最优装载问题和背包问题有些相似,有很多集装箱要装到轮船上去,但是轮船是有载重限制的,不能无限制的装进去,轮船有承重量,不能够吃水太多,现在的问题是怎么才能让集装箱的个数最多,而不是达到重量最大,这个是和背包问题的区别,你可以这样认为,集装箱的价值为1,不管集装箱重还是轻,装进去价值就加1了,所以可以看成0-1背包的子问题。
一、问题描述:
n 个集装箱1, 2, … , n装上轮船,集装箱i的重量wi, 轮船装载重量限制为C,无体积限制. 问如何装使得上船的集装箱最多?不妨设每个箱子的重量wi≤C. 该问题是0-1背包问题的子问题. 集装箱相当于物品,物品重量是wi,价值vi 都等于1,轮船载重限制C 相当于背包重量限制b.
二、建模
集装箱每一个货箱有自己的重量,当你装进去或者不装就是两种选择,装进去的话就是1就会乘重量做个累积,这个就表示装到集装箱上所有重量求和,这个和是不能超过轮船载重限制的,超重就会很危险。
在说明约束条件的时候一定是0和1之间的整数,目标函数每一个集装箱的价值都相当于1
m a x ∑ i = 1 n x i ∗ 1 max\sum\limits_{i=1}^n x_{i} *1 maxi=1∑nxi∗1
装进去或者不装进去把它乘1,没装进去就是0,装进去就是1个单位,现在求最大价值。这个是0-1背包的子问题体现在
Value = 1
约束更强,条件限制更多不是完全的0-1背包的问题
1、设<x1,x2,…,xn> 表示解向量,xi=0,1,xi=1当且仅当第i个集装箱装上船
(1)目标函数
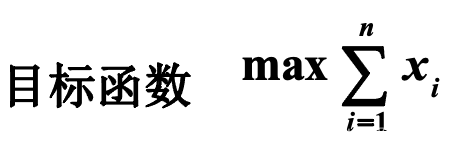
(2)约束条件
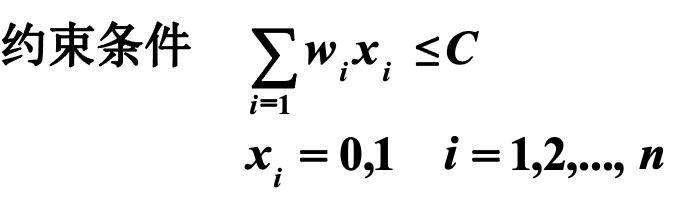
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from IPython.display import Image
# from sklearn.externals.six import StringIO
from sklearn import tree
import pydotplus
from six import StringIO
from sklearn.datasets import load_iris
from six import StringIO
from sklearn.metrics import accuracy_score
from sklearn.tree import accuracy_score
from sklearn.model_selection import GridSearchCV #优化模型参数
from IPython.display import Image
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifer
from sklearn.ensemble import GradientBoostingClassifier
import os
os.environ["PATH"] += os.pathsep + \
'F:/mydownload/python/stable_windows_10_cmake_Release_x64_graphviz-install-2.49.1-win64/Graphviz/bin'
stu_grade = pd.read_csv('student_1.csv')
stu_grade.head() #只读取df中前五行数据,默认为五行
new_data = stu_grade.iloc[:,:] #通过行号来取得行列式全
new_data.head()
def choice_2(x): #将G1,G2,G3做连续值处理,转换成离散值,然后替换数据
x = int(x) #G1,G2为一阶段成绩和二阶段成绩
if x < 5: #G3为最终成绩
return 'bad'
elif x >= 5 and x < 10:
return 'medium'
elif x >= 10 and x < 15:
return 'good'
else:
return "excellent"
stu_data = new_data.copy()
stu_data['G1'] = pd.Series(map(lambda x:choice_2(x),stu_data['G1']))
stu_data['G2'] = pd.Series(map(lambda x:choice_2(x),stu_data['G2']))
stu_data['G3'] = pd.Series(map(lambda x:choice_2(x),stu_data['G3']))
stu_data.head()
def choice_3(x): #设置对Pedu的划分,做连续值处理,转化成离散值,然后替换数据
x = int(x)
if x > 3:
return "high"
elif x > 1.5:
return "medium"
else:
return "low"
stu_data["Pedu"] = pd.Series(map(lambda x:choice_3(x),stu_data["Pedu"]))
stu_data.head()