第4章 决策树 学习心得
基本流程
主要是一个递归过程
def TreeGenerate(D, A): # D为样本集合/列表,A为属性集合
生成节点node
if D 中样本属于同一个类C:
node标记为C类叶子结点
return
if A 为空集(即所有的属性已经用光了) or D中样本在A上取值相同:
将node作为叶节点,标记为D中样本数最多的类
return
从A中挑选最优的属性划分属性a_best
for a in a_best的可取值:
从node生成一个分支点,令D_divided为D中在a_best属性取值为a的样本集合
if D_divided is empty:
该分支节点成为叶子节点,用D中类别最多样本的类标记(即,当预测一个
样本时,这个属性值为a时,他用D中类最多的来估计的,书中所说的服从
父结点的类别先验分布)。
return
else:
分支节点为TreeGenetate(D_divided, A)
划分选择
信息增益(information gain)
信息熵(information entropy)
衡量随机变量可能性“混乱度”的,高中化学提到的熵有点区别,这个用物理上的熵理解非常直观,熵越大越“混乱”越“随机”越”无序”,熵越小越“有序“越”整齐“。公式为:
Ent ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k \operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_{k} \log _{2} p_{k} Ent(D)=−k=1∑∣Y∣pklog2pk
一般code就直接用e作为底数不用2。
条件熵
这里本质理解为加权信息熵就好了,公式很直观:
∣ D v ∣ ∣ D ∣ Ent ( D v ) \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right) ∣D∣∣Dv∣Ent(Dv)
其中 D v D^{v} Dv表示从 D D D中划分出的子集(取了某个已知“条件”)。
所以可以得到信息增益的表达式:
Gain ( D , a ) = Ent ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Ent ( D v ) \operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
即用未划分的信息熵减去划分后的条件熵/加权信息熵,也是直观的,如果差距越大,表明划分后分类相比之前更“有序”当然是我们希望的结果。这也是ID3算法使用的思想(Iterative Dichotomiser, 迭代二分类器)。
增益率(gain ratio)
ID3算法使用的这种信息增益思想的一个缺点是,当属性可取值增多时,其得到的条件熵往往就变小了(类越多,每个分类自然直观上也会越整齐),极端情况是书上每个属性取值对应一个样本的情况,那条件熵就是0了,信息增益取当前最大,但这种情况显然不能很好地泛化。于是为了平衡,平衡这种分类数增多造成的熵增(类多本身也是一种无序),因此可以用划分本身造成的熵增来约化信息增益,公式为:
Gain ratio ( D , a ) = Gain ( D , a ) IV ( a ) \operatorname{Gain} \operatorname{ratio}(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)} Gainratio(D,a)=IV(a)Gain(D,a)
其中,
IV ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ \operatorname{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
称为a的固有值(intrinsic value),其实就是按照A集合划分造成的熵增,显然划分越多熵增越多,从而平衡信息增益的增大。因此增益率有一定的对于属性可取值少的属性作为划分属性的偏好。
基尼指数(Gini index)
定义从数据集中随机有放回抽取两个样本,不属于同一类的概率为基尼值:
Gini ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 \begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′=1−k=1∑∣Y∣pk2
比较直观地,如果数据集纯度比较大,那么基尼值越小。
对应信息熵与条件熵,基尼值与基尼指数有类似的“加权”关系,基尼指数定义为:
Gini_index ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Gini ( D v ) \operatorname{ Gini\_index }(D, a)=\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Gini}\left(D^{v}\right) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
