Temporal Kernel Selection Block
paper题目:BiCnet-TKS: Learning Efficient Spatial-Temporal Representation for Video Person Re-Identification
paper是中科院发表在CVPR 2022的工作
paper地址:链接
Code:链接
在 [30, 42] 之后,我们将视频网络分解为分别处理空间线索和时间关系。利用高效的 BiCnet 充分挖掘空间线索,我们构建了一个 Temporal Kernel Selection 块来联合建模短期和长期时间关系。由于不同尺度的时间关系对于不同的序列具有不同的重要性(如图 2 所示),TKS 以动态方式组合多尺度时间关系,即根据输入序列为不同的时间尺度分配不同的权重。

图 2:短期和长期的时间关系对于不同的序列具有不同的重要性。(a) 部分遮挡的序列。需要长期的时间线索来减轻遮挡。(b) 快速移动的行人序列。需要短期时间线索来模拟详细的运动模式。
特别的, T K S \mathrm{TKS} TKS 以一系列连续帧特征图 F = { F t } t = 1 T F=\left\{F_{t}\right\}_{t=1}^{T} F={ Ft}t=1T 作为输入, 其中 F t F_{t} Ft 是第 t t t 帧 的特征图, 并在 F F F 上执行三重操作, 即 Partition、Select 和 Excite。
分区操作。由于不完善的人物检测算法, 视频的相邻帧没有很好地对齐, 这可能 会使时间卷积在视频 reID [9]上无效。在 [34]之后,我们使用分区策略来缓解 空间错位问题。具体来说, 给定视频特征图 { F t } t = 1 T \left\{F_{t}\right\}_{t=1}^{T} {
Ft}t=1T, 我们将每帧特征图均匀地划 分为 h × w h \times w h×w 个空间区域, 并对每个划分的区域进行平均池化, 构建区域级视频特 征图 X ∈ R T × C × h × w X \in \mathbb{R}^{T \times C \times h \times w} X∈RT×C×h×w 。
选择操作。如图 4 所示, 给定 X X X, 涐们进行 K K K 条并行路径 { F ( i ) : X → Y ( i ) ∈ \left\{\mathcal{F}^{(i)}: X \rightarrow Y^{(i)} \in\right. {
F(i):X→Y(i)∈ R T × C × h × w } i − 1 K \left.\mathbb{R}^{T \times C \times h \times w}\right\}_{i-1}^{K} RT×C×h×w}i−1K, 其中 F ( i ) \mathrm{F}(\mathrm{i}) F(i) 是具有 2 i + 1 2 i+1 2i+1 内核大小的 1 D 1 \mathrm{D} 1D 时间卷积 [ 30 ] [30] [30] 。为了 进一步提高效率, 具有 ( 2 i + 1 ) × 1 × 1 (2 i+1) \times 1 \times 1 (2i+1)×1×1 内核的时间卷积被替换为具有 3 × 1 × 1 3 \times 1 \times 1 3×1×1 内 核和扩张大小 i i i 的扩张卷积。选择操作的基本思想是使用来自所有时间路径的全 局信息来确定分配给每个路径的权重。具体来说, 涐们首先通过元素求和融合所 有路径的输出, 然后执行全局平均池化以获得全局特征 u ∈ R C × 1 u \in \mathbb{R}^{C \times 1} u∈RC×1 :
