嵌入Circle映射和逐维小孔成像反向学习的鲸鱼优化算法
文章目录
摘要:针对鲸鱼优化算法(WOA)容易陷入局部最优解、收敛速度慢等缺陷,提出一种改进鲸鱼优化算法.首先,利用Circle混沌序列取代原始算法中随机产生的初始种群,提高初始个体的多样性;其次,提出了一种逐维小孔成像反向学习策略,增加寻优位置的多样性,提高了算法摆脱局部最优的能力;最后,提出了融合贝塔分布和逆不完全Γ函数的自适应权重,在保留鲸鱼优化算法优点的前提下,协调了算法的搜索能力.
1.鲸鱼优化算法
基础鲸鱼算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/107559167
2. 改进鲸鱼优化算法
2.1 混沌序列初始化
群体初始化对当前大多数智能优化算法的效率有很大影响,均匀分布的种群可以适度地扩大算法的搜索范围,从而提高算法的收敛速度和求解精度,在WOA种群初始化时,由于没有任何先验条件可以使用,大部分算法都是在搜索空间内随机生成初始种群,这种随机生成的群体位置容易导致鲸鱼位置分布不均匀,搜索范围不广,匡芳君[14] 等人提出利用Tent混沌来初始化种群,使个体尽可能均匀分布在搜索空间中,从而提高了蜂群算法的性能.混沌具有不可预测、非周期等特点,可以利用这种特点来提高算法的性能,其主要思想是利用混沌的特性,将变量映射到混沌变量空间的取值区间内,最后将解线性地转化到优化变量空间.目前优化领域中存在多种不同的混沌映射[15],主要有Tent映射、Circle映射和Gauss映射等.本文采用Circle混沌映射来生成初始群体,Circle映射定义如下:
x i + 1 = m o d ( x i + 0.2 − ( 0.5 2 π ) sin ( 2 π x i ) , 1 ) (8) x_{i+1}=\bmod \left(x_{i}+0.2-\left(\frac{0.5}{2 \pi}\right) \sin \left(2 \pi x_{i}\right), 1\right) \tag{8} xi+1=mod(xi+0.2−(2π0.5)sin(2πxi),1)(8)
利用Circle映射来产生初始种群, 相比于随机 分布的种群, 改进后的种群初始位置分布更加均 匀, 扩大了鲸鱼群在空间中的搜索范围, 增加了群 体位置的多样性, 一定程度上改善了算法容易陷入 局部极值的缺陷, 从而提高了算法的寻优效率.
2.2 逐维小孔成像反向学习
假设某一空间中, 有一个高度为 h h h 的火 焰 p p p 在 X X X 轴上的投影为 X b e s t j X_{b e s t}^{j} Xbestj (第 j j j 维最优解), 坐标轴 的上下限为 a j , b j a_{j}, b_{j} aj,bj (第 j j j 维解的上下限), 在基点 o o o 上放置 一个有小孔的小孔屏, 火焰通过小孔可以在接收屏 上得到一个高度为 h ′ h^{\prime} h′ 的倒像 p ′ p^{\prime} p′, 此时在 X X X 轴上得到 通过小孔成像产生的一个反向点 X best ′ j X_{\text {best }}^{\prime j} Xbest ′j (第 j j j 维解得反 向解). 所以由小孔成像原理可以得出:
( a j + b j ) / 2 − X best j X best ′ j − ( a j + b j ) / 2 = h h ′ (9) \frac{\left(a_{j}+b_{j}\right) / 2-X_{\text {best }}^{j}}{X_{\text {best }}^{\prime j}-\left(a_{j}+b_{j}\right) / 2}=\frac{h}{h^{\prime}} \tag{9} Xbest ′j−(aj+bj)/2(aj+bj)/2−Xbest j=h′h(9)
令 h / h ′ = n h / h^{\prime}=n h/h′=n, 通过变换得到 X b e s t ′ j X_{b e s t}^{\prime j} Xbest′j, 表达式如下:
X best ′ j = ( a j + b j ) 2 + ( a j + b j ) 2 n − X best j n (10) X_{\text {best }}^{\prime^{j}}=\frac{\left(a_{j}+b_{j}\right)}{2}+\frac{\left(a_{j}+b_{j}\right)}{2 n}-\frac{X_{\text {best }}^{j}}{n}\tag{10} Xbest ′j=2(aj+bj)+2n(aj+bj)−nXbest j(10)
当 n = 1 n=1 n=1 时, 可得:
X b e s t ′ j = ( a j + b j ) − X b e s t j (11) X_{b e s t}^{\prime} j=\left(a_{j}+b_{j}\right)-X_{b e s t}^{j}\tag{11} Xbest′j=(aj+bj)−Xbestj(11)
由11式可以看出, 当 n = 1 n=1 n=1 时, 此时每维的逐 维小孔成像反向学习就是一般反向学习策略, 通过 改变接收屏与小孔屏的距离来调整调节因子 n n n, 从 而可以得到位置更好的个体.通过对算法保留下来的 最优解进行逐维小孔成像反向学习, 将各维度的值 映射到空间中得到反向解, 避免了各维度之间的干 扰, 同时也扩大了算法的搜索范围, 从而改善算法 的性能. 改进后的算法每迭代一次, 都通过(10)式进 行位置䇠选, 某一维度的值经过反向学习之后与其 他维度的值组成新的解, 通过比较各个适应度值来 进行篮选, 进而确定最优解, 利用这种方式不断求 得更好的解, 用这种精英保留的方式来进行下一维 的反向学习更新, 直到各维度更新结束.与一般反向 学习相比, 本文选择的是当前种群中保留的最优个 体进行逐维反向学习, 一定程度上降低了算法陷入 局部最优的可能性, 同时本文所提策略中 a j a_{j} aj 和 b j b_{j} bj 是 动态变化的, 相比于固定边界的反向学习策略具有 更加准确的搜索范围, 从而提高了算法的优化效率.
