2020年9月25-26日,2020年中国科技峰会系列活动青年科学家沙龙将迎来新的一期—“人工智能学术生态与产业创新”。本次活动由中国科学技术协会主办,清华大学计算机系、AI TIME、智谱·AI承办;大会完整视频报告,请在B站关注“AI Time论道”,或点击下方“阅读原文”。
9月25日上午,大会邀请到达闼科技首席架构师,研发副总裁赵开勇先生做了名为《基于自学习的机器人决策系统》的主题演讲。
在演讲中,赵开勇先生主要介绍了达闼科技通过云端平台加速机器人学习,并形成了一套传统方法+人类经验+强化学习的方法。
赵开勇, 博士, 机器人,人工智能,高性能计算领域的资深从业者,拥有多年的科技开发,团队管理及行业拓展经验并购经验。现任CloudMinds首席架构师,研发副总裁,负责带领人工智能与导航部门,之前为大疆互联网事业部负责人,负责公司互联网服务及3D测绘行业应用的整体策略。赵博士长期从事高性能计算
一、机器人控制面临的问题

达闼科技是前中国移动研究院院长黄晓庆于2015年成立的公司,是一家云端智能机器人运营商,主要从事云端智能机器人运营级别的安全云计算网络、大型混合人工智能机器学习平台、以及安全智能终端和机器人控制器技术的研究。
可以看一下他们主要的产品,包括云端的服务机器人、云端安防机器人、清洁机器人、生活机器人和云端的门禁,这些终端设备通过安全高速的光纤网络(VBN),与云端机器人操作系统HARIX相连接。在这个过程中遇到了很多实际的问题,研究过程中将很多学术相关的方法和研究拿到机器人应用开发里面,介绍了在做机器人应用或者开发的时候遇到的实际问题和解决方案。

上图是报告的几个主题,第一部分讲解了机器人在传统控制方法中所面临的问题,我们的服务机器人是一个仿人形的机器人,这个机器人怎么学习动作,通用传统的方式是对机器人的每个动作进行轨迹规划,并进行编码,这就导致每次添加新动作都需要重新编程。。第二部分讲解的是逐步提高机器人系统的学习能力,当机器人要学一个新动作的时候,不一定非要重新编程,可以通过机器学习的方式让机器人学习新的动作,逐步提高其学习、决策的能力。。第三是构建了一套仿真平台,即数字孪生平台。在20年前做机器人的时候,要在仿真平台做机器人的训练或者学习并不方便,由于近些年来计算能力的提升,可以很容易的在云端或者在虚拟环境中搭建完整的机器人运动学、动力学及控制系统,这样可以在仿真平台里进行大量的训练,而不是必须造出机器人硬件再做开发。有了这样一套仿真环境以后,下一步就是需要考虑怎么把传统控制方法和生物的已有的一些经验加到仿真平台里面来,形成一套可以自学习的系统。后面我会举几个例子,一个是仿人形的机器人怎么学跳舞,机器人怎么去做抓取,还有四足机器狗的步态学习。

在上面两幅图中,左图是机器人配合茉莉花音乐学跳舞。最开始编排动作的时候专门找了舞蹈学院的老师帮忙,但是如何将机器人动作变得更柔和、更拟人,是非常具有挑战的问题。右图是机器人抓取的过程。可以看到服务机器人的抓取动作与工厂里面的工业机器人差别较大,因为服务机器人需要在日常生活等非结构化空间中工作,因此抓取的物品种类、大小、重量、位置等都无法确定,而且抓取规划中还可能遇到障碍物进行避障,这个抓取的过程其实也是相对比较复杂的过程。

左图是四足机器狗,四足机器人的步态规划是目前尚未解决的问题,目前的传统方法生成的步态与真实的四足动物相比差别非常大,且传统方法大多未考虑到不同情况下步态的区别,即使现在可以在仿真中可以模拟不同环境,但传统方法仍然无法生成灵活的步态规划。右图是在小区里机器人的避障,小区里的环境很复杂,在实验室里不会有小朋友围着机器人转,有的小朋友可能把镜头盖住,甚至碰激光雷达,或者爬到机器人上面去,这些实际问题都考验了机器人规划决策系统的稳定性。总体来说和前面机器狗的动作、抓取、跳舞都有类似的内容,我们把这些过程抽象出来,把所有的控制过程,定义为机器人决策。在仿真环境中利用仿生或者强化学习的方法结合传统方法来实现机器人的决策控制。
二、机器人决策系统