u = G A P T , h , w ( ∑ i = 1 K Y ( i ) ) u=G A P_{T, h, w}\left(\sum_{i=1}^{K} Y^{(i)}\right) u=GAPT,h,w(i=1∑KY(i))
其中 G A P T , h , w G A P_{T, h, w} GAPT,h,w 表示沿时间和空间维度的全局平均池化。之后根据全局嵌入 u u u 得 到通道选择权重 { g i ∈ R C × 1 } i − 1 K \left\{g_{i} \in \mathbb{R}^{C \times 1}\right\}_{i-1}^{K} {
gi∈RC×1}i−1K,
g i = exp ( W i u ) ∑ j − 1 K exp ( W j u ) i ∈ { 1 , … , K } g_{i}=\frac{\exp \left(W_{i} u\right)}{\sum_{j-1}^{K} \exp \left(W_{j} u\right)} \quad i \in\{1, \ldots, K\} gi=∑j−1Kexp(Wju)exp(Wiu)i∈{
1,…,K}
其中 W i ∈ R C × O W_{i} \in \mathbb{R}^{C \times O} Wi∈RC×O 是为 Y ( i ) Y^{(i)} Y(i) 生成 g i g_{i} gi 的变换参数。然后通过各种时间核上的选择极 重获得聚合特征图 Z ∈ R T × C × h × w , Z \in \mathbb{R}^{T \times C \times h \times w \text {, }} Z∈RT×C×h×w,
Z = ∑ i = 1 K R ( g i ) ⊙ Y ( i ) Z=\sum_{i=1}^{K} \mathcal{R}\left(g_{i}\right) \odot Y^{(i)} Z=i=1∑KR(gi)⊙Y(i)
其中 R \mathcal{R} R 是将 g i ∈ R C × 1 g_{i} \in \mathbb{R}^{C \times 1} gi∈RC×1 重塑为 R 1 × C × 1 × 1 \mathbb{R}^{1 \times C \times 1 \times 1} R1×C×1×1 以与 Y ( i ) Y^{(i)} Y(i) 的大小兼容的重塑操作。
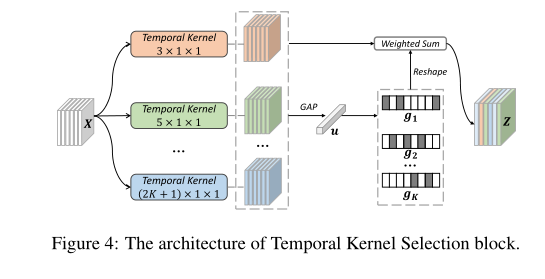
值得指出的是,与使用尺度权重提供粗融合相比,我们选择使用通道权重(等式 7)进行融合。这种设计产生了更细粒度的融合,可以调整每个特征通道。此外,权重是根据输入视频动态计算的。这对于不同序列可能具有不同主导时间尺度的 reID 至关重要。
激发操作。激发操作通过使用残差方亲对 Z Z Z 进行调节来调制输入特征图。最终 的特征图 map E = { E t } t = 1 T \operatorname{map} E=\left\{E_{t}\right\}_{t=1}^{T} mapE={ Et}t=1T 为: E t = U ( Z t ) + F t E_{t}=\mathcal{U}\left(Z_{t}\right)+F_{t} Et=U(Zt)+Ft 。这里 U \mathcal{U} U 是最近邻上来样器, 它对 Z t Z_{t} Zt 执行上米样以世配 F t F_{t} Ft 的空间分辨率。 T K S \mathrm{TKS} TKS 块保持输入大小, 因此可以揷入到 BiCnet 的任何深度以提取有效的时空特征。
TEMPORAL-WISE DYNAMIC NETWORKS
paper题目:Dynamic Neural Networks: A Survey
paper是清华发表在TPAMI 2021的工作
paper链接:地址