2.3 融合贝塔分布和逆不完全Γ函数的权重
在WOA中, 惯性权重对算法性能具有很明显的 影响, 当惯性权重大于 1 时, 随着迭代的进行算法会 很快发散; 若惯性权重小于 0 , 则将导致算法很快 停滞.通常情况下, 在算法初期主要注重全局探索, 以确保算法快速到达最优解附近, 此时权重应该较 大; 而在算法后期, 主要侧重局部开发, 此时需要 适当减小相邻两代之间的关联, 在最优解附近进行 精确搜索, 因此权重应该较小.WOA在进行全局搜 索和局部开发时, 权重是固定不变的, 导致鲸鱼群 只能停留在最优解附近, 不能精确的找到最优解, 同时在WOA中没有考虑算法迭代过程中 X r a n d X_{r a n d} Xrand 随机 性的影响, 因此本文提出一种融合贝塔分布 [ 18 ] [18] [18] 和 逆不完全 Γ \Gamma Γ 函数 [ 19 ] { }^{[19]} [19] 的惯性因子调整方法:
ω = ω min + ω max − ω min λ × gammaincinc ( λ , 1 − t T ) + σ B ( b 1 , b 2 ) 其中, ω max = 0.9 , ω min = 0.4 , gammaincinv ( λ , a ) \begin{aligned} \omega &=\omega_{\min }+\frac{\omega_{\max }-\omega_{\min }}{\lambda} \times \text { gammaincinc }\left(\lambda, 1-\frac{t}{T}\right)+\sigma B\left(b_{1}, b_{2}\right) \\ & \text { 其中, } \omega_{\max }=0.9, \omega_{\min }=0.4, \text { gammaincinv }(\lambda, a) \end{aligned} ω=ωmin+λωmax−ωmin× gammaincinc (λ,1−Tt)+σB(b1,b2) 其中, ωmax=0.9,ωmin=0.4, gammaincinv (λ,a)
为逆不完全 Γ \Gamma Γ 函数 γ ( λ , a ) = ∫ 0 λ e − t t a − 1 d t \gamma(\lambda, a)=\int_{0}^{\lambda} \mathrm{e}^{-t} t^{a-1} \mathrm{~d} t γ(λ,a)=∫0λe−tta−1 dt 的Matlab调 用函数, λ ( λ ≥ 0 ) \lambda(\lambda \geq 0) λ(λ≥0) 为随机变量, 本文取 λ = 0.1 \lambda=0.1 λ=0.1; B ( b 1 , b 2 ) B\left(b_{1}, b_{2}\right) B(b1,b2) 表示服从贝塔分布的随机数, 其中 b 1 = 1 b_{1}=1 b1=1, b 2 = 2 , σ b_{2}=2, \sigma b2=2,σ 为惯性权重调整因子, 本文取 σ = 0.1 \sigma=0.1 σ=0.1 用 来控制惯性权重 ω \omega ω 的偏移程度, 使其能够更好地平 衡算法的全局搜索和局部开发能力. 其中 t t t 为当前迭 代次数, T T T 为算法最大迭代次数, 此时 a = 1 − t / T a=1-t / T a=1−t/T.
