Mobileye转变与芯片技术
参考文献链接
https://mp.weixin.qq.com/s/fLb8zKbHe_oxxIMv3y59TQ
https://mp.weixin.qq.com/s/I7pfDI5j8Th6myRnXTIytA
https://mp.weixin.qq.com/s/PjJdF37H4Ape-IDw68wR1A
https://www.top500.org/news/ornls-frontier-first-to-break-the-exaflop-ceiling/
Mobileye放弃黑盒
7月5日,Mobileye正式发布首个面向EyeQ®系统集成芯片的软件开发工具包(SDK)——EyeQ Kit。使用EyeQ Kit,车企可基于EyeQ® 6 High和EyeQ® Ultra处理器的高能效架构,在EyeQ平台上部署差异化的算法和人机接口工具。
也就是说,Mobileye终于决定放弃其广受诟病的黑盒子了。
早期,Mobileye凭借低成本的视觉感知方案大杀四方,在ADAS领域拿下多家车企。包括理想、蔚来、宝马,彼时都是Mobileye的忠实用户。
在自动驾驶发展初期,Mobileye的黑盒封装设计装车即用,可以大大节约车企的使用成本。但发展到今天,全栈自研已经成为趋势,车企对辅助驾驶的要求也越来越多样,此时的黑盒便成了限制。
诚如李想所言:“理想汽车不允许一个‘黑盒子’出现在车上。”
短短几年时间,多家车企先后与Mobileye分手。
在中国市场的切肤之痛终于让Mobileye下定决心抛弃过去了。
Mobileye中国区总经理路以理表示,EyeQ Kit将赋能中国本土主机厂进行尖端算法应用的自主研发,同时借助Mobileye已被行业验证的技术实力确保解决方案安全可靠。
“在设计这套全新开发工具的过程中,我们充分了解了中国合作伙伴的需求,希望借此为他们的产品带来更多灵活性和差异化的功能。如今,行业客户面临着产品选择收窄的趋势,而Mobileye正在努力拥抱更开放的合作模式。”

EyeQ Kit由数百名Mobileye工程师开发而成,汲取英特尔和Mobileye的技术实力,使车企能够轻松高效地开发属于自己的应用软件,同时支持第三方应用的嵌入式开发,从而降低因集成其他芯片所增加的成本。
通过EyeQ的硬件和软件,汽车制造商可以获得全面的Mobileye解决方案,包括计算机视觉、道路信息管理(REM™)自动驾驶汽车地图技术,以及基于责任敏感安全模型(RSS)的驾驶策略。
此外,EyeQ Kit使车企可以进一步挖掘Mobileye系统集成芯片的强大功能,在增强辅助驾驶功能的同时,也帮助车企实现专属自己品牌的个性化定制。
随着驾驶员和汽车之间交互及通信的视觉需求越来越复杂,EyeQ Kit可为车企提供定制关键信息流的新途径。
通过更先进的增强现实显示屏,EyeQ Kit将帮助客户实现环绕可视化、自动车道保持和交通标志识别等功能。
从通用CPU内核到计算高度密集的加速器(包括深度学习神经网络),EyeQ 具有可扩展的模块化架构,可提供合适的能效来为汽车应用部署人工智能技术,并同时达到超高性能。
Mobileye总裁兼首席执行官Amnon Shashua教授表示:“EyeQ Kit是一个两全其美的解决方案,帮助客户既能受益于Mobileye久经考验的核心技术,也能让他们从自身在驾驶体验和接口方面的专业知识中获益。随着汽车越来越多的核心功能逐渐软件化,客户将需要极高的灵活性和空间来定义品牌并实现差异化。”
EyeQ Kit在降低开发成本、加快产品上市之外,还可在整个开发周期内为硬件厂商提供超高的灵活性。
Mobileye最初赢得市场就是凭借其经济、高效的解决方案。在被问及与英伟达等芯片的算力之差时,Mobileye产品及策略执行副总裁Erez Dagan曾表示,仅用一个数字来衡量芯片是不可取的,算力与功耗之间的平衡更加重要。
但看着一众新车纷纷转头拥抱英伟达Orin,乃至地平线征程系列,大概Mobileye也不得不承认,时代是变了。
不久前极氪与Mobileye分手的传言也引发舆论揣测,曾令英特尔溢价收购的Mobileye是否真的落伍了?
此次推出EyeQ Kit,Mobileye放弃黑盒,不再做一家说一不二的供应商,而是开始拥抱更开放的合作模式。
Amnon Shashua教授给人的印象是技术至上的理性主义者。但放诸市场,不同车企与用户的需求是多样的。拥抱市场,即便站在山巅的供应商也需要更加开放的态度。
Mobileye开始变了。
什么是PoE技术?
PoE(Power over Ethernet)是指通过网线传输电力的一种技术,借助现有以太网通过网线同时为IP终端设备(如:IP电话、AP、IP摄像头等)进行数据传输和供电。
PoE又被称为基于局域网的供电系统(Power over LAN,简称PoL)或有源以太网( Active Ethernet),有时也被简称为以太网供电。
为了规范和促进PoE供电技术的发展,解决不同厂家供电和受电设备之间的适配性问题,IEEE标准委员会先后发布了三个PoE标准:IEEE 802.3af标准、IEEE 802.3at标准、IEEE 802.3bt标准。
为什么需要PoE?
随着网络中IP电话、网络视频监控以及无线以太网设备的日益广泛,通过以太网本身提供电力支持的要求也越来越迫切。多数情况下,终端设备需要直流供电,而终端设备通常安装在距离地面比较高的天花板或室外,附近很难有合适的电源插座,即使有插座,终端设备需要的交直流转换器也难有位置安置。另外,在很多大型的局域网应用中,管理员同时需要管理多个终端设备,这些设备需要统一的供电和统一的管理,由于供电位置的限制,给供电管理带来极大的不便,以太网供电PoE则正好解决了这个问题。
PoE是一种有线以太网供电技术,使用于数据传输的网线同时具备直流供电的能力,有效解决IP电话、无线AP、便携设备充电器、刷卡机、摄像头、数据采集等终端的集中式电源供电。PoE供电具有可靠、连接简捷、标准统一的优势:
• 可靠:一台PoE设备可以同时为多个终端设备供电,实现电源集中供电的同时,还可以进行电源备份。
• 连接简捷:终端设备不需外接电源,只需要一根网线。
• 标准:符合国际标准,使用全球统一的RJ45电源接口,可保证与不同厂商的设备对接。
PoE是如何工作的?
如下图所示,PoE供电系统包括如下两个设备角色:
• 供电设备PSE(Power-sourcing Equipment):通过以太网给受电设备供电的PoE设备,提供检测、分析、智能功率管理等功能,例如:PoE交换机。
• 受电设备PD(Powered Device):如无线AP、便携设备充电器、刷卡机、摄像头等受电方设备。按照是否符合IEEE标准,PD分为标准PD和非标准PD。
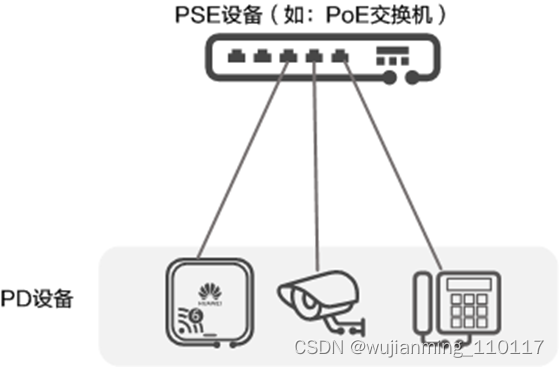
PoE供电设备角色
PoE供电模式
按照IEEE标准的定义,PSE设备分为MidSpan(PoE功能模块在设备外)和Endpoint(PoE功能模块集成到设备内)两种类型。华为Cloudengine S系列PoE交换机的PoE功能模块全部集成在设备的内部,属于Endpoint的PSE设备。
Endpoint类型的PSE设备依据使用的供电线对不同分为Alternative A(1/2和3/6线对)和Alternative B(4/5和7/8线对)两种供电模式。
Alternative A供电模式通过数据对供电。PSE通过1/2和3/6线对给PD供电,1/2链接形成负极,3/6链接形成正极。10BASE-T、100BASE-TX接口使用1/2和3/6线对传输数据,1000BASE-T接口使用全部的4对线对传输数据。由于DC直流电和数据频率互不干扰,所以可以在同一对线同时传输电流和数据。
Alternative B供电模式通过空闲对供电。PSE通过4/5和7/8线对给PD供电,4/5链接形成正极,7/8链接形成负极。
IEEE标准不允许同时应用以上两种供电模式。供电设备PSE只能提供一种用法,但是受电设备PD必须能够同时适应两种情况。
PoE供电协商流程
PSE设备上电,PD设备通过网络连接到PSE设备后,PSE与PD就开始进行供电协商:
• 检测PD:PSE在端口周期性输出电流受限的小电压,用以检测PD设备的存在。如果检测到特定阻值的电阻,说明线缆终端连接着支持IEEE 802.3af标准或IEEE 802.3at标准的受电端设备(电阻值在19kΩ~26.5kΩ的特定电阻,通常的小电压为2.7V~10.1V,检测周期为2秒)。
• 供电能力协商即PD设备分类过程:PSE对PD进行分类,并协商供电功率。供电能力协商不仅可以通过解析PSE与PD发送的电阻实现的,还可以通过链路层发现协议LLDP(Link Layer Discovery Protocol)协议发现和通告供电能力进行协商。
• 开始供电:在启动期内(一般小于15μs),PSE设备开始从低电压向PD设备供电,直至提供48V的直流电压。
• 正常供电:电压达到48V之后,PSE为PD设备提供稳定可靠48V的直流电,PD设备功率消耗不超过PSE最大输出功率。
• 断电:供电过程中,PSE会不断监测PD电流输入,当PD电流消耗下降到最低值以下,或电流激增,例如拔下设备或遇到PD设备功率消耗过载、短路、超过PSE的供电负荷等,PSE会断开电源,并重复检测过程。
通过LLDP协议进行供电能力协商
