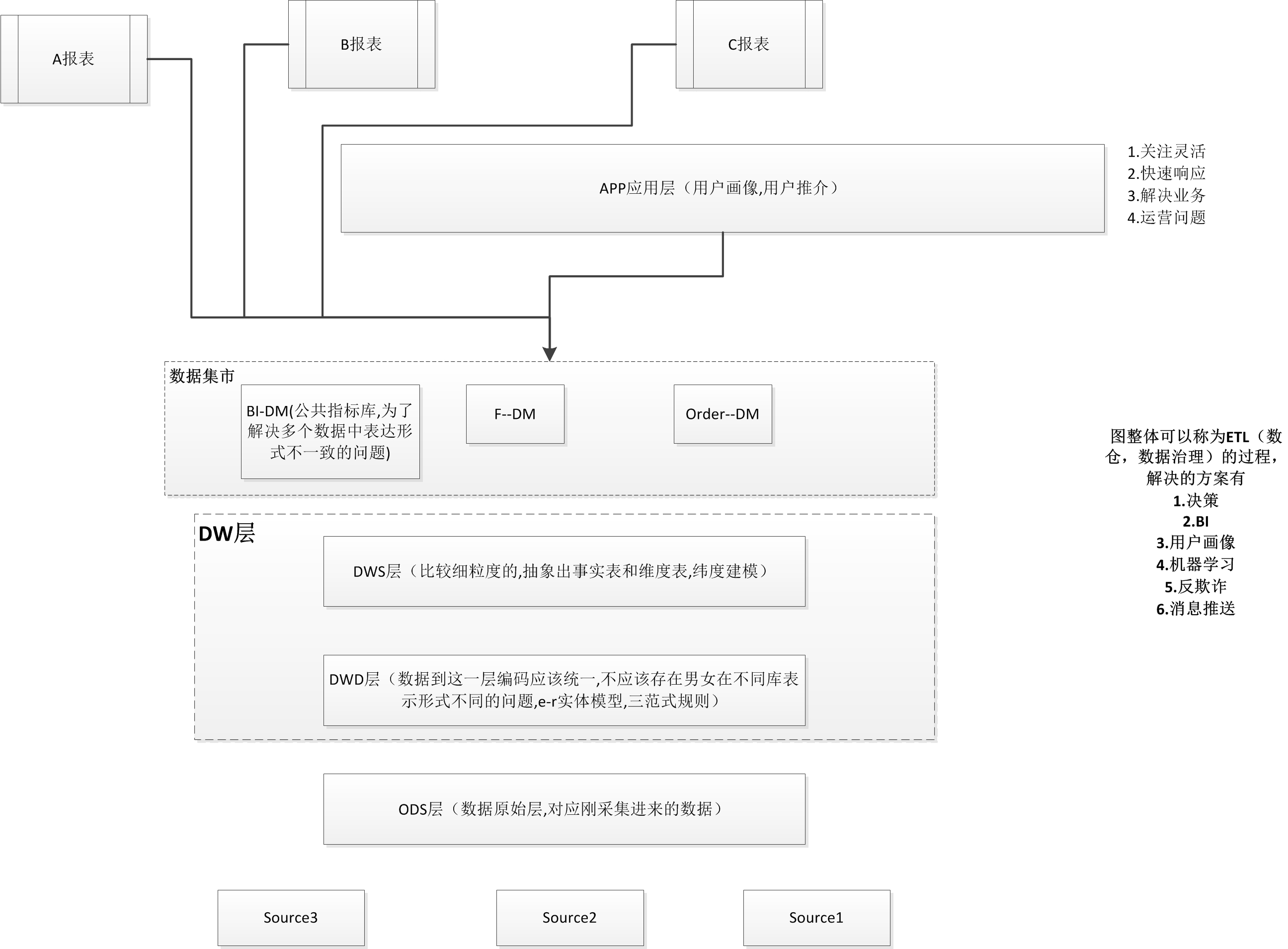
市面公司大多基础模型如图
数仓建模目标
1.访问性能-快速查询所需数据,减少IO,缩短统计路径
2.数据成本-减少不必要的数据冗余,实际计算结果数据复用,降低达数据系统中的存储成本和计算成本
3.使用效率-改善用户体验,提高使用数据率
4.数据质量-改善数据口径不一致性,减少计算错误的可能性,提供高质量的,一致的数据访问平台。
(这里我感觉数据仓库也属于为大数据计算提供便捷的一个设计或者产品吧)
大数据的数仓建摸需要通过建模的方法更好的组织,存储数据,一边在性能,成本,效率和数据质量之间找到最佳的平衡点
关系模式范式
目的:降低数据的冗余性达到数据一致性,涉及规范有
1.第一范式--表字段都应为原子性的,不可分割的
2.第二范式--实体的属性完全依赖于主键字段,不能存在依赖外键之类的字段(非主键)。(缺点:容易造成冗余,调整表字段时候造成大量列的修改)
3.第三范式--消除传递依赖(传统数据库和数据仓库一般只做到第三范式)
4.巴斯-柯德范式(对第三范式的一个补充)
5.第四范式
6.第六范式
数据仓库建模基本理论模型(实体 eg:[商品,仓库,货位,汽车],属性 eg:[颜色,尺寸,重量,产地],关系表示数据之间的关系)
1.ER实体模型
2.维度建模
3.dataValue模型
4.Anchor(key-value)模型
关系:实体之间建立关系时,存在对照关系一般有:
1:1
1:n
n:m
梳理步骤一般为
1.找出实体,抽象出主体
2.梳理关系
3.梳理属性
4.画ER关系图