本文权值的前两项用来控制 ω \omega ω 从 0.9 0.9 0.9 非线性递减 到 0.4 0.4 0.4, 进而协调全局搜索和局部开发阶段, 第三项 利用贝塔分布调整 ω \omega ω 整体取值的分布, 使权值的选 取更加合理. 由(12)式可知, 本文改进权重在总体上 随着迭代次数的增加而非线性递减, 满足整个搜索 过程权重的变化, 同时, 在式中加入了服从贝塔分 布的随机数, 一方面在迭代前期权值变化太快时也 可能产生较大的权值, 此时一定程度上增强了算法 的全局搜索能力; 另一方面到迭代后期, 权重系数 随着迭代次数增加而减小, 而且变化比较平稳, 此 时加入服从贝塔分布的随机数使算法有机会获得较 大的权值, 实现了权重的动态变化, 从而提高算法 的收玫速度.结合WOA位置更新公式, MWOA公式 定义如下:
X ( t + 1 ) = ω ⋅ X ∗ ( t ) − A ⋅ D ∣ A ∣ < 1 , p < 0. (13) X(t+1)=\omega \cdot X^{*}(t)-A \cdot D|A|<1, p<0 .\tag{13} X(t+1)=ω⋅X∗(t)−A⋅D∣A∣<1,p<0.(13)
X ( t + 1 ) = ω ⋅ X rand − A ⋅ D rand ∣ A ∣ ≥ 1 , p < 0.5 (14) \begin{aligned} &X(t+1)=\omega \cdot X_{\text {rand }}-A \cdot D_{\text {rand }}|A| \geq 1, p<0.5 \end{aligned}\tag{14} X(t+1)=ω⋅Xrand −A⋅Drand ∣A∣≥1,p<0.5(14)
X ( t + 1 ) = D ′ ⋅ e b l ⋅ cos ( 2 π l ) + ω X ∗ ( t ) p ≥ 0.5 (15) X(t+1)=D^{\prime} \cdot e^{b l} \cdot \cos (2 \pi l)+\omega X^{*}(t) p \geq 0.5 \tag{15} X(t+1)=D′⋅ebl⋅cos(2πl)+ωX∗(t)p≥0.5(15)
鲸鱼算法的模型简单, 相比于传统算法, 鲸鱼 优化算法寻优能力更强, 但是在整个进化过程中主 要通过搜索包围、螺旋更新位置、随机选择鲸鱼位 置来实现寻优, 但是算法在迭代时不断更新领导者 的位置, 这样的领导者更新方式导致算法进行到某 一代陷入局部最优则会使算法陷入停滞, 虽然一些 改进算法利用混沌理论和反向学习增加了算法跳出 局部最优的概率、加入惯性权重来平衡算法的全局 搜索和局部开发能力, 但本质上来说都是对单一的 进化策略进行改进, 因此本文通过结合混沌映射理 论、逐维小孔成像反向学习策略、融合贝塔分布和 逆不完全 Γ \Gamma Γ 函数的权重, 来优化算法的寻优效率, 提高算法的稳定性, 以期望在每次迭代过程中获得 更好的优化结果.
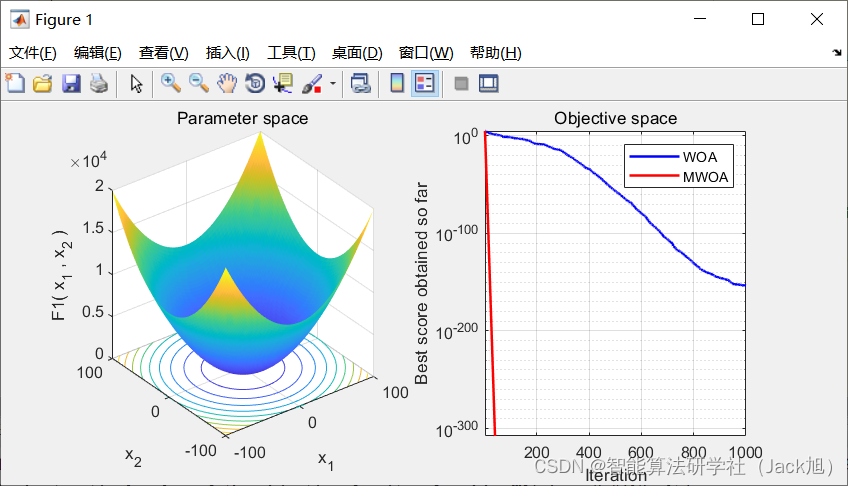
3.实验结果
4.参考文献
[1]张达敏,徐航,王依柔,宋婷婷,王栎桥.嵌入Circle映射和逐维小孔成像反向学习的鲸鱼优化算法[J].控制与决策,2021,36(05):1173-1180.