所以更小的基尼指数,表示划分纯度更高,这是CART(Classification and Regression Tree)算法采用的思想。
剪枝处理(pruning)
为了解决过拟合,减少过多的叶子结点的产生,控制树的“深度”。
预剪枝(prepruning)
在生成结点的过程中,利用验证集去衡量对结点划分前后的泛化能力/正确率,从而在划分后正确率/泛化能力下降的结点结束划分成为叶节点。
预剪枝也存在一定的问题,它无法保证某个节点划分后泛化能力的下降是否是暂时的,比如,在其划分后如果继续划分可能可以达到更低的错误率,因此预剪枝有欠拟合风险。
后剪枝(postpruning)
先生成一棵完整的决策树,然后自下而上考察含有叶节点的中间节点,考察将其叶节点去掉,自身作为叶节点后,对于验证集是否有正确率的提高,如果有则进行剪枝。
一般后剪枝欠拟合风险较小,但是训练的时间开销要大于决策树生成本身和预剪枝。
连续与缺失值
连续值的处理
其实就是回归树的生成过程中,划分点的选择,书中说比如有n个属性,则有n-1个划分点,其实也不一定,完全可以增加一个,即将所有的都化为一个类中。这样实际中可以不用信息增益,而启发式的进行学习,比如大于某分割的为正类,小于为负类,或者小于为正,大于为负,然后依据错误率最小找到最优划分点以及取大于还是小于的不等号(见之前自己写的代码)。
缺失值的处理
对于缺失值书上介绍了C4.5算法的处理方法,基本思想可以总结为,在选择划分属性时,根据未缺失样本占总样本的加权数量比例,加权(由未缺失属性值的样本子集计算出的)信息增益,从而平衡不同属性的信息增益因为样本数目不同造成的差异;在选取最佳属性之后,划分子节点时候,对于该属性缺失的样本,按照未缺失样本划分的数量分布,将样本数量加权并分到每个节点(相当于比如将0.1个样本分到某一子节点),这个数量将在之后的划分中一直保留或再次被“加权”(另外划分属性也缺失值时)。
具体地,定义:
ρ = ∑ x ∈ D ~ w x ∑ x ∈ D w x \rho=\frac{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in D} w_{\boldsymbol{x}}} ρ=∑x∈Dwx∑x∈D~wx
p ~ k = ∑ x ∈ D ~ k w x ∑ x ∈ D ~ w x ( 1 ⩽ k ⩽ ∣ Y ∣ ) \tilde{p}_{k}=\frac{\sum_{\boldsymbol{x} \in \tilde{D}_{k}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad(1 \leqslant k \leqslant|\mathcal{Y}|) p~k=∑x∈D~wx∑x∈D~kwx(1⩽k⩽∣Y∣)
r ~ v = ∑ x ∈ D ~ v w x ∑ x ∈ D ~ w x ( 1 ⩽ v ⩽ V ) \tilde{r}_{v}=\frac{\sum_{\boldsymbol{x} \in \tilde{D}^{v}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad(1 \leqslant v \leqslant V) r~v=∑x∈D~wx∑x∈D~vwx(1⩽v⩽V)
其中的 w x w_{\boldsymbol{x}} wx即为数量权重,一开始初始为1,表示每个样本自身的数量,当有缺失值且按照缺失属性划分时,数量权重会变化。此时信息增益为:
Gain ( D , a ) = ρ × Gain ( D ~ , a ) = ρ × ( Ent ( D ~ ) − ∑ v = 1 V r ~ v Ent ( D ~ v ) ) \begin{aligned} \operatorname{Gain}(D, a) &=\rho \times \operatorname{Gain}(\tilde{D}, a) \\ &=\rho \times\left(\operatorname{Ent}(\tilde{D})-\sum_{v=1}^{V} \tilde{r}_{v} \operatorname{Ent}\left(\tilde{D}^{v}\right)\right) \end{aligned} Gain(D,a)=ρ×Gain(D~,a)=ρ×(Ent(D~)−v=1∑Vr~vEnt(D~v))
其中
Ent ( D ~ ) = − ∑ k = 1 ∣ Y ∣ p ~ k log 2 p ~ k \operatorname{Ent}(\tilde{D})=-\sum_{k=1}^{|\mathcal{Y}|} \tilde{p}_{k} \log _{2} \tilde{p}_{k} Ent(D~)=−k=1∑∣Y∣p~klog2p~k
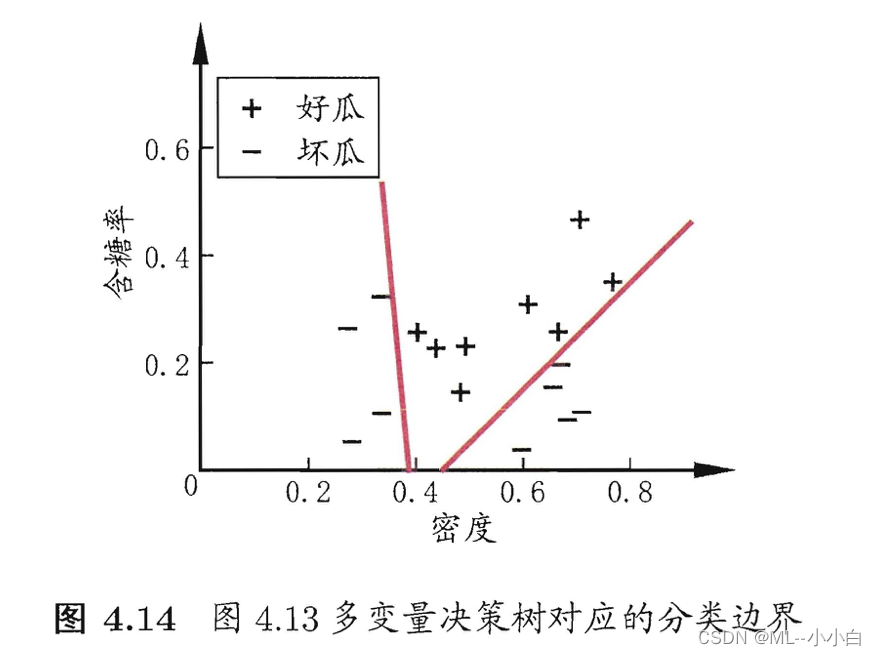
多变量决策树(multivariate decision tree)
亦称斜决策树(oblique decision tree)本质上就是把原来的属性划分(特征空间中轴平行axis-parallel式地划分),变成在特征空间的线性划分(线性分类器),如图所示: