一、机器学习系统设计
机器学习面试涵盖了广泛的技能,如编码、机器学习、概率/统计、研究、案例研究、演示等。重要的机器学习面试之一是系统设计面试。
ML 系统设计面试分析候选人为给定用例设计端到端机器学习系统的技能。
这样做是为了衡量候选人理解开发完整 ML 系统的大局的能力,同时考虑到大部分必要的细节。大多数 ML 候选人都擅长理解 ML 主题的技术细节。但是,在将它们连接在一起时,他们无法辨别设计一个完整的 ML 系统从数据收集到模型评估和部署的复杂性和相互依赖性,因此在此类面试中表现不佳。
在这样的活动中,最重要的是有组织的思维过程。这样的组织思维过程需要准备。在有限的面试时间内,此类问题的通用模板可以派上用场。这可以保证您将注意力集中在重要方面,而不是长时间谈论一件事或完全错过重要话题。
二、通用模板
大多数 ML 系统设计面试问题都可以按照以下模板回答
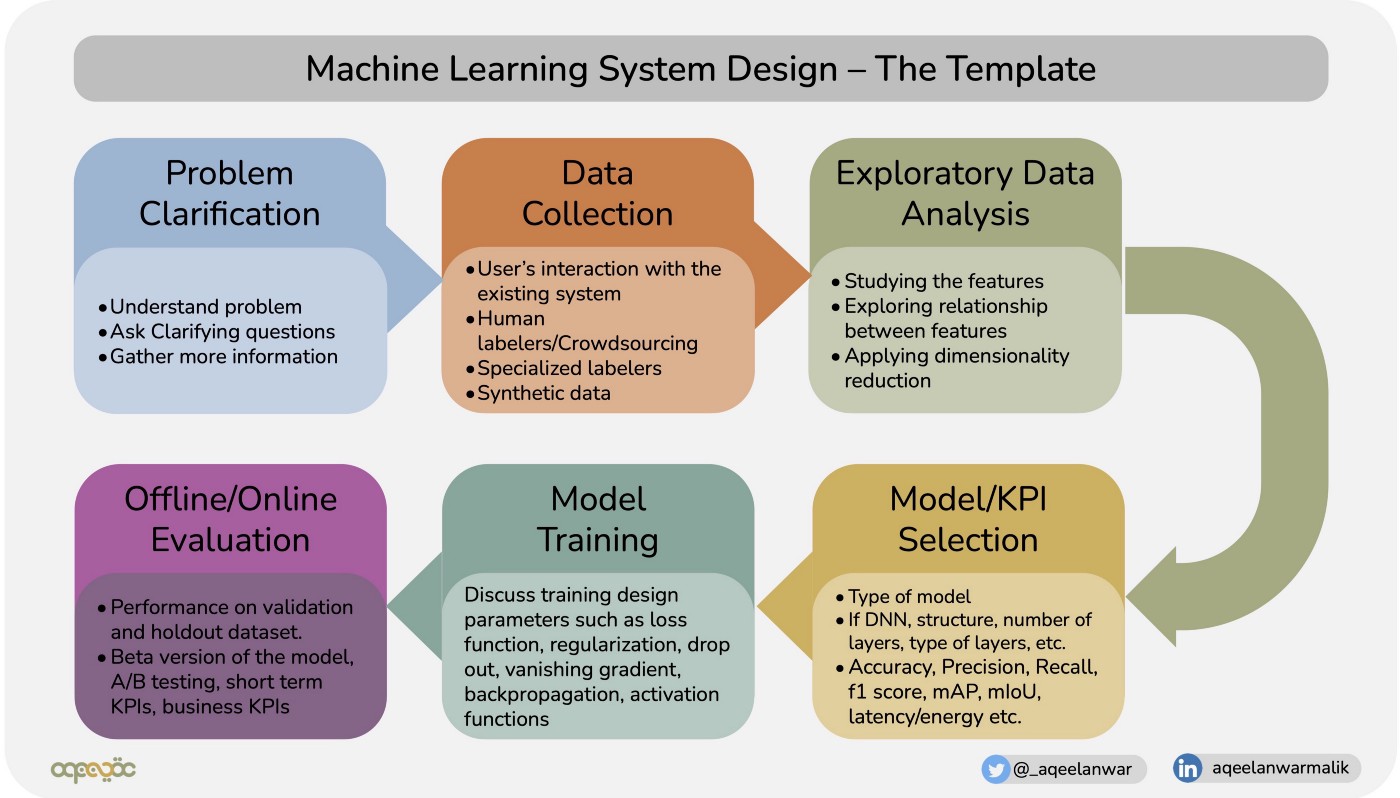
按照上面提到的每个模块的关键资源的六步模板,完成ML设计面试的组织过程。
1、了解问题并提出澄清问题
在开始解决这个问题之前,你必须确保你有足够的信息。ML 设计问题大部分时间都是开放式的。设计高效模型的关键是收集尽可能多的信息。面试官会用最少的信息提出问题。当遇到问题时,您必须确保您正确理解它并提出澄清问题,例如极端情况、数据大小、数据/内存/能量限制、延迟要求等。
2、数据收集/生成
ML模型直接从数据中学习,因此数据的来源和收集策略非常重要。有多种方法可以为您的 ML 系统收集数据。有几种方法
- 用户与现有系统的交互(如果有)
- 人工贴标/众包
- 专业贴标机
- 综合数据
如果您与面试官一起讨论这些要点,将会有所帮助。另一个重要的事情是分析你可以使用什么样的数据,并争论是否有足够的通用性。您应该了解 ML 中不平衡数据集的影响,并在需要时加以解决。确保正负样本平衡,以避免过度拟合到一类。此外,在数据收集过程中不应该有任何偏见。问问自己,数据是否是从足够大的人群中采样的,以便很好地概括。
3、探索性数据分析
一旦你有了原始数据,你就不能直接使用这些数据来输入机器学习系统。你总是必须分析和修剪它。这种预处理包括数据清洗、过滤和去除冗余参数。这样做的几种方法是

- 研究特征(均值、中值、直方图、矩等)
- 探索特征之间的关系(协方差、相关性等)
- 应用降维(如 PCA)去除冗余参数
最终目标是探索哪些特征是重要的,并去掉多余的特征。不必要的特征往往会在模型训练中产生问题,通常称为维度灾难。
4、模型和KPI选择
与其选择复杂的模型,不如从简单的模型开始。分析给定问题和数据的模型,然后不断改进它。面试官对你的思维过程以及你是否能意识到自己的错误并加以改进很感兴趣。在讨论模型时,请确保您谈论的是
- 模型类型(回归、树、ANN、随机森林等)
- 如果您选择 DNN,请讨论结构、层数、层类型等