IEEE 802.1ab定义了可选的TLV(Type Length Value):Power via MDI(Media Dependent Interface) TLV。LLDP报文封装Power via MDI TLV,进行MDI供电能力的发现和通告。当PSE检测到PD后,PSE和PD即周期性地向对方发送LLDP报文,这个报文里包含了定义的TLV字段。将本端信息发送给对方,对方记录下报文中包含的信息,达到信息交互的作用。但IEEE 802.1ab定义的Power via MDI TLV格式仅能协商IEEE 802.3af和IEEE 802.3at两种标准的供电参数,不能协商IEEE 802.3bt标准的供电参数,当相连的PD设备使用IEEE 802.3bt标准供电时,标准Power via MDI TLV将无法协商供电。华为S系列交换机为能够支持协商IEEE 802.3bt标准的供电参数,自定义了一种Power via MDI TLV。
IEEE 802.1ab定义的Power via MDI TLV报文
由2字节的TLV报文头和12字节的TLV信息字段组成,报文格式如下图所示:
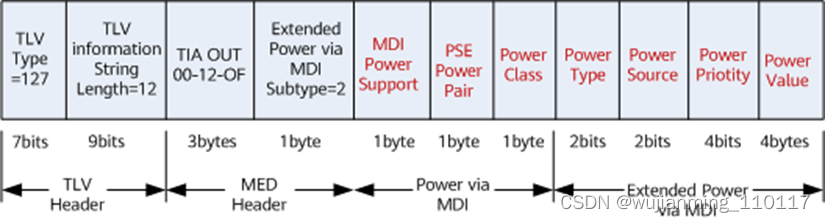
IEEE 802.1ab定义的TLV报文格式
Power via MDI和Extended Power via MDI各字段含义如下图所示。
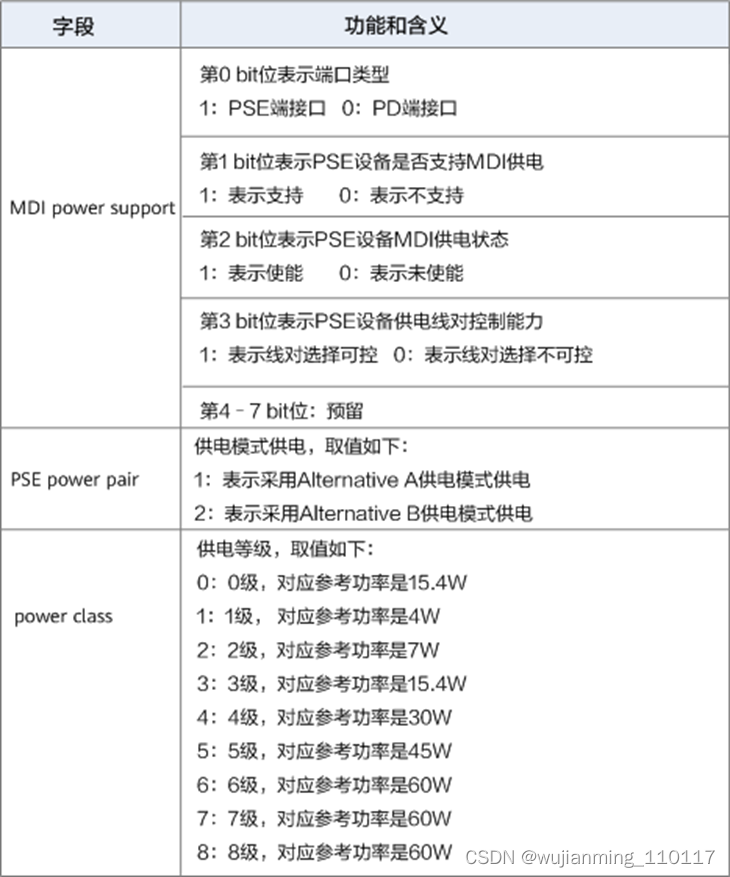
Power via MDI各字段含义
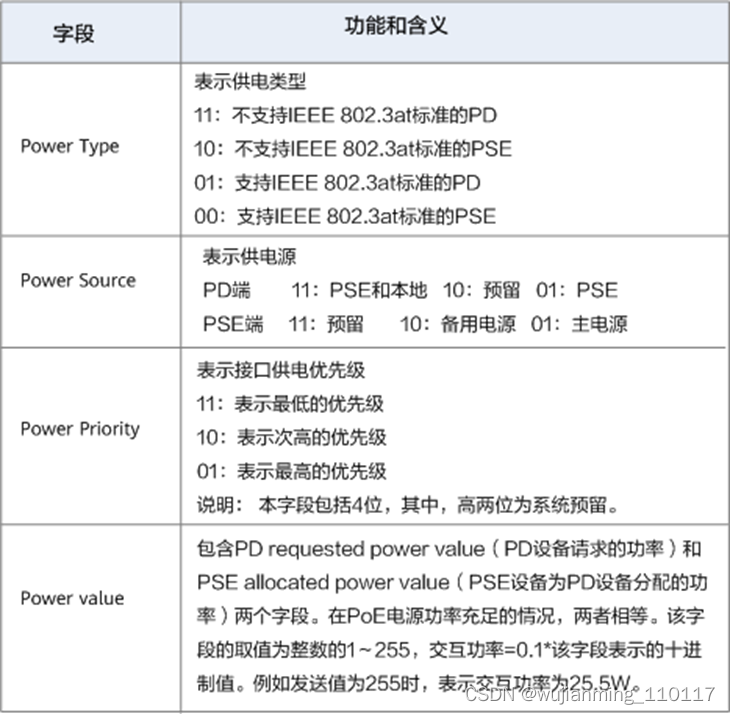
Extended Power via MDI各字段含义
华为公司自定义的Power via MDI TLV
由2字节的TLV报文头和4字节的TLV信息字段组成,报文格式如下图所示:

华为公司自定义的TLV报文格式
TLV报文中各字段含义如下:
• TLV Type:TLV的类型,占1个字节。取值为1,表示PD支持的供电模式;取值为2,表示PD当前工作的供电模式。
• TLV Length:TLV的长度,占1个字节。取值为4,表示TLV信息字段值占4个字节。
• TLV Value:TLV的值,占4个字节,共32位。第0位、1位、2位、3位的含义如下图所示,第4~31位预留。
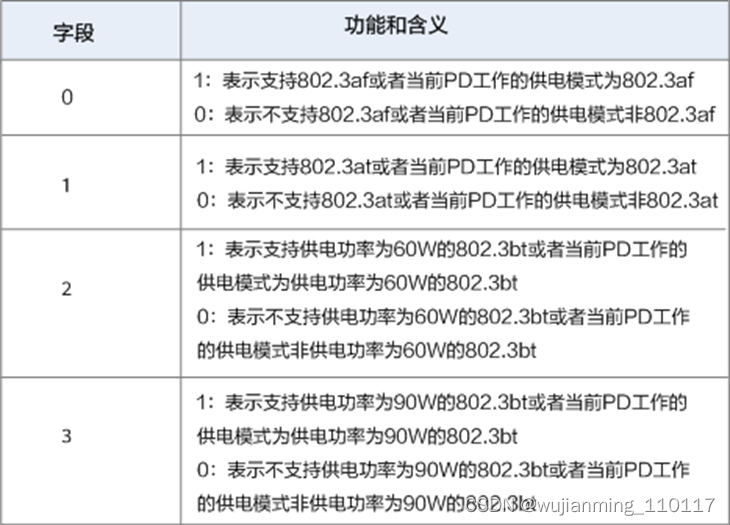
自定义TLV Value字段含义
PoE供电标准有哪些?
前面我们提及了IEEE标准委员会为解决不同厂家供电和受电设备之间的适配性问题,会先后发布了三个PoE标准:IEEE 802.3af标准、IEEE 802.3at标准、IEEE 802.3bt标准。那么这三个标准有什么不同呢?
2003年6月,IEEE 802.3工作组制定了IEEE 802.3af标准,作为以太网标准的延伸,对网络供电的电源、传输和接收都做了细致的规定。例如:IEEE 802.3af标准规定PSE设备需要在每个端口上提供最高15.4W的直流电源。
由于电缆中的一些功率耗散,因此受电设备仅有12.95W可用。2009年10月,为对应大功率终端的需求,诞生了IEEE 802.3at标准,IEEE 802.3at标准在兼容802.3af标准的基础上,提供最高25.5W的功率,满足新的需求。
2018年9月,为进一步提升PoE供电功率以及对标准进行优化,IEEE标准委员会的发布了IEEE 802.3bt标准。IEEE 802.3bt标准进一步提升了供电能力,类型3可提供高达51 W的供电功率,类型4可提供高达71.3W的供电功率。此外,还包括对2.5GBASE-T、5GBASE-T和10GBASE-T的支持,扩大了高性能无线接入点和监控摄像头等应用程序的使用。
一般将IEEE 802.3af标准对应的供电技术称为PoE供电,将IEEE 802.3at标准对应的供电技术称为PoE+供电,将IEEE 802.3bt标准对应的供电技术称为PoE++供电,也称为4PPoE。三种供电技术对应的参数如下图所示。
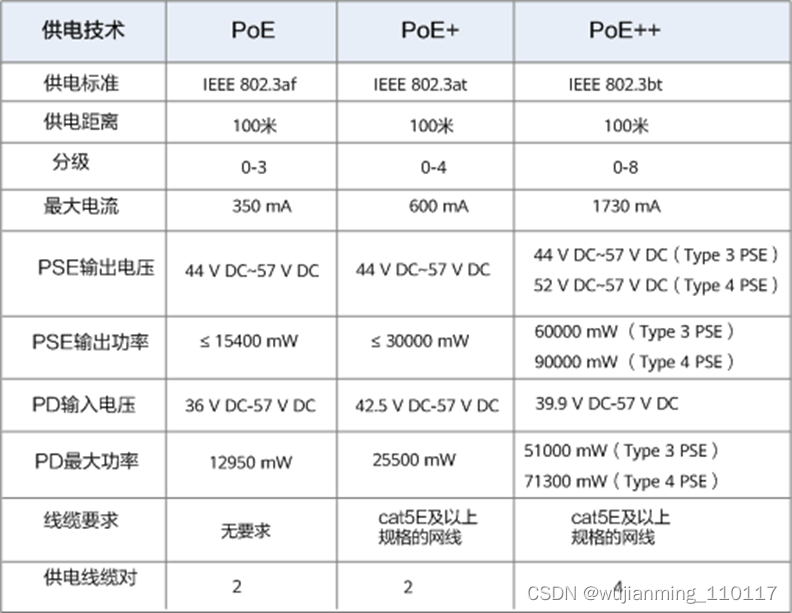
PoE供电技术参数对比
有哪些设备可以支持PoE供电
PoE供电设备非常普遍,例如华为S系列园区交换机、无线接入控制器AC和AR接入路由器都有款型可以支持PoE供电,设备是否可以支持PoE供电,是由硬件决定的,不能通过升级软件把不支持PoE供电的设备变更为支持PoE供电的设备。
以华为S系列园区交换机为例,能够支持PoE供电的交换机叫做PoE交换机,一般部署在接入层,通过内置或外置的PoE电源为终端设备供电。框式交换机要作为PoE交换机,需要同时满足:一是机框必须是支持PoE供电的机框,二是机框中插入的单板必须是PoE单板;盒式交换机只要设备款型支持PoE功能,设备上电后就可以支持PoE供电。
首台E级超算:登顶Top500榜单,超算进入新时代
5 月30日,第 59 届 ISC 2022(国际超算大会)发布最新 Top500 榜单,美国田纳西州橡树岭国家实验室(ORNL)的 Frontier 成为第一个真正突破 Exascale 大关的超算,性能达到 1.102 exaflops,该榜单正式标志着超级计算新时代的到来。
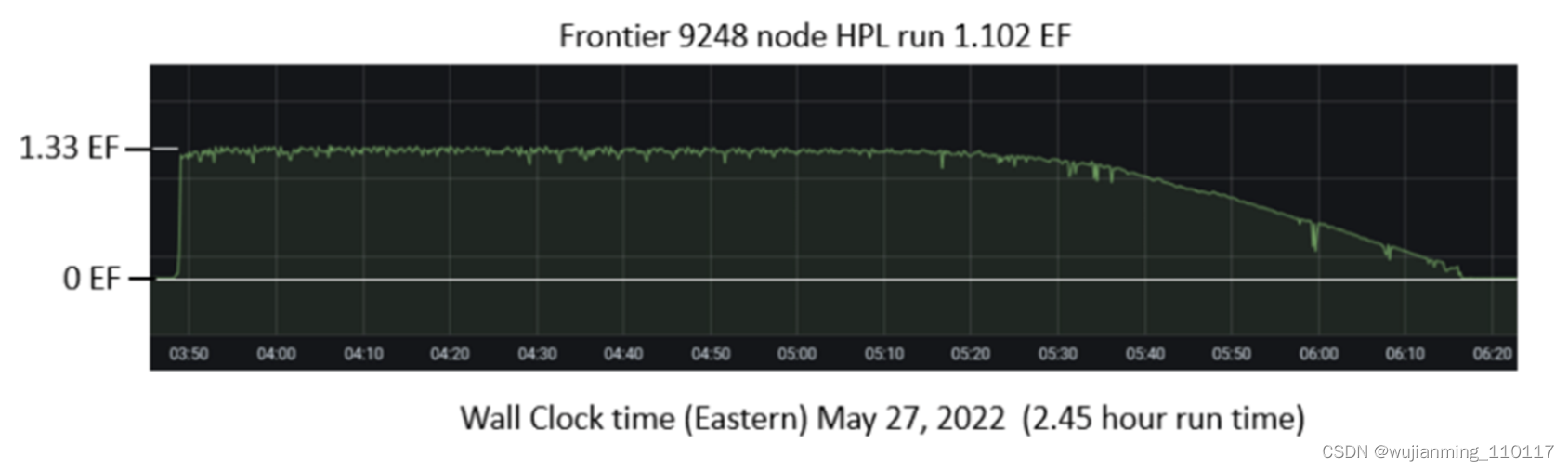
Frontier 超算突破 Exaflops
Frontier 由 74 个 Cray EX 机柜组成,可容纳 9408 个节点,每个节点配备一个 AMD Milan「Trento」7A53 Epyc CPU 和四个 AMD Instinct MI250X GPU,GPU 总数为 37632。节点通过 HPE 的 Slingshot-11 互连连接。每个节点 CPU 支持 512GiB DDR4 内存,跨节点支持 512GiB HMB2e(每 GPU 128GiB)内存。

Frontier 的 Linpack 性能为 1.102 exaflops,比 Top500 中的排名靠前的 7 个系统加起来还要快。来自田纳西州橡树岭国家实验室的 Thomas Zacharia 表示:「我们不能低估 0.1 的差距,一个 0.1 代表 100petaflops,0.1 看起来很小,很容易被四舍五入。但每个小数点都代表着一种巨大的能力。」

Frontier 在 OLCF(美国橡树岭国家实验室领先运算机构)占地 372 平方米,聚合了 9.2 PB 的内存(4.6 PB 的 DDR4 和 4.6 PB 的 HBM2e),有 37 PB 的节点本地存储,并可访问 716 PB 的中心范围存储。
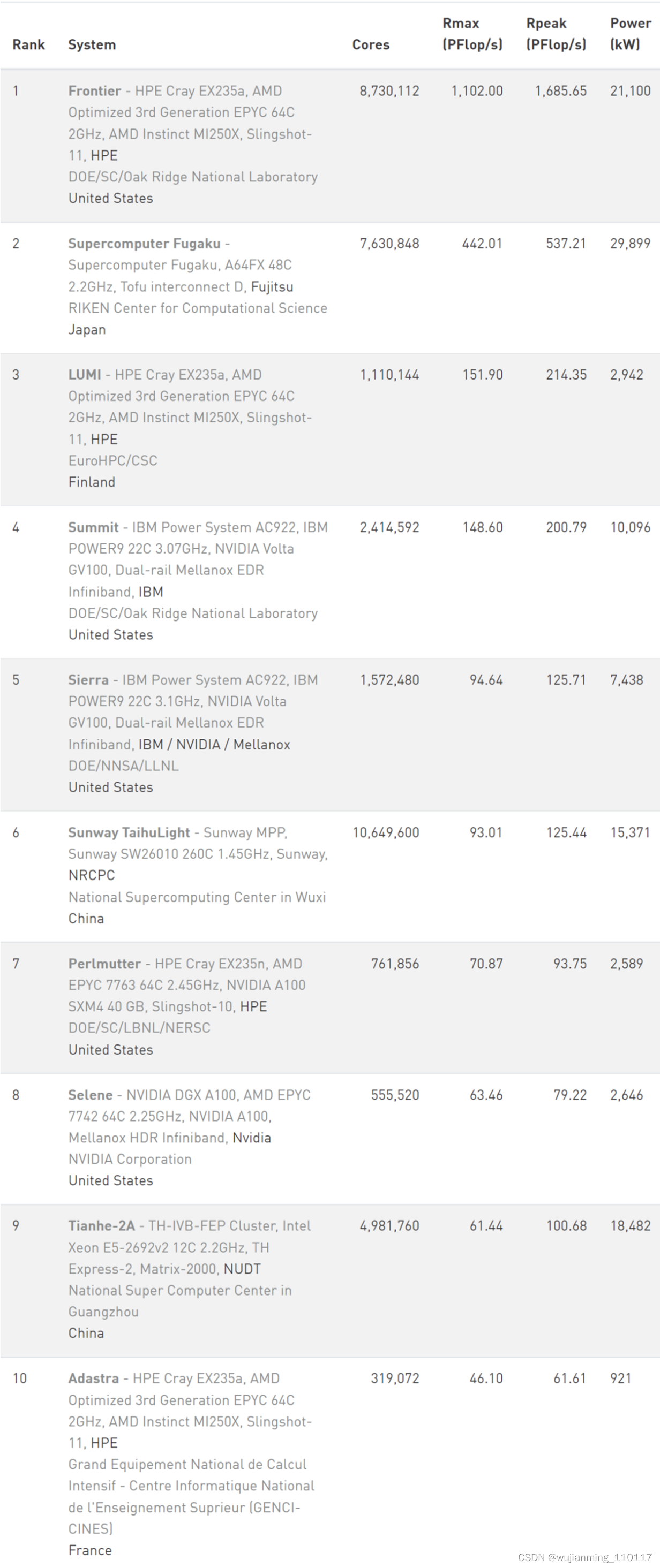
Top10 榜单
四次登顶的日本超算富岳本次排在第二位,性能 442 petaflops,其采用 Arm A64FX 系统。
部署在芬兰国家超算中心的 LUMI 排名第三,使其成为欧洲最强大超算系统。LUMI 实现了 151.90 Linpack petaflops,理论峰值可达到 214.3 petaflops,这个数字大约为 71% 的 Linpack 效率。
IBM 的 Summit 排名第四、Sierra 排名第五;中国的神威太湖之光排名第六;美国劳伦斯伯克利实验室的国家能源研究科学计算中心(NERSC) 的 Perlmutter HPE Cray EX 排名第七;紧随其后的是英伟达 Selene 排在第八位;中国的天河 2A 排名第九。
