动态调整数组大小的实现)
下压栈就是后进先出(last in first out)的,比如那种放饼干的罐子,就是下压栈,放羽毛球的那个筒子也是。
import java.util.Iterator;
public class ResizingArrayStack<Item> implements Iterable<Item>{
private Item[] a = (Item[]) new Object[1]; //栈元素
private int N = 0;
public boolean isEmpty() { return N == 0; }
public int size() { return N; }
private void resize(int max) {
//将栈移动到一个大小为max的新数组
Item[] temp = (Item[]) new Object[max];
for (int i = 0; i < N; i++)
temp[i] = a[i];
a = temp;
}
public void push(Item item) {
if (N == a.length) resize(2 * a.length);
a[N++] = item;
}
public Item pop() {
Item item = a[--N];
a[N] = null; //避免对象游离
if (N > 0 && N == a.length / 4) resize(a.length / 2);
return item;
}
public Iterator<Item> iterator()
{ return new ReverseArrayIterator(); }
private class ReverseArrayIterator implements Iterator<Item>{
//支持后进先出的迭代
private int i = N;
public boolean hasNext() { return i > 0; }
public Item next() { return a[--i]; }
public void remove() { }
}
}以上这份泛型的可迭代的Stack Api的实现是所有集合类抽象数据类型实现的模版。
链表
链表是一种递归的数据结构,它或者为空(null),或者是指向一个节点(node)的引用,该节点含有一个泛型的元素和一个指向另一条链表的引用。
最开始学C的时候被指针折腾的死去活来,学到链表的时候又被链表折腾的死去活来,想想都蛋疼。
在面向对象的编程中,实现链表并不困难,首先用一个嵌套类来定义节点的抽象数据类:
private class Node{
Item item;
Node next;
}下面是书中关于链表的实现的一些图片,还是蛮直观的:
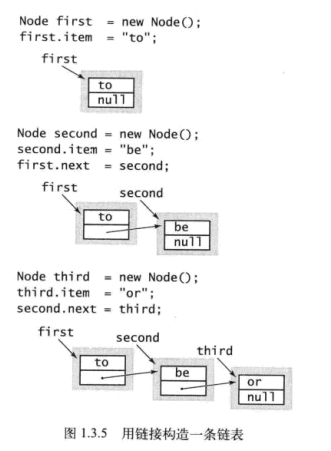
然后是链表如何在表头插入节点,以及从表头删除节点:
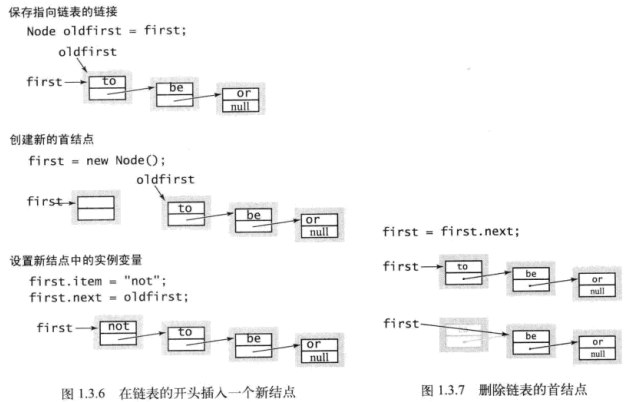
接着是如何在表尾插入节点和其他位置的插入删除工作
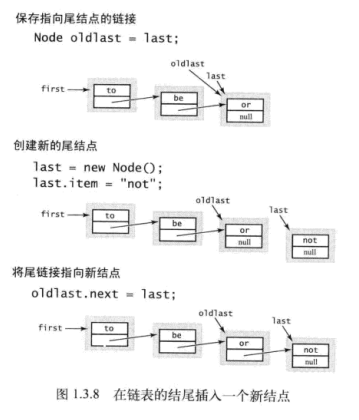
关于如何遍历链表,可以使用如下方法:
for (Node x = first; x != null; x = x.next){
//处理x.item
}接下来就看一下下压堆栈用链表是如何实现的:
下压堆栈(链表实现)
public class Stack<Item> implements Iterable<Item>{