- 您是否更喜欢一种类型的网络/块,例如 AlexNet、VGGNet、ResNet 和 inception。
- 确保谈论网络的内存和计算使用情况
模型的选择取决于可用数据和性能指标。确保讨论不同的 KPI 以及它们之间的比较。此类 KPI 包括但不限于
- 分类问题:准确度、精确度、召回率、F1 分数、ROC 下面积 (AUROC)
- 回归: MSE、MAE、R-squared/Adjusted R-squared
- 目标检测/定位:联合交集 (IoU)、平均精度 (AP)
- 强化学习:累积奖励、回报、Q 值、成功率。
- 系统/硬件:延迟、能量、功率
- 业务相关 KPI:用户留存、每日/每月活跃用户(DAU、MAU)、新用户
5、模型训练
这是评估技术知识的地方。确保您熟悉 ML 培训的不同方面,并且乐于深入讨论它们。面试官甚至可能会问你如何对抗过度拟合,或者你为什么不使用正则化,如果你做了,你使用了哪一个以及为什么等等。主题包括但不限于
- 损失函数选择: CrossEntropy、MSE、MAE、Huber loss、Hinge loss
- 正则化: L1、L2、熵正则化、K-fold CV、dropout
- 反向传播: SGD、ADAGrad、动量、RMSProp
- 梯度消失以及如何解决它
- 激活函数: Linear、ELU、RELU、Tanh、Sigmoid
- 其他问题:数据不平衡、过拟合、归一化等
6、模型评估
训练模型的最终目标是在手头问题的真实场景中表现良好。它在看不见的数据上表现如何?角落案例是否被覆盖?要分析这一点,需要同时进行离线和在线评估。
- 离线评估:模型在数据集的保留样本上的性能。在数据集收集期间,数据被分为训练、测试和验证子集。这个想法是分析模型对看不见的数据集的概括程度。您还可以进行 K 折交叉验证,以找出不同数据子集下的性能。选择对所选 KPI 表现良好的模型进行实施和部署。
- 在线评价:在现实场景中部署训练好的模型(在离线评估之后)的第一步是进行 A/B 测试。训练后的模型不会很快被用于面对现实世界的大量数据。这风险太大了。相反,该模型部署在一小部分场景上。例如,假设设计的模型是为了匹配优步司机和骑手。在 A/B 测试中,该模型会说只部署在较小的地理区域而不是整个全球。然后,该模型的 beta 版本将在更长的时间内与现有模型进行比较,如果它导致业务相关 KPI 的性能提高(例如 Uber 应用程序的 DAU/MAU 更多,用户留存率,并最终提高 uber 收入),那么它将在更大范围内实施。
7、小结
如果你在任何一步都走错了方向,面试官会介入并试图引导你朝着想要的方向前进。确保你接受了面试官提供的提示。ML系统设计应该是一个讨论,所以每当你陈述一些事情时,询问面试官他们对此有何想法,或者他们是否认为这是一个可以接受的设计步骤。一旦你完成了这 6 个步骤的讨论(在此过程中进行了改进),请务必用几句话概括最终的系统设计参数,并提及过程中的关键要点。