通常,可以通过在不重要的时间位置为输入动态分配较少的计算/不计算来提高网络效率。
Temporal-wise Dynamic Video Recognition
对于视频识别,视频可以被视为帧的顺序输入,时间动态网络旨在为不同的帧分配自适应计算资源。这通常可以通过两种方法来实现:1)在循环模型的每个时间步中动态更新隐藏状态,以及 2)对关键帧执行自适应预采样(第 4.2.2 节)。
Video Recognition with Dynamic RNNs
视频识别通常通过循环过程进行,其中视频帧首先由 2D CNN 编码,然后将获得的帧特征依次馈送到 RNN 以更新其隐藏状态。基于RNN的自适应视频识别通常通过以下方式实现:1)用相对便宜的计算处理不重要的帧(“glimpse”)[177],[178];2)提前退出[61],[62];3)执行动态跳跃来决定“where to see”[61]、[179]、[180]、[181]。
-
隐藏状态的动态更新。为了减少每个时间步的冗余计算,LiteEval [177] 在两个具有不同计算成本的 LSTM 之间做出选择。ActionSpotter [178] 根据每个输入帧决定是否更新隐藏状态。AdaFuse [182] 选择性地重用上一步中的某些特征通道,以有效地利用历史信息。最近的工作还提出在处理顺序输入帧时自适应地决定数值精度[183]或模态[184]、[185]。
-
暂时提前退出。人类能够在观看整个视频之前轻松理解内容。这种提前停止也在动态网络中实现,仅基于视频帧的一部分进行预测 [61]、[62]、[186]。与时间维度一起,[62] 中的模型进一步实现了从网络深度方面的早期退出。
-
跳过视频。考虑到使用 CNN 对那些不重要的帧进行编码仍然需要大量计算,更有效的解决方案可能是动态跳过某些帧而不观看它们。现有技术 [179]、[180]、[187] 通常学习预测网络在每个时间步应跳转到的位置。此外,在 [61] 中允许提前停止和动态跳跃,其中跳跃步幅被限制在离散范围内。自适应帧 (AdaFrame) [181] 生成 [0, 1] 范围内的连续标量作为相对地点。
Dynamic Key Frame Sampling
首先执行自适应预采样过程,然后通过处理选定的关键帧或剪辑子集进行预测。
-
时间注意力是网络关注显著帧的常用技术。对于人脸识别,神经聚合网络 [22] 使用软注意力来自适应聚合帧特征。为了提高推理效率,实现了硬注意力以使用 RL 迭代地删除不重要的帧,以进行有效的视频人脸验证 [188]。
-
采样模块也是动态选择视频中的关键帧/剪辑的流行选项。例如,首先在 [189]、[190] 中对帧进行均匀采样,然后对每个选定的帧做出离散决策以逐步前进或后退。至于剪辑级别的采样,SCSample [191] 是基于经过训练的分类器设计的,以找到信息量最大的剪辑进行预测。此外,动态采样网络 (DSN) [192] 将每个视频分割成多个部分,并利用跨部分共享权重的采样模块从每个部分中采样一个剪辑。
Temporal Deformable Convolutional Encoder
paper题目:Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning
paper是中山大学发表在AAAI 2019的工作
paper地址:链接
编码器是将源序列(即视频的帧/剪辑序列)作为输入并产生中间状态以对语义内容进行编码的模块。在这里,我们在 TDConvED 的编码器中设计了一个时间可变形卷积块,它在输入序列上应用时间可变形卷积,以捕获以自由形式时间变形采样的帧/剪辑的上下文,如图 3 (a) 所示。这种时间可变形卷积的设计通过在视频中的动作/场景的自然基础上捕捉时间动态来改进传统的时间卷积。同时,编码器中的前馈卷积结构可以实现输入序列内的并行化,并允许快速计算。此外,为了在编码阶段利用输入序列之间的长期依赖关系,在编码器中堆叠多个时间可变形卷积块,以整合来自输入序列中大量时间采样的上下文信息。