部署在法国国家大型计算中心的 Adastra 系统排名第十,其 Linpack 实现 46.1 Linpack petaflops,理论峰值为 61.6 千万亿次,Linpack 效率为 75%。
值得一提的是,Top10 中新上榜的 3 台新系统(美国的 Frontier、芬兰的 LUMI 和 法国的 Adastra)都是采用了 HPE Cray EX235a 架构。
仅仅在四年前,也就是 2018 年 6 月,整个 Top500 榜单首次以 1.22 exaflops 的总和超过 exaflops 大关。现在 Frontier 的单个系统算力就达到了 1.102 Exaflops。
本次 Top500 榜单共迎来 39 个新系统,地域分布广泛。美国最多,有 9 个,其次是德国的 5 个。近十年来,中国首次没有新系统上榜,尽管如此,中国仍然拥有列表中最多的系统:173 个,而美国系统数量为 127 个,就系统数量而言,美国位居第二。然而,美国由于 Frontier 的性能显着拉长了领先优势。
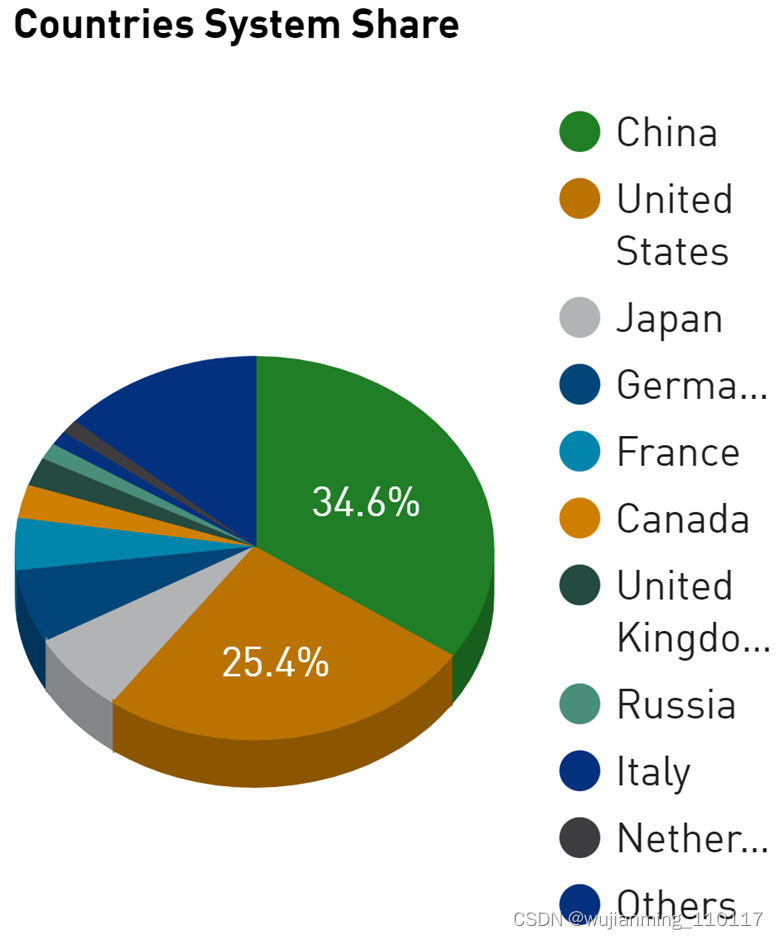
中国的超算进展
在国内的超级计算机计划中已有三个 E 级超算上马,这些系统本质上不是由 Top500 或 HPL 基准验证的,而是由戈登贝尔奖。其中一个是无锡超级计算中心运营的神威太湖之光(新机位于青岛)。
另一个系统天河三号位于天津市。Tianhe-3 基于 Phytium 2000+ FTP Arm 芯片和 Matrix 2000+ MTP 加速器。该系统据报道已于去年秋天完成,估计可以提供 1.7 exaflops 的峰值性能,在 Linpack 上提供了略高于 1.3 exaflops 的性能。
在汉堡举行的 ISC 2022 之前,有消息人士表示,中国正计划在 2025-2026 年的时间范围内制造一台 10 exaflops 的机器。另有消息人士称,有两台目标 2025 年上线的 10 exaflops 系统正在开发中,但现在更大的可能是在 2026 年只推出一台 10 exaflops 系统。与太湖之光一样,它将是神威架构,即基于 Alpha 核心。
上海交通大学网络信息中心副主任,HPC 专家林新华表示,Top500 已成为事实上的实体名单。「中国顶级超级计算机的供应商和主机中心都在名单上,」他表示。「进入 Top500 是为了促进国际合作,但结果却适得其反。我们提交 Top500 并不是为了维持联系。」