传统的电机控制,包括有电流环,速度环,位置环。这是一个成熟的过程,今天我不会讲这方面的内容。我们把每个关节的控制定义为基础层的控制,有了基础层的控制之后,多个关节组合起来形成一些配合的控制。通过前面的几个视频,我们可以看到,传统的关节控制,组合起来,就是多关节联动,就是通常意义下的二维或者三维路径规划或者是步态规划。我们把组合的过程抽象成了机器人决策过程,基本动作决策。就好比我们的小脑的平衡决策,而不只是一个简单的规划问题。
三、数字孪生
在达闼公司内部,借助于高性能的硬件和计算的提升,架构了一套机器人训练仿真平台,包括云端的管理和储存,中间也包含有AI的训练平台。借助仿生学原理以及人体及动物的运动数据,再结合模仿学习、强化学习等AI算法,从而构建了一套基础动作学习库。在仿真平台中,我们把每一个机器人的关节都按照接近真实的物理模型方式进行建模,在仿真环境里面就可以进行机器人的训练。在仿真平台里面,还可以根据控制的要求,对硬件关节进行修改参数,最后对真实生产的关节提出需求。这个过程就可以对硬件的设计提供很好的帮助。
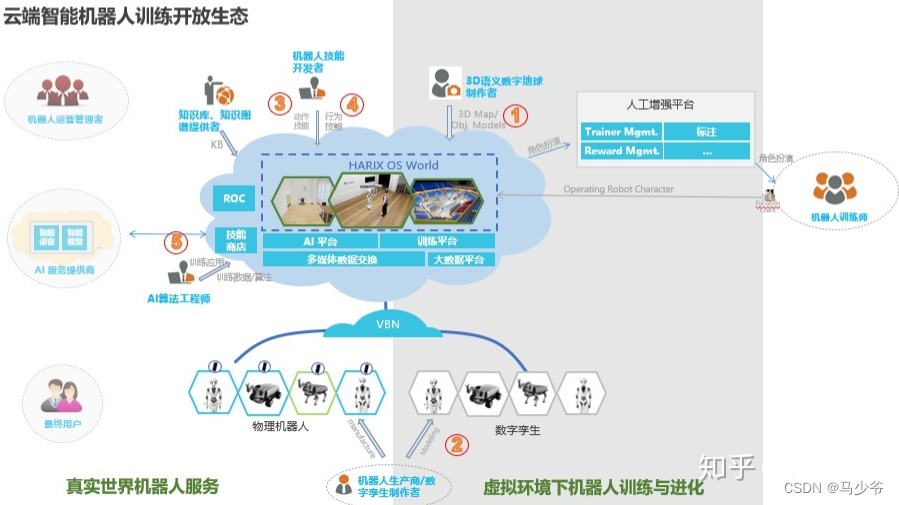
这是云端的智能机器人开放平台,已经在一些高校中得到了应用。这个平台相当于在物理真实机器人的基础上,同时会有一套接近真是的数字孪生系统,对每个机器人进行仿真。从云端来讲,会先有一套3D的语义环境,构建一套机器人的使用场景,同时把机器人模型放到这个环境里面。同时把已有的知识库或者传统的动作技能放到这个系统里面去,再根据训练的要求进行动作的开发。之后根据3和4收集到的数据再进行大量的AI训练。这相当于利用传统的经验和人的经验构建一个有限的空间再经过AI的仿生学习和强化学习的方式进行更高层次的空间的搜索,分成几层进行不同的配合和训练。就类似alphago的过程中,通过人类的棋谱进行训练,训练有一个基础以后再进行左右互搏,再更大的空间及逆行搜索。
四、机器人控制

总结过去的一些研究,可以看到传统控制方法如RRT、DMP等,其限定了一个控制域,但如果结合仿生学习和强化学习等,就相当于在更大范围或更高维空间中搜索最优解。
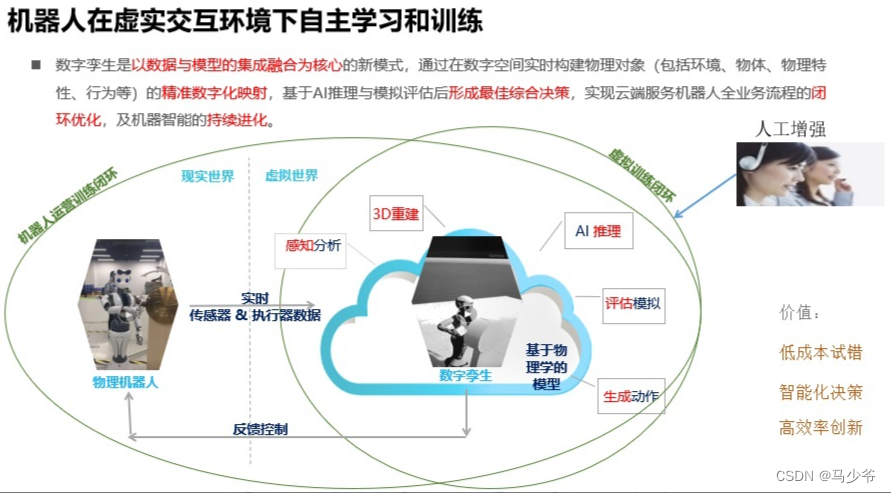
上图是一个真实机器人与虚拟环境中的数字孪生机器人进行配合训练的示意图。比如通过真实机器人传感器感知世界信息,就可以在虚拟环境中进行三维重建,再通过AI推理决策,即可产生行为,并在虚拟环境中尝试动作进行评估,准确无误后下载到真实机器人上进行执行。