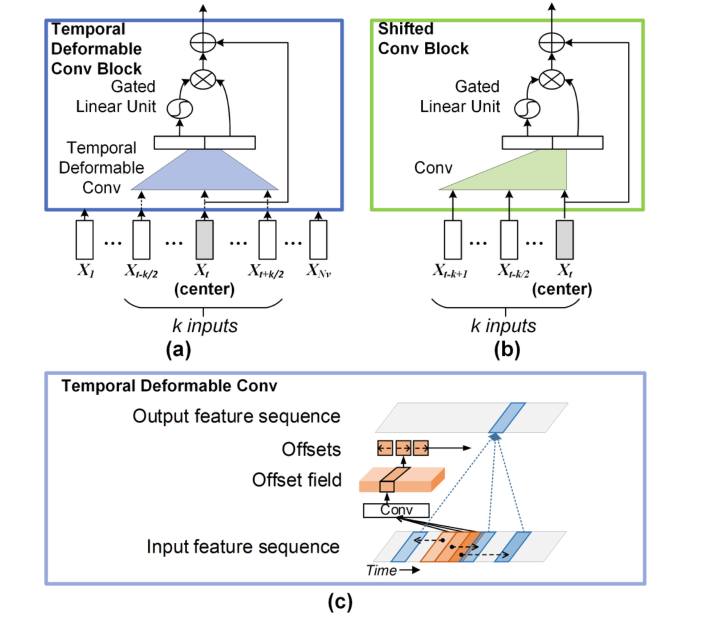
图 3:(a) 编码器中的时间可变形卷积块、(b) 解码器中的移位卷积块和 © 时间可变形卷积的图示。
公式上, 考虑编码器中的第 l l l 个时间可变形卷积块, 其对应的输出序列表示为 出。给定第 ( l − 1 ) (l-1) (l−1) 个块的输出序列 p l − 1 = ( p 1 l − 1 , p 2 l − 1 , … , p N v l − 1 ) \mathbf{p}^{l-1}=\left(p_{1}^{l-1}, p_{2}^{l-1}, \ldots, p_{N_{v}}^{l-1}\right) pl−1=(p1l−1,p2l−1,…,pNvl−1), 每个输出的中间状态 p i l p_{i}^{l} pil 是通过将 p l − 1 \mathbf{p}^{l-1} pl−1 的子序列送入时空变形卷积 (核大小: k k k ) 加上一个非线性单元来 实现。请注意, 时间变形卷积以两阶段的方式运行, 即首先通过一维卷积测量采 样帧/片段的时间偏移,然后汇总. 采样帧/片段的特征, 如图 3 © 所示. 更具体 地说, 今 X = ( p i + r 2 l − 1 , p i + r 2 l − 1 , … , p i + r k l − 1 X=\left(p_{i+r_{2}}^{l-1}, p_{i+r_{2}}^{l-1}, \ldots, p_{i+r_{k}}^{l-1}\right. X=(pi+r2l−1,pi+r2l−1,…,pi+rkl−1 表示 p l − 1 \mathbf{p}^{l-1} pl−1 的子序列,其中 r n r_{n} rn 是 R R R 的 n n n 个元素, R = { − k / 2 , … , 0 , … , k / 2 } R=\{-k / 2, \ldots, 0, \ldots, k / 2\} R={
−k/2,…,0,…,k/2} 。第 l l l 个时间可变形卷积块中的一维卷积可以参数化为变 移量 Δ r i = { Δ r n i } n = 1 k ∈ R k : \Delta r^{i}=\left\{\Delta r_{n}^{i}\right\}_{n=1}^{k} \in \mathbb{R}^{k}: Δri={
Δrni}n=1k∈Rk:
Δ r i = W f l [ p i + r 2 l − 1 , p i + r 2 l − 1 , … , p i + τ k l − 1 ] + b f l \Delta r^{i}=W_{f}^{l}\left[p_{i+r_{2}}^{l-1}, p_{i+r_{2}}^{l-1}, \ldots, p_{i+\tau_{k}}^{l-1}\right]+b_{f}^{l} Δri=Wfl[pi+r2l−1,pi+r2l−1,…,pi+τkl−1]+bfl
其中 Δ r i \Delta r^{i} Δri 中的第 n n n 个元素 Δ r n i \Delta r_{n}^{i} Δrni 表示子序列 X X X 中第 n n n 个样本的测量时间偏移。接下来, 我们通过另一个一维卷积对带有时间偏移的样本进行增强, 实现时间可变形卷积 的输出。