近年来,在 Top500 基准上的几家中国系统的支持实体和供应商确实被列入了美国实体名单。
技术供应商
联想是 Top500 榜单上的常客,其参与基准测试的新系统数量最多(17 个),在 14 个新系统中,HPE 的数量位居第二(其中 7 个采用 AMD+AMD 节点,通过 Slingshot-11 连接,包括 三个 NNSA/LLNL 系统)。在所有 500 个系统中,按纯系统数量计算的阵容是联想(180 个)、HPE(84 个)和浪潮(50 个)。按性能份额比较的话,排名依次为:HPE(18.6%)、富士通(18.1%)和联想(15.1%)。
名单上没有新的英伟达系统。其自用的 Eos 超算将会展示它的最新实力,但为 Eos 提供算力的 DGX H100 节点预计直到下个季度才会发货。
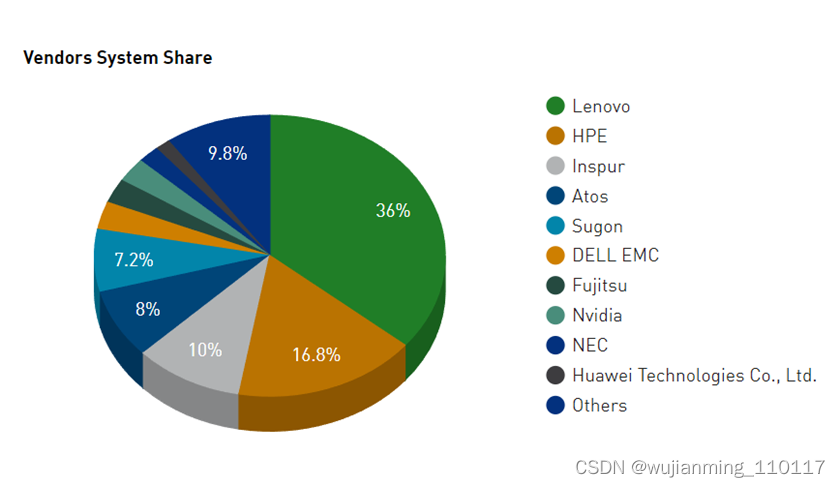
英伟达是该列表中 19 个系统的制造商,并且它合作参与了另外 5 个系统的构建,包括第五位的 Sierra、第 22 位的 Chervonenkis 、第 30 位的 Lassen、第 40 位的 Galushkin 和第 43 位的 Lyapunov。
英特尔声称在 Top500 排行榜中占有 77.40% 的份额,这个数字低于六个月前的 81.60%。AMD 共有 94 个系统,在该列表中的份额已从六个月前的 14.60% 增长到 18.80%。
IBM 的超算数量仍然未变是 9 个:第 4 名的 Summit、第 5 名的 Sierra、第 21 名的 Marconi-100、第 30 名的 Lassen、第 33 名的 PANGEA II、第 24 名的 AiMOS、第 160 名的 HPC2 第 205 名的 SuperMUC Phase2(与联想合作)和第 303 名的 Longhorn。
参考文献链接
https://mp.weixin.qq.com/s/fLb8zKbHe_oxxIMv3y59TQ
https://mp.weixin.qq.com/s/I7pfDI5j8Th6myRnXTIytA
https://mp.weixin.qq.com/s/PjJdF37H4Ape-IDw68wR1A
https://www.top500.org/news/ornls-frontier-first-to-break-the-exaflop-ceiling/