private Node first; //栈顶(最近添加的元素)
private int N; //元素数量
private class Node{
Item item;
Node next;
}
public boolean isEmpty() { return N == 0; } //或者first == null
public int size() { return N; }
public void push(Item item) {
Node oldFirst = first;
first = new Node();
first.item = item;
first.next = oldFirst;
N++;
}
public Item pop() {
Item item = first.item;
first = first.next;
N--;
return item;
}
//iterator()的实现等1.4的时候就有了
}然后是基于链表实现队列:
先进先出队列
public class Queue<Item> implements Iterable<Item>{
private Node first; //指向最早添加的节点的链接
private Node last; //指向最近添加的节点的链接
private int N; //队列中的元素数量
private class Node{
Item item;
Node next;
}
public boolean isEmpty() { return N == 0; } //或者first == null
public int size() { return N; }
public void enqueue(Item item) {
//向表尾添加元素
Node oldLast = last;
last = new Node();
last.item = item;
last.next = null;
if (isEmpty()) first = last;
else oldLast.next = last;
N++;
}
public Item dequeue() {
//从表头删除元素
Item item = first.item;
first = first.next;
if (isEmpty()) last = null;
N--;
return item;
}
//iterator()的实现见算法1.4
}1.4 算法分析
算法分析一般是对程序运行时间的判断,基本上需要使用各类数学模型,所以说数学在计算机领域的重要性那都不谈了。
下面看一个计时器的实现吧:
一种表示计时器的抽象数据类型
public class Stopwatch{
private final long start;
public Stopwatch()
{ start = System.currentTimeMillis(); }
public double elapsedTime() {
long now = System.currentTimeMillis();
return (now - start) / 1000.0;
}
}上面计时器的实现主要使用了System.currentTimeMillis()方法获取当前系统时间,下面看一下用例:
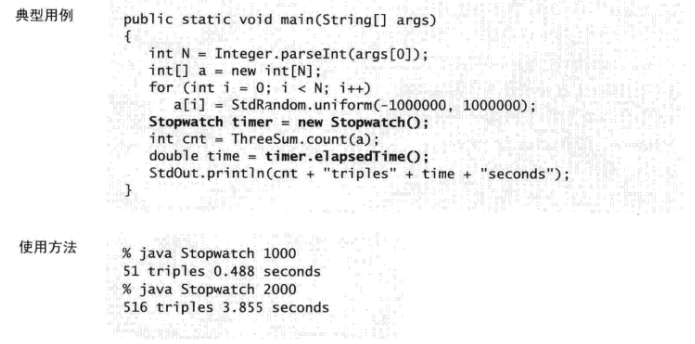
一个程序运行的总时间主要和两点有关:
1.执行每条语句的耗时;
2.执行每条语句的频率。
前者取决于计算机、Java编译器和操作系统,而后者取决于程序本身和输入。
一般情况下,程序运行时间的增长数量级函数有如下几种:

《算法》里面的lgN表示的是以2为底的对数,不过我们学的数学里面都是以10为底才这样表示的,所以这里是容易混淆的地方,我也不知道是不是因为计算机里面二进制用的比较多所以这么规定的,在此记录一下。
书上面关于增长数量级有一个例子:
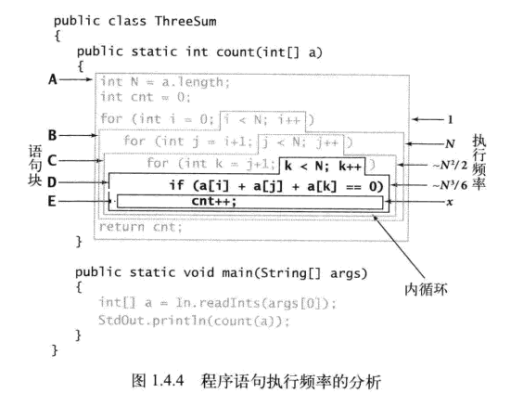
然后是对增长数量级的常见假设的总结
增长数量级的分类

关于这些增长模型,图解如下:
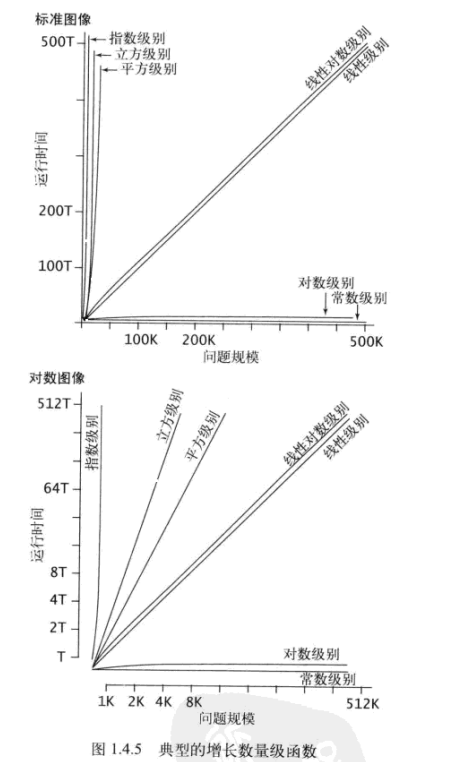
接下来,看一下书中的例子:
热身运动 2-sum
首先说明一下,之前有用过二分查找法,这个算法是输入一个值以及一个数组,然后如果数组中有和这个值一样的元素,就返回这个元素的下标,然后看一下书中的例子吧。
public class TwoSumFast{
public static int count(int[] a) {
//计算和为0的整数对数目
Arrays.sort(a);
int N = a.length;
int cnt = 0;
for (int i = 0; i < N; i++) {
if (BinarySearch.rank(-a[i], a) > i)
cnt++;
}
return cnt;
}
public static void main(String[] args) {
int [] a = In.readInts(args[0]);
StdOut.println(count(a));
}
}可以看到,上面的方法是查找数组中和为0的整数对,把二分法查找的结果当作j,如果j>i,就将计数器加1;

归并排序(就是Arrays.sort(a))所需要的时间和NlogN成正比,二分查找所需要的时间和logN成正比,因此整个算法的运行时间和NlogN成正比。
3-sum 问题的快速算法
上面这种方式对于3-sum同样有效,这次我们假设所有整数均不相同。
当且仅当-(a[i] + a[j])在数组中时,整数对a[i] 和 a[j]是某个和为0的三元组的一部分。下面的代码框中的代码会将数组排序并进行N(N-1)/2次二分查找,每次查找的时间和logN成正比,所以总运行时间和
在这种情况下排序的成本是次要因素。

1.5 案例研究:union-find算法
union是联合的意思,网上把union-find翻译为并查集算法,但是我觉得这个翻译比较晦涩难懂,还不如就看英文的名字。
在1.5节里面使用的union-find例子是查找两个点是否连通的算法,具体说明如下:

如果在网络中,整数对可能表示的是朋友关系,在这类应用中,我们就可能需要处理数百万的对象和数十亿的连接,可以看一下下面这个较大的例子:
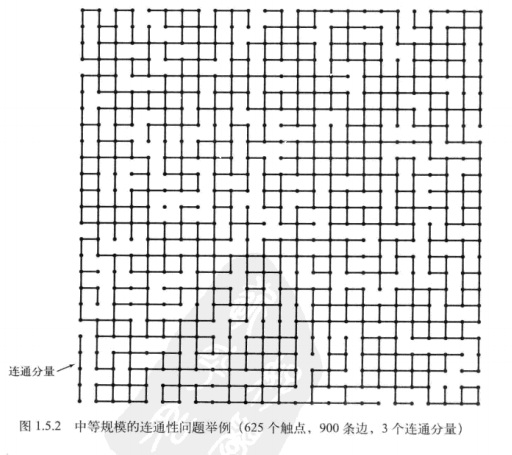
为了说明问题,书中设计了一份API来封装所需的基本操作

其实我觉得把这个find(int p)换成getID(int p)更好理解一些。
public class UF{
private int[] id; //分量id(以触点作为索引)
private int count; //分量的数量
public UF(int N) { //初始化分量id数组
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
public int count() { return count; }
public boolean connected(int p, int q) { return getID(p) == getID(q); }
public int getID(int p) { return id[p]; }
public void union(int p, int q) {/*待会儿会有union详情方法*/}
public static void main(String[] args) {
int N = StdIn.readInt(); //读取触点数量
UF uf = new UF(N); //初始化N个分量
while(!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if (uf.connected(p, q)) continue; //如果已经连通则忽略
uf.union(p, q); //归并分量,就是把这两个连起来
StdOut.println(p + " " + q);
}
StdOut.println(uf.count() + "components");
}
}union-find的成本模型是数组的访问次数。接下来看一下union的实现:
public void union(int p, int q){
int pID = getID(p);
int qID = getID(q);
if(pID == qID) return; //如果p、q已经在相同分量中则略过
for (int i = 0; i < id.length; i++) { //将p的分量重命名为q的名称
if(id[i] == pID)
id[i] = qID;
}
count--;
}可以看一下处理测试数据的完整轨迹:

getID()操作速度很快,因为它只需要访问id[]数组一次,但是对于每一对输入union()都需要扫描整个id[]数组,那么假设我们使用该算法来解决动态连通性问题,并且最后只得到了一个连通分量,那么这至少需要调用N-1次union(),即至少(N+3)(N-1)——N
很明显,我们需要更好的算法。(可以把上面的算法叫做quick-find)
quick-union算法
看一下书中的详细说明吧:

接下来是quick-union的概述:
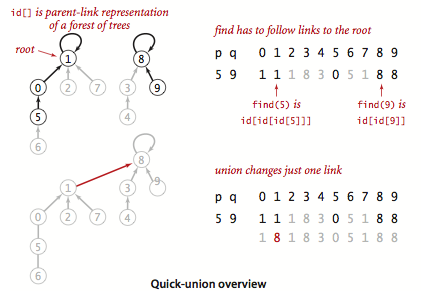
可以对比一下中文版
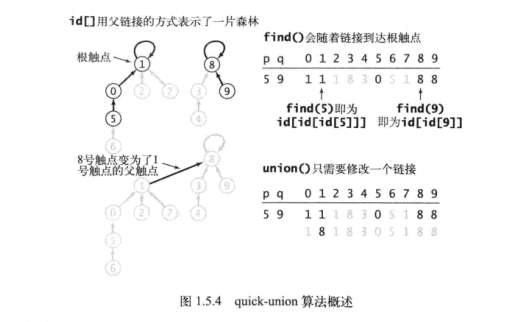
之后是quick-union的轨迹:

关于quick-union算法,书上写了这样一个命题(之前的代码中我把find()改成了getID()):

由命题G我们可以知道算法的运行时间在最坏的情况下是平方级别的,下面展示最坏情况:
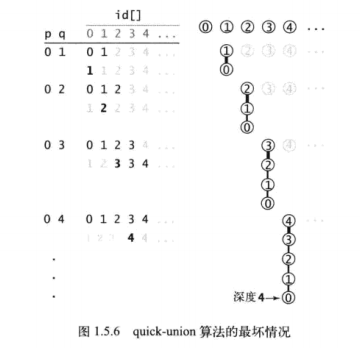
对于整数对0-i,union()操作访问数组的次数为2i+1(触点0深度喂i-1,触点i的深度为0)。因此,处理N对证书所需的所有getID()操作访问数组的总次数为3+5+7+…+(2N-1)——N
所以还需要改进,下面就是加权算法
加权quick-union算法
与其在union()中随意将一棵树连接到另外一棵树,我们现在会记录每一棵树的大小并且总是将较小的树连接到较大的树上。这项改动需要添加一个数组和一些代码来记录树中的节点数
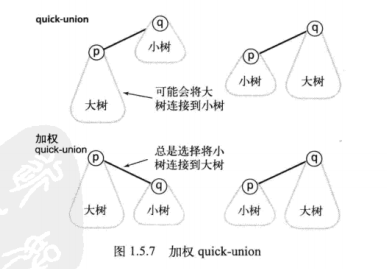
来看一下加权算法是如何实现的(这次就不把find改为getID了):
public class WeightedQuickUnionUF {
private int[] id; // parent[i] = parent of i
private int[] sz; // size[i] = number of sites in subtree rooted at i
private int count; // number of components
public WeightedQuickUnionUF(int n) {
count = n;
id = new int[n];
for (int i = 0; i < n; i++) id[i] = i;
sz = new int[n];
for (int i = 0; i < n; i++) sz[i] = 1;
}
public int count() { return count; }
public int find(int p) { //跟随链接找到根节点
while (p != id[p]) p = id[p];
return p;
}
public boolean connected(int p, int q) { return find(p) == find(q); }
public void union(int p, int q) {
int i = find(p);
int j = find(q);
if (i == j) return;
//将小树的根节点连接到大树的根节点
if (sz[i] < sz[j]) { id[i] = j; sz[j] += sz[i]; }
else { id[j] = i; sz[i] += sz[j]; }
count--;
}
}然后看一下加权算法的轨迹:

书中还有一个推论:对于quick-union算法和N个触点,在最坏情况下find()、connected()、和union()的成本的增长数量级别为logN。
最后是各种union-算法的性能特点:

总 结
第一章虽然名字叫做【基础】,但是看得我头皮发麻,更不谈后面的习题了,习题就暂且放着吧,如果做习题的话感觉估计会是这样的——学一天的知识,做一星期的习题。。。