o i l = W d l [ p i + r 1 + Δ r 1 i l − 1 , p i + r 2 + Δ r 2 i l − 1 , … , p i + r k + Δ r k i l − 1 ] + b d l o_{i}^{l}=W_{d}^{l}\left[p_{i+r_{1}+\Delta r_{1}^{i}}^{l-1}, p_{i+r_{2}+\Delta r_{2}^{i}}^{l-1}, \ldots, p_{i+r_{k}+\Delta r_{k}^{i}}^{l-1}\right]+b_{d}^{l} oil=Wdl[pi+r1+Δr1il−1,pi+r2+Δr2il−1,…,pi+rk+Δrkil−1]+bdl

通常是小数, 公式 (4) 中的 p i + r n + Δ r n i l − 1 p_{i+r_{n}+\Delta r_{n}^{i}}^{l-1} pi+rn+Δrnil−1 可以通过时间线性揷值计算。
p i + r n + Δ r n i l − 1 = ∑ s B ( s , i + r n + Δ r n i ) p s l − 1 p_{i+r_{n}+\Delta r_{n}^{i}}^{l-1}=\sum_{s} B\left(s, i+r_{n}+\Delta r_{n}^{i}\right) p_{s}^{l-1} pi+rn+Δrnil−1=s∑B(s,i+rn+Δrni)psl−1
其中 i + r n + Δ r n i i+r_{n}+\Delta r_{n}^{i} i+rn+Δrni 表示一个任意位置, s s s 列举了输入序列 p l − 1 \mathbf{p}^{l-1} pl−1 中的所有积分位置, B ( a , b ) = max ( 0 , 1 − ∣ a − b ∣ ) B(a, b)=\max (0,1-|a-b|) B(a,b)=max(0,1−∣a−b∣) 。
此外, 我们采用门控线性单元 (GLU) 作为非线性单元来缓解梯度传播。因此, 给定时间上可变形卷积 o i l ∈ R 2 D r o_{i}^{l} \in \mathbb{R}^{2 D_{r}} oil∈R2Dr 的输出, 其维度是输入元素的两倍, 通过一个简 单的门控机制在 o i l = [ A , B ] o_{i}^{l}=[A, B] oil=[A,B] 上应用 G L U \mathrm{GLU} GLU 。
g ( o i l ) = A ⊗ σ ( B ) , g\left(o_{i}^{l}\right)=A \otimes \sigma(B), g(oil)=A⊗σ(B),
其中, A , B ∈ R D r , ⊗ A, B \in \mathbb{R}^{D_{r}}, \otimes A,B∈RDr,⊗ 是逐点乘法。 σ ( B ) \sigma(B) σ(B) 代表一个门单元, 控制 A A A 的哪些元素与当 前语境更相关。此外, 从时间可变形卷积块的输入到该块的输出的残差连接被添 加, 以使网络更深入。因此, 第 l l l 个时间可变形卷积块的最终输出被测量为
p i l = g ( o i l ) + p i l − 1 . p_{i}^{l}=g\left(o_{i}^{l}\right)+p_{i}^{l-1} . pil=g(oil)+pil−1.
为了保证时间可变形卷积块的输出序列长度与输入长度匹配, 输入的左右两边都 用 k / 2 k / 2 k/2 个零向量填充。通过在输入帧/剪辑序列上堆叠几个时间可变形卷积块, 我 们获得了上下文向量 z = ( z 1 , z 2 , … , z N v ) \mathbf{z}=\left(z_{1}, z_{2}, \ldots, z_{N_{v}}\right) z=(z1,z2,…,zNv) 的最终序列, 其中 z i ∈ R D r z_{i} \in \mathbb{R}^{D_{r}} zi∈RDr 表示第 i i i 帧 / 剪 辑。