如果要学一个新动作会先通过一个视频,视频中工作人员做一个动作,根据每个动作实时的识别完之后生成动作。我们从抖音上抓了很多的视频,通过2D视频得到3D的姿态,这些姿态映射到机器人关节里面。当然这里面的映射不是一个简单的映射,如果是简单的映射这里面会出现问题,例如机器人平台的关节和动作不一定能和跳舞的人的动作一致,也有可能发生碰撞。如果想让机器人生成的动作更加优美,更加拟人化,就需要根据这些数据进行自学习,进而产生数据驱动的行为动作,在这个过程中,机器人会根据自身的结构特性以及物理限制生成尽可能相似的动作,使得机器人舞姿尽可能的贴近自然。
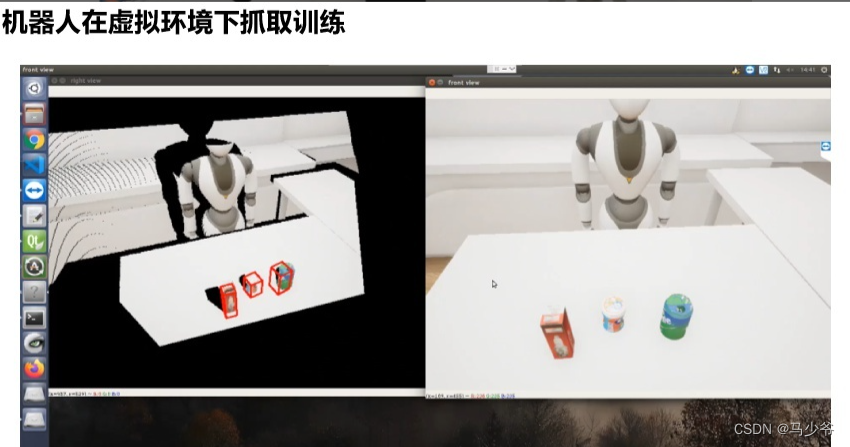
第二个场景是抓取。左边的是真实的场景,右边是一个虚拟的场景。为了生成更加拟人化的抓取动作,首先需要人穿戴运动捕捉设备进行数据记录,在仿真平台中结合AI进行大量训练,就可以形成一套机器人的抓取知识库,这样也避免了新的抓取动作再次采集数据。

上图是机器狗,在仿真环境里用MIT的模型做控制,比如前进后退,大家可能网上都看到过。
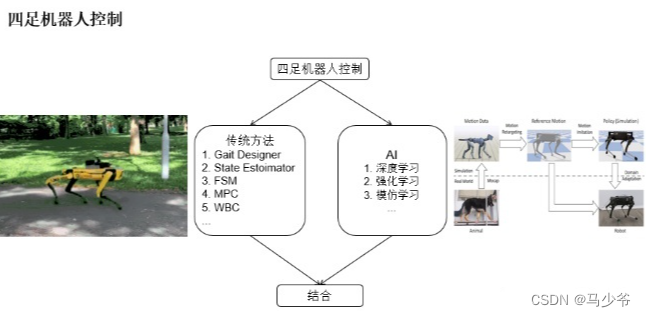
这个机器人动作的实现是把传统的控制方式和深度学习、仿生习结合起来,相当于既有传统的搜索空间,同时又通过一些强化学习等机器学习的方式搜索更大的空间。因为传统的方法一般是需要建模,因此控制效果往往因为建模的简化而受到影响,当结合强化学习的方式就得到一个更广的搜索空间。

通过比较两边,可以看到仿生的训练是端到端的训练,不需要复杂的设计,但是它不够灵活,没办法现在落地。传统的方法比较灵活,鲁棒性也比较强,但是动作并不是最优的动作,就说每个动作,比如在行走过程中,四足机器人的步态规划与真实动物相差较大。把两者结合起来,可以达到能量消耗减少,稳定性更强。
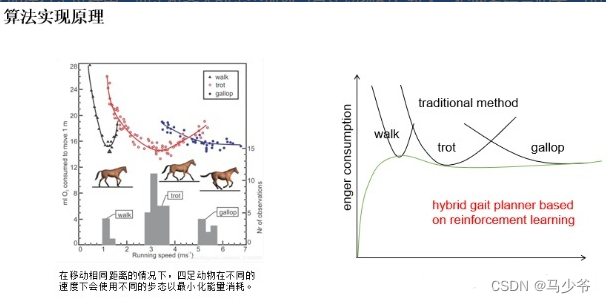
这是四足动物行走过程中的能量消耗曲线。机器人传统控制方式中,每个步态是单独的状态,只能由一种步态瞬间切换到另一个步态,而真实动物却与此有较大的不同。最近谷歌有篇论文,其在进行这样的AI训练或者搜索的时候,大量的数据通过网上抓过或者外部搜集。其实在这个过程中我们也意识到这个问题,因为人或者自然界已经有大量的数据,我们需要把这样的数据结合起来,形成一个由数据驱动的机器人动作训练方法,而不需要完全从头开始训练一个动作,尤其是做四足步态机器人或者机器人的抓取的动作,因为已经存在大量的经验值。采用这些经验值后,通过对数据进行一些约束和边界条件的界定,实现在有限的空间里进行搜索,并且更快的达到理想的效果,这些动作所消耗的能量能够达到最低。
这是对机器狗做不同步态训练的时候,训练多个机器人,加入不同的参数比如不同的力,不同环境的情况。
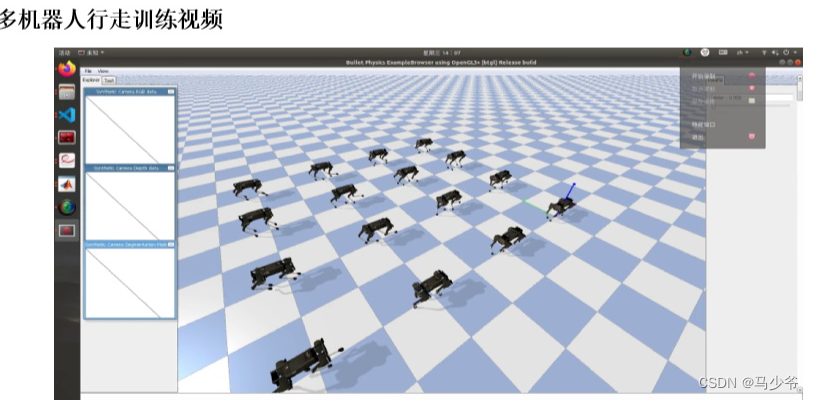
这是一个大规模的场景训练,这里面有不同的状态。因为这是一个分布式的平台,所以速度可以做的很快。这里面关键点在于,我们会借助传统的方法得到一个有限的搜索空间,同时利用经验值得到另外一个搜索空间,结合强化学习等AI训练就可以在更广的范围内结合两者找到最优。有点类似于AlphaGO学习棋谱的时候先用人类的棋谱学一些信息,当然这里的学习更多的会加入人为控制的环节,把人的经验值放到这里面。
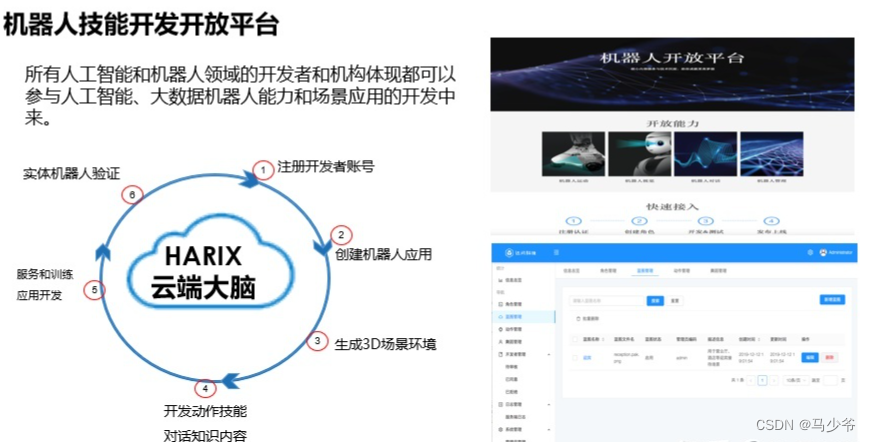
这是达闼的开放平台,已经在高校里进行使用。这个训练平台还有整个训练过程放到网上以后,会有更多的人使用到这个的开放平台,可以在这上面训练自己的机器人,甚至自己架构一套机器人系统,可以放到这上面得到一个实际的你想要的效果。现在我们内部设计机器人的时候,已经和传统的设计机器人的方式有所区别,我们会先在仿真平台把机器人的特性要求设计出来。这基于现在较强的计算能力,摆脱了实体机器人的束缚,所以会先在仿真平台里做训练。对结构的要求,每个环节的要求,每个关节的要求,比如四足机器人都可以首先在里面进行一些步态训练,训练完以后再对硬件提要求,这也是我们开放平